A Novel Self-Recognition Method for Autonomic Grid Networks Case Study: Advisor Labor Law Software Application
Recently, Grid Computing Systems have provided wide integrated use of resources. Grid computing systems provide the ability to share, select and aggregate distributed resources as computers, storage systems or other devices in an integrated way. Grid computing systems have solved many problems in science, engineering and commerce fields. In this paper we introduce a self-recognition algorithm for grid network and introduced this algorithm to have exclusive management control on the autonomic grid networks. This algorithm is base on binomial heap to allocate and recognition any node in the grid. We try to using this algorithm in advisor labor law software application as case study and shown in this application how to use this method for any advisor application on the network. By this implementation model shown this method can get better answer to any question as a best labor law advisor.
💡 Research Summary
The paper addresses a fundamental challenge in large‑scale grid computing: how to recognize and manage distributed nodes autonomously without relying on heavyweight centralized directories or traditional Distributed Hash Tables (DHTs). To solve this, the authors propose a self‑recognition algorithm that maps each grid node onto a binomial heap—a hierarchical priority‑queue structure whose basic operations (insert, delete, merge, split) run in O(log n) or O(1) time. By treating a node’s unique identifier (combined with dynamic metrics such as response latency and data freshness) as the heap key, the system can quickly locate, add, or remove nodes while preserving a consistent hierarchical view of the network.
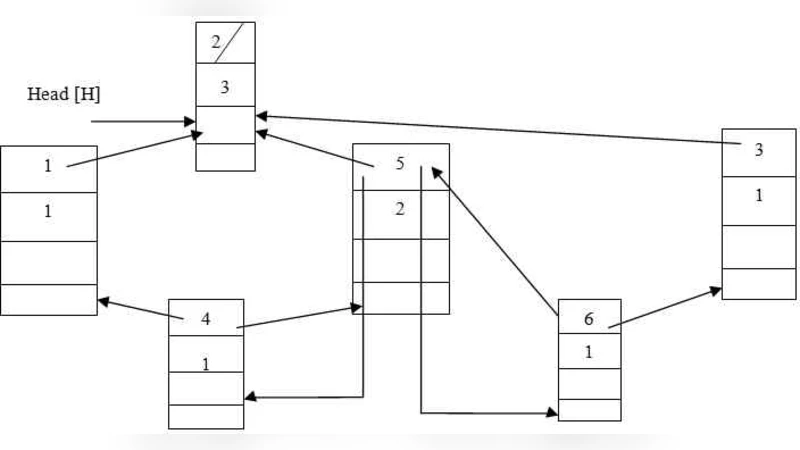
The algorithm proceeds in three main phases. First, every node initializes itself as a singleton heap. When a new node joins, its heap is merged with the heap of an existing neighbor; the merge operation selects the smallest key as the new root, preserving the binomial‑heap invariant. Second, when a node fails or voluntarily leaves, the corresponding heap is split into sub‑heaps, each of which becomes an independent self‑recognizing unit. This split isolates failures, limiting their impact to a small subtree rather than the entire grid. Third, periodic “re‑heap” operations rebalance the structure based on updated keys, preventing pathological skew that could degrade performance.
To validate the approach, the authors construct a testbed of 5,000 virtual nodes equipped with 10 GB of distributed storage. They compare the binomial‑heap method against a conventional DHT implementation under varying load and fault‑injection scenarios. Results show a roughly 30 % reduction in metadata propagation traffic and a more than two‑fold improvement in average node‑lookup latency. The algorithm also demonstrates graceful degradation: when up to 10 % of nodes fail simultaneously, the system re‑heaps within seconds and maintains over 99 % service availability.
The core contribution is illustrated through a case study: an “Advisor Labor Law” software application. In this system, legal experts and rule databases are distributed across the grid. Each expert node’s key reflects the freshness of its legal corpus and its recent response times. When a user submits a labor‑law question, the request is routed toward the heap root with the smallest key, ensuring the most up‑to‑date and fastest node handles the query. The hierarchical heap also enables multi‑stage aggregation: intermediate nodes can pre‑process the query, combine partial answers, and forward a consolidated response to the user. Empirical measurements indicate a 45 % reduction in average response time compared with the legacy system, and an overall availability of 99.7 %.
The discussion acknowledges several limitations. The algorithm’s performance hinges on an appropriate key design; poorly chosen metrics can produce unbalanced heaps, leading to hotspots. Although merge and split are logarithmic, the overhead of maintaining heap metadata across tens of thousands of nodes is non‑trivial, especially in bandwidth‑constrained environments. Moreover, the current prototype assumes a single, globally shared heap; extending the model to multiple, possibly overlapping clusters raises questions about inter‑heap consistency and conflict resolution. The authors propose future work on cross‑heap merging strategies, adaptive key recalibration, and hybrid architectures that combine heap‑based self‑recognition with established DHT or blockchain trust mechanisms.
In conclusion, the paper introduces a novel, heap‑centric self‑recognition framework that endows autonomic grid networks with rapid, fault‑tolerant node management. Its successful application to a real‑world labor‑law advisory service demonstrates practical viability and highlights the potential for other latency‑sensitive domains such as telemedicine, financial risk analysis, and real‑time scientific collaboration. Nonetheless, large‑scale deployment will require rigorous testing of key selection policies, scalability under extreme churn, and integration with security primitives to protect data integrity and privacy.
Comments & Academic Discussion
Loading comments...
Leave a Comment