Analyzing noise in autoencoders and deep networks
Autoencoders have emerged as a useful framework for unsupervised learning of internal representations, and a wide variety of apparently conceptually disparate regularization techniques have been proposed to generate useful features. Here we extend existing denoising autoencoders to additionally inject noise before the nonlinearity, and at the hidden unit activations. We show that a wide variety of previous methods, including denoising, contractive, and sparse autoencoders, as well as dropout can be interpreted using this framework. This noise injection framework reaps practical benefits by providing a unified strategy to develop new internal representations by designing the nature of the injected noise. We show that noisy autoencoders outperform denoising autoencoders at the very task of denoising, and are competitive with other single-layer techniques on MNIST, and CIFAR-10. We also show that types of noise other than dropout improve performance in a deep network through sparsifying, decorrelating, and spreading information across representations.
💡 Research Summary
The paper introduces a unified framework called the Noisy Autoencoder (NAE) that extends traditional autoencoders by injecting stochastic perturbations not only at the input layer but also before the non‑linearity (hidden‑unit pre‑activation) and after the non‑linearity (hidden‑unit activation). The authors formalize the noise injection as a triple (ε_I, ε_Z, ε_H) where each component can be additive or multiplicative and can follow arbitrary distributions (e.g., Gaussian, Bernoulli dropout). The encoder computes a corrupted hidden representation ˜h = s_f((W(x⊕ε_I)+b)⊕ε_Z)⊕ε_H, and the decoder reconstructs the input with a linear mapping. Training minimizes the expected reconstruction loss over the noise distribution.
A key theoretical contribution is the analysis of how different noise locations relate to each other. By performing a first‑order Taylor expansion of the encoder, the authors show that small pre‑activation noise ε_Z can be equivalently expressed as a transformed activation‑noise ε_H whose covariance is scaled by the Jacobian diag(s_f′(W x)). Consequently, Gaussian input noise propagates to the hidden layer with covariance W Σ Wᵀ, and dropout can be approximated by a Gaussian with matching mean and variance. This insight allows the authors to rewrite any NAE so that all stochasticity appears only at the hidden activations, simplifying analysis.
Under the simplifying assumptions of a linear decoder, squared‑error loss, and independent per‑neuron noise, the authors marginalize the noise analytically. The expected loss decomposes into the deterministic reconstruction error plus three additive regularization terms: c_I (input‑noise penalty), c_Z (pre‑activation‑noise penalty), and c_H (activation‑noise penalty). Each term has a clear interpretation:
- c_H = ∑_i Var(˜h_i|h)‖w_i‖², which for Gaussian activation noise with variance proportional to the activation magnitude reduces to an L₂ penalty on the hidden activations, encouraging sparsity.
- c_Z ≈ ∑_i Var(˜z_i|z)(s_f′(w_iᵀx)‖w_i‖)², which matches the contractive autoencoder’s Jacobian penalty λ‖J_f(x)‖_F² when ε_Z is Gaussian white noise.
- c_I ≈ ‖W Wᵀ diag(s_f′(W x)) Var(ε_I)‖_F², which for isotropic Gaussian input noise forces the rows of W to become orthogonal, mirroring the orthogonality regularizer used in over‑complete ICA.
Through these derivations the paper demonstrates that denoising autoencoders (DAE), contractive autoencoders (CAE), sparse autoencoders, dropout regularization, and ICA‑style penalties are all special cases of the NAE framework with particular choices of (ε_I, ε_Z, ε_H). This unification clarifies why each method improves generalization: they each impose a different statistical constraint on the hidden representation via noise.
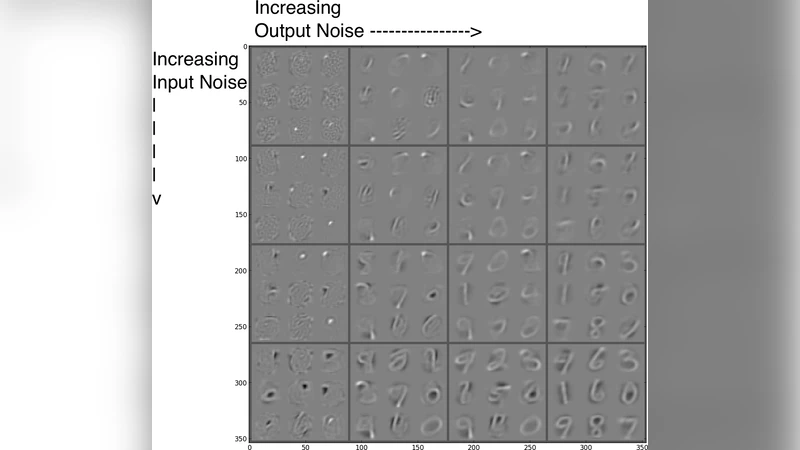
Empirically, the authors evaluate NAEs on three fronts. First, on 12 × 12 natural‑image patches from the van Hateren dataset, a NAE with dropout on hidden activations (p = 0.5) outperforms a standard DAE in reconstruction error (2.5 vs 3.2 average error). Second, on MNIST, they train small NAEs (250 hidden units) with varying levels of input Gaussian noise and hidden‑unit noise (dropout or Gaussian). Visualizing the learned filters shows that input noise yields localized stroke‑like features, while hidden‑unit noise yields more global, digit‑shaped patterns; the combination produces the most discriminative features. Classification experiments using these features as initializations for a multilayer perceptron confirm that models with both input and hidden‑unit noise achieve the lowest test error. Third, on larger MNIST (2000 hidden units) and CIFAR‑10 experiments, NAEs are used for unsupervised pre‑training followed by supervised fine‑tuning. The best MNIST result (138.1 % test error) is obtained with a NAE pre‑trained with dropout (p = 0.25) and fine‑tuned with standard back‑propagation, outperforming comparable DAE, CAE, and dropout‑only baselines. Similar trends are observed on CIFAR‑10, indicating that the benefits of noise injection extend to deeper, more complex tasks.
The paper concludes that injecting noise at multiple stages of an autoencoder provides a flexible toolbox for shaping hidden representations. By selecting the distribution and location of noise, practitioners can simultaneously encourage sparsity, contractivity, orthogonality, and robustness to co‑adaptation. Moreover, the unified view suggests new strategies for stacking unsupervised pre‑training and supervised fine‑tuning: different noise regimes can be tailored to each phase to maximize the utility of the learned features. This work thus bridges several previously disparate regularization techniques under a single probabilistic perspective and opens avenues for designing novel noise‑based regularizers in deep learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment