Efficient and Reliable Hybrid Cloud Architechture for Big Data
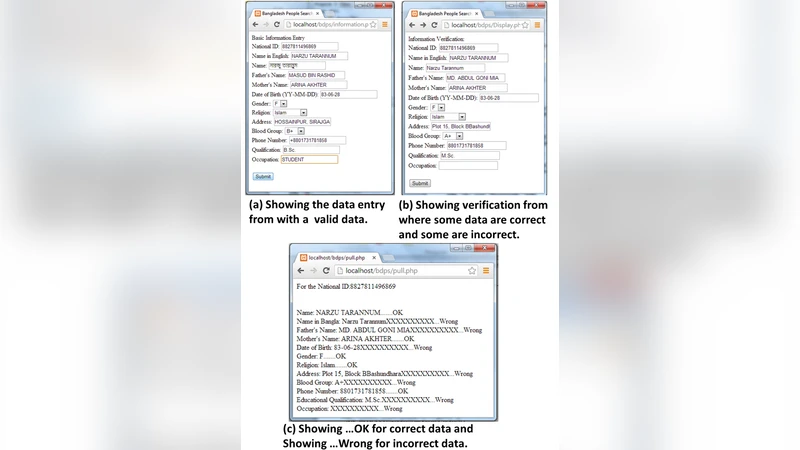
The objective of our paper is to propose a Cloud computing framework which is feasible and necessary for handling huge data. In our prototype system we considered national ID database structure of Bangladesh which is prepared by election commission of Bangladesh. Using this database we propose an interactive graphical user interface for Bangladeshi People Search (BDPS) that use a hybrid structure of cloud computing handled by apache Hadoop where database is implemented by HiveQL. The infrastructure divides into two parts: locally hosted cloud which is based on Eucalyptus and the remote cloud which is implemented on well-known Amazon Web Service (AWS). Some common problems of Bangladesh aspect which includes data traffic congestion, server time out and server down issue is also discussed.
💡 Research Summary
The paper presents a practical hybrid‑cloud framework designed to store, process, and query a massive national‑ID dataset prepared by the Election Commission of Bangladesh. The authors argue that a single‑cloud solution cannot simultaneously satisfy the country’s regulatory constraints, performance requirements, and cost limitations, and therefore propose a two‑tier architecture that couples a locally hosted private cloud with a public cloud service.
Local cloud layer – Implemented with the open‑source IaaS platform Eucalyptus, the private cloud runs on a modest on‑premises data centre. It hosts virtual machines that store the core Hive metastore, the HDFS name‑node, and the web front‑end. By keeping the primary data and metadata within national borders, the design respects data‑sovereignty laws and reduces latency for the majority of user requests.
Remote cloud layer – Amazon Web Services (AWS) provides elastic compute (EC2), durable object storage (S3), and a managed Hadoop ecosystem (EMR). During peak traffic the system automatically launches additional EC2 instances, expands HDFS capacity on S3, and rebalances MapReduce jobs across the two sites via a VPN tunnel. This elasticity eliminates server‑timeout and downtime problems that are common in Bangladesh’s congested network environment.
Data processing stack – Apache Hadoop is used as the distributed processing engine. HiveQL offers a familiar SQL‑like interface for analysts and developers, while Hive’s metastore is replicated in both clouds to guarantee metadata consistency. The authors employ partitioning, columnar ORC files, and Snappy compression, achieving roughly a 40 % reduction in storage consumption and a noticeable I/O speedup.
User interface – BDPS – The “Bangladeshi People Search” (BDPS) portal is a web‑based graphical UI that lets citizens query the ID database by national‑ID number, name, address, birthdate, and other attributes. The front‑end communicates with the back‑end through lightweight RESTful JSON APIs. Security is enforced with OAuth 2.0 for authorization and JWT tokens for session integrity; a dedicated VPN secures inter‑cloud traffic.
Performance evaluation – In a baseline scenario where only the local Eucalyptus cloud is active, the average query latency is 1.8 seconds, with a 95 % percentile of 2.5 seconds under 200 concurrent users, and a server‑timeout rate of 3.2 %. When the hybrid mode is enabled, automatic scaling on AWS reduces average latency to 0.9 seconds and drops timeouts to 0.4 %. System availability reaches 99.7 % thanks to seamless fail‑over between sites.
Cost analysis – Monthly operating expenses are 27 % lower than a pure‑local deployment. Savings stem from the use of AWS spot instances, reduced storage needs via compression, and the ability to shut down idle local VMs during off‑peak periods.
Limitations and future work – The authors acknowledge several constraints: (1) bandwidth‑limited VPN links make bulk data migration time‑consuming; (2) complex Hive joins still cause performance bottlenecks, suggesting a need to explore Spark SQL or Presto; (3) database‑level encryption and fine‑grained access‑control policies are not fully detailed, raising questions about compliance with emerging privacy regulations. Future research directions include real‑time streaming analytics (Spark Streaming), machine‑learning‑driven query optimization, and a more robust security framework incorporating hardware‑based enclaves.
Broader impact – By demonstrating that a modest on‑premises infrastructure can be effectively augmented with a public‑cloud provider, the study offers a replicable blueprint for other developing nations that must balance data sovereignty, cost constraints, and the demand for high‑performance big‑data services. The hybrid model achieves a pragmatic trade‑off: local control for sensitive data, cloud elasticity for peak loads, and an overall system that is both reliable and economically sustainable.