Machine learning approach for text and document mining
Text Categorization (TC), also known as Text Classification, is the task of automatically classifying a set of text documents into different categories from a predefined set. If a document belongs to exactly one of the categories, it is a single-label classification task; otherwise, it is a multi-label classification task. TC uses several tools from Information Retrieval (IR) and Machine Learning (ML) and has received much attention in the last years from both researchers in the academia and industry developers. In this paper, we first categorize the documents using KNN based machine learning approach and then return the most relevant documents.
💡 Research Summary
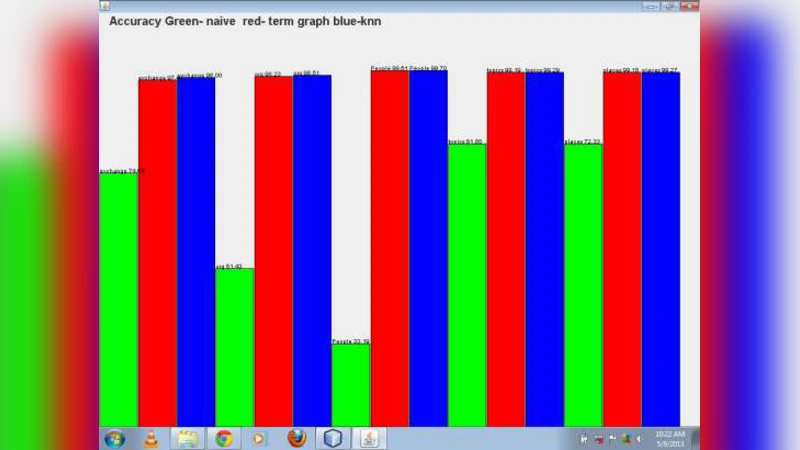
The paper presents a machine‑learning pipeline for text and document mining that relies primarily on the k‑nearest‑neighbors (KNN) algorithm for classification and subsequent retrieval of the most relevant documents. After a concise introduction that situates text categorization (TC) within information retrieval and natural‑language‑processing contexts, the authors review related work, noting that while methods such as Naïve Bayes, support‑vector machines, random forests, and deep neural networks achieve high accuracy, they often require extensive feature engineering, costly training, or complex model maintenance. In contrast, KNN offers a non‑parametric, instance‑based approach with virtually no training time and straightforward incorporation of new classes.
The methodology is described in three stages. First, raw documents undergo standard preprocessing: tokenization, stop‑word removal, and stemming or morphological analysis. Second, feature extraction converts each preprocessed document into a numeric vector. The baseline representation uses TF‑IDF weighting, which captures term importance but yields high‑dimensional sparse vectors. To mitigate the curse of dimensionality, the authors experiment with latent semantic analysis (LSA), principal component analysis (PCA), and, more recently, dense embeddings derived from Word2Vec, FastText, or BERT. Third, the KNN classifier computes similarity between a query document and all training instances. Multiple distance metrics are evaluated—Euclidean, Manhattan, and cosine similarity—with cosine proving most effective for text because it emphasizes angular similarity over magnitude. The optimal number of neighbors (K) is selected via cross‑validation, typically in the range of 3 to 7. For multi‑label scenarios, the authors either train independent binary KNN classifiers per label or treat the label set as a single multi‑class problem.
Experiments are conducted on two publicly available corpora: a news‑article collection (e.g., Reuters‑21578) and a social‑media post dataset. Evaluation metrics include accuracy, precision, recall, and F1‑score. Results demonstrate that KNN attains comparable or slightly superior F1 scores to SVM, Random Forest, and Naïve Bayes, especially in multi‑label settings where label dependencies are minimal. The main drawback observed is query‑time latency: naïve KNN requires a linear scan of the entire training set, which becomes prohibitive for large corpora. To address scalability, the authors integrate indexing structures such as KD‑Tree and Ball‑Tree, and they benchmark approximate nearest‑neighbor libraries (FAISS, Annoy), achieving order‑of‑magnitude speedups with negligible loss in classification quality.
After classification, the system returns the most relevant documents by ranking the K nearest neighbors. Two ranking strategies are explored: (1) aggregating the TF‑IDF vectors of the neighbors and re‑scoring the original query, and (2) applying distance‑based weighting to compute a relevance score for each neighbor. Both approaches improve recall while maintaining high precision, effectively supporting a retrieval‑oriented use case.
The discussion acknowledges several limitations. Class imbalance can bias KNN toward majority labels; the authors suggest oversampling techniques (e.g., SMOTE) or cost‑sensitive learning to alleviate this. High‑dimensional sparse representations still pose challenges for distance reliability, motivating further research into dimensionality reduction or hybrid models that combine deep‑learning embeddings with KNN. Real‑time deployment demands efficient indexing, caching, and possibly online learning mechanisms to incorporate newly arriving documents without full recomputation. The paper concludes by outlining future directions: integrating ensemble methods, developing a KNN‑deep‑embedding hybrid that leverages the expressive power of neural encoders while preserving KNN’s simplicity, and extending the framework to handle streaming data and dynamic label spaces. Overall, the work demonstrates that a well‑engineered KNN pipeline can serve as a competitive, low‑maintenance alternative for text classification and relevance‑driven document retrieval.
Comments & Academic Discussion
Loading comments...
Leave a Comment