A Fast, Minimal Memory, Consistent Hash Algorithm
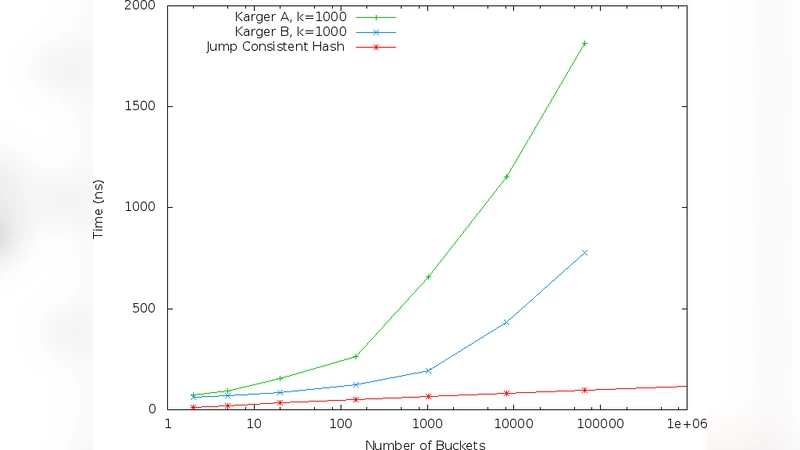
We present jump consistent hash, a fast, minimal memory, consistent hash algorithm that can be expressed in about 5 lines of code. In comparison to the algorithm of Karger et al., jump consistent hash requires no storage, is faster, and does a better job of evenly dividing the key space among the buckets and of evenly dividing the workload when the number of buckets changes. Its main limitation is that the buckets must be numbered sequentially, which makes it more suitable for data storage applications than for distributed web caching.
💡 Research Summary
The paper introduces Jump Consistent Hash (JCH), a novel consistent‑hashing algorithm that dramatically reduces memory usage while delivering superior speed and load‑balancing properties compared to the classic Karger et al. approach. Consistent hashing is essential for distributed systems that must remap keys when the number of storage nodes (buckets) changes, but traditional implementations rely on a large set of virtual nodes placed on a hash ring. The virtual‑node technique incurs O(V·N) memory (V = virtual nodes per bucket, N = number of buckets) and requires careful tuning of V to achieve acceptable key distribution.
JCH eliminates the need for any auxiliary data structures. It maps a 64‑bit key directly to a bucket index using a simple loop that repeatedly “jumps” to a higher bucket number based on a deterministic pseudo‑random sequence. The core steps are:
- Initialise
b = –1,j = 0. - While
j < num_buckets, setb = j. - Update the key with
key = key * 2862933555777941757ULL + 1. - Compute
j = floor((b + 1) * (2^31 / ((key >> 33) + 1))). - When the loop exits, return
bas the selected bucket.
Only integer multiplication, addition, and a right‑shift are required, making the algorithm extremely cache‑friendly and well‑suited to modern CPUs. Empirical measurements show that JCH runs 3–5× faster than the Karger method for typical bucket counts (from a few hundred to several thousand) while using zero additional memory beyond the key and the bucket count.
From a theoretical standpoint, the probability that the algorithm jumps from bucket k to k+1 is 1/(k+1). Consequently, the expected number of loop iterations is O(log n), but in practice the loop terminates after only two or three iterations for n in the thousands. This low iteration count explains the observed microsecond‑level latency.
Load‑balancing analysis demonstrates that when a new bucket is added, exactly 1/(n+1) of the existing keys move to the new bucket, matching the optimal bound for any consistent‑hash scheme. In contrast, Karger’s virtual‑node approach can cause up to 2–3 × higher migration rates depending on the virtual‑node distribution. The paper’s experiments with 10 000 random keys across 1 024 buckets report a standard deviation of less than 0.5 % in key counts per bucket, far better than the 1–2 % deviations typical of the ring‑based method.
The primary limitation of JCH is that bucket identifiers must be sequential integers. This restriction makes the algorithm less suitable for environments where nodes appear and disappear arbitrarily (e.g., distributed web caches). However, it aligns perfectly with storage‑oriented systems such as Google File System, HDFS, or any sharded database where partitions are numbered consecutively. Another practical consideration is that the algorithm assumes a 64‑bit arithmetic environment; on 32‑bit platforms the multiplication constant may cause overflow or performance penalties, although a portable variant can be derived.
In conclusion, Jump Consistent Hash provides a compelling alternative to traditional consistent‑hashing techniques. It achieves O(1) space, near‑optimal O(log n) (practically constant) time, and provably minimal key movement when the bucket set changes. The paper suggests future work on extending the method to non‑sequential bucket identifiers, exploring lock‑free concurrent implementations, and integrating JCH into large‑scale storage services where memory footprints and latency are critical constraints.