Topic words analysis based on LDA model
Social network analysis (SNA), which is a research field describing and modeling the social connection of a certain group of people, is popular among network services. Our topic words analysis project is a SNA method to visualize the topic words amon…
Authors: Xi Qiu, Christopher Stewart
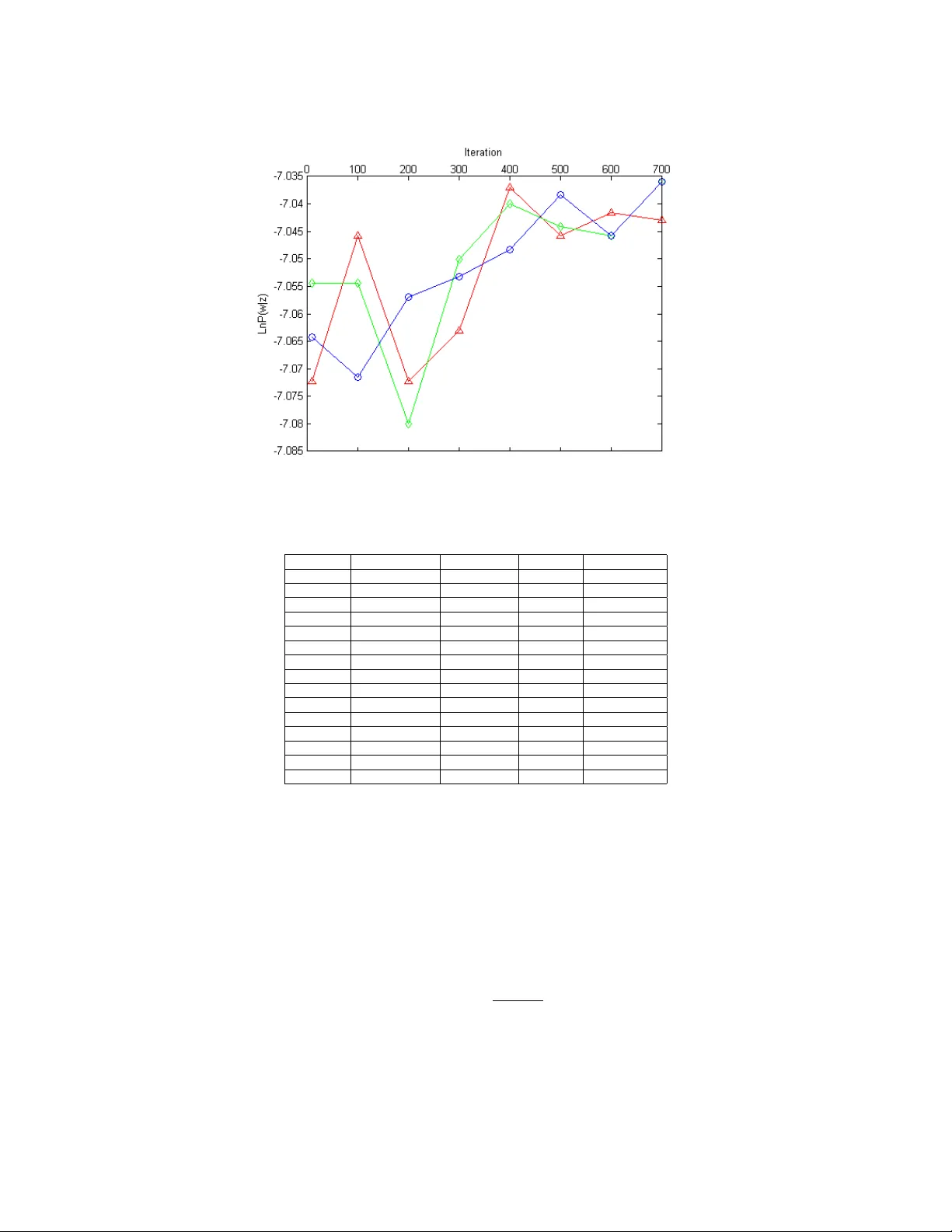
A T opic w o rds analysis based on LD A mo del XI QIU , Ohio State Universit y Social netw ork analysis (SNA), which is a research field describing and modeling the social connection of a certain group of people, is popular among netw ork services. Our topic words analysis pro ject is a SNA method to visualize the topic w ords among emails from Obama.com to accounts registered in Colum bus, Ohio. Based on Laten t Diric hlet Allo cation (LD A) mo del, a popular topic model of SNA, our pro ject charac- terizes the preference of senders for target group of receptors. Gibbs sampling is used to estimate topic and word distribution. Our training and testing data are emails from the carbon-free server Datagreening.com. W e use parallel computing tool BashReduce for word processing and generate related words under each latent topic to discov ers typical information of political news sending sp ecially to local Colum bus receptors. Running on tw o instances using paralleling tool BashReduce, our pro ject contributes almost 30% sp eedup processing the raw con tents, comparing with processing conten ts on one instance lo cally . Also, the experi- mental result shows that the LD A model applied in our pro ject provides precision rate 53.96% higher than TF-IDF model finding target words, on the condition that appropriate size of topic w ords list is selected. Categories and Sub ject Descriptors: [] A CM Reference F ormat: ACM V, N, Article A (January YYYY), 10 pages. DOI: http://dx.doi.org/10.1145/0000000.0000000 1. INTRODUCTION So cial netw ork is a net w ork consisting of constan t information of the connection of a group of people. Social Net work Analysis (SNA) [Adamic and Adar 2009] discov ers the unique or target characters to describ e the certain pattern of suc h p eople connection. As an im- plemen tation of SNA, online so cial services lik e Linke dIn.c om are becoming popular these y ears. In some previous studies, SNA mo dels are implemented to mak e connections of cer- tain groups b y directed graph mo dels or w eigh ted edge graph mo dels. F or example, W ang and his co w orkers dev elop a probabilistic factor graph model [W ang et al. 2010] to analyze bibliographic netw ork in academic w orld. When conducting research in so cial netw orks by c haracterizing do cuments, suc h as emails and academic publications, data mining models ha ve b een applied in man y SNA mo dels. Lada Adamic and Eytan Adar presen t Latent Diric hlet Allo cation (LDA) mo del [Blei et al. 2003], which selects Dirichlet distribution to estimate topic mixture, and samples training data b y Expectation Maximization (EM) algorithm. This LD A model collects separated data to impro v e predicted models, generat- ing representativ e words under such latent topics from giv en do cuments. Later, Rosen-Zvi and her group extend LD A mo del to Author T opic (A T) mo del [Rosen-Zvi et al. 2004], determining topics b y b oth con tent and author distributions. Our pro ject collects topic words from emails and mo dels the preference of senders in t ypical website, using Gibbs sampling as training strategy instead of EM algorithm. W e Author’s address: X. Qiu, Departmen t of Computer Science and Engineering, Ohio State Univ ersity , Colum- bus, OH 43210, USA. Permission to make digital or hard copies of part or all of this work for p ersonal or classroom use is granted without fee pro vided that copies are not made or distributed for profit or commercial adv antage and that copies show this notice on the first page or initial screen of a display along with the full citation. Copyrigh ts for components of this work owned b y others than A CM must be honored. Abstracting with credit is p ermitted. T o cop y otherwise, to republish, to post on serv ers, to redistribute to lists, or to use an y component of this w ork in other works requires prior specific p ermission and /or a fee. Permissions may be requested from Publications Dept., A CM, Inc., 2 P enn Plaza, Suite 701, New Y ork, NY 10121-0701 USA, fax +1 (212) 869-0481, or permissions@acm.org. c YYYY ACM 0000-0000/YYYY/01-AR T A $15.00 DOI: http://dx.doi.org/10.1145/0000000.0000000 ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. A:2 Xi Qi u create an email account at Colum bus, Ohio and use this account to register at Ob ama.c om . Emails sent b y Ob ama.c om are receiv ed through Datagr e ening.c om [Stewart 2012], whic h is a carb on-free serv er dev elop ed by our research group. Then the do wnloaded emails are pro cessed to input data for LD A model in an appropriate format. Then we apply the LDA mo del mapping the data to topic lay ers. Thus the topic w ords list is able to be generated in the next step. Finally , b y analyzing the similarity betw een target words list and topic w ords list generated in ab ov e steps, we establish whic h information are lik ely given to publicit y b y Ob ama.c om . Python pack ages ha ve b een used to pro cess w ords, suc h as w ord tokenizing, word stem- ming and filtering out stop words, etc. W ord count program is run on tw o no des imple- men ting the parallel computing to ol BashReduce [Zaw o dn y 2009] to achiev e almost 30% sp eedup. TF-IDF model [Liu et al. 2004] is selected to b e a comparison generating topic w ords list. The mo del applied in our pro ject provides precision rate 53.96% higher than TF-IDF mo del, when w e define the size of topic list prop erly . The rest parts of this pap er are organized in following five sections: In section 2, we in tro duce the generativ e LD A model and the design details of applying this mo del in our pro ject. Section 3 describes parameter estimation using Gibbs sampling [Gilks et al. 1996]. Section 4 describ es Datagr e ening.c om server, BashReduce tool and python pac k ages used in the pro ject. Experimental results are shown and ev aluated in section 5. Conclusion and future w ork are discussed in section 6. 2. GENERA TIVE LD A MODEL In this section, we will first briefly introduce the unigram model, a model generating docu- men ts b y single topics. Then we discuss LDA mo del applied in our pro ject. T o simplify the pro cess, w e define that a do cumen t is a collection of discrete words. 