Asymmetric LSH (ALSH) for Sublinear Time Maximum Inner Product Search (MIPS)
We present the first provably sublinear time algorithm for approximate \emph{Maximum Inner Product Search} (MIPS). Our proposal is also the first hashing algorithm for searching with (un-normalized) inner product as the underlying similarity measure.…
Authors: Anshumali Shrivastava, Ping Li
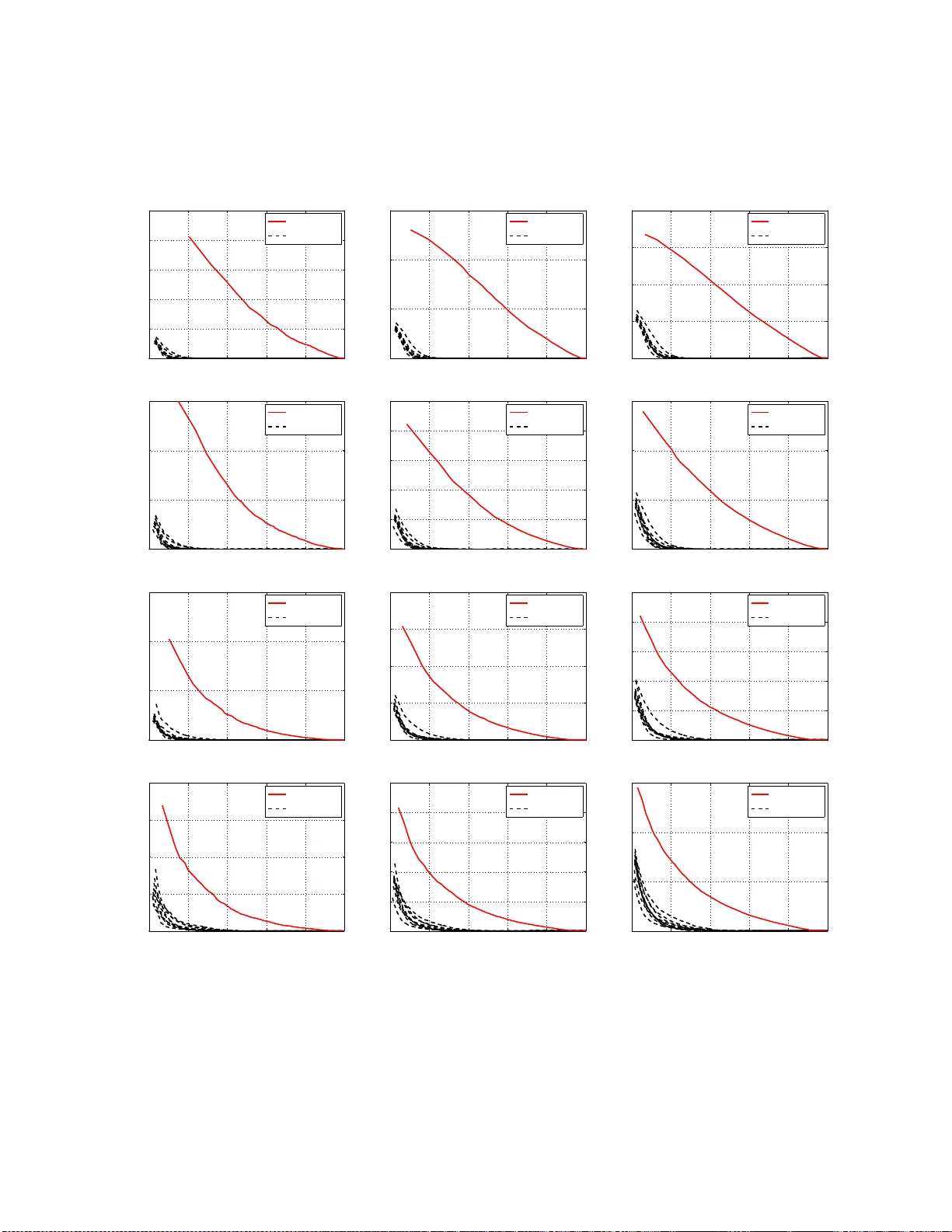
Asymmetric LSH (ALSH) for Sublinear T ime Maximum Inner Product Search (MIPS) Anshumali Shriv astav a Department of Computer Science Computer and Information Science Cornell Uni versity Ithaca, NY 14853, USA anshu@cs.c ornell.edu Ping Li Department of Statistics and Biostatisti cs Department of Computer Science Rutgers Univ ersity Piscataw ay , NJ 08854, USA pingli@sta t.rutgers. edu Abstract W e 1 present the first provably sublinear time algorithm for approximate Maximum Inner Pr oduct Sear ch (MIPS). Our propo sal is also th e first hashing algorith m for sear ching with ( un-no rmalized) in- ner p roduct as the u nderly ing similar ity measur e. Finding ha shing schemes for MIPS was considered hard. W e formally sho w that the e xisting Locality Sensitiv e Hashing (LSH) frame work is insuf ficient fo r solving MIPS, and then we extend the existing LSH framework to allow asymm etric h ashing schemes. Our proposal is based on an interesting mathematical phenomenon in which inner products, after in- depend ent asymmetr ic tr ansforma tions, can be converted in to the prob lem o f appro ximate near n eigh- bor search . This key o bservation makes efficient sublinear hashing sch eme for MI PS po ssible. In the extended asymm etric LSH (ALSH) framew ork, we p rovide an explicit construction o f prov ably fast hashing scheme fo r MIPS. The proposed construction and the extended LSH framework cou ld be of indepen dent theoretical interest. Our prop osed algorithm is simple and easy to implemen t. W e evaluate the metho d, for retrieving inner pro ducts, in the collaborative filtering task o f item recomm endations on Netflix and Movielens datasets. 1 Initially submitted in Feb . 2014. 1 1 Introd uction and Motivation The focus of this pap er is on th e pr oblem of Maximum I nner Pr oduct S ear c h ( MIPS) . I n th is pr oblem, we are gi v en a gi ant data v ector collec tion S of size N , wher e S ⊂ R D , and a giv en query poi nt q ∈ R D . W e ar e interes ted in searching for p ∈ S which maximizes (or approxima tely maximizes) the inner pr oduct q T p . Formally , we are interested in efficien tly computing p = arg max x ∈S q T x (1) The MIPS proble m is related to the problem of near neighb or sear ch (NNS) , which instead requires com- puting p = arg min x ∈S q − x 2 2 = arg min x ∈S ( x 2 2 − 2 q T x ) (2) These tw o problems are equ i v alent if the norm o f e v ery ele ment x ∈ S is constant. N ote that the value of the no rm q 2 has no effec t as it is a constant through out and does not cha nge the ident ity of arg max or arg min . There are many sc enario s in which MIPS arises naturally a t places where the norms of the ele - ments in S ha ve very significant vari ations [17] and can not be controlled . As a consequ ence, exi sting fast algori thms for the proble m of appro ximate NNS can not be direct ly used for solving MIPS. Here we list a number of p ractical scen arios where the MIPS problem is solv ed as a subroutine : ( i) recommend er sy stem, (ii) larg e-scale object detection wit h D PM, (iii) structural S VM, and (iv) m ulti-cl ass label predi ction. 1.1 Recommender Systems Recommender s ystems are often based o n coll aborati ve filtering whi ch reli es on p ast be ha vior of u sers, e.g., past pu rchases and r atings. Latent factor mode lling based o n matrix f acto rizatio n [19] is a popular app roach for solv ing collabo rati ve filtering. In a typical matrix f actori zation model, a user i is associated with a latent user cha racteris tic vector u i , an d simila rly , an item j is associated with a latent item c haracte ristic vector v j . The rating r i,j of ite m j by us er i is m odeled as the inner pr oduct between the corres pondin g characte ristic vec tors. A po pular gener alizatio n of this f rame work, which combine s neighborh ood information with laten t fact or approach [18], leads to the follo wing model: r i,j = µ + b i + b j + u T i v j (3) where µ is the o ver all consta nt mean rati ng va lue, b i and b j are u ser and item biases, resp ecti v ely . Note tha t Eq. (3) can also be w ritten as r i,j = µ + [ u i ; b i ; 1 ] T [ v j ; 1; b j ] , where the form [ x ; y ] is the concaten ation o f vec tors x and y . Recently , [ 6] sh o wed that a simple co mputation of u i and v j based on nai ve SVD of the sparse ratin g matrix outperf orms e xistin g model s, in cludin g the neighborho od model, in recommending t op-rank ed items. In this sett ing, gi ven a us er i and the corre spond ing learned latent ve ctor u i finding the rig ht item j , to recommend to this user , in volv es computing j = arg max j ′ r i,j ′ = arg max j ′ u T i v j ′ (4) which is an instance of the standard MIPS problem. It should be noted that we do not ha ve cont rol ov er the norm of the learned charac teristic vecto r , i.e., v j 2 , which often has a wide range in pract ice [17 ]. If the re are N items to recommend, so lving (4) requir es computing N inner pr oducts . Reco mmendatio n systems are typical ly deploye d in on-line applicatio n o ve r w eb where the number N is huge. A brute force linear scan ov er all items, for comput ing arg max , would be prohibi ti vely expen si ve. 2 1.2 Large-S cale Object Detection w ith DPM Deformable Part Mod el (DPM) based represent ation of images is the state- of-the- art in object detection tasks [11]. In DPM mod el, first a s et of part filters are l earned from the train dataset. During detection, these learned filte r activ ati ons ov er va rious p atches of the test i mage are use d to score the test image. The acti v atio n of a fi lter on an image patch is an inner product between them. T ypically , the number of possible filters ar e lar ge (e.g., millions) and so sco ring the tes t image is c ostly . V ery recently , it w as sho wn that scorin g based on ly on filters with high acti v atio ns performs well in prac tice [10]. Identif ying filters, from a lar ge collec tion of possib le filters, ha ving high ac ti v ations on a gi ve n image pat ch requires computi ng top inner products. Consequ ently , an ef fi cient solution to t he MIPS p roblem will benefit l ar ge s cale object detect ions based on DPM. 1.3 Structur al SVM Structura l S VM, with cuttin g plane trainin g [16], is one of the popular methods for learning over s tructur ed