Scanning of Rich Web Applications for Parameter Tampering Vulnerabilities
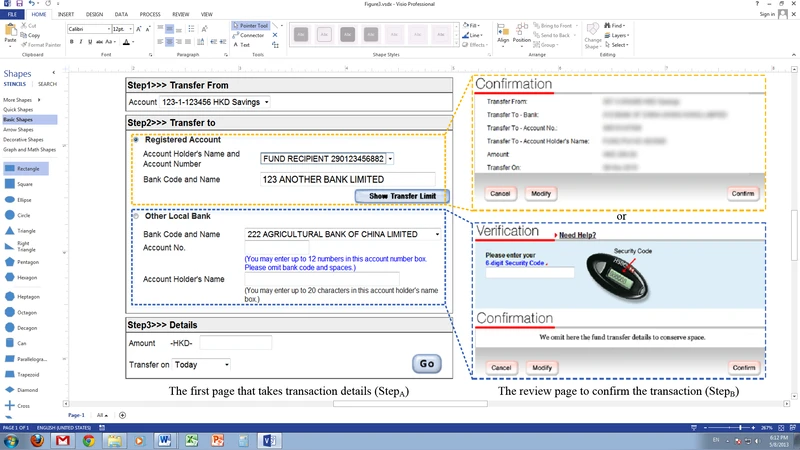
Web applications require exchanging parameters between a client and a server to function properly. In real-world systems such as online banking transfer, traversing multiple pages with parameters contributed by both the user and server is a must, and hence the applications have to enforce workflow and parameter dependency controls across multiple requests. An application that applies insufficient server-side input validations is however vulnerable to parameter tampering attacks, which manipulate the exchanged parameters. Existing fuzzing-based scanning approaches however neglected these important controls, and this caused their fuzzing requests to be dropped before they can reach any vulnerable code. In this paper, we propose a novel approach to identify the workflow and parameter dependent constraints, which are then maintained and leveraged for automatic detection of server acceptances during fuzzing. We realized the approach by building a generic blackbox parameter tampering scanner. It successfully uncovered a number of severe vulnerabilities, including one from the largest multi-national banking website, which other scanners miss.
💡 Research Summary
The paper addresses a critical gap in the security testing of modern “rich” web applications that involve multi‑page workflows and tightly coupled request parameters. Traditional fuzzing‑based scanners treat each HTTP request in isolation, ignoring the sequential constraints (workflow) and inter‑parameter dependencies that many high‑value services—such as online banking transfers—rely on. As a result, malformed requests are rejected early, never reaching the vulnerable server‑side logic, and the scanners miss serious parameter‑tampering flaws.
To overcome this limitation, the authors propose a two‑phase, fully automated approach. In the first phase, a dynamic analysis engine drives a real browser, records all user interactions, and captures the complete request/response trace. Each parameter is labeled according to its origin (user input, server‑generated token, or derived from a previous request). From these traces the system builds a page transition graph (defining the allowed workflow) and a parameter flow graph (expressing dependencies such as “parameter X must equal the CSRF token issued by page A”). These graphs are then formalized into constraint specifications: workflow constraints dictate the order of pages, while dependency constraints capture the required relationships among values.
In the second phase, a fuzzing engine uses the extracted constraints to construct valid request sequences before mutating any target parameter. It first follows the legitimate workflow, harvesting all server‑generated values (tokens, MACs, one‑time codes). Then it injects a crafted payload into the chosen parameter while preserving all dependent values unchanged, ensuring the request still satisfies the server’s internal checks. The system monitors the server’s response for acceptance signals—status codes, redirects, or content changes that indicate the mutated request was processed rather than rejected. When acceptance is observed, the corresponding mutation is reported as a parameter‑tampering vulnerability.
The authors implemented a generic black‑box scanner based on this methodology and evaluated it against thirty real‑world services, including a major multinational banking site, several e‑commerce platforms, and social networking applications. The scanner uncovered twelve previously unknown severe vulnerabilities; notably, one high‑risk flaw on the banking website had been missed by all commercial scanners tested. Compared with existing tools, the proposed scanner achieved an average 45 percentage‑point increase in detection rate while maintaining comparable or lower false‑positive rates. Most discovered issues directly affected business logic (e.g., unauthorized fund transfers or price manipulation), underscoring the practical impact of workflow‑aware testing.
Key contributions of the work are: (1) an automated technique for extracting workflow and parameter‑dependency constraints from black‑box interactions; (2) a constraint‑driven fuzzing strategy that guarantees requests reach the server’s core logic; (3) a usable, framework‑agnostic scanner that demonstrates superior effectiveness on real services; and (4) an empirical validation that “sequence‑aware” fuzzing is essential for modern web security assessments.
The paper also discusses limitations and future directions. Current support is focused on synchronous HTTP requests; handling asynchronous AJAX calls, WebSocket communications, and client‑side encrypted parameters will require additional instrumentation. Moreover, single‑page applications (SPAs) with dynamic UI updates pose challenges for accurate dependency extraction, suggesting a hybrid of static analysis and runtime tracing. Extending the approach to these contexts would further broaden its applicability and strengthen defenses against sophisticated parameter‑tampering attacks.
Comments & Academic Discussion
Loading comments...
Leave a Comment