2.1. Unigram Mo del Unigram Mo del, which is a basic probability mo del, treats words as isolated elemen ts in eac h document [Nigam et al. 2000]. Assume that w e ha v e a corpus W of m do cuments, and a do cumen t d is a vector of n w ords, where each w ord is selected from a vocabulary of | V | w ords. W e define document d = ~ w = ( w 1 , w 2 , . . . , w n ), and corpus W = ( ~ w 1 , ~ w 2 , . . . , ~ w m ). In unigram mo del, the probabilit y of generating do cumen t d is: p ( ~ w ) = p ( w 1 , w 2 , . . . , w n ) = p ( w 1 ) p ( w 2 ) · · · p ( w n ) (1) Considering that the do cuments are interc hangeable with eac h other, the probabilit y of generating corpus W is: p ( ~ W ) = p ( ~ w 1 ) p ( ~ w 2 ) · · · p ( ~ w m ) (2) Supp ose the word probability of this corpus is N , and the probabilit y of word i in corpus is n i . Then written in full, ~ n = ( n 1 , n 2 , . . . , n V ) can b e representativ e as a multinomial distribution o ver V w ords vocabulary: p ( ~ n ) = M ult ( ~ n | ~ p, N ) = N ~ n V Y k =1 p n k k (3) where ~ p = ( p 1 , p 2 , . . . , p V ) is the vector of V w ords probability in vocabulary , and the probabilit y of the corpus is p ( ~ W ) = p ( ~ w 1 ) p ( ~ w 2 ) · · · p ( ~ w V ) = Q V k =1 p n k k . ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. T opic wo rds analysis based on LDA mo del A:3 2.2. LDA Model LD A mo del is a Bay esian hierarch y topic model [F ei-F ei and P erona 2005], generating topic w ords for each document with efficien tly reduced complexity . Also, LDA model characterize the possibility that one do cument may contain multiple topics, while unigram model only consider the single topic situation. Instead of calculating probability of word frequency using con tinually multiply in unigram mo del, LD A mo del maps a do cumen t of N w ords d = ~ w = ( w 1 , w 2 , . . . , w n ) to | T | latent topics. As the hierarc hy mo del shows in Figure 1, document-w ord distribution has b een mapped to document-topic distribution following topic-w ord distribution. Therefore, the general expression for word probability in topic mo del is: p ( w | d ) = T X j =1 p ( w | z j ) · p ( z j | d ) , (4) where z j is the j th topic sampled from a m ultinomial distribution of whic h the prior distri- bution is a Diric hlet distribution. Fig. 1 . Graphic representation of hierarc hy topic model. Eac h document is mapped to a mixture of | T | topics from document-topic distribution, and then eac h one of n w ords is generated under its latent topic by sampling from the topic-word distribution. In our pro ject, a do cumen t of n words d = ~ w = ( w 1 , w 2 , . . . , w n ) is generated in the follo wing process. Suppose that there are | T | latent topics, then the probabilit y of i th w ord w i in the giv en do cumen t can b e represented in the follo wing mixture: p ( w i ) = T X j =1 p ( w i | z i = j ) · p ( z i = j ) , (5) where z i is the topic to whic h i th word w i assigned, p ( w i | z i = j ) represents the probability of word w i assigned to the j th topic, and P T j =1 p ( z i = j ) gives the topic mixture prop ortion for the curren t sampled do cumen t. Assume that the corpus is a collection of | D | do cumen ts and the v ocabulary of this corpus has | V | unique w ords. Each do cument d of | N d | w ords is generated according to | T | topics. Let φ ( z = j ) w denote p ( w i | z i = j ), representing that w ord w i is sampled from the multinomial distribution on the j th topic z j . And let ψ ( d ) z = j denote p ( z i = j | d ), which is a m ultinomial distribution from | T | topics for do cument d . Therefore, the probabilit y of word w in do cumen t d is: p ( w | d ) = T X j =1 φ ( z = j ) w · ψ ( d ) z = j (6) ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. A:4 Xi Qi u In LDA mo del, ψ ( d ) sampled from D ir ichlet ( α ) is the prior distribution of multinomial distribution ψ ( d ) z = j [F orbes et al. 2011], and φ ( z ) sampled from symmetric D ir ichl et ( χ ) is the prior distribution of m ultinomial distribution φ ( z = j ) w . Then the m ultinomial distributions φ ( z = j ) w and ψ ( d ) z = j in LD A mo del is parameterized as follows: w i | z i , φ ( z i ) M ul t ( φ ( z i ) ) , φ ( z i ) D irichl et ( χ ) (7) z i | ψ ( d i ) M ul t ( ψ ( d i ) ) , ψ ( d i ) D irichl et ( α ) (8) In Eq.(7), χ is a | T | × | V | matrix, whic h is the initial v alue of w ord probabilit y sampled from | T | topics. And in Eq.(8), α = < α 1 , α 2 , . . . , α T > is the initial v alue of topic probability . χ and α are parameters of prior distribution of each m ultinomial distribution. W e assume b oth prior distributions to b e symmetric Diric hlet distributions. Therefore, χ is initialed the same v alue in the b eginning of sampling every do cument. Also, is initialed the same v alue in the b eginning of sampling every document. Figure 2 shows the Bay esian net work [Carey 2003] of LD A model. The plates represent rep eated sampling. In the left part, the inner plate represen ts generating each topic and eac h w ord under its topic repeatedly in a do cument d ; the outer plate represents repeated sam- pling topic proportion for each of | D | do cuments in corpus. And the right plate rep eatedly samples | T | parameters for M ul t ( φ ( z i ) ). Fig. 2 . Bay esian netw ork of LDA mo del. 3. GIBBS SAMPLING T o estimate parameters of LDA mo del, Lada Adamic and Eytan Adar use Exp ectation Maximization (EM) algorithm as the inference strategy [McCallum 1999]. In our pro ject, Gibbs sampling is the c hoice. Considering the p osterior distribution p ( w | z ), Gibbs sampling is a simple strategy to estimate φ and ψ . As a simple case of Mark ov c hain Mon te Carlo (MCMC) algorithm, Gibbs sampling aims at constructing a Mark ov c hain con v erging to the target distribution on z , and selecting samples approximating the inferred distribution. The sampling metho d b egins with initialing the v alue of vector z . Then it rep eatedly samples the z i from the conditional probability p ( z i = j | z − i , w i ) and transfers to the next state of Mark ov chain b y updating the probabilit y function using the newly sampled z i . In our pro ject, the probability function of Gibbs sampling is: ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. T opic wo rds analysis based on LDA mo del A:5 P ( z i = j | z − i , v i ) = n ( v i ) − i,j + χ n ( . ) − i,j + V χ · n ( d i ) − i,j + α n ( d i ) − i,. + T α P T j =1 n ( v i ) − i,j + χ n ( . ) − i,j + V χ · n ( d i ) − i,j + α n ( d i ) − i,. + T α , (9) where z i = j stands for the assignment of w ord v i , the i th word in a document, to topic j ; and z − i represen ts all z k ( k 6 = i ) assignmen ts. n ( v i ) − i,j is the n umber of times v i assigned to topic j ; n ( . ) − i,j is the n umber of words in v o cabulary assigned to topic j ; n ( d i ) − i,j is the n umber of w ords in document d i assigned to topic j ; all n um b ers of w ords do not include the curren t assignmen t z i = j . The detailed sampling pro cess is as follo ws: (1) F or i = 1 to N , where N is the num b er of word in the curren t do cumen t, iteratively initial z i as one random integer b et ween 1 to T . This N -sized Z vector is the initial state of this Mark ov c hain. (2) F or i = 1 to N , transfer to next state of this Marko v chain b y iteratively assigning w ord v i to its topic using Eq.(9). (3) Run step 2 for b iterations until it reaches the conv ergent state. F or i = 1 to N , the curren t v alue of z i is selected as a sample. The v alue of b is called Burn-in p eriod in Gibbs sampling. Eq.(9) is the function calculating the p osterior distribution o ver w ord distribution in eac h do cumen t. Therefore, we can deriv e the conditional probability function estimating φ and ψ for ev ery unique w ord w in a document b y remo ving the word tag i in Eq.(9): ˜ φ ( z = j ) w = n ( v ) j + χ n ( . ) j + V χ , ˜ ψ ( d ) z = j = n ( d ) j + α n ( d ) . + T α , (10) where n ( v ) j is the n umber of times v assigned to topic j ; n ( . ) j is the n umber of w ords in v o cabulary assigned to topic j ; n ( d ) j is the num b er of words in do cument d assigned to topic j ; n ( d ) . is the n umber of all words in document d assigned to its topic. 4. DA T A PREPROCESSING In this section, we discuss the operations of data prepro cessing for LD A mo del. Datagr e en- ing.c om serv er, Python pac k ages and BashReduce tool implemen ted in our pro ject will b e in tro duced in the follo wing. 4.1. Datagreening.com The input data for analyzing in LD A mo del are emails sen t to our locally registered accoun t at Ob ama.c om . In our pro ject, these emails are received through Datagr e ening.c om , whic h is an email server dev eloped by our research group. This serv er pro vides email service with clean energy and collects researc h data of carb on footprint in the mean time. Also, capturing the energy cost in datacen ters of p opular email pro viders, this greening server helps further researc h in p erformance of cloud computing. 4.2. Python packages The do wnloaded emails are pro cessed to do cumen ts consisting of unique terms using Python NumPy pack age [Developers 2013] and Natural Language T o olkit (NL TK) pac k age [Dan Garrette and Nothman 2013]. NumPy is the fundamen tal pack age for scien tific com- puting with Python. W e install the NumPy pack age to offer the prop er back environmen t ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. A:6 Xi Qi u for NL TK pac k ages and include sorting algorithm functions for Python co de. NL TK is a Python platform for text processing. Some of the NL TK pack ages are installed for ra w con- ten t tokenizing, word stemming and stop w ords removing in our pro ject. F ollo wing is the list of pac k ages w e installed: (1) banktree tag pac k age; (2) stop w ord pac k age; (3) wn pack age. 4.3. BashReduce to ol No w we format the unique terms learned b y the abov e Python program as: N w ord 1 : count 1 , w or d 2 : count 2 , ..., w ord n : count n where N is the num b er of unique terms in the curren t document; wor d i is an integer that indexes this term in the v o cabulary . BashReduce to ol is used here to calculate the w ord coun t. BashReduce is a parallel computing to ol applying online MapReduce [Dean and Ghe- ma wat 2008] model to bash en vironment. According to BashReduce op eration instruction, w e begin with sp ecifying the host list to b e b ash.xi.0 and b ash.xi.1 using BashReduce op- tion ’br h’ . Th us, w e ha ve tw o instances for parallel calculating word count. Then we write Python programs map.py and r e duc e.py . Program map.py maps each word in w ord set to pattern (word,1); while r e duc e.py receiv es suc h patterns and sum the same patterns to generate the (w ord, coun t) result and implements. W e use BashReduce options ’-m’ and ’-r’ to run map.py and r e duc e.py resp ectiv ely . Note that, b oth input and output paths for map.py and r e duc e.py need to b e defined b y user. Running on tw o instances implemented BashReduce, it costs 3’41” to finish the word count program, ignoring the net work latency . Comparing with the time cost 5’18” when calculating lo cally , it ac hieve almost 30% sp eedup. 5. EXPERIMENT AL RESUL T In our results, we use emails sen t to our lo cally registered accoun t by Ob ama.c om . There are total 58 emails in this account with a v ocabulary size of | V | = 1118 w ords. T o use Gibbs sampling more efficien tly , we first fix the v alue of burn-in p erio d b using the data learned in section 4. Then w e show the experimental result of top 15 words generated under 5 laten t topics. And w e define precision rate to ev aluate the predictiv e p o wer. 5.1. Burn-in p erio d choice W e define the num ber of topics | T | = 300 and use 3 distinct v alues for initialization. Then the con vergen t sample result ln P ( w | z ) will b e obtained when choosing the appropriate iteration n umber. Figure 3 shows the conv ergent pro cess for Gibbs sampling. Starting at 3 distinct v alues, the sample result tends to gather and reach a constant v alue indep enden t with all three initial v alues after 500 iterations. 5.2. Exp erimental Result In our exp eriment, parameters χ and α are assigned v alues 0.01 and 50 /T resp ectiv ely . Laten t topics are selected after 500 iterations in Gibbs sampling. And w ords are generated under 300 topics. T able 1 giv e the example of top 15 w ords generated under 4 topics. 5.3. Result Analysis T o compare the LDA model applied in our pro ject with other models, we in tuitively define a w ord list of size | C | = 15, and each w ord in the target list works as an iden tifier to represent the information of this corpus. ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. T opic wo rds analysis based on LDA mo del A:7 Fig. 3 . Bay esian netw ork of LDA m odel. T able I. Example of top 15 wo rds generated under 5 topics. T opic1 T opic2 T opic3 T opic4 T opic5 action winner ohio display president organize enter party color obama email guest help none contact make action need medium supporter take organize gov ernor screen committee get nbsp state input email ofa washington authorize block democrat people receive friend auto let health contribution make http w ashington fight entry k asich label work send email campaign leav e kno w care state pay nbsp candidate Box tick e republican see support friend prize voter table country address resident W ork Arial stay a W ords in each topic list is able to help reveal what corresponding topic it can be. According to the table, a email from Ob ama.c om is lik ely consisting of health care (T opic1), new con tributions (T opic2), local news (T opic3), and president information (T opic4). c orr e ct list = { ob ama, ohio, he alth, washington, governor,c amp aign, r epublic an, pr esident, p arty, supp orter, state, c ommitte e,demo cr at, voter, work } And the target w ord list are defined as part of the correct list. 5.3.1. Evaluation measure. W e use precision as a measure to ev aluate the exp erimental re- sults. The definition of precision is defined as follow: pr ecision = n corr ect n total (11) ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. A:8 Xi Qi u Fig. 4 . Precision rate of LDA model and TF-IDF model when | T W | = 5. Precision rate of b oth mo del grows when | T G | increases, for the reason that larger | T G | ma y lead to more matches. Considering the limited | T W | , the precision rate of LDA mo del falls b elo w TF-IDF mo del when | T G | > 8. Fig. 5 . Precision rate of LDA model and TF-IDF model when | T W | = 10. Precision rate of b oth model grows when increases | T G | . Higher precision rate of LD A model than TF-IDF model illuminates that the predictive p ow er of LDA mo del is stronger than TF-IDF mo del, when | T W | is large enough. ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. T opic wo rds analysis based on LDA mo del A:9 Fig. 6 . Precision rate of LDA model and TF-IDF model when | T W | = 15. Precision rate of b oth model grows when increases | T G | . And when | T W | = 15, the precision rate of LDA model is almost 53.96% higher than TF-IDF model. F or eac h do cumen t with | T | topic w ord list, we compare the top k w ords of each topic w ords list with the w ords in curren t target w ord list. If an y matc h is captured, then w e mark this do cument as ’correct’. n corr ect in Eq.(11) represen ts the n umber of ’correct’ do cumen ts in this corpus, and n total stands for the total n umber of do cuments in this corpus. 5.3.2. Compa rison mo del. W e choose TF-IDF mo del as a comparison.TF-IDF, short for T erm F requency-In v erse Do cument F requency mo del, a n umerical statistic representing the relation b etw een the k ey w ord and the document, is one of the ma jor w eight factors in text mining. It is often used for text classification by ranking a do cument’s relev ance given a user query . Assume that D is the total num b er of dicumen ts in this corpus; f ( t, d ) is the ra w frequency of a term in a do cument, then the expression of this model is: tf id f ( t, d, D ) = tf ( t, d ) × id f ( t, D ) (12) where id f ( t, D ) is defined as: id f ( t, D ) = log | D | |{ d ∈ D : t ∈ d }| (13) Therefore, a high weigh t in TF-IDF is reached by a high term frequency and a low do cumen t frequency of the term in the whole collection of do cumen ts; the weigh ts hence tend to filter out common terms and select the terms with low er probability to be the words that distinguish do cumen ts. 5.3.3. Predictive p ow er. Let | T G | b e denoted as the size of target word list, and | T W | as the size of topic word list. W e ev aluate the predictive p o w er by comparing precision rate for LDA mo del and TF-IDF mo del in cases with different | T W —. The following Figure 4, Figure 5 and Figure 6 show the comparison of LDA mo del and TF-IDF mo del where x -co ordinate represents different v alues of | T G | and y -co ordinate represen ts precision rate. ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY. A:10 Xi Qi u 6. CONCLUSION In this pro ject, w e apply LDA mo del to analyze and vilsualize topic words of emails from Ob ama.c om to accoun ts registered in Colum bus, Ohio. W e use Gibbs sampling to estimate topic and w ord distribution. Carbon-free serv er Datagr e ening.c om , pareleling tool BashRe- duce and Python pack ages are used in data preprocessing. The experimental result sho ws the MapReduce metho d in our pro ject efficiently reduces the time cost of w ord count pro- gram and the predictiv e pow er of LDA mo del applied in our pro ject is obviously stronger than TF-IDF mo del. Ev ery new do cumen t adding to this corpus lead to another sampling pro cess for it, highly increasing the time cost. Considering this dra wbask, p ossible future w ork of our pro ject is lik ely to b e sampling only new added words instead of a new added document. REFERENCES Lada A. Adamic and Eytan Adar. 2009. How to search a so cial netw ork. @MISC. (2009). abs/cond- mat/0310120 David M. Blei, Andrew Y. Ng, and Mic hael I. Jordan. 2003. Laten t Diric hlet Allo cation. J. Mach. L e arn. R es. 3 (Marc h 2003), 993–1022. http://dl.acm.org/citation.cfm?id=944919.944937 Vincent J Carey. 2003. Graphical models: Metho ds for data analysis and mining. J. Amer. Statist. Asso c. 98, 461 (2003), 253–254. Peter Ljunglf Dan Garrette and Jo el Nothman. 2013. Python text pro cessing pack age NL TK. (2013). http: //www.nltk.org/api/nltk.html Jeffrey Dean and Sanja y Ghema w at. 2008. MapReduce: simplified data processing on large clusters. Com- mun. ACM 51, 1 (2008), 107–113. NumPy Developers. 2013. Python scientific computing pack age NumPy . (2013). http://www.nump y .org L. F ei-F ei and P . Perona. 2005. A Ba yesian hierarc hical mo del for learning natural scene categories. In Computer Vision and Pattern R e co gnition, 2005. CVPR 2005. IEEE Computer So ciety Confer enc e on , V ol. 2. 524–531. DOI: http://dx.doi.org/10.1109/CVPR.2005.16 Catherine F orb es, Merran Ev ans, Nicholas Hastings, and Brian P eacock. 2011. Statistic al distributions . John Wiley & Sons. WR Gilks, S Richardson, DJ Spiegelhalter, and others. 1996. Mark ov Chain Monte Carlo in Practice. 1996. New Y ork: Chapman Hal l/CRC 486 (1996). Ying Liu, B.J. Ciliax, K. Borges, V. Dasigi, A. Ram, S.B. Na v athe, and R. Dingledine. 2004. Comparison of t w o sc hemes for automatic k eyw ord extraction from MEDLINE for functional gene clustering. In Computational Systems Bioinformatics Confer enc e, 2004. CSB 2004. Pro c e e dings. 2004 IEEE . 394– 404. DOI: http://dx.doi.org/10.1109/CSB.2004.1332452 Andrew McCallum. 1999. Multi-label text classification with a mixture model trained b y EM. In AAAI99 Workshop on T ext L e arning . 1–7. Kamal Nigam, AndrewKachites Mccallum, Sebastian Thrun, and T om Mitchell. 2000. T ext Classifica- tion from Labeled and Unlabeled Documents using EM. Machine Le arning 39, 2-3 (2000), 103–134. DOI: http://dx.doi.org/10.1023/A:1007692713085 Michal Rosen-Zvi, Thomas Griffiths, Mark Steyv ers, and Padhraic Smyth. 2004. The Author-topic Mo del for Authors and Documents. In Pr oc e e dings of the 20th Confer enc e on Unc ertainty in Artificial Intel ligenc e (UAI ’04) . AUAI Press, Arlington, Virginia, United States, 487–494. Christopher Stewart. 2012. A protot yp e greening service that p ow ers email with clean energy . @MISC. (2012). http://www.datagreening.com Chi W ang, Jiaw ei Han, Y un tao Jia, Jie T ang, Duo Zhang, Yintao Y u, and Jingyi Guo. 2010. Mining Advisor- advisee Relationships from Research Publication Networks. In Pr o c e edings of the 16th ACM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining (KDD ’10) . ACM, New Y ork, NY, USA, 203–212. DOI: http://dx.doi.org/10.1145/1835804.1835833 Jeremy Zawodny. 2009. A Bare-Bones MapReduce. @MISC. (2009). http://www.linux- mag.com/id/7407/ ACM Journal Name, V ol. V, No. N, Article A, Publication date: January YYYY.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment