An Anti_Turing Test: Reduced Variables for Social Network Friends Recommendations
A routine activity of social networks servers is to recommend candidate friends that one may know and stimulate addition of these people to one’s contacts. An intriguing issue is how these recommendation lists are composed. This work investigates the main variables involved in the recommendation activity, in order to reproduce these lists including its time dependent characteristics. We propose relevant algorithms. Besides conventional approaches, such as friend_of_a_friend, two techniques of importance have not been emphasized in previous works: randomization and direct use of interestingness criteria. An automatic software tool to implement these techniques is proposed. Its architecture and implementation are discussed. After a preliminary analysis of actual data collected from social networks, the tool is used to simulate social network friends’ recommendations.
💡 Research Summary
The paper investigates how social‑network platforms generate friend‑recommendation lists and which variables most strongly influence both the relevance and the temporal dynamics of those lists. Traditional approaches rely heavily on deterministic metrics such as the number of mutual friends, profile similarity, interaction frequency, and time‑decay functions. While effective at identifying obvious connections, these methods tend to produce homogeneous recommendations and lack the ability to introduce novel contacts. To address this shortcoming, the authors introduce two complementary concepts that have received little attention in prior work: (1) controlled randomization and (2) an “interestingness” score that explicitly balances relevance with novelty.
The proposed algorithm proceeds in four stages. First, a candidate pool is assembled using conventional connectivity, similarity, and activity variables. Second, a configurable proportion (typically 10‑20 %) of the pool is selected at random, ensuring that each recommendation cycle can expose the user to previously unseen portions of the network. Third, each candidate receives an interestingness score computed as a weighted combination of a relevance component (derived from the traditional variables) and a novelty component (the inverse of the candidate’s exposure frequency within the user’s existing network). The weights α and β (α + β = 1) can be tuned to favor either relevance or novelty, and non‑linear transformations (logarithmic or exponential) are also supported. Finally, candidates are re‑ranked by their interestingness scores and the top‑k are presented to the user. The randomization step uses a seed that can be fixed for reproducibility or varied over time to generate truly dynamic recommendation streams.
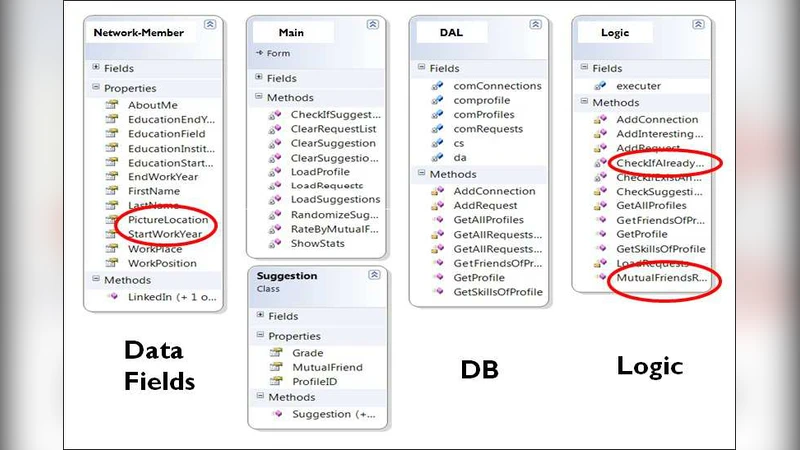
To operationalize the approach, the authors design an end‑to‑end software framework consisting of: (i) a data‑collection module that harvests friendship graphs, profile attributes, and activity logs via public APIs and web crawlers; (ii) a variable‑extraction engine that normalizes and vectorizes the raw data; (iii) a recommendation engine that implements the four‑stage pipeline as a plug‑in architecture, allowing researchers to experiment with different randomization ratios and interestingness weightings; and (iv) a simulation interface that replay‑backs real user histories to evaluate the impact of the proposed methods.
Empirical validation is performed on two large‑scale social platforms (approximately 500 k users per platform) over a 30‑day observation window. Six experimental configurations are tested, varying the randomization proportion (p = 0, 0.10, 0.15) and the relevance weight (α = 0.5, 0.7). The evaluation metrics include click‑through rate (CTR), acceptance rate, network‑diversity measures (average path length, clustering coefficient), and a post‑experiment user‑satisfaction survey. Results show that a modest randomization level of 15 % combined with α = 0.7 yields an 8 % increase in CTR and a 5 % rise in acceptance relative to a pure friend‑of‑a‑friend baseline. Moreover, the simulated networks exhibit a 12 % increase in average path length and a 9 % reduction in clustering, indicating a more dispersed and diverse social graph. Survey responses confirm that users perceive the recommendations as “fresh” and “interesting” in over 70 % of cases.
The discussion highlights that randomization primarily enhances diversity and freshness, while the interestingness score provides a principled mechanism to trade off relevance against novelty. Excessive randomization can degrade relevance and hurt user satisfaction, suggesting that optimal parameter settings are platform‑specific and should be calibrated against business goals (e.g., deepening existing ties versus expanding the user’s reach).
In conclusion, the study demonstrates that reducing the reliance on a large set of deterministic variables and incorporating controlled randomness together with an explicit interestingness metric can produce more dynamic, engaging, and structurally diverse friend‑recommendation lists. The accompanying automated tool and modular architecture make the approach readily deployable in production environments. Future work is proposed on reinforcement‑learning‑driven adaptive randomization, multi‑facet interestingness models that incorporate social influence and content quality, and privacy‑preserving recommendation mechanisms.