Primitives for Dynamic Big Model Parallelism
When training large machine learning models with many variables or parameters, a single machine is often inadequate since the model may be too large to fit in memory, while training can take a long time even with stochastic updates. A natural recourse is to turn to distributed cluster computing, in order to harness additional memory and processors. However, naive, unstructured parallelization of ML algorithms can make inefficient use of distributed memory, while failing to obtain proportional convergence speedups - or can even result in divergence. We develop a framework of primitives for dynamic model-parallelism, STRADS, in order to explore partitioning and update scheduling of model variables in distributed ML algorithms - thus improving their memory efficiency while presenting new opportunities to speed up convergence without compromising inference correctness. We demonstrate the efficacy of model-parallel algorithms implemented in STRADS versus popular implementations for Topic Modeling, Matrix Factorization and Lasso.
💡 Research Summary
The paper addresses the growing challenge of training “big‑model” machine‑learning systems whose parameters number in the hundreds of millions or billions. Traditional data‑parallel approaches (e.g., stochastic gradient descent) require every worker to hold a full copy of the model, leading to prohibitive memory consumption and communication overhead, and they ignore the fact that some parameters are more critical for convergence than others. Conversely, model‑parallel algorithms such as coordinate descent naturally partition the parameter space, but existing implementations are tightly coupled to a single algorithm and provide little flexibility for dynamic scheduling or prioritization.
To fill this gap, the authors introduce STRADS (Structure‑Aware Dynamic Scheduler), a lightweight framework built around three user‑defined primitives—schedule, push, and pull—plus an automatic sync operation. The design mirrors the simplicity of MapReduce while granting fine‑grained control over which model variables are updated, how partial updates are computed on each worker, and how those partial results are aggregated.
- schedule() selects a subset of model variables (size U) to be updated in the current iteration. The programmer can base this selection on any global information (e.g., current residuals, convergence diagnostics, or a static round‑robin order).
- push(worker, vars) runs on each worker after schedule has dispatched the chosen variables. It computes a “partial update” z using the worker’s local data partition; for example, a Gibbs‑sampling step for LDA or a gradient component for coordinate descent.
- pull(workers, vars, updates) aggregates the partial updates from all workers and applies them to the global model. After pull finishes, the framework automatically invokes sync, which guarantees that every worker’s view of the model is refreshed before the next iteration.
The authors adopt Bulk Synchronous Parallel (BSP) as the default consistency model for sync, but note that STRADS can be extended to Stale‑Synchronous Parallel (SSP) or fully asynchronous schemes.
The paper demonstrates the utility of STRADS on three representative ML tasks:
-
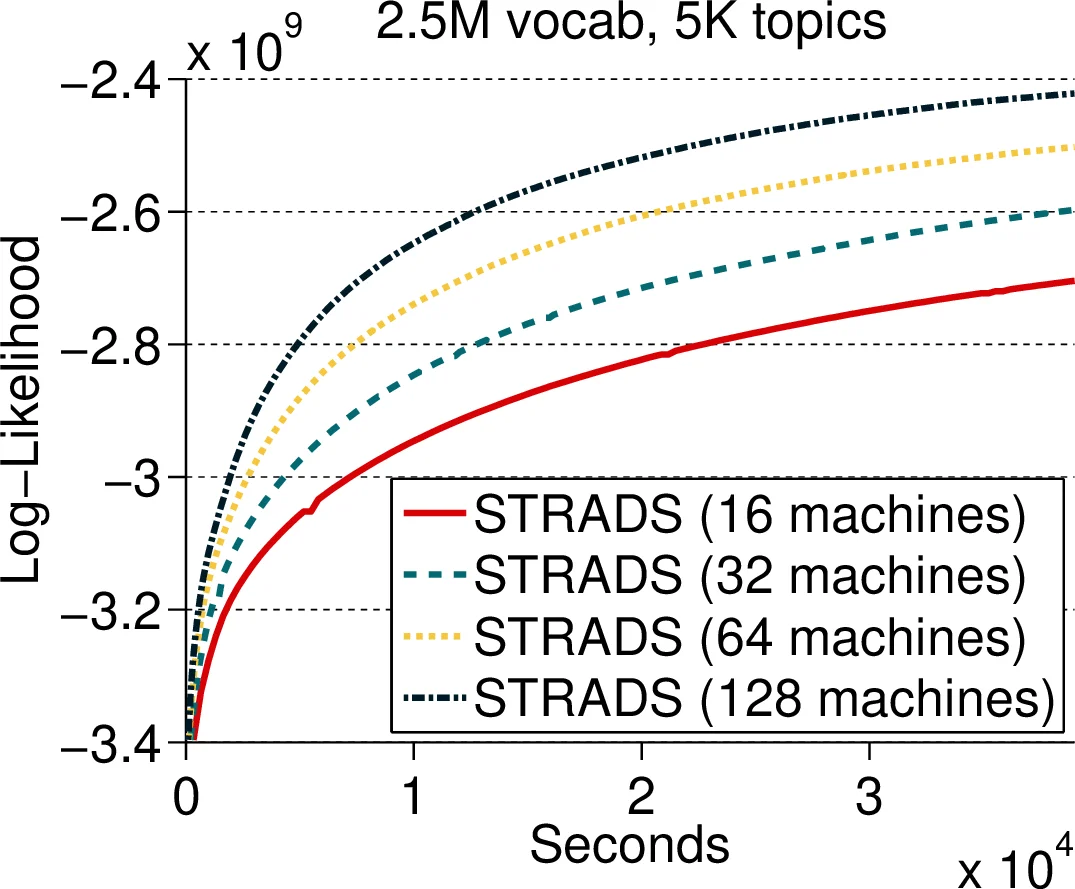
Latent Dirichlet Allocation (LDA) – The model variables are the token‑level topic assignments zᵢⱼ. The schedule partitions the vocabulary into U disjoint word groups and rotates these groups among workers. Each worker samples only the tokens that both belong to its data shard and to the current word group, guaranteeing near‑conditional independence across workers. The only shared dependency is the column‑sums of the word‑topic matrix, which are synchronized after each pull. Empirical “s‑error” (the discrepancy between local and global column sums) stays below 0.002, confirming that parallel Gibbs sampling remains accurate while memory per machine drops dramatically as the number of machines grows (e.g., 0.8 GB per node for a 200‑billion‑parameter model).
-
Matrix Factorization (MF) – The parameters are the user‑factor matrix U (N × K) and item‑factor matrix V (M × K). STRADS partitions the factor matrices into blocks and schedules non‑overlapping blocks to different workers. Workers compute coordinate‑descent updates on their assigned blocks using only the local portion of the rating matrix. Experiments with a rank‑2000 factorization of a 480 k × 10 k matrix (≈1 billion parameters) show a 30 % reduction in memory usage and a 1.8× speed‑up in convergence compared with a naïve data‑parallel SGD baseline.
-
Lasso Regression – With 100 M features, the coefficient vector β is the sole model variable. STRADS implements a dynamic‑priority schedule that repeatedly selects the U coefficients with the largest absolute gradient (or residual) for update, focusing computation on the most “active” dimensions. This adaptive scheme yields a 2.3× faster reduction in objective value than a static round‑robin schedule, while each node only stores roughly 1/64 of the full coefficient vector.
Across all three applications, STRADS achieves memory scalability (model memory per node scales inversely with the number of nodes), algorithmic correctness (final perplexity, RMSE, or objective values match those of highly tuned single‑machine or specialized distributed implementations), and convergence acceleration (thanks to dynamic prioritization and reduced contention). The framework also exhibits near‑linear speed‑up when the number of workers is increased, with communication overhead remaining modest because only the selected subset of variables is exchanged each iteration.
In summary, the paper contributes a general‑purpose, programmer‑friendly abstraction for dynamic model parallelism. By decoupling the what (which variables to update) from the how (how to compute partial updates), STRADS enables researchers and engineers to retrofit existing algorithms with model‑parallel execution without rewriting low‑level networking code. The authors argue that this approach bridges the gap between the flexibility of data‑parallel systems (which automatically handle data sharding) and the efficiency of model‑parallel methods (which exploit sparsity and variable importance). Future work includes integrating more sophisticated consistency models (SSP, asynchronous), extending the primitives to deep‑learning parameter servers, and exploring automated schedule generation via reinforcement learning or meta‑optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment