Crowdsourcing Predictors of Behavioral Outcomes
Generating models from large data sets – and determining which subsets of data to mine – is becoming increasingly automated. However choosing what data to collect in the first place requires human intuition or experience, usually supplied by a domain expert. This paper describes a new approach to machine science which demonstrates for the first time that non-domain experts can collectively formulate features, and provide values for those features such that they are predictive of some behavioral outcome of interest. This was accomplished by building a web platform in which human groups interact to both respond to questions likely to help predict a behavioral outcome and pose new questions to their peers. This results in a dynamically-growing online survey, but the result of this cooperative behavior also leads to models that can predict user’s outcomes based on their responses to the user-generated survey questions. Here we describe two web-based experiments that instantiate this approach: the first site led to models that can predict users’ monthly electric energy consumption; the other led to models that can predict users’ body mass index. As exponential increases in content are often observed in successful online collaborative communities, the proposed methodology may, in the future, lead to similar exponential rises in discovery and insight into the causal factors of behavioral outcomes.
💡 Research Summary
The paper introduces a novel “machine‑science” framework that leverages the collective intelligence of non‑expert participants to both generate predictive features and supply the data needed to model a behavioral outcome. The authors built a web‑based platform that operates as a dynamically expanding survey: users answer existing questions that are presumed to be related to a target variable, and they are also encouraged to pose new questions that they believe might influence that variable. As more participants join, the question set grows, creating a rich, high‑dimensional feature space without any a‑priori domain‑expert design.
Two proof‑of‑concept experiments were conducted. In the first, the target variable was each household’s monthly electricity consumption (kWh). In the second, the target was an individual’s body‑mass index (BMI). Participants were recruited online, and each session involved (1) answering all currently available questions, (2) rating the relevance of existing questions (optional), and (3) submitting new questions. All responses were stored in a relational database; missing values were imputed with column means, and categorical answers were one‑hot encoded.
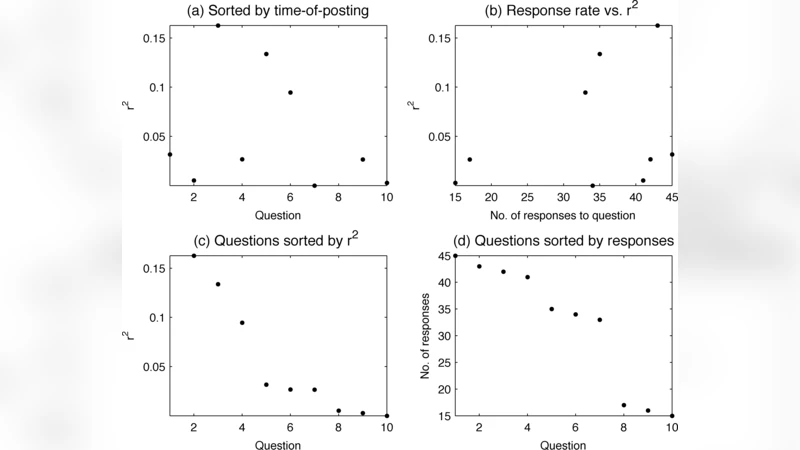
Because the number of questions quickly reached several hundred, the authors employed Lasso‑regularized linear regression to perform simultaneous coefficient estimation and feature selection. The Lasso penalty forces many coefficients to zero, leaving only the most predictive questions in the final model. Model performance was evaluated using ten‑fold cross‑validation, reporting both the coefficient of determination (R²) and root‑mean‑square error (RMSE).
For the electricity‑consumption task, the final model achieved R²≈0.62 and RMSE≈15 kWh. The strongest predictors included household size, frequency of heating/cooling usage, number of electronic devices, and dwelling type. Notably, several high‑impact predictors emerged from user‑generated questions such as “Do you run appliances on weekends?”—a factor that would not typically appear in a conventional engineering survey.
In the BMI experiment, the model obtained R²≈0.55 and RMSE≈2.3 kg/m². Key variables were weekly exercise frequency, daily fruit/vegetable intake, late‑night snacking, average sleep duration, and perceived stress level. Again, user‑crafted items like “percentage of meals eaten out on weekends” received substantial weight, illustrating the platform’s ability to surface lifestyle nuances that standard health questionnaires often overlook.
The authors also examined the dynamics of question growth. Early in both experiments, the number of new questions added per day was modest (2–3), but after the participant pool exceeded roughly 100 users, the rate accelerated dramatically, displaying a classic network‑effect curve. This suggests that once a critical mass of contributors is reached, the system can generate an exponential increase in both data volume and feature diversity.
However, the study acknowledges several limitations. First, there is no automated quality‑control mechanism for newly submitted questions; irrelevant, ambiguous, or duplicate items can clutter the survey. The authors propose a community‑voting or expert‑review layer to filter low‑quality contributions. Second, the reliance on linear models may miss nonlinear interactions among variables; future work could explore tree‑based ensembles (Random Forest, Gradient Boosting) or deep neural networks to capture more complex patterns. Third, the participant sample is self‑selected and skewed toward internet‑savvy individuals, raising concerns about external validity. Weighting schemes or stratified recruitment would be needed to generalize findings to broader populations.
In summary, this research demonstrates that crowdsourced feature generation, combined with modest statistical modeling, can produce accurate predictors of real‑world behavioral outcomes without traditional domain‑expert input. The approach reduces data‑collection costs, uncovers novel explanatory variables, and capitalizes on the motivational dynamics of online collaboration. By addressing question‑quality assurance, incorporating nonlinear learners, and broadening the participant base, the methodology holds promise for scaling to a wide array of social, health, and environmental prediction tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment