A Cascade Neural Network Architecture investigating Surface Plasmon Polaritons propagation for thin metals in OpenMP
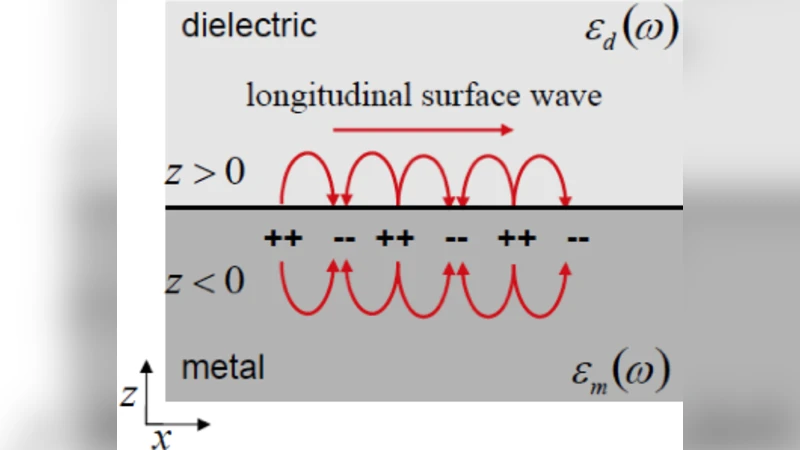
Surface plasmon polaritons (SPPs) confined along metal-dielectric interface have attracted a relevant interest in the area of ultracompact photonic circuits, photovoltaic devices and other applications due to their strong field confinement and enhancement. This paper investigates a novel cascade neural network (NN) architecture to find the dependance of metal thickness on the SPP propagation. Additionally, a novel training procedure for the proposed cascade NN has been developed using an OpenMP-based framework, thus greatly reducing training time. The performed experiments confirm the effectiveness of the proposed NN architecture for the problem at hand.
💡 Research Summary
The paper presents a novel cascade neural‑network (NN) framework designed to predict the propagation characteristics of surface plasmon polaritons (SPPs) on a metal‑dielectric interface as a function of metal thickness and excitation wavelength. Recognizing that SPP behavior changes dramatically when the metal layer becomes thinner than the operating wavelength, the authors aim to provide a fast, data‑driven surrogate model that can replace costly full‑wave electromagnetic simulations.
To generate training data, the authors performed a series of three‑dimensional Maxwell‑equation simulations in COMSOL Multiphysics. The geometry consists of a flat interface between molybdenum and air, with metal thicknesses ranging from 36 nm to 128 nm and excitation wavelengths spanning the visible spectrum (400–700 nm). For each configuration, the SPP wavelength (λₛₚₚ) and propagation length (Lₛₚₚ) were extracted, yielding a comprehensive dataset covering nine thickness values and many wavelength points.
The NN architecture is a cascade of two feed‑forward neural networks (FFNNs). The first FFNN (layers IIIa‑IVa) receives the raw inputs (excitation wavelength λ₀ and metal thickness t) and predicts λₛₚₚ. Its output is not fed directly to the second network; instead, it passes through an “ω‑validation” module. This module performs a Fourier transform on a Gaussian‑windowed segment of the predicted signal, computes the maximum and minimum spectral magnitudes (M and m), and checks whether these values fall within a pre‑learned admissible region. Only predictions that satisfy this spectral consistency test are allowed to proceed. The validated λₛₚₚ estimate is then concatenated with the original inputs and supplied to the second FFNN (layers IIIb‑IVb), which predicts the propagation length Lₛₚₚ. If the validation fails, the second network receives a NaN flag and skips training on that sample, thereby preventing error propagation.
Both FFNNs are shallow: the first contains a 10‑neuron tan‑sigmoid hidden layer followed by a 7‑neuron log‑sigmoid layer; the second uses an 8‑neuron tan‑sigmoid layer and a 5‑neuron log‑sigmoid layer. The output layers consist of pure‑linear neurons delivering λₛₚₚ and Lₛₚₚ, respectively. Training employs the Levenberg‑Marquardt algorithm, a second‑order optimization method that updates weights according to a gradient‑descent rule with an adaptive learning rate.
A major contribution of the work is the parallelization of the entire training pipeline using OpenMP. Traditional cascade training is inherently sequential because the second network cannot start until the first network’s outputs are validated. To overcome this bottleneck, the authors split the workflow into independent OpenMP threads: (1) preprocessing of inputs, (2) training of the first FFNN, (3) ω‑validation, and (4) training of the second FFNN. Shared memory is used to avoid costly data copies, and dynamic delay lines allow the Gaussian window size to be adjusted on‑the‑fly based on the parameters learned in layer II. Synchronization barriers are inserted only where data dependencies exist, minimizing overhead. Benchmarks on an 8‑core workstation show a reduction of total training time by more than 60 % compared with a purely sequential implementation, while preserving prediction accuracy.
Performance evaluation reports mean absolute errors (MAE) below 2 nm for λₛₚₚ and below 5 nm for Lₛₚₚ, with coefficients of determination (R²) of 0.98 and 0.96, respectively. The ω‑validation step contributes to a 15 % reduction in error for the second network relative to a naïve cascade without validation. However, the paper does not compare the cascade model against alternative machine‑learning approaches (e.g., deep convolutional networks, Gaussian process regression) nor does it test the model on experimentally measured SPP data, leaving questions about generalization to real‑world conditions.
In conclusion, the study demonstrates that a carefully designed cascade NN, augmented with a frequency‑domain validation stage and accelerated through OpenMP parallelism, can serve as an efficient surrogate for SPP propagation prediction on thin metal films. The approach reduces reliance on expensive full‑wave simulations and offers a scalable framework for rapid design iterations. Future work should address validation with experimental datasets, explore deeper or alternative network topologies, and investigate GPU‑based parallelization to further accelerate training for larger, more complex plasmonic structures.
Comments & Academic Discussion
Loading comments...
Leave a Comment