data. The m ost expensi ve step with cutting plane iteration is the call to t he sep aration ora cle whic h iden tifies the most violated constraint . In particular , gi v en the current SVM estimate w , th e separation oracle computes ˆ y i = arg max ˆ y ∈ Y ∆ ( y i , ˆ y ) + w T Ψ ( x i , ˆ y ) (5) where Ψ ( x i , ˆ y ) is the join t fea ture representat ion of d ata w ith the possible la bel ˆ y and ∆ ( y i , ˆ y ) is the loss functi on. Clearly , this is a gain an instance of the MIPS problem. This step is expensi ve in that the number of possible elemen ts, i.e., the size of Y , is possibly e xpon ential. Many heuristi cs were deployed to hopefull y impro ve the computation of arg max in (5), for instance caching [16]. An ef ficient MIPS routine can make structu ral SVM faste r and m ore scal able. 1.4 Multi-Class Label Pred iction The models for multi-class S VM (or logisti c regres sion) learn a weight vect or w i for each of the class label i . After the weigh ts are learned, gi ven a new test d ata vector x test , predicting its class label is basically an MIPS proble m: y test = arg max i ∈L x T test w i (6) where L is the set o f possib le class labels. Note t hat the norms of t he weigh t vector s w i 2 are not co nstant . The si ze, L , of the set of clas s labels di ff ers in applicatio ns. Classifyi ng with la r ge number o f po ssi- ble cla ss labels is c ommon in fine grained objec t classificatio n, for in stance , pred iction task with 1 00,000 classe s [10] (i.e., L = 1 00 , 000 ). C omputin g such hig h-dimens ional v ector mu ltiplica tions f or pr edictin g the class label of a singl e instan ce can be exp ensi v e in, for exa mple, user-f acin g applicat ions. 1.5 The Need for Ha shing Inner Prod ucts Recall t he MIPS problem is t o find x ∈ S which maximizes the inner produ ct between x and the g i ven query q , i.e. max x ∈S q T x . A brute for ce scan of al l elements of S can be prohibiti v ely costly in ap plicatio ns which deal with massi ve data and care abo ut the latenc y (e.g., search). Owing t o the significan ce of t he p roblem, there was an attempt to ef ficientl y solve MIPS by making use of tree da ta structur e combin ed with branch and bound s pace partition ing tec hnique [27, 17] s imilar to k-d trees [12]. That meth od d id not come with prov able runtime guarante es. In fact, it is a lso w ell-kno wn that techniques based on space partition ing (such as k-d trees) suf fer from the curse of dimensionali ty . For exa mple, it was sh o wn in [30] (both empirically and theor etically ) that all current techniq ues (base d on space partitio ning) deg rade to linear search, ev en for dimensi ons as small as 10 or 20. 3 Locality Sensiti ve Hashing (LSH) [15] base d rand omized techniq ues are common and succe ssful in indust rial prac tice for efficie ntly s olving NNS ( near neighbor sea r c h ). Unlik e space partitionin g technique s, both the runni ng time as well as the accurac y guarantee of LSH based NNS are in a wa y indepe ndent of the dimensio nality of the data. This mak es LS H suitable fo r lar ge scale processing syste m deali ng with ultra- high dimensio nal data sets which a re common these d ays. Furthermore, LS H based sc hemes are massiv ely paralle lizable , whic h makes them ideal for modern “Big” datase ts. The prime focus of this paper will be on ef ficient hashin g based algorith ms for MIPS, which do not suf fer from the curse of dimensiona lity . 1.6 Our Contrib utions W e dev elop Asymmetric LSH (ALSH) , an extende d LSH scheme for efficient ly solvin g the approximat e MIPS probl em. Finding hashing based algor ithms for MIP S was co nsidere d hard [2 7, 17]. In this pape r , we for mally sho w that this is inde ed the cas e with the current frame work o f LSH, a nd there c an not e xist any LSH for solving MIPS. Despite th is negati ve result, we sho w that it is po ssible to relax the cu rrent LSH frame work to allo w asymmetric h ash functions whic h c an ef ficiently solve MIPS. This generalizat ion comes with no cost and the ext ended framewo rk inherits all the theoreti cal guaran tees of LSH. Our constr uction of asymmetric LS H is ba sed on an int erestin g mathematical ph enomeno n that the orig- inal MIPS p roblem, afte r asymmetr ic transfo rmations , reduces t o the problem of approximate near neighbor search . Based on this ke y observ ation, we show an explici t constructi on of asymmet ric hash functi on, leadin g to the fi rst prov ab ly sublin ear query time algo rithm for approxi mate similarit y search w ith (un- normaliz ed) inner pro duct as the similarity . The con structi on of asymmetric has h fun ction and the n e w LSH frame work cou ld be of independe nt theoretical interest. Experiment ally , we e v aluate our algorithm for the task o f recommendin g top-r ank ed items, under the collab orati v e fi ltering frame work, with the proposed asymmetric hashing scheme on N etflix and Movielens datase ts. Our e v alu ations supp ort the theoretical resul ts and clearly sho w that the prop osed asymmetric hash functi on i s superior for retrie ving i nner product s, compared to t he well kno wn hash function based on p- stable distrib ution for L2 norm [9 ] (which is also part of standard L SH package [2]). This is not surprising becaus e L 2 distan ces and inner product s may ha ve ve ry diff erent ordering s. 2 Backgrou nd 2.1 Locality Sensitive Hashing (LSH) Approxima te ve rsions of the near neighbor sea rch pro blem [ 15] w ere propose d to break the linear query time bottl eneck. The follo wing formulation is commonly adopted. Definition: ( c -Approx imate Near Neighbor or c -NN ) Given a set of po ints in a D -dimensional space R D , and par ameter s S 0 > 0 , δ > 0 , construct a data structur e whi ch, giv en any query point q , does the following with pr obability 1 − δ : if ther e ex ists an S 0 -near neig hbor of q in P , it r eport s some cS 0 -near neighb or of q in P . The usua l notion of S 0 -near neig hbor is in terms o f distance . Since we de al with similari ties, we can equi v alen tly d efine S 0 -near neighbor of point q as a point p w ith S im ( q , p ) ≥ S 0 , w here S im is the similarity functi on of intere st. The popular techn ique for c -NN u ses the unde rlying theory of Loca lity Sen sitive Hashi ng (LSH) [15]. LSH is a family of fun ctions, with the property that more similar input objects in the domain of these functi ons ha ve a high er prob ability of colliding in the range space than les s simil ar ones. In formal terms, 4 consid er S a family of hash func tions mapping R D to some set I . Definition: (Locality Sensi ti ve Has hing (LSH)) A family H is call ed ( S 0 , cS 0 , p 1 , p 2 ) -sens itive if, for any two point x, y ∈ R D , h chos en uniformly fr om H satisfi es the following : • if S im ( x, y ) ≥ S 0 then P r H ( h ( x ) = h ( y )) ≥ p 1 • if S im ( x, y ) ≤ cS 0 then P r H ( h ( x ) = h ( y )) ≤ p 2 F or ef ficie nt appr oximate near est neighbor sear c h, p 1 > p 2 and c < 1 is needed. 2.2 Fast Simil arity Sear ch with LSH In a typic al task of simil arity se arch, we are gi ven a query q , and our a im is to find x ∈ S with high v alue of S im ( q , x ) . LSH provid es a clean mechanism o f creating has h ta bles [2]. T he idea is to concatenate K indepe ndent hash funct ions to create a meta-hash functi on of the form B l ( x ) = [ h 1 ( x ) ; h 2 ( x ) ; ... ; h K ( x )] (7) where h i , i = { 1 , 2 , ..., K } are K indep endent hash func tions sampl ed from the LSH family . The LSH algori thm needs L indepe ndent meta hash func tions B l ( x ) , l = 1 , 2 , ..., L . • Pr e-pr ocessing Step: Durin g preproc essing, w e assign x i ∈ S to the buck et B l ( x i ) in the hash table l , for l = 1 , 2 , ..., L . • Querying Step: Give n a qu ery q , we retrie v e union of all elements from b uck ets B l ( q ) , where the union is tak en over all has h tables l , for l = 1 , 2 , ..., L . The b ucket B l ( q ) contai ns elements x i ∈ S whose K diff erent hash v alues collide with that of the query . By the LSH propert y of the hash func tion, these elements ha ve highe r pro babilit y of bein g si milar to the query q compared to a rando m point. This p robabil ity valu e can be tuned by choosi ng approp riate va lue for paramete rs K and L . Optimal ch oices lead to fast query time algorithm: Fac t 1 : G i ven a family of ( S 0 , cS 0 , p 1 , p 2 ) -sensiti ve hash functions, one can construct a d ata structure for c -NN with O ( n ρ log n ) query time and space O ( n 1 + ρ ) , where ρ = log p 1 log p 2 < 1 . LSH trades of f quer y time with extra (one time) prepr ocessin g cost an d sp ace. Existen ce of an LSH family translat es into prov ably sublinear quer y time algorithm f or c- NN problems. It sh ould b e noted that the wo rst cas e query time for LSH is only dependen t on ρ and n . Thus, LSH b ased near nei ghbor search in a sense does not suffer from the curse of dimensionali ty . This makes LS H a widely popul ar techniq ue in indust rial practi ce [14, 25, 7]. 2.3 LSH f or L2 distance [9] pre sented a n ov el LSH family for all L p ( p ∈ ( 0 , 2 ] ) distances . In particular , when p = 2 , this sch eme pro vides an LS H family for L 2 distan ces. Formally , gi ven a fix ed number r , we choose a r andom vecto r a with each compone nt generat ed from i.i.d. normal, i.e., a i ∼ N ( 0 , 1 ) , and a scalar b generated uniformly at random from [ 0 , r ] . The hash function is defined as: h L 2 a,b ( x ) = a T x + b r (8) 5 where is the floor operation. The collisio n probabi lity under this scheme can be sho wn to be P r ( h L 2 a,b ( x ) = h L 2 a,b ( y )) = F r ( d ) , (9) F r ( d ) = 1 − 2Φ ( − r d ) − 2 √ 2 π ( r d ) 1 − e −( r / d ) 2 / 2 (10) where Φ ( x ) = ∫ x −∞ 1 √ 2 π e − x 2 2 dx is the cumulati v e density functio n (cdf) of standard normal distrib ution and d = x − y 2 is the E uclidea n distanc e between the v ectors x and y . This co llision proba bility F r ( d ) is a monoton ically decre asing fu nction o f the dis tance d and hence h L 2 a,b is an LSH for L 2 distanc es. This scheme is also the part of LSH packa ge [2]. Here r is a parameter which can be tuned. As arg ued previ ously , x − y 2 = ( x 2 2 + y 2 2 − 2 x T y ) is not mo notonic in the inner product x T y unless the gi ve n data has a cons tant norm. Hence, h L 2 a,b is not suitable for MIPS. In Section 4, we will exp erimental ly show tha t our proposed method compares fav orably to h L 2 a,b hash function for MIPS. V ery recently [2 3] re ported an improv ement o f th is well-kn o wn hashin g scheme when the data can be normaliz ed (for e xample, when x and y both ha v e uni t L 2 norm). Howe ver , in our problem se tting, since the data can not be normali zed, we can not tak e advant age of the new resul ts of [23 ], at the moment. 3 Hashing f or MIPS 3.1 A Negative Result W e first show that, under the current L SH framew ork, it is impossible to obtain a locality sensiti ve hashin g for MIPS. In [2 7, 17], the auth ors also a rg ued that finding localit y sensiti ve hashin g for inne r prod ucts could be hard, bu t to the best of our kno wledge we hav e not seen a formal proof. Theor em 1 Ther e can not e xist any LSH family for MIPS. Proof: Suppo se, ther e exists such ha sh function h . F or un-normali zed inner pr odu cts the self similarit y of a point x with itself is S im ( x, x ) = x T x = x 2 2 and ther e m ay ex ist anothe r points y , such that S i m ( x, y ) = y T x > x 2 2 + M , fo r any constant M . U nder any single randomiz ed hash function h , the collision pr oba bility of the eve nt { h ( x ) = h ( x )} is always 1. So if h is an LSH for inner pr odu ct th en the even t { h ( x ) = h ( y )} should have higher pr obabi lity compar ed to the event { h ( x ) = h ( x )} (which a lr ead y h as pr oba bility 1). This is n ot po ssible because the pr obability can not be gr eater th an 1 . Note that we can alway s c hoose y with S im ( x, y ) = S 0 + δ > S 0 and cS 0 > S im ( x, x ) ∀ S 0 and ∀ c < 1 . This complete s the pr oof . ◻ Note that in [4] it was sho wn that we can not hav e a ha sh f unction where the collis ion pr obabili ty is equal to the inner pro duct, becaus e “1 - inn er produ ct” does not s atisfy the tri angle inequ ality . This does not totally eliminates the exis tence of L SH. For instance, und er L2Hash , the collisio n probab ility is a mono tonic functi on of distan ce and not the distance itself. 3.2 Our Pr oposal: Asymmetric LS H (ALSH) The basic idea of LSH is proba bilistic b ucketing an d it is more ge neral than th e requirement of having a single hash functi on h . In the LSH a lgorithm (S ection 2.2), we us e the same hash function h for bo th the prepro cessing step and the query step. W e assign buc kets in the hash table to all the candidates x ∈ S us ing h . W e use the same h on the q uery q to identi fy rele v ant b uck ets. The on ly requ irement for the proof, of Fact 1, to work is th at th e collision pro bability of the eve nt { h ( q ) = h ( x )} inc reases with the similarity S im ( q , x ) . The the ory [13] behind L SH still works if w e use hash function h 1 for preproces sing x ∈ S and 6 a dif ferent hash function h 2 for queryin g, as long as the probab ility of the ev ent { h 2 ( q ) = h 1 ( x )} increase s with S im ( q , x ) , and there exist p 1 and p 2 with the req uired prop erty . T he traditiona l LS H definition does not all o w this asy mmetry b ut it is not a re quired condi tion in the proo f. For this reason, we can relax the definitio n of c -NN without loosin g runtime guaran tees. As the first step, we define a modified locality sensiti v e hashing, in a slightly d if ferent form which will be useful later . Definition: ( Asymmetric Locality S ensiti ve Hashing (ALSH)) A family H , along with the two vector func- tions Q ∶ R D ↦ R D ′ ( Query T ransf ormation ) and P ∶ R D ↦ R D ′ ( Pr epro cessing T ransf ormation ), is called ( S 0 , cS 0 , p 1 , p 2 ) -sens iti ve if for a giv en c -NN instance w ith query q , and the hash functio n h chosen unifor mly from H satisfies the follo wing: • if S im ( q , x ) ≥ S 0 then P r H ( h ( Q ( q ))) = h ( P ( x ))) ≥ p 1 • if S im ( q , x ) ≤ cS 0 then P r H ( h ( Q ( q )) = h ( P ( x ))) ≤ p 2 Here x is an y point in the collection S . When Q ( x ) = P ( x ) = x , we recov er the va nilla LSH definition with h ( . ) as the required hash functio n. Coming back to the problem of M IPS, if Q and P are diff erent, th e ev ent { h ( Q ( x ) ) = h ( P ( x ))} will not ha ve probabil ity equal to 1 in general . Thus, Q ≠ P can cou nter the fact that self similarity is not hig hest with inner produ cts. W e jus t need the probabilit y of the ne w colli sion ev ent { h ( Q ( q )) = h ( P ( y ))} to satisfy the conditi ons of Definition of c - NN for S im ( q , y ) = q T y . Note that the query t ransforma tion Q is only applied on the q uery and the pre-process ing transformat ion P is a pplied to x ∈ S while creating hash tables . It is this asymmetry whic h will allo w us to solv e MIPS e ffici ently . In Section 3 .3, we explic itly sho w a co nstruc tion (an d hence the existenc e) of asymmetric loca lity sensiti v e hash func tion for solv ing MIPS. The source of randomiza tion h for both q and x ∈ S is th e same. Formally , it is not difficu lt to show a res ult analogous to Fact 1. Theor em 2 Given a family of hash functio n H and the associa ted query an d p r epr ocessi ng transfor mations P and Q , whic h is ( S 0 , cS 0 , p 1 , p 2 ) -sensi tive, one can con struct a data stru ctur e for c -NN with O ( n ρ log n ) query time and space O ( n 1 + ρ ) , wher e ρ = log p 1 log p 2 . Proof: Use the standar d LSH pr ocedur e (Section 2.2) with a slight modi ficatio n. While pr epr ocessi ng, we assign x i to b uc ket B l ( P ( x i )) in tab le l . While querying with query q , w e r etr ieve element s fr om b uc k et B l ( Q ( q )) in the hash ta ble l . B y definiti on of asy mmetric LSH, th e pr obab ility of r etrieving an e lement, under t his modi fied s cheme , follo ws the sa me e xpr ession as in the origin al LSH. T he pr oof can be co mpleted by ex act same ar gument s used for pr ov ing F act 1 (See [13] for detai ls). 3.3 Fr om MIPS to Near Neighbor Search (NNS) W ith out loss of generalit y , we can assume that f or the problem of MIPS the query q is normalized, i.e., q 2 = 1 , be cause i n co mputing p = a rg m ax x ∈S q T x the ar gmax is ind epende nt of q 2 . In part icular , we can choose to let U < 1 be a number such that x i 2 ≤ U < 1 , ∀ x i ∈ S (11) If this is n ot the case the n during the one time pre process ing we can alw ays di vide all x i s by max x i ∈S ∣∣ x i ∣∣ 2 U . Note that scaling all x i ’ s by the same constant does not change arg m ax x ∈S q T x . 7 W e are now ready to desc ribe the key step in our algorith m. Firs t, we define two vector tran sformatio ns P ∶ R D ↦ R D + m and Q ∶ R D ↦ R D + m as follo ws: P ( x ) = [ x ; x 2 2 ; x 4 2 ; .... ; x 2 m 2 ] (12) Q ( x ) = [ x ; 1 2; 1 2 ; .... ; 1 2 ] , (13) where [;] is t he concatenati on. P ( x ) appen ds m scalers of the form x 2 i 2 at the end of the vector x , while Q(x) simply append s m “1/2” to the end of the vec tor x . By observ ing that P ( x i ) 2 2 = x i 2 2 + x i 4 2 + ... + x i 2 m 2 + x i 2 m + 1 2 (14) Q ( q ) 2 2 = q 2 2 + m 4 = 1 + m 4 (15) Q ( q ) T P ( x i ) = q T x i + 1 2 ( x i 2 2 + x i 4 2 + ... + x i 2 m 2 ) (16) we obtain the follo wing ke y equalit y: Q ( q ) − P ( x i ) 2 2 = ( 1 + m 4 ) − 2 q T x i + x i 2 m + 1 2 (17) Since x i 2 ≤ U < 1 x i 2 m + 1 → 0 , at the tower rate (expon ential t o exponen tial). The term ( 1 + m 4 ) is a fixed constant. A s long as m is not too small (e.g., m ≥ 3 would suf fice), we ha ve arg max x ∈S q T x ≃ arg min x ∈S Q ( q ) − P ( x ) 2 (18) T o the best of our kno wledge, this is the first connectio n between solvin g un-normal ized MIPS and approx imate near neighbor search. Tran sformatio ns P and Q , when norms are less than 1, provide correction to the L2 distance Q ( q ) − P ( x i ) 2 making it rank c orrelate with the (un-nor malized) inn er product. This works only after shr inking th e no rms, as norms g reater than 1 will in stead b lo w the te rm x i 2 m + 1 2 . This interes ting mathematical pheno menon connects M IPS with approxi mate near neighb or search. 3.4 Fast Al gorithms for MIPS Eq. (18) shows that MIPS reduces to the standard approximate near neighb or search problem w hich can be ef ficiently solved . As th e error term x i 2 m + 1 2 < U 2 m + 1 goes to zero at a to wer rate, it quickly becomes neg- ligible for any pract ical purpos es. In fact, fro m theor etical perspec ti ve, since we are interested in gu arantees for c -appro ximate solution s, this additi onal error can be absorbed in the approxi mation parameter c . Formally , we can state the follo wing theorem. Theor em 3 Given a c -appr oximate instance of MIPS, i.e ., S im ( q , x ) = q T x , and a quer y q such that q 2 = 1 along with a collec tion S having x 2 ≤ U < 1 ∀ x ∈ S . L et P and Q be the vector tr ansfo rmations define d in Eq. (12) and Eq. (13), r espe ctively . W e have the following two condition s for hash function h L 2 a,b (define d by Eq. (8)) • if q T x ≥ S 0 then P r [ h L 2 a,b ( Q ( q )) = h L 2 a,b ( P ( x ) )] ≥ F r 1 + m 4 − 2 S 0 + U 2 m + 1 8 • if q T x ≤ cS 0 then P r [ h L 2 a,b ( Q ( q )) = h L 2 a,b ( P ( x ) )] ≤ F r 1 + m 4 − 2 cS 0 wher e the functi on F r is defined by Eq. (10). Proof: F r om Eq. ( 9), we have P r [ h L 2 a,b ( Q ( q )) = h L 2 a,b ( P ( x ) )] = F r ( Q ( q ) − P ( x ) 2 ) = F r 1 + m 4 − 2 q T x + x 2 m + 1 2 ≥ F r 1 + m 4 − 2 S 0 + U 2 m + 1 The last step follo ws fr om the mono tonica lly decr easing natur e of F combined with in equalit ies q T x ≥ S 0 and x 2 ≤ U . W e hav e also used the monot onicity of the squ ar e r oot function. The second inequ ality similarly follows using q T x ≤ cS 0 and x 2 ≥ 0 . . This completes the pr oof. The cond itions q 2 = 1 and x 2 ≤ U < 1 , ∀ x ∈ S can b e absor bed in the tra nsformati ons Q and P respec ti vely , but we sho w it exp licitly for clarity . Thus, we ha ve obtained p 1 = F r ( 1 + m 4 ) − 2 S 0 + U 2 m + 1 and p 2 = F r ( 1 + m 4 ) − 2 cS 0 . A p- plying T heorem 2 , we can construct data structu res with worst case O ( n ρ log n ) query time guarant ees for c -appr oximate MIPS, where ρ = log F r 1 + m 4 − 2 S 0 + U 2 m + 1 log F r 1 + m 4 − 2 cS 0 (19) W e also need p 1 > p 2 in order for ρ < 1 . This requires us to ha ve − 2 S 0 + U 2 m + 1 < − 2 cS 0 , which boils do wn to the conditio n c < 1 − U 2 m + 1 2 S 0 . Note that U 2 m + 1 2 S 0 can be made arbitrari ly clos e to zero with the appropriate v alue o f m . For any gi v en c < 1 , there always e xist U < 1 and m such that ρ < 1 . This wa y , w e ob tain a sublin ear query time algorithm for MIPS. The guar antee holds for any v alu es of U and m satisfying m ∈ N + and U ∈ ( 0 , 1 ) . W e also ha ve one more paramet er r for the hash functi on h a,b . Rec all the definitio n of F r in Eq. (10): F r ( d ) = 1 − 2Φ (− r d ) − 2 √ 2 π ( r / d ) 1 − e − ( r / d ) 2 / 2 . Giv en a c -a pproxi mate MIPS instanc e, ρ is a functi on of 3 parameters: U , m , r . The algo rithm with the best query time choos es U , m and r , which minimizes the val ue of ρ . For c on venienc e, w e define ρ ∗ = min U,m,r log F r 1 + m 4 − 2 S 0 + U 2 m + 1 log F r 1 + m 4 − 2 cS 0 (20) s.t. U 2 m + 1 2 S 0 < 1 − c, m ∈ N + , r > 0 and 0 < U < 1 . See Figure 1 for the plots of ρ ∗ . W ith this best valu e of ρ , w e can stat e our main result in Theorem 4. 9 Theor em 4 ( Appr oximat e MIPS is Efficient ) F or the pr obl em of c -appr oximate MIPS, one can construc t a data stru ctur e having O ( n ρ ∗ log n ) query time and space O ( n 1 + ρ ∗ ) , wher e ρ ∗ < 1 is the solution to constr aint optimizatio n (20). 0 0.2 0.4 0.6 0.8 1 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 c ρ * S 0 = 0.9U S 0 = 0.5U 0.6 0.7 0.8 Figure 1 : Optimal v alues of ρ ∗ with respect to approximatio n rati o c for dif ferent S 0 . The op timization of Eq. (20) was done by a grid sear ch ov er para meters r , U and m , gi ven S 0 and c . See Figure 2 for the corres pondin g op timal va lues of parameters. Just like in the typical LS H framew ork, the va lue of ρ ∗ in Theorem 4 depen ds on the c - approx imate instan ce w e aim to solv e, which req uires kno wing the si milarity threshol d S 0 and the a pproxima tion ratio c . Since, q 2 = 1 and x 2 ≤ U < 1 , ∀ x ∈ S , we ha ve q t x ≤ U . A reasona ble c hoice of the threshold S 0 is to choos e a high fraction of U, for ex ample, S 0 = 0 . 9 U or S 0 = 0 . 8 U . The computatio n of ρ ∗ and the optimal value s of correspond ing parameters can be condu cted via a grid search ove r the possib le valu es of U , m and r , as we only ha ve 3 parameters. W e compute the val ues of ρ ∗ along w ith the correspondi ng optimal v alues of U , m and r for S 0 ∈ { 0 . 9 U, 0 . 8 U, 0 . 7 U, 0 . 6 U, 0 . 5 U } for dif feren t appro ximation rat ios c ranging fro m 0 to 1. The plot of the optimal ρ ∗ is shown in Figure 1 , a nd the corresp onding optimal v alues of U , m and r are sho wn in Figure 2. 0 0.2 0.4 0.6 0.8 1 2 3 4 5 c Opt m 0.9 0.6 0.7 0.8 S 0 = 0.9U S 0 = 0.8U S 0 = 0.5, 0.6, 0.7U 0 0.2 0.4 0.6 0.8 1 0.75 0.8 0.85 0.9 0.95 c Opt U 0.9U 0.5U S 0 = 0.7U S 0 = 0.8U 0.6U 0 0.2 0.4 0.6 0.8 1 1.5 2 2.5 3 c Opt r S 0 = 0.5U S 0 = 0.6U S 0 = 0.7U S 0 = 0.8U S 0 = 0.9U Figure 2: O ptimal values of parameters m , U and r with respect to the approximation ratio c for relati vel y high similari ty thresho ld S 0 . The cor respond ing optimal valu es of ρ ∗ are sho w n in Figure 1. 3.5 Practical Recommendation of Parameters In pract ice, the actual choi ce of S 0 and c is depen dent on the data and is often unkn o wn. Figure 2 illu strates that m ∈ { 2 , 3 , 4 } , U ∈ [ 0 . 8 , 0 . 85 ] , a nd r ∈ [ 1 . 5 , 3 ] are reasona ble c hoices. F or con venience , w e recommend 10 to use m = 3 , U = 0 . 83 , and r = 2 . 5 . W ith thi s ch oice of the parameters, Figure 3 shows that t he ρ v alues using these paramet ers are very c lose to the optimal ρ ∗ v alues. 0 0.2 0.4 0.6 0.8 1 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 c ρ S 0 = 0.5U 0.6 S 0 = 0.9U 0.8 0.7 m=3,U=0.83, r=2.5 Figure 3: ρ valu es (dashe d curve s) for m = 3 , U = 0 . 83 and r = 2 . 5 . The soli d curv es are the opt imal ρ ∗ v alues as sho wn in Figure 1. 3.6 Mor e Insight: Th e T rade-off between U and m Let ǫ = U 2 m + 1 be the erro r t erm in Eq. (17). A s long a s ǫ is small the MIP S problem re duces to stand ard near neighb or s earch via the transformation s P and Q . There are two ways to make ǫ small, either we choose a small val ue of U or a large value of m . There is an in terestin g trade -of f b etween parameters U and m . T o see this, conside r the followin g F igure 4 for F r (d), i.e., the coll ision probability defined in E q. (10). 1 1.5 2 2.5 3 3.5 4 0.2 0.3 0.4 0.5 0.6 0.7 d F(d) p 1 p 2 p 2 p 1 Figure 4: Plot of the mon otonic ally decreasin g function F r ( d ) (Eq. (10)). The curve is steeper when d is close to 1, and flatter when d goes awa y from 1. This lea ds to a tradeof f between the choices of U and m . Suppose ǫ = U 2 m + 1 is small, then p 1 = F r ( 1 + m 4 − 2 q T x ) and p 2 = F r ( 1 + m 4 − 2 cq T x ) . Be- cause of the bou nded norms, we ha v e − q 2 x 2 = − U ≤ q T x ≤ U = q 2 x 2 . Consi der the high si milarity range d ∈ [ 1 + m 4 − 2 U , 1 + m 4 − 2 cU ] , for some appropriatel y chosen c < 1 . This rang e is wide r , if U is clos e to 1, if U is clos e to 0 th en 2 U ≃ 2 cU making the ar guments to F clo se to eac h ot her , which in turn decreases the gap between p 1 and p 2 . On the other hand, when m is larger , it adds bigger offs et (term m 4 inside square root) to both the arg uments. Adding o f fset, makes p 1 and p 2 shift to wa rds righ t in th e col lision proba bility plot. Righ t shift, mak es p 1 and p 2 closer because of the nature of the collision probabil ity curve (see Figure 4). Thus, bigge r m m ake s p 1 and p 2 closer . S maller m pushes p 1 and p 2 to wards left and there by increas ing the gap betwee n them. 11 Small ρ = log p 1 log p 2 rough ly boils down to ha ving a bigger gap between p 1 and p 2 [26]. Ideally , for small ρ , we would like to use big U and small m . The error ǫ = U 2 m + 1 exa ctly follo ws the opposite trend. For error t o be small we want small U an d not too small m . 3.7 Parallelization T o con clude this se ction, we shou ld mention tha t the ha sh tabl e based sc heme is mas si vely p aralleli zable. Dif ferent nod es on cluste r need to mainta in their o wn hash tab les and hash f unction s. The oper ation of retrie vin g from b uck ets and computing the maxi mum inn er prod uct ov er those retrie v ed candida tes, g i ven a qu ery , is a local opera tion. Computing the fina l maxi mum can be conducted efficie ntly by si mply com- municati ng one single number per nodes. Scalab ility of hashing based methods is one of the reasons which accoun t for their popular ity in indus trial practice . 4 Evaluations 4.1 Datasets W e ev aluate o ur proposed hash function for the MIPS problem on two popular c ollabor ati ve filtering datasets (on the task of item recommenda tions): • Movi elens. W e choose the larg est av ailab le Mo viele ns d ataset, t he Movielen s 10 M , which contains around 10 million movi e ratings from 70,000 users o ver 10 ,000 movie title s. The ratings are between 1 to 5, with incremen ts of 0.5 (i.e., 10 possib le ratings in total). • Netflix. This da taset contains 100 million mo vie rati ngs from 480,000 users o ver 1 7,000 movie t itles. The rating s are on a scale from 1 to 5 (integ er). Each d ataset for ms a sparse user -ite m matrix R , where t he v alue of R ( i, j ) indicate s the ratin g of us er i for mo vie j . Giv en t he user -item ra tings matrix R , we fo llo w the PureSVD procedure describ ed in [6] to genera te user and item latent vect ors. That is, we compute the SVD of the ratings matrix R = W Σ V T where W i s n user s × f mat rix an d V is n item × f mat rix fo r some appropriatel y chosen rank f (which is also called the latent dimensi on ). After th e SVD step, the ro ws of matr ix U = W Σ are treated as the user c haracte ristic vecto rs while ro ws of matrix V corres pond to the item charac teristic v ector s. More specifically u i , the i th ro w of matrix U , denote s the characteris tic v ecto r of user i , while the j th ro w of V , i.e., v j , correspond s to the characteristi c vec tor for item j . The c ompatibil ity between item i and item j is gi ven by the inner pr oduct bet ween the corres pondin g user and ite m c haracte ristic v ectors. T herefor e, in recommend ing top -rank ed items to users i , the PureSVD method return s top-rank ed items based on the inner products u T i v j , ∀ j . The P ureSVD proced ure, d espite its simplicity , outp erforms other popular recommendat ion alg orithms for the ta sk of to p-rank ing recommend ations (see [6] f or more d etails) on the se two da tasets. Foll o wing [6], we use the same choice s for the latent dimension f , i.e., f = 150 for Moviele ns and f = 300 for Netflix. 4.2 Baseline Hash Function Our prop osal is the first prov able hashin g scheme in the li teratur e for retrie ving inner prod ucts and hence there is no exis ting baseline. Sin ce, our hash functio n uses H ashing for L2 distance after asymmetric trans- formatio n P (12) a nd Q (1 3), we would like to know if such transformation s are e ven needed and fu rther - more get an estimate of the improv ements obtained using these transformati ons. W e therefore compare our 12 propo sal with L2LSH the hash ing scheme h L 2 a,b descri bed by Eq. (8). It is implemented in the LSH packa ge for near neighb or search with Euclidea n distance. Although , L2LSH are not optimal for retrie ving un-nor malized inner produ cts, it d oes pro vide some inde xing capability . Our experime nts will sho w that the proposed method outperform L2LSH , of ten signif- icantly so, in retriev ing inner products . This is n ot su rprisin g as we k no w t hat the ran kings of L2 distan ce can be dif fere nt from rankin gs of inner produc ts. 4.3 Evaluations W e are interested in knowing , how the two hash functions correlate w ith the top- T inner products. For this task, giv en a user i and its correspondi ng u ser vector u i , we compute the top- T gold sta ndard items based on the actua l in ner products u T i v j , ∀ j . W e then compute K dif ferent hash codes of the vect or u i and all the item v ectors v j s. For eve ry i tem v j , we then co mpute the number of times its has h v alues matches (or collid es) with the hash v alues of query which is user u i , i.e., we compute M atches j = K ∑ t = 1 1 ( h t ( u i ) = h t ( v j )) , (21) where 1 is t he indi cator functio n. Based o n M atches j we ran k all the items. T his procedure genera tes a sorted list of all the items for a gi ven user vector u i corres pondin g to e very hash function under considera tion. Here, we use h = h L 2 a,b for L 2LSH. For our proposed asymmetric hash function we hav e h ( u i ) = h L 2 a,b ( Q ( u i )) , since u i is the qu ery , and h ( v j ) = h L 2 a,b ( P ( v j )) for a ll the items. The subsc ript t is used to d istingu ish indepe ndent draws of h . Idea lly , for a better hashing scheme, M atche s j should be higher for items having higher inner product s w ith the gi ven user u i . W e compute the precision and recall of the top- T items for T ∈ { 1 , 5 , 10 } , obta ined from the sorted list based o n M atches . T o c ompute thi s prec ision and re call, we s tart at the top of the ra nked item list and w alk do wn in order . Suppose we a re at the k th rank ed item, we check if t his item belongs to the gold s tandard top- T list. If it is one of th e top- T gold standard ite m, the n we increment the c ount of rele van t see n by 1, else we mo ve to k + 1 . By k th step, we hav e already seen k items, so t he total items seen is k . The pre cision and recall at that point is then comput ed as: P r ecision = rele v ant seen k , Recal l = rele v ant seen T (22) W e v ary a lar ge numbe r of k v alues to obtain c ontinu ously-l ooking pr ecisio n-r eca ll cur ves. Note that it is import ant to balanc e both precisio n an d recal l. Methodology which obtains high er precisio n a t a gi v en recall is superior . Higher precisi on in dicate s higher ranking of the relev ant items. W e av erag e this v alue of precis ion and recall ov er 2000 randomly chosen users. Choice of r . W e need t o specify this impo rtant parameter for ou r proposed a lgorith m as well as L 2LSH. W e hav e shown in Figure 3 that, for our proposed algorithm, it is over all good to choose m = 3 , U = 0 . 83 and r = 2 . 5 . This theoretic al result lar gely frees us from the bu rden of choosing para meters. W e still need to cho ose r fo r L2LSH. T o ensure that L2LS H is not bei ng sub optimal beca use of the choice of r , we report th e results of L2LSH for all r ∈ { 1 , 1 . 5 , 2 , 2 . 5 , 3 , 3 . 5 , 4 , 4 . 5 , 5 } , and we sh ow t hat our propo sed method (with r = 2 . 5 ) very significant ly outperf orms L2LSH at al l cho ices of r , in Figure 5 and Figure 6 , for K = 64 , 128 , 25 6 , 512 ha shes. The good perfo rmance of our algori thm sh o wn in Figure 5 an d Figure 6 is not sur prising because we kno w fro m Theorem 3 that the collision unde r the ne w hash fun ction is a direct ind icator of hig h inn er prod- uct. As the number of hash codes is increased , the performance of the proposed m ethodo logy sho ws bigger 13 impro vement s over L2LSH. T he suboptimal performance of L2LSH clearly indicates that the norms of the item charact eristic vectors do play a si gnificant role in item recommendat ion task. Also, the experimen ts clearly establ ishes the need of propo sed asymmetric transformation P and Q . 0 20 40 60 80 100 0 5 10 15 20 25 Recall (%) Precision (%) Movielens Top 1, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 20 40 60 Recall (%) Precision (%) Movielens Top 5, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 20 40 60 80 Recall (%) Precision (%) Movielens Top 10, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 Recall (%) Precision (%) Movielens Top 1, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 50 Recall (%) Precision (%) Movielens Top 5, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 20 40 60 Recall (%) Precision (%) Movielens Top 10, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 Recall (%) Precision (%) Movielens Top 1, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 Recall (%) Precision (%) Movielens Top 5, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 50 Recall (%) Precision (%) Movielens Top 10, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 2 4 6 8 Recall (%) Precision (%) Movielens Top 1, K = 64 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 20 25 Recall (%) Precision (%) Movielens Top 5, K = 64 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 Recall (%) Precision (%) Movielens Top 10, K = 64 Proposed L2LSH Figure 5: Moviele ns . Precision-Reca ll curv es (higher is better ), of retrie ving top- T items, for T = 1 , 5 , 10 . W e vary the number of h ashes K from 64 to 512. The proposed algorithm (solid, red if colo r is a v aila ble) significa ntly ou tperfor ms L2LSH. W e fix the parameters m = 3 , U = 0 . 83 , a nd r = 2 . 5 for our prop osed method and we present the results of L2LSH for all r value s in { 1 , 1 . 5 , 2 , 2 . 5 , 3 , 3 . 5 , 4 , 4 . 5 , 5 } . Becaus e the dif feren ce between our method and L2LSH is l ar ge, we do no t label curv es at dif ferent r val ues for L2LSH. 14 0 20 40 60 80 100 0 5 10 15 20 Recall (%) Precision (%) Netflix Top 1, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 Recall (%) Precision (%) Netflix Top 5, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 50 Recall (%) Precision (%) Netflix Top 10, K = 512 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 Recall (%) Precision (%) Netflix Top 1, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 Recall (%) Precision (%) Netflix Top 5, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 40 50 Recall (%) Precision (%) Netflix Top 10, K = 256 Proposed L2LSH 0 20 40 60 80 100 0 2 4 6 8 Recall (%) Precision (%) Netflix Top 1, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 20 25 Recall (%) Precision (%) Netflix Top 5, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 10 20 30 Recall (%) Precision (%) Netflix Top 10, K = 128 Proposed L2LSH 0 20 40 60 80 100 0 2 4 6 Recall (%) Precision (%) Top 1, K = 64 Netflix Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 Recall (%) Precision (%) Netflix Top 5, K = 64 Proposed L2LSH 0 20 40 60 80 100 0 5 10 15 20 Recall (%) Precision (%) Netflix Top 10, K = 64 Proposed L2LSH Figure 6 : Netflix . Precision- Recall curve s (higher is better), of retrie vin g top- T items, for T = 1 , 5 , 10 . W e vary the number of h ashes K from 64 to 512. The proposed algorithm (solid, red if colo r is a v aila ble) significa ntly ou tperfor ms L2LSH. W e fix the parameters m = 3 , U = 0 . 83 , a nd r = 2 . 5 for our prop osed method and we present the results of L2LSH for all r value s in { 1 , 1 . 5 , 2 , 2 . 5 , 3 , 3 . 5 , 4 , 4 . 5 , 5 } . Becaus e the dif feren ce between our method and L2LSH is l ar ge, we do no t label curv es at dif ferent r val ues for L2LSH. 15 T o close this section, we present Figure 7 to visuali ze the impact of the parameter r on the performan ce of our propos ed method. Our theory and Figure 3 ha ve already shown that w e can achiev e close to optimal perfor mance by choosing m = 3 , U = 0 . 83 , a nd r = 2 . 5 . Nev erthe less, it is st ill interesting to see how the theory is confirmed by expe riments. Figure 7 presents the precisio n-recal l curve s for our propos ed met hod with m = 3 , U = 0 . 83 , and r ∈ { 1 , 1 . 5 , 2 , 2 . 5 , 3 , 3 . 5 , 4 , 4 . 5 , 5 } . For clarify , we only dif ferenti ate r = 1 , 2 . 5 , 5 from the r est of th e curves. The results demonstrate tha t r = 2 . 5 is indeed a good cho ice and the performan ce is not too sensit iv e to r unless it is much away from 2.5. 0 20 40 60 80 100 0 5 10 15 20 25 Recall (%) Precision (%) Movielens Top 1, K = 512 r = 2.5 r = 1 r = 5 0 20 40 60 80 100 0 20 40 60 Recall (%) Precision (%) Movielens Top 5, K = 512 r = 2.5 r = 1 r = 5 0 20 40 60 80 100 0 20 40 60 80 Recall (%) Precision (%) Movielens Top 10, K = 512 r = 2.5 r = 1 r = 5 0 20 40 60 80 100 0 5 10 15 20 Recall (%) Precision (%) Netflix Top 1, K = 512 r = 2.5 r = 1 r = 5 0 20 40 60 80 100 0 10 20 30 40 Recall (%) Precision (%) Netflix Top 5, K = 512 r = 2.5 r = 1 r = 5 0 20 40 60 80 100 0 20 40 60 Recall (%) Precision (%) Netflix Top 10, K = 512 r = 2.5 r = 1 r = 5 Figure 7: Impact of r on the perfo rmance of the p roposed meth od. W e present the precision -recall curve s for m = 3 , U = 0 . 83 , and r ∈ { 1 , 1 . 5 , 2 , 2 . 5 , 3 , 3 . 5 , 4 , 4 . 5 , 5 } , which demonst rate that, (i) r = 2 . 5 is indeed a good choice; and (ii) the perfo rmance is not too sensiti ve to r unless it is much awa y from 2.5. 5 Conclusion and Futur e W ork MIPS (maximum inn er product search) naturally arises in numerous practical scenario s, e.g., collabor ati ve filtering. G i ven a query da ta v ecto r , th e task o f MIP S is to find dat a vectors from t he repository whic h are most simil ar to the query in terms of (un-normaliz ed) inner product (instead o f dista nce). This p roblem is challen ging a nd, p rior to our work, there exist ed no p rov ably s ubline ar time al gorithms for MIPS . The curren t frame work of LSH (loc ality sensiti ve hashin g) is not sufficie nt for solving MIPS . In this study , w e de velo p ALSH (asymmetric L SH), which generalizes th e existing L SH framewo rk by applyi ng (appro priatel y chose n) asymmetric trans formation s to the input quer y v ector and the data v ec- tors in the repository . W e presen t an implementatio n of ALSH by proposing a novel transformation whic h con verts the original inner products in to L2 distances in the tra nsformed space. W e demonstrate, both the- oretica lly and empirically , that this implement ation of ALSH provides a pr ov abl y ef ficien t solu tion to MIPS. 16 W e belie ve our work will lead to se v eral interes ting (and practica lly useful) lines of future wo rk : • Thr ee- way (and higher -or der) m aximum inner pr oduct sear ch: In this paper , we hav e focused on pairwise similarity search. T hree-w ay (or eve n higher -order) search can also be important in practice and might attract more attentio ns in the near future due to the recent pilot studies on ef ficient three-way similarit y computatio n [20, 22, 28]. Extend ing AL SH to three- way MIPS could be very usefu l. • Other efficie nt si milarities : Finding other similarities for which there exist fast retrie v al algorithms is an impor tant problem [5]. Explori ng other similarity functions , which can be ef ficient solv ed using asymmetric has hing is an inte resting future area. One good ex ample is to find special ALSH sche mes for binary data by explorin g prior powerful hashing methods fo r binary d ata s uch as (b-bit) minwis e hashin g and one permutati on hashin g [3, 24]. • F ast has hing fo r MIPS: Our pr oposed hash func tion us es r andom pr ojectio n as the main hashin g scheme. There is a ric h set of literature [21, 1, 8, 24, 29] on making hashi ng faster . Evaluat ions of these ne w faster tech niques w ill furthe r improve the runti me guaran tees in this paper . • Applicat ions: W e hav e ev aluate d the efficien cy of our scheme in the collaborati v e filte ring applica- tion. An interesti ng s et of future work consist of applyi ng this hashing scheme for other applicat ions mentione d i n Section 1. In particu lar , it will be excitin g to apply effici ent M IPS subroutine s to improv e the DPM based object detect ion [10] and structura l SVMs [16]. Refer ences [1] N. A ilon and B. Chazelle. Approx imate neares t neigh bors and t he f ast J ohnson -Lindenst rauss tran s- form. In ST OC , pages 557–5 63, Seattle, W A, 2006. [2] A. Andoni and P . Indyk. E2lsh: Exact euc lidean locality sensiti ve hashing . T echnical report, 2004. [3] A. Z. Broder . On th e resemb lance and containment of documents. In the C ompr ess ion and Complexit y of Sequ ences , pages 21–29, P ositano , Italy , 1997. [4] M. S. Cha rikar . Similarity estimat ion techniq ues from ro unding algori thms. In S TOC , pages 3 80–38 8, Montreal , Quebec, Canada, 2002. [5] F . Chierich etti and R. Kumar . Lsh-preser ving functio ns and their applic ations. In SODA , pages 1078– 1094, 2012 . [6] P . Cremonesi, Y . K oren, and R. T urr in. Performance of recommender algorithms on top-n recommen- dation ta sks. In Pr oceedings of the f ourth A CM confer en ce o n Recommender sy stems , pages 39–46 . A CM, 201 0. [7] A. S . Das, M. Data r , A. Garg, and S. Rajaram. Google n e ws personaliza tion: scalable online collabo ra- ti ve fi ltering . I n Pr oceedings of the 16th in ternatio nal confer ence on W orld W ide W eb , pag es 271– 280. A CM, 200 7. [8] A. Dasgupta, R. Ku mar , and T . Sarl ´ os. Fast loc ality-se nsiti v e hashing. In KDD , pages 1073–10 81, 2011. [9] M. Datar , N. Immorlica, P . Indy k, and V . S. Mir rokn. L ocality -sensit i ve has hing scheme b ased on p -stable distrib utions. In SCG , pages 253 – 262, Brooklyn , NY , 200 4. 17 [10] T . D ean, M. A. Ruzon, M. Se gal, J. Shlens, S . V ijayanar asimhan, and J. Y agnik. Fast, ac curate de- tection of 100,0 00 object classes on a sing le machine. In Computer V ision and P attern Recogn ition (CVPR), 2013 IEEE Confer ence on , pages 1814–1 821. IE EE, 2013. [11] P . F . Felzenszwa lb, R. B . Girshick, D. M cAllester , and D. Ramanan. Obje ct detection with discrimi- nati v ely train ed part-bas ed models. P attern Analys is and Mac hine In tellig ence , IEEE T ransa ctions on , 32(9): 1627–1 645, 20 10. [12] J. H . Frie dman and J. W . T ukey . A projec tion pursuit alg orithm for explora tory data analysis. IEEE T ransact ions on Computer s , 23(9):88 1–890, 1974. [13] S. Har-Peled , P . Indyk, and R. Motwani. Approximate nearest neighbor: T o wards removin g the curse of dimens ionality . Theory of Computing , 8(14):321 –350, 2012. [14] M. R. Henzing er . Finding near -dupli cate w eb p ages: a lar ge- scale ev aluation of algorith ms. In SIGIR , pages 284–29 1, 2006. [15] P . Indyk and R. Motw ani. Ap proximate neares t neighbors : T o wards remo ving the c urse of di mension- ality . In STOC , pages 604– 613, Dallas, TX, 1998 . [16] T . Joachi ms, T . Finley , and C.-N . J. Y u. C utting -plane training of structural svms. Mac hine Learning , 77(1): 27–59, 2009. [17] N. K oenigs tein, P . Ram, and Y . S ha vitt. Efficient retrie v al of recommendati ons in a matrix factor ization frame work . In CIKM , pages 535–544, 2012. [18] Y . K oren. Factorizatio n meets the neigh borhoo d: a multifacete d collab orati v e filtering model. In KD D , pages 426–43 4. ACM, 2 008. [19] Y . Kor en, R. Bell, and C. V olinsky . Matrix fa ctoriza tion techniqu es for recommender systems. [20] P . Li and K. W . C hurch. A sketch algo rithm for estimating two-wa y and multi-way ass ociatio ns. Com- putati onal L inguis tics (Pr elimina ry re sults appear ed in HLT/EMNLP 200 5) , 33(3):305–3 54, 2 007. [21] P . Li, T . J. Hastie, and K. W . Church . V ery sparse random project ions. In KDD , pa ges 287–29 6, Philadelp hia, P A, 2006. [22] P . L i, A . C . K ¨ onig, and W . G ui. b-bit m inwise hashing for estimating three-way similarities. In Advances in Neur al Informatio n Pr oces sing Systems , V ancouv er , B C, 20 10. [23] P . Li, M. Mitzen macher , and A . Shriv ast a v a. Coding for random projections and approximate near neighb or search. T echnical report, arXiv:1 403.814 4 , 2014. [24] P . Li, A. B. Owen, and C.-H. Zhang. One permut ation hashing . In NIPS , L ake T ahoe, NV , 2012. [25] G. S. Manku, A. Jain, and A. D . S arma. Detectin g Near -Duplicat es for Web-Cra wling. In WWW , Banf f, Alberta, Canada, 2007. [26] A. Rajaraman and J. Ullman. Mining of Massi ve D ataset s . http://i.stanf ord.edu/ ∼ ullman/mmds.html . [27] P . Ram and A. G. Gray . Maximum inner -p roduct search usin g cone tree s. In KDD , pages 931–939 , 2012. [28] A. Shri v asta v a and P . Li. Beyo nd pairwise: Pro v ably fast algo rithms for approximate k-way simila rity search . In NIPS , Lak e T ahoe, NV , 2013. 18 [29] A. Shri v asta v a and P . Li. D ensify ing one permutation hashing via rotation for fast near neighbo r s earch. In ICML , Beijing, China, 2014. [30] R. W eber , H.-J. Schek, and S. Blott . A qua ntitati ve analysis and per formance study for similarit y- search methods in high- dimension al s paces. In VLDB , pages 194–20 5, 1998. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment