Exploiting Agent and Type Independence in Collaborative Graphical Bayesian Games
Efficient collaborative decision making is an important challenge for multiagent systems. Finding optimal joint actions is especially challenging when each agent has only imperfect information about the state of its environment. Such problems can be …
Authors: Frans A. Oliehoek, Shimon Whiteson, Matthijs T.J. Spaan
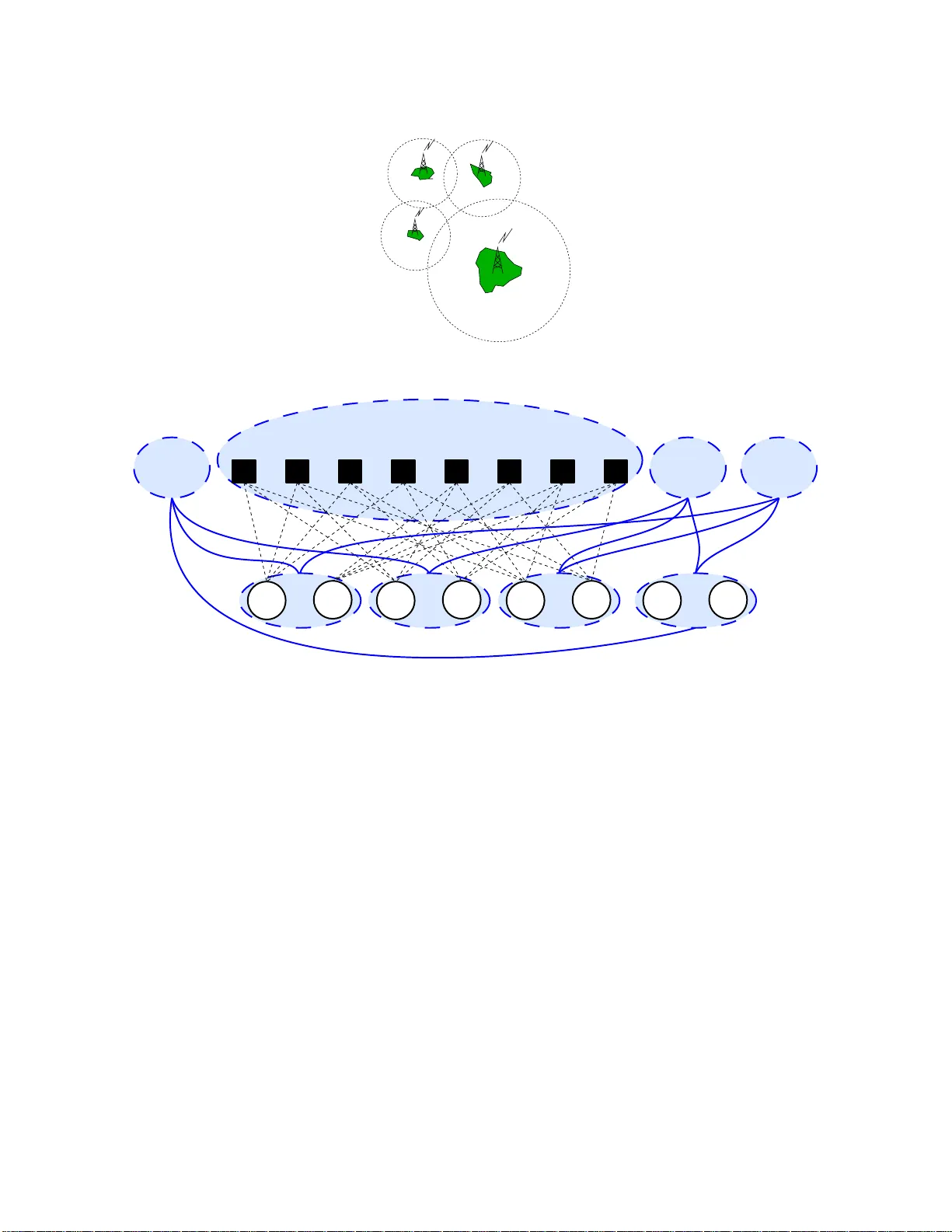
Exploiting Agent and T ype Independence in Collabora ti ve Graphica l Ba yesian Games Frans A. Oliehoek 1 , Shimon Whiteson 2 , and Matthijs T .J. Spaan 3 1 CSAIL, Massachusetts Institute of T echnology , C ambrid ge, MA, USA, fao@csail.m it.edu 2 Informatics Institute, Univer sit y of Amsterdam, Amsterdam, The Netherlands, s.a.whiteso n@uva.nl 3 Institute for Systems and Robotics, Institut o S uperio r T ´ ecnico, Lisbon, Portugal, mtjspaan@is r.ist.utl.pt Abstract Efficient collaborati ve decision making is an important ch allenge for mu lt iagent systems. Finding optimal joint actions is especially challenging when each agent has only imperfect information about the state of its en vironment. Such problems can be modeled as collaborative Bayesian games in which each agent recei ves priv ate information in the form of its type . Ho weve r, represe nting and solving such games requ ires spa ce and computation time exponential in the number of agents. This article introduces collabor ative graph ical Bayesian games (CGBGs) , which facilitate more ef ficient collaborativ e decision making by decomposing the global payo ff function as the sum of local payof f functions that depen d on only a fe w agents. W e propose a frame work for the ef ficient solution of CGBGs based on the insight that they posses two different types of independe nce, which we call ag ent independ ence and type indepen dence . In particular , we present a factor grap h representation that captures bo th forms of independ ence and thus enables efficient solutions. In addi- tion, we sho w ho w this representation can pro vide lev erage in sequen tial tasks by using it to con struct a nov el method for decentralized par ti ally observa ble Markov decision pro cesses . Experimental results in both ran- dom and benchmark tasks demonstrate the improved scalability of our methods compared to se veral existing alternativ es. 1 keywo rds: reaso ning under uncertainty , decision-theoretic plann ing, multiagent decision making, collabora- tiv e Bayesian games, decentralized partially observ able Markov decision processes 1 Introd uction Collaborative mu ltiagent systems are of significan t scientific inter est, not only because they can tackle inher- ently distributed problems, but also becau se they facilitate the decom position of problem s too c omplex to be tackled by a single agent (Huhns, 1 987; Sycara, 19 98; Panait and Luke, 2005; Vlassis, 200 7; Bus ¸ oniu et al., 2008). As a r esult, a fundamental q uestion in artificial intelligen ce is how best to design con trol systems for collaborative multiagen t systems. In other words, how s ho uld teams of agents act so as to most effecti vely achieve co mmon goals? When uncertainty and many agents are in v o lved, this question is particularly challeng- ing, and has not yet been answered in a satisfactory way . 1 Parts of this pape r serve as a basi s for the papers prese nted at UAI ’12 (Oliehoek et al., 2012) and AAMAS’13 (Ol iehoek et al., 2013). 1 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n Figure 1: I llustration of multiagent decision mak ing with imp erfect infor mation. Both agents ar e loca ted n ear house 2 and kn ow that it is o n fire. Howe ver , each ag ent receives o nly a n oisy ob servation of the single neighbo ring house it can observe in the distance. A key challeng e of collaborative multiagent decision making is the presen ce o f imperfect information (Harsanyi, 1967 –1968 ; Kaelbling et al., 199 8). Even in single-agen t setting s, agen ts may have inco mplete knowledge of the s tate of their en vironme nt, e.g., due to noisy sensors. Ho wever , in multiagent settings this problem is often greatly exacerbated, as agents ha ve access only to their own sensors, typically a small fraction of those of the complete system. In some cases, imper fect information can be ov erco me by sharin g sensor readings. Howe ver, due to bandwidth limitatio ns an d synchron ization issues, comm unication -based solutions are often brittle and scale poorly in the number of agents. As an example, consider th e situation depicted in Fig. 1 . After an emergen cy c all by the owner o f house 2, two firefighting agents are dispatched to fig ht t h e fire . While each agent knows there is a fire at house 2, the agen ts are not sure whether fir e h as spread to the neighbo ring hou ses. Each agent can potentially obser ve flames at one of th e n eighbo ring hou ses (ag ent 1 o bserves house 1 and agent 2 observes hou se 3 ) but neither has perfect information about the state of the houses. As a result, ef fective decision making is difficult. If agent 1 observes flames in house 1, it may be tempted to fight fire ther e rather than at hou se 2. Howe ver , the ef ficacy of do ing so d epends on whether agent 2 will stay to fight fire in house 2, which in tu rn depen ds on wh ether agent 2 observes flames in house 3, a fact unkn own to agent 1. Strate gic games , the traditional mod els of ga me theor y , are poo rly suited to m odeling such problems because they assume tha t the re is only on e state, wh ich is known to all the agen ts. In co ntrast, in the example o f Fig. 1, each age nt h as only a p artial view o f the state, i.e., f rom each agent’ s ind ividual p erspective, m ultiple states ar e possible. Such p roblems o f m ultiagent d ecision making with imper fect in formatio n can b e mo deled with Bayesian games (BGs) (Harsanyi, 1967–1 968 ; Osborn e and Rubinstein, 1 994). In a BG, each agen t ha s a type that specifies wh at priv ate infor mation it holds. For example, an agent’ s type may correspon d to an observation that it m akes but th e other agen ts do not. Before the agents select actions, their typ es are drawn from a distribution. Then , the payoffs they recei ve depend not only on the actions they choose, b ut also on their types. Problems in which the ag ents ha ve a co mmon go al can be mod eled as collaborative Bayesian games (CBGs) , in which all ag ents share a single global payoff f unction. Unfo rtunately , solving CBGs effi cien tly is difficult, a s both the space needed to represen t the payoff function and th e co mputation time need ed to find optimal joint actions scale exponentially with the number of agents. In this article, we in troduce collabo rative graphical Bayesian games (CGBGs) , a new framew ork designed to facilitate more efficient collaborative d ecision making with imp erfect information. As in strategic games (Guestrin et al., 2002; K ok and Vlassis, 2006), global payoff functions in Bayesian games can often be decom- posed as the sum of local payo ff functions , each of which de pends on the actions of only a f ew agents. W e call such gam es graphical because this d ecompo sition can be expressed as an in teraction hyper graph that specifies 2 which agents participate in which local payoff function s. Our main contribution is to d emonstrate how this grap hical structure can be exp loited to solve CGBGs more efficiently . Our approach is based on the critical insight that C GBGs contain two fundamen tally different types of independen ce. L ike graphical s trategic games, CGBGs possess ag ent indepen dence : each local payoff function d epends on only a subset o f the agents. Howev er, we identify that GBGs also possess type in depen- dence : since only one type per agent is realized in a gi ven game, th e e xp ected payoff decomposes as the sum of contributions that depend on only a subset of type s. W e propo se a facto r graph repre sentation tha t captures both agent and type independ ence. Then, we show how su ch a factor graph can be u sed to find optim al jo int policies via non serial dy namic pr ogramming (Bertele and Brioschi, 197 2; Guestrin et al., 20 02). While this a pproach is faster th an a na ¨ ıve alternativ e, we prove that its computation al co mplexity remains exponential in the n umber o f types. Howev er, we also show how the same factor grap h facilitates even mo re efficient, scalable co mputation of approximate so lutions v ia M A X - P L U S (Kok and Vlassis, 2 006), a message-passing algo rithm. In particular, we prove that each iteratio n of max-plu s is tractable for small local neighb orho ods. Alternative solution appro aches for CGBGs can be fo und amo ng existing techniqu es. For example, a CGBG can be converted to a m ultiagent influence d iagram (MAI D) (K oller and Milch, 20 03). Howe ver , since the resu lting MAID has a single s tro ngly c onnected comp onent, the divide and conqu er techn ique pro- posed by K oller and Milch r educes to br ute-for ce search. An other appr oach is to convert CGBGs to non- collaborative grap hical strate gic games, for which ef ficient solution algorithms e x ist (V ickrey and K oller, 2002; Ortiz and Kearns , 2003; Daskalakis and Papadimitriou, 2006). Howe ver, the co n version p rocess essentially strips away the CGBG’ s type independ ence, resulting in an exp onential increase in the worst-case size of the payoff function . CGBGs can also be mode led as constraint optimizatio n problem s (Modi et al., 2 005), for wh ich some methods implicitly e xplo it type ind ependen ce (Olieh oek et al., 201 0; Kumar and Zilberstein, 2010). Howev er, these methods do not explicitly identify type indepe ndence and do not exploit agent indepen- dence. Thus, the k ey advantage o f the appro ach pr esented in this article is the simu ltaneous exploitation o f both agent and typ e ind epende nce. W e pr esent a range of exp erimental re sults th at dem onstrate th at this advantage leads to better scalability than se veral alternatives with respect to the number of agents, actions, and types. While CGBGs model an imp ortant class of collab orative decision-m aking problems, they apply only to one-sho t settings, i.e., each age nt ne eds to select only one actio n. Howe ver , CGBG so lution metho ds can also provide substantial le verage in s eq uential tasks, in which agents tak e a series of actions ov er time. W e illustrate the ben efits of C GBGs in such settings by u sing them to construct a novel meth od for solving decentralized partially observab le Markov decision p r ocesses ( Dec-POMDPs) (Ber nstein et al., 2 002). Ou r m ethod extend s an e xisting approach in which each stage of the Dec-POMDP is modeled as a CBG. In p articular, we sho w how approximate inference and factored v alue fun ctions can be used to reduce the problem to a set of CGB Gs, which can be solved using our novel appr oach. Additional experime nts in multiple Dec-POMDP ben chmark tasks demo nstrate better scalability in the numb er of agents than se veral alterna ti ve methods. In particular, for a sequential version of a firefigh ting task as described ab ove, we were able to scale to 1000 ag ents, wher e previous approaches to Dec-POMDPs have not been demonstrated beyond 20 agents. The rest of th is paper is o rganized as follows. Sec. 2 provides b ackgro und by introducin g co llaborative (Bayesian) gam es and their solution m ethods. Sec. 3 in troduc es CGBGs, which captu re both agent and type indepen dence. This section also presents solution methods that e xp loit such independen ce, a nalyzes their com- putational complexity , and em pirically evaluates their pe rforma nce. In Sec . 4, we show th at the imp act o f o ur work extends to seque ntial tasks by presenting a nd evaluating a new Dec -POMDP m ethod based on CGBGs. Sec. 5 discusses related work, Sec. 6 discusses possible directions for future w or k, and Sec. 7 conclude s. 3 2 Backgrou nd In this section, we provide backgro und on v ario us game-theo retic models for collaborativ e decision mak ing. W e start with the well-known framework of s trate gic games and discuss their graphical coun terparts, which allow for compact represen tations of problems with many agen ts. Next, we discuss Bayesian g ames , which take into acco unt different priv ate in formatio n av ailable to each ag ent. Th ese mo dels provide a f ound ation for understan ding collabo rative graphical Bayesian games , the frame work we propose in Section 3. 2.1 Strategic Games The strate gic game (SG) fram ew ork (Osborn e and Rubinstein, 19 94) is probably the mo st studied of all game- theoretic m odels. Strategic games are also called n ormal form game s or ma trix ga mes , since two-ag ent games can be represented by matrices. W e first introduce the fo rmal m odel an d then discuss so lution m ethods and compact representatio ns. 2.1.1 The Strategic Game Model In a strate gic game, a set of agents participate in a one-shot interaction in which they each select an action. The outcome of the game is determ ined by the co mbination of selected ac tions, which leads to a payoff for each agent. Definition 2.1. A strate gic game (SG) is a tuple h D , A , h u 1 ,... u n ii , where • D = { 1 , . . . , n } is the set of n agents, • A = × i A i is the set of joint actions a = h a 1 , . . . , a n i , • u i : A → R is the payoff function of agent i . This article focuses on collabor ativ e decision making: settin gs in which the agents have the same goal, which is modeled by the fact that the payoffs the agents receiv e are identical. Definition 2.2. A collaborative strate gic g ame (CSG ) is a s trategic game in which each ag ent has the same payoff function : ∀ i , j ∀ a u i ( a ) = u j ( a ) . In the collabo rative case, we drop th e sub script on the payoff fun ction and simply write u . CSGs are also called identical payoff games or team games . 2.1.2 Solution Concepts A solution to an SG is a description of what ac tions each agent should take. While many so lution concepts have been proposed , one of central impor tance is the equilibrium introdu ced by Nash (1950). Definition 2.3. A join t action a = h a 1 , . . . , a i , . . . , a n i is a Nash equilibrium (NE) if and only if u i ( h a 1 , . . . , a i , . . . , a n i ) ≥ u i ( a 1 , . . . , a ′ i , . . . , a n ) , ∀ i ∈ D , ∀ a ′ i ∈ A i . (2.1) Intuitively , an NE is a joint action suc h that no agen t can improve its payoff by changing its own action. A game may have zero, one or multiple NEs. 2 When there are multiple NEs, the concept of P ar eto optimality can help distinguish between them. 2 Nash pr oved t hat e very finite game contains at least one NE if ac tions are all owed to be played with a particular probabi lity , i.e., if mixed strate gies are allowed . 4 Definition 2.4. A jo int ac tion a is P ar eto optimal if there is no o ther joint action a ′ that specifies at least the same payoff for ev ery agent and a high er payoff for at least one agent, i.e., there exists no a ′ such that ∀ i u i ( a ′ ) ≥ u i ( a ) ∧ ∃ i u i ( a ′ ) > u i ( a ) . (2.2) If there does exist an a ′ such that (2.2) hold s, then a ′ P areto domina tes a . Definition 2.5 . A jo int action a is a P ar eto-o ptimal Nash equilibrium (PONE) if and only if it is an N E and there is no other a ′ such that a ′ is an NE and Pareto do minates a . Note that this definition does not require that a is P areto optimal. On the contrary , there may exist an a ′ that dominates a but is not an NE. 2.1.3 Solving CSGs In co llaborative strategic g ames, each max imizing entry of the payo ff function is a PONE. Therefor e, find ing a PONE req uires only loop ing over all the entries in u and selecting a m aximizing o ne, which takes time linear in the size of the game. Howev er, coordin ation issues can arise when sear ching for a PONE with a decentralized algorithm, e.g., when there are multiple maxima. En suring that the agents select the same PONE can be accomplished by imposing certain social conv entio ns or throu gh repeated interactions (Boutilier, 1996). In this article, we assume th at the gam e is solved in an of f-lin e ce ntralized plan ning phase and th at the joint strategy is then distributed to the agen ts, who merely execute the actions in the on-lin e phase. W e fo cus on the design of cooperative teams of agents, for which this is a reasonable assumption. 2.2 Collaborative Graph ical Strategic G ames Although CSGs are conceptually easy to solve, the g ame d escription scales exponentially with the num ber of agents. Th at is, the size of the pay off function and thus the time req uired for th e trivial alg orithm is O ( | A ∗ | n ) , where | A ∗ | denotes th e size of the largest ind ividual action set. This is a major obstacle in the repre sentation and solutio n of SGs for large values of n . Many games, however , possess indepen dence because no t all agents need to coor dinate directly (Guestrin et al., 2 002; Kearns et al., 2001; K ok and Vlassis, 20 06). This idea is formalized by collaborative graphical strategic games. 2.2.1 The Collaborative Graphical SG Model In co llaborative gr aphical SGs, the p ayoff function is decom posed into loca l payo ff functions , each having limited scope , i.e., only subsets of agents participate in each local payoff function . Definition 2 .6. A collab orative graphica l strate gic ga me (CGSG) is a CSG whose payo ff fun ction u decom- poses over a numb er ρ of local payoff functions U = { u 1 , . . . , u ρ } : u ( a ) = ρ ∑ e = 1 u e ( a e ) . (2.3) Each local p ayoff function u e has scope A ( u e ) , the subset o f agen ts that particip ate in u e . Here a e denotes the local joint action , i.e., the profile of actions of the agents in A ( u e ) . Each loca l pay off c ompon ent can be interpre ted as a hyper-edge in an interaction hyp er-gr ap h I G = h D , E i in which the n odes D are agents and th e hyper-edges E are local payoff functio ns (Nair et al. , 20 05; Oliehoek et al., 2008c). T wo (or more) agents a re con nected b y such a (hyper-)edge e ∈ E if and only if they 5 participate in the correspon ding lo cal payoff fu nction u e . 3 Note that we shall abuse notatio n in that e is used as an in dex in to the set of local payoff functions and as an element o f the s et of scopes. Fig. 2a s hows the interaction hy per-graph of a five-agent CGSG. If only two agen ts participate in e ach local pay off function, the interaction hyper-graph reduces to a regular grap h and the frame work is identical to th at of coor dination graphs (Guestrin et al., 2002; K ok and Vlassis, 200 6). CGSGs are als o similar to gr aph ical g ames (K ear ns et al., 2001; K ear ns, 2007; Soni et al., 2007). Howe ver, there is a cr ucial difference in the meaning of the term ‘g raphical’. In CGSGs, it indicates that the sing le, common payoff fu nction ( u = u 1 = · · · = u n ) de composes into local payoff functions, each in volving subsets of agents. However , all agen ts par ticipate in the comm on payoff function ( otherwise they would be irrelevant to the game). In contrast, graph ical ga mes are typically not collaborative. Thus, in that context, the term indicates that the individua l payoff f unctions u 1 , . . . , u n in volve subsets of agents. Howe ver, th ese individual payoff functio ns do not decomp ose into sums of local payoff functions. 2.2.2 Solving CGSGs Solving a c ollaborative gra phical strategic game entails finding a m aximizing joint action. Howe ver, if the representatio n of a p articular p roblem is compa ct , i.e . exponen tially smaller th an its non-g raphical (i.e., CSG) representatio n, then the trivial alg orithm o f Sec. 2 .1.3 r uns in exponential time. Non-serial dyn amic pr ogram- ming (NDP) (Bertele and Brioschi, 19 72), also known as va riable elimination ( Guestrin et al., 200 2; Vlassis, 2007) and b ucket elimination (Dechter, 1999), can find an optimal solution much fas ter by exploiting t h e struc- ture of the problem . W e will explain NDP in more detail in Sec. 3.4.1. Alternatively , M A X - P L U S , a message-passing algo rithm describ ed fu rther in Sec. 3 .4.2, can be applied to the interaction grap h (K ok and Vlassis, 20 05, 2 006). In p ractice, M A X - P L U S is often much faster than NDP (K ok and Vlassis, 200 5, 2006; Farinelli et al., 20 08; Kim et al., 2010). Howe ver, wh en more than two agents participate in the same h yper-edge (i.e., wh en th e inter action gr aph is a hyper-graph) , message passing cann ot be con ducted on the hyp er-graph itself. Fortun ately , an in teraction hy per-graph can be translated in to a factor graph (Kschischang et al., 2001; Loeliger, 2004) to which M A X - P L U S is applicable. The resulting factor graph is a bipartite graph containing one set of nodes for all the local payoff fu nctions and another for all the agents. 4 A local pa yoff function u e is co nnected to an ag ent i if an d only if i ∈ A ( u e ) . Fig. 2 illustrates the relation ship between an interaction hyper-graph and a factor graph. It is also possible to con vert a C GSG into a (non-collab orative) graphical SG by combining all payoff func- tions in which an agent participates into one normalized, individual pay off fu nction. 5 Sev eral methods f or solv- ing gra phical SGs are then applicable (V ickrey and K oller, 200 2; Ortiz and K earns, 2 003; Daskalak is and Papadimitriou , 2006). Unfortunate ly , the individual pay off functions resulting from th is transformation are exponentially larger in the worst case. 2.3 Bayesian Games Although strategic gam es p rovide a rich mod el o f interactions between ag ents, they assume that each agen t has c omplete k nowledge o f a ll relev ant inf ormation and can therefo re p erfectly predict the payo ffs that result from each joint action. As such, they cannot explicitly represent cases where agents possess pri vate information that influen ces the effects of actions. For example, in the firefighting example depicted in Fig. 1, there is n o natural way in a strate gic g ame to represen t th e fact that each a gent has different informatio n abo ut th e state 3 This constitutes an edg e-based dec omposition , which stands in cont rast to age nt-based decomposit ions (Kok and Vlassis, 2006). W e focus on edge-b ased de compositions because they are more general. 4 In the t erminology of factor graphs, the loca l payof f functions correspond to fa ctors and the agent s to va riables whose domains are the agents’ acti ons. 5 This corre sponds to con verting an edge-based representation to an agent-b ased re presentatio n (Ko k and Vlassis, 2006). 6 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n 1 2 3 4 5 u 1 u 2 u 3 u 4 (a) An i nteraction hyper-gra ph. P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n 1 2 3 4 5 u 1 u 2 u 3 u 4 (b) The c orresponding factor graph. Figure 2: A CGS G with fi ve agents. I n (a), each node is an ag ent and each hyper-edge is a local p ayoff fu nction. In (b), the circular nodes are ag ents an d the square n odes are lo cal payoff fu nctions, with edges in dicating in which local payoff function each agent participates. of the h ouses. In more complex prob lems with a large number of agen ts, modeling private informa tion is ev en more importan t, since assuming that so many agents hav e perfect kno wledg e o f the complete state of a complex en vir onment is rarely realistic. In th is section, we describe Bayesian games , which augm ent the strategic game framework to explicitly model pri vate i n formation . As bef ore, we focus on the collaborativ e case. 2.3.1 The Bayesian Game Model A Bayesian g ame, also called a strate gic ga me of impe rfect in formation ( Osborne and Rubinstein, 1994) is an augmen ted strategic g ame in which the players hold priv ate information. The pr iv ate inf ormation o f agen t i defines its type θ i ∈ Θ i . The payoffs the agents receiv e depend not only on their actions, but also on their types. Formally , a Bayesian game is defined as follows : Definition 2.7. A Ba yesian game (BG) is a tuple h D , A , Θ , Pr ( Θ ) , h u 1 ,... u n ii , where • D , A are t h e sets of agents and joint actions as in an SG, • Θ = × i ∈ D Θ i is the set of joint types θ = h θ 1 , . . . , θ n i , • Pr ( Θ ) is the distribution ov er joint types, and • u i : Θ × A → R is the payoff function of agent i . In many prob lems, the types are a p robab ilistic fu nction of a hid den state, i.e., based on a hidden st ate, there is s o me probab ility Pr ( θ ) fo r each j o int type. This is typically the case, as in the e xa mple belo w , when an agent’ s type co rrespond s to a priv ate observation it makes abou t such a state. Howev er, this hid den state is not a necessary comp onent of a BG. On the con trary , BGs can also mo del problems where the types correspo nd to intrinsic prop erties o f the agents. For instance, in a e mployee re cruitment game, a potential emp loyee’ s type could correspon d t o wheth er or not he or she is a hard worker . Definition 2.8. A co llaborative Bayesian game (CBG) is a Bayesian game with identical payoffs: ∀ i , j ∀ θ ∀ a u i ( θ , a ) = u j ( θ , a ) . In a strategic game, the agents simply select action s. Ho wever , in a BG, the agents can cond ition their actions on th eir typ es. Consequently , ag ents in BGs select po licies instead of actions. A jo int policy β = h β 1 ,..., β n i , con sists of individual policies β i for each ag ent i . Deter ministic (pu re) indi v idual policies are map- pings from types to actions β i : Θ i → A i , while stochastic policies map each type θ i to a probability distribution over actions Pr ( A i ) . 7 Pr ( θ | s ) state s Pr ( s ) h F 1 , F 2 i h F 1 , N 2 i h N 1 , F 2 i h N 1 , N 2 i no neighb ors on fire 0 . 7 0 . 01 0 . 09 0 . 09 0 . 81 house 1 on fire 0 . 10 0 . 09 0 . 81 0 . 01 0 . 09 house 3 on fire 0 . 15 0 . 09 0 . 01 0 . 81 0 . 09 both on fire 0 . 05 0 . 81 0 . 09 0 . 09 0 . 01 Pr ( θ ) 0 . 07 0 . 15 0 . 19 0 . 59 T able 1: The con ditional pro babilities of the join t ty pes g iv en states and the resulting distrib u tion over join t types for the two-agent firefighting problem. Payoff of joint actions u ( s , a ) state s h H 1 , H 2 i h H 1 , H 3 i h H 2 , H 2 i h H 2 , H 3 i no neighb ors on fire + 2 0 + 3 + 2 house 1 on fire + 4 + 2 + 3 + 2 house 3 on fire + 2 + 2 + 3 + 4 both on fire + 4 + 4 + 3 + 4 T able 2: The pay offs as a function of the joint actions and hidden state for the two-agent firefighting problem. Example: T wo-Age nt Fir e Fighting As a n example, co nsider a formal mode l of the situatio n dep icted in Fig . 1. T he a gents each h av e two action s av ailable: ag ent 1 can fight fire at the first two houses ( H 1 and H 2 ) and agent 2 can figh t fire at the last two houses ( H 2 and H 3 ). Both agents are locate d near H 2 and ther efore know whether it is burning. Ho wever , they are uncertain whether H 1 and H 3 are burning or not. Each agent gets a noisy o bservation o f one of these h ouses, which defines its type. In particular, agent 1 can obser ve flames ( F 1 ) or n ot ( N 1 ) at H 1 and age nt 2 can ob serve ( F 2 ) or not ( N 2 ) at H 3 . The pro bability o f making the cor rect observation is 0.9 . T able 1 shows th e resulting probab ilities o f joint types conditio nal on the state. The table also shows the a p riori state distribution—it is most likely that none of the neig hborin g houses are on fire and H 3 has a slightly high er probability of being on fire than H 1 —and the resulting probab ility distrib u tion over joint types, computed by marginalizing over states: Pr ( θ ) = ∑ s Pr ( θ | s ) Pr ( s ) . Finally , ea ch agent generates a +2 p ayoff fo r the team by fighting fire at a burning house. Howe ver , payoffs are sub-additive: if both agents fight fire at the s ame house (i.e., at H 2 ), a payoff of +3 is g enerated. Fig hting fire at a ho use tha t is no t burning does not ge nerate any p ayoff. T able 2 su mmarizes all the possible payoffs. These rew ards ca n b e co n verted to the u ( θ , a ) fo rmat by computin g the conditio nal state probab ilities Pr ( s | θ ) using Bayes’ rule and taking the e xp ectation ov er states: u ( θ , a ) = ∑ s u ( s , a ) · Pr ( s | θ ) . (2.4) The result is a fully specified Bayesian game whose payoff matrix is shown in T able 3. 2.3.2 Solution Concepts In a BG, the concep t of NE is replaced by a Bay esian Nash equilibrium (BNE) . A profile of po licies β = h β 1 ,..., β n i is a BNE when no ag ent i has an incen tiv e to switch its policy β i , giv en the policies of the other 8 θ 2 F 2 N 2 θ 1 H 2 H 3 H 2 H 3 F 1 H 1 3 . 414 2 . 032 3 . 14 1 . 22 H 2 3 3 . 543 3 2 . 08 N 1 H 1 2 . 058 1 . 384 2 . 032 0 . 079 H 2 3 3 . 326 3 2 . 047 T able 3: The Bayesian game payoff matrix for the tw o- agent firefighting problem. agents β 6 = i . Th is occur s when, f or each a gent i and ea ch of its types θ i , β i specifies th e action th at maxim izes its expected value. When a Bayesian game is collab orative, the characterization o f a BNE is simp ler . Let the value of a joint policy be its expected payoff: V ( β ) = ∑ θ ∈ Θ Pr ( θ ) u ( θ , β ( θ )) , (2.5) where β ( θ ) = h β 1 ( θ 1 ) ,..., β n ( θ n ) i is the join t action spe cified by β for join t type θ . Fu rthermo re, le t the contribution of a joint type be: C θ ( a ) ≡ Pr ( θ ) u ( θ , a ) . (2.6) The value of a joint policy β can be interp reted as a sum of contributions, one for each joint ty pe. The BNE of a CBG maximizes a sum of such contributions. Theorem 2.1. The Bayesian Nash equilibrium of a CBG is: β ∗ = arg max β V ( β ) = arg max β ∑ θ ∈ Θ C θ ( β ( θ )) , (2.7) which is a P ar eto-op timal (Bayesian) N ash equ ilibrium (PONE). Pr oof. A CBG G can b e redu ced to a CSG G ′ where each action of G ′ correspo nds to a p olicy of G . Further- more, in G ′ , a joint a ction a ′ correspo nds to a join t policy of G an d th e payoff of a joint action u ′ ( a ′ ) correspon ds to the value of th e joint policy . As explained in Sec. 2.1.2, a PONE f or a CSG is a maximizing entry , which correspo nds to (2.7). For a more formal proof, see (Oliehoek et al., 2008b). 2.3.3 Solving CBGs Although the characterization o f a PONE is simple, find ing one is intr actable in g eneral. In fact, a CBG is equiv alent to a team decision pr oblem , which is NP-hard (Tsitsiklis and Athans, 1985). Since a CBG is an in stance o f a (non-c ollaborative) BG, solu tion metho ds f or th e latter apply . A co mmon approa ch is to conv er t a BG G to an SG G ′ , as in the pro of of Theorem 2.1. An action a ′ i in G ′ correspo nd to a policy β i in G , a ′ i ≡ β i , an d th e p ayoff of a joint action in G ′ equals the expected p ayoff of the co rrespon ding joint BG policy u ′ ( a ′ ) ≡ V ( β ) . Howe ver, sinc e the num ber of policies f or an agent in a BG is exponential in the nu mber of types, the co n version to an SG le ads to an expo nential blowup in size. When apply ing th is proced ure in the collabor ativ e case (i.e., to a CBG), the result is a CSG to which the tri vial algorithm applies. In effect, since joint actions corre spond to joint BG-policies, this procedure corresponds to brute-forc e e valuation of all joint BG-policies. A different appr oach to solv ing CBGs is alternatin g maximizatio n (AM) . Starting with a random join t policy , each agent iterati vely computes a b est respo nse policy f or each of its type s. In this way the agents hill-climb 9 tow ard s a local optimum. While the method guarantees find ing an NE, it can not guarantee finding a PONE and there is no bound on the quality of the approximation. By starting from a specially constructed starting point, it is possible to g i ve some guaran tees on the quality of appro ximation (Cogill and Lall, 2006). These guaran tees, howe ver , degrade exponentially as the number of agents increases. Finally , recen t work sho ws that the additi ve structu re of the value fun ction (2.7) can be exploited by heuristic search to g reatly speed up the computation of optimal solu tions (Oliehoek et al., 2010). Furtherm ore, the point- based backup operation in a Dec-POMDP—which can be interpreted as a special case of CB G—can be solved using state-of- the-art weighted con straint satisfaction metho ds (Kumar and Zilberstein, 2010), als o providing significant increases in perfor mance. 3 Exploiting Independence in Collaborative Bay esian Games The p rimary goal of this work is to find ways to ef ficiently solve large CBGs, i.e., CBGs with m any agents, actions and types. None of the models pre sented in the p revious section a re adeq uate fo r the task. CGSGs, by representing indepen dence between agents, a llow solu tion methods that scale to many agen ts, but they do not model priv ate information. In contrast, CBGs model pri vate informa tion but do not represent indepen dence between agents. Consequen tly , CBG solution methods scale poorly with respect to the number of agents. In this section, we propose a new mod el to ad dress th ese issues. In particular, we make three m ain co ntri- butions. First, Sec. 3.1 distinguishes between two types of independenc e that can occur in C BGs: in addition to the agent in depend ence that o ccurs in CGSGs, all CBGs po ssess type indep endenc e , an inher ent conseq uence of imperfect in formatio n. Second , Sec. 3.2 pro poses collab orative graphical B ayesian g ames , a n ew framework that models b oth these types of independence. Third , Sec. 3.4 describ es solutio n m ethods for this model that use a nov el factor graph representation to capture both agent and type independence su ch that they can be e xp loited by NDP and M A X - P L U S . W e pr ove that, while th e com putation al cost of NDP applied to such a factor gra ph remains exponen tial in the number of indi vid ual types, M A X - P L U S is tractable for small local neighborh oods. 3.1 Agent and T ype Independenc e As exp lained in Sec. 2.2, in many CSGs, agent inter actions are spar se. The resultin g indep endence, whic h we call agent independence , ha s long been exploited to compactly represent and more effi cien tly solve games with many agents, as in the CGSG model. While many CBGs also po ssess agent independence , th e CBG framework provides no w ay to mod el or exploit it. I n addition , regardless o f whether they have agent independen ce, all CBGs po ssess a second kind of ind ependen ce, which we call type indep endenc e , that is an inherent conseq uence o f imper fect in formatio n. Unlike agent independence , type independe nce is captured in the CBG model and can thus be exploited. T ype independence , which we originally iden tified in (Oliehoek, 2 010), is a result of the add iti ve structu re of a joint policy’ s v alue (shown in (2.7)). The k ey insight is that each of the contribution terms from (2.6) depends only on the action selected for some ind i v idual typ es. In particular , the action β i ( θ i ) selected for type θ i of agent i affects only the contribution terms whose joint types in volve θ i . For instance, in the two-agent firefighting problem, o ne possible joint type is θ = h N , N i (neither agent observes flames). Clearly , the action β 1 ( F ) that agent 1 selects wh en it has type F (it observes flames), has no effect on the contr ibution of this joint type. As il lustra ted in Fig. 3, this type of structure can also be represented by a factor graph with one set of nodes for all the contributions (corresponding to joint typ es) and another set for all the indi vidu al types of all the agents. Un like the repre sentation that results from reduc ing a BG to an SG p layed by agent-type combinatio ns (Osborne and Rubinstein, 199 4), this factor gr aph does not comp letely ‘flatten’ the utility functio n. On the 10 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n N 1 F 1 N 2 F 2 C h N 1 , N 2 i C h N 1 , F 2 i C h F 1 , N 2 i C h F 1 , F 2 i Figure 3: A factor grap h of the two-agent firefig hting p roblem, illustrating the type in depend ence inh erent in CBGs. The action cho sen fo r an individual type θ i affects only a sub set of contribution factors. For in stance, the action that agent 1 selects wh en it h as type N affects on ly the con tribution factors C h N 1 , N 2 i and C h N 1 , F 2 i in which it has that type. contrary , it e x plicitly represents the contributions of each joint type , thereby capturing type independ ence. The distinction between agent and type indepen dence i s sum marized in the following observation. Observation 1. CBGs can possess two dif fe rent types of independen ce: 1. Ag ent indepen dence: the payoff function is additively decomposed over local payoff functions, each specified over only a subset of agents, as in CGSGs. 2. T ype ind epend ence: on ly one typ e per agen t is actu ally realized , leading to a value fu nction that is additively decomposed ov er contributions, each specified o ver only a subset of types. The consequence of this distinction is that neither the CGSG nor CBG model is adequ ate to model complex games with im perfect inform ation. T o scale to many agents, we need a new model that expresses (and therefore makes it possible to exploit) both typ es of indep endenc e. In the rest of this section, we propo se a mod el that does this and show ho w both typ es of indepen dence can be rep resented in a factor graph which, in turn, can be solved using NDP and M A X - P L U S . 3.2 The Collaborative Graph ical Bayesian Game Model A collaborativ e graph ical Bayesian game is a CB G whose common payoff function decomp oses over a numb er of local payoff function s (as in a CGSG). Definition 3.1. A co llaborative graphical Bayesian game (CGBG) is a tuple h D , A , Θ , P , U i , with: • D , A , Θ as in a Bayesian game, • P = { Pr ( Θ 1 ) ,..., Pr ( Θ ρ ) } is a set of consistent local pr obability distributions , • U = { u 1 , . . . , u ρ } is the set of ρ local p ayoff functions . These cor respond to a set E of hyper-edges of an interaction grap h, such that th e total team pay off ca n (with some abuse of n otation) be wr itten as u ( θ , a ) = ∑ e ∈ E u e ( θ e , a e ) . A CGBG is collaborative because all agents share the comm on payoff function u ( θ , a ) . It is also grap hical because this payoff function dec omposes into a sum o f lo cal pa yoff functions, each o f which de pends on on ly 11 a subset of agents. 6 As in CGSGs, each local payof f function u e has scope A ( u e ) , which can be e xpr essed in an interaction hyper-graph I G = h D , E i with one hyper-edge for each e ∈ E . Strictly speaking, an edge corresponds to th e scope of a local pay off function, i.e., the set o f agen ts that participate in it (as in ‘ a e ’), but we will also use e to index the sets of hyper-edges and payoff functions (as in u e ). Each local pay off function de pends not only on the lo cal join t action a e , but also on the loca l joint type θ e , i.e., the ty pes o f the a gents in e (i.e., in A ( u e ) ). Furthermo re, each local pr obability fu nction Pr ( θ e ) specifies the probab ility of each local joint type. The go al is to maximize the e xp ected sum of re wards: β ∗ = arg max β ∑ θ Pr ( θ ) u ( θ , β ( θ )) = arg max β ∑ e ∈ E ∑ θ e Pr ( θ e ) u e ( θ e , β e ( θ e )) (3.1) where β e ( θ e ) is the local joint action under policy β giv en local joint type θ e . In principle, the local probab ility function s can be computed from the full joint probability function Pr ( Θ ) . Howe ver , doin g so is gen erally intr actable as it re quires margin alizing over the types tha t are n ot in sco pe. By including P in the model, we implicitly assume that Pr ( Θ ) has a compact representation th at allows for ef ficient computatio n of Pr ( θ e ) , e.g., by means of Bayesian networks ( Pearl, 1988; Bishop, 2006) or othe r g raphical models. Not all p robab ility distributions over joint types will admit such a comp act representation . However , those that do not will ha ve a size exponential in the number of agents and thus cannot e ven be represented, much les s solved, ef ficiently . Th us, the assumption that these local proba bility functions exist is minimal in the sense that it is a necessary co ndition f or solv ing th e g ame efficiently . Note, howe ver, that it is not a sufficient cond ition. On the c ontrary , the compu tational advantage o f the m ethods proposed below r esults fr om the agent an d type indepen dence captured in the resulting factor graph, not the existence of local prob ability functions. Example: Generalized Fire Fighting As an example, c onsider G E N E R A L I Z E D F I R E F I G H T I N G , which is like th e two-agent firefigh ting pro blem of Sec. 2 .3.1 but with n agen ts. In this version th ere are N H houses and th e ag ents are phy sically distributed over the area. Each ag ent gets an o bservation of the N O nearest houses and m ay choo se to fight fire at any of the N A nearest ho uses. For each h ouse H , th ere is a local pay off function inv olv ing the agen ts in its n eighbor hood (i.e., of the agents that can cho ose to fight fire at H ). These payo ff functions yield sub-additive re wards similar to those in T able 2. The type of each agent i is defined by the N O observations it recei ves from the surround ing houses: θ i ∈ { F i , N i } N O . T he probability o f ea ch type d epends on th e proba bility th at th e surroun ding h ouses are burning. As lon g as those probabilities can be compactly represented , th e probab ilities over ty pes can be too. Fig. 4 illustrates the case where N H = 4 and n = 3. E ach agent can go to the N A = 2 closest houses. In this problem , there are 4 local pay off functions, on e fo r e ach h ouse, ea ch with limited sco pe. Note that the pay off function s f or th e first and the last house include o nly o ne agent, which means th eir scopes are pro per subsets of the scopes of other payoff functions (those for houses 2 and 3 respecti vely). T herefor e, they can be included in those functions, reducing the number of local payoff functions in this example to two: on e in which agents 1 and 2 participate, and one in which agents 2 and 3 participate. 3.3 Relationship to Other Models T o provide a better u nderstan ding of th e CGBG model, we elabo rate on its relationship with existing mod els. Just as CGSGs are related to graphica l games, CGBGs are r elated to g raphical BGs (Soni et al., 2007). H owe ver , as befo re, there is a cr ucial difference in the meaning of the term ‘ graphica l’. In CGBGs, all agents p articipate 6 Arguab ly , since all C BGs ha ve type in dependence, they are in some sense a lready graph ical, as i llustrated in Fig. 3. Ho we ver , to be consisten t with the literat ure, we use the te rm graphical here to indicat e age nt independe nce. 12 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n Figure 4: Illustration of G E N E R A L I Z E D F I R E F I G H T I N G with N H = 4 and n = 3 . in a comm on payoff function that decomposes into local payo ff functions, each in volving subsets of age nts. In contrast, grap hical BGs are not necessarily collaborative and the individual payoff functio ns in volve subsets of agents. Since these individual payoff functions do not decom pose, CGBGs ar e not a special ca se of GBGs but rather a unique, n ovel formalism. In addition, the graphical BGs considered by Soni et al. (2 007) m ake much more restricti ve assumptions on the type probabilities, allowing only i n depend ent typ e distributions (i.e., Pr ( Θ ) is defined as the product of indi vidu al type probabilities Pr ( Θ i ) ) and assuming conditional utility independ ence (i.e., the payoff of an agent i depen ds only on its own type, not that of other agents: u i ( θ i , a ) ). More closely related is the multiagent influen ce diagra m (M AID) fra mew or k that extends decision diagrams to multiag ent settings (K oller and Milch, 200 3). In par ticular, a MAID represents a decision problem w ith a Bayesian network that contains a set of chance nodes and, for each agent, a set of decision and utility nodes. As in a CGBG, the in dividual pay off func tion for each ag ent is defined as the sum of local pa yoffs (one fo r each utility nod e of that agent). On the on e hand, MAIDs are more gener al than CGBGs because they can represent non-id entical payoff settings (tho ugh it would be straightfor ward to extend CGBGs to such pr oblems). On the other hand, CGBGs ar e m ore general than MAIDs since they allow any r epresentation o f the distribution over joint types (e.g ., a Markov r andom field), as long as th e local proba bility distributions can be comp uted efficiently . A CGBG ca n be re presented as a MAID, a s illustrated in Fig. 5 . It is imp ortant to no te that, in th is MAID, both utility no des are associated with all agen ts, such that each a gent’ s goal is to o ptimize the sum u 1 + u 2 and the MAID is collabor ativ e. Howe ver, the r esulting MAID’ s rele van ce g raph ( K oller and Milch, 20 03), which in- dicates which decisions influence each o ther, consists of a single strongly connected compon ent. Conseque ntly , the divide and conquer s o lution method proposed by K oller and Milch offers no speedup over b rute-fo rce e val- uation of all the joint p olicies. In th e f ollowing section, we propose methods to overcome this pr oblem and solve CGBGs ef ficiently . 3.4 Solution Methods Solving a CGBG amo unts to findin g the maximizing joint policy as expressed b y (3.1). As men tioned in Sec. 2.3 .3, it is p ossible to convert a BG to an SG in which the actions corresp ond to BG policies. In previ- ous w ork (Oliehoek et al., 2008c), we app lied s imilar transforma tions to CGBGs, yielding CGSGs to which all the solutio n methods men tioned in Sec. 2.2 ar e applicab le. Alternatively , it is p ossible to convert to a (non- collaborative) gra phical BG (Son i et al., 2007) and apply the prop osed solution metho d. Under the hood , howe ver , this method con verts to a graphical SG. The prim ary limitation o f all of th e op tions men tioned ab ove is that th ey exploit o nly agen t ind ependen ce, 13 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n θ 1 θ 2 θ 3 θ 1 2 θ 2 3 a 1 a 2 a 3 u 1 u 2 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n θ 1 θ 2 θ 3 θ 1 2 θ 2 3 a 1 a 2 a 3 u 1 u 2 Figure 5: At left, a th ree-agen t CGBG repr esented as a MAID. At right, the resulting relev an ce grap h, which has only one strongly connected compo nent containing all decision variables. not type independen ce. In fact, con verting a CGBG to a CGSG has the effect of stripping all type independen ce from the mode l. T o see why , note that type indepen dence in a CBG occu rs as a result of the form of the pay off function u ( θ , β ( θ )) . In other words, the pa yoff depen ds on the joint action , which in tu rn depend s only on the joint t y pe that occurs. Con verting to a CSG produ ces a payoff fu nction t h at depends on the joint action selected for all p ossible joint types, effecti vely ignoring type in depend ence. A direc t result is that the solution metho ds have an exponential dependence on the number of types. In this section, we propose a new app roach to so lving CGBGs tha t av oid s this pro blem by exploiting both kinds of ind ependen ce. The main idea is to represent the CGBG using a novel factor gr aph formulatio n that neatly captures both agent and type independ ence. Th e resulting factor graph can then be solved using methods such as NDP and M A X - P L U S . T o enable this factor graph formulation , we define a local contribution as follo ws: C e θ e ( a e ) ≡ Pr ( θ e ) u e ( θ e , a e ) (3.2) Using this notation, the solution of the CGBG is β ∗ = arg max β ∑ e ∈ E ∑ θ e C e θ e ( β e ( θ e )) . (3.3) Thus, the solution correspond s to th e maxim um of an add itiv ely d ecompo sed f unction co ntaining a con- tribution fo r each lo cal joint type θ e . This can be expressed in a factor graph with one set of node s fo r all the contributions and a nother fo r all the in dividual typ es of a ll the agents. An individual type θ i of an agent i is con nected to a contribution C e θ e only if i pa rticipates in u e and θ e = h θ j i j ∈ A ( u e ) specifies θ i for agen t i , as illustrated in Fig. 6. W e refer to this graph as th e agent a nd type independence (ATI) factor graph . 7 Contri- butions are separ ated, not only by the join t type to which they apply , but also by the local payoff fu nction to which they contribute. Consequen tly , bo th agent and ty pe indepen dence are naturally expressed. In the next two subsection s, we d iscuss the application of NDP and M A X - P L U S to this factor g raph f ormulatio n in order to efficiently solv e CGBGs. 3.4.1 Non-Serial Dynamic Programming f or CGBGs Non-serial dy namic prog ramming ( NDP) ( Bertele and Brioschi, 19 72) can be used to find the maxim um con - figuration of a factor graph. In the forwar d pass , the variables in the factor graph are eliminated one by o ne 7 In pre vious work, we referred to this as the ‘type-action’ factor graph, since its vari ables cor respond to actions selected for indi vidual types (Oliehoe k , 2010). 14 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n β 1 β 2 β 3 u 1 u 2 θ 1 1 θ 2 1 θ 1 2 θ 2 2 θ 1 3 θ 2 3 C 1 h 1 , 1 i C 1 h 1 , 2 i C 1 h 2 , 1 i C 1 h 2 , 2 i C 2 h 1 , 1 i C 2 h 1 , 2 i C 2 h 2 , 1 i C 2 h 2 , 2 i Figure 6: Factor g raph for G E N E R A L I Z E D F I R E F I G H T I N G with three ag ents, two typ es per agent, and two local p ayoff functions. Agents 1 and 2 particip ate in payo ff function u 1 (correspo nding to the first four con tri- butions), while agents 2 and 3 par ticipate in u 2 (correspo nding to the last fou r contributions). The factor graph expresses both agent independ ence (e.g., agent 1 d oes not participate in u 2 ) and type ind epende nce (e. g, the action agent 1 selects when it receives observation θ 1 1 affects only the first 2 contr ibutions). accordin g to some prespecified order . Eliminating the k th variable v in volves collecting all the factors in which it participates and replacing them with a ne w factor f k that represents the sum of the removed facto rs, gi ven that v selects a best respo nse. Once all variables are elimin ated, the backwar ds pass begins, iterating th rough the variables in reverse order of elimina tion. Each variable selects a best respon se to th e variables alread y visited, ev entu ally yielding an optimal joint policy . The maximum number of agents participating in a factor encountered during NDP is known as the induced width w of the orderin g. The fo llowing result is well-known (see for instance (Dechter, 1999)): Theorem 3.1. NDP r equires exponential time and space in the induced width w. Even thoug h NDP is still exponential, for sp arse pro blems the in duced with is m uch smaller than th e to tal number o f variables V , i.e., w ≪ V , leading to an exponen tial speed up over naive enumeration over joint variables. In previous work ( Oliehoek et al., 2008c), we used NDP to op timally solve CGBGs. Howe ver , NDP was applied to the ag en t independenc e (A I) factor gra ph (e.g., as in Fig. 2(b)) th at results from con verting the C GBG to a CGSG. Conseq uently , only agent indep endenc e w as exploited. In principle, we should b e able to impr ove perfor mance b y applying NDP to the A TI f acto r graph introduced above, thereby exploiting both ag ent and type indepen dence. Fig. 7 illustrates a few steps of the resulting algorithm. Howe ver , there are tw o important lim itations of the NDP approach . First, the computational co mplexity is expon ential in the induced wid th, which in turn depe nds on the order in which the variables are e liminated. Determining the optimal ord er (which Bertel ` e and Brioschi (197 3) call the secondary optimization pr oblem ) is NP-complete (Arnb org et al., 1 987). While there are heu ristics for determining the order, NDP scales poo rly in p ractice on den sely conn ected graphs (Kok and Vlassis, 2006). Second, b ecause of the par ticular shape that type indepen dence induces on the factor graph, we can establish the following: Theorem 3.2. The in duced with of an ATI factor graph is l o wer b ound ed by the numb er of individu al types: w ≥ | Θ ∗ | , wher e Θ ∗ denotes the lar gest individua l type s et. Pr oof. L et us consider the first elimination step o f NDP for an arbitrary θ m i (i.e., an arbitrary variable). Now , 15 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n θ 1 1 θ 2 1 θ 2 1 θ 1 2 θ 1 2 θ 1 2 θ 2 2 θ 2 2 θ 2 2 θ 2 2 θ 1 3 θ 1 3 θ 1 3 θ 1 3 θ 2 3 θ 2 3 θ 2 3 θ 2 3 C 1 h 1 , 1 i C 1 h 1 , 2 i C 1 h 2 , 1 i C 1 h 2 , 1 i C 1 h 2 , 2 i C 1 h 2 , 2 i C 2 h 1 , 1 i C 2 h 1 , 1 i C 2 h 1 , 1 i C 2 h 1 , 2 i C 2 h 1 , 2 i C 2 h 1 , 2 i C 2 h 2 , 1 i C 2 h 2 , 1 i C 2 h 2 , 1 i C 2 h 2 , 1 i C 2 h 2 , 2 i C 2 h 2 , 2 i C 2 h 2 , 2 i C 2 h 2 , 2 i f 1 f 1 f 2 f 3 Figure 7: A few steps of NDP run on the factor grap h of Fig. 6. V ariables are eliminated from left to right. Dotted ellipses indicate the part of the factor graph to be eliminated. each edge e ∈ E (i.e., each payoff comp onent) in which it participates in duces O ( | Θ ∗ | | e |− 1 ) contributions to which it is connected: on e contr ibution for ea ch pr ofile θ e \ i of typ es o f the other agents in e . As a result, the new factor f 1 is con nected to all types of the neighbors in the interaction h yper-graph. The n umber of such types is at least | Θ ∗ | . Note that | Θ ∗ | is not the only term that determines w ; th e number of edges e ∈ E in which agents participate as well as the e limination order still matter . In par ticular , let k den ote the ma ximum degree of a con tribution factor , i.e., the lar gest local scope k = max e ∈ E | A ( u e ) | . Clearly , since there is a f acto r that has degree k , we have that w ≥ k . Corollary 1. The computation al complexity of NDP app lied to a n ATI factor graph is e xp onential in the nu mber of individual types. Pr oof. T his follows directly from theorems 3.1 and 3.2. Therefo re, even given the A TI factor graph formulation, it seems unlikely that NDP will prove useful in exploiting type inde penden ce. In particular, we hyp othesize that NDP app lied to the A TI factor graph will no t perfor m significan tly better than NDP on th e AI factor gra ph. In fact, it is possible that the fo rmer p erform s worse th an the latter . Th is is illustrated in the last elim ination step shown in Fig. 7. A factor f 3 is intro duced with degree w = 3 and size | A ∗ | w . In contrast, performing NDP on the AI factor graph using the ‘same’ left-to- right order ing has induced width w = 1 and the size of the factors constructed is ( | A ∗ | 2 ) w (where 2 = | Θ ∗ | ). 3.4.2 Max-Plus for CGBGs In order to m ore effectively exploit type in depend ence, we consider a second approach in w hich the fac- tor graph is solved using the M A X - P L U S message p assing algorithm (Pearl, 1 988; W ainwr ight et al., 2004; K ok and Vlassis, 2005; Vlassis, 20 07). M A X - P L U S was originally prop osed by Pearl (198 8) un der th e name 16 belief r evision to compu te th e maximum a posteriori probab ility c onfigura tions in Bayesian ne tworks. The algorithm is also known as max -prod uct or m in-sum ( W ainwright et al., 2004) and is a special case o f the sum-pr oduc t algorith m (Kschischang et al., 2001)—also ref erred to as belief pr opagation in probabilistic do- mains. M A X - P L U S can be implemented in eith er a c entralized or d ecentralized way (Kok and Vlassis, 2006). Howe ver , since we assume planning tak es p lace in a centralized off-line phase, we consider only the former . M A X - P L U S a lgorithm is an ap pealing cho ice for se veral reason s. First, on structur ed problem s it has been shown to ach iev e excellent perf ormanc e in practice (Kschischang et al., 2001; Kok and Vlassis, 20 06; Kuyer et al., 2008). Second, un like NDP , it is an a nytime algorithm that can provid e results after each iteration of the algorith m, no t only at the end (K ok and Vlassis, 20 06). Third, a s we show below , its computatio nal complexity is exponential o nly in the size of the largest local payoff function’ s scope, which is fix ed for a giv en CGBG. At an intuitive level, M A X - P L U S works by iterati vely sending messages between the f actor s, correspon ding to con tributions, an d variables, corresp onding to (choices o f action s for) types. These messages enc ode how much payo ff the send er expects to be able to con tribute to th e total payoff. In p articular, a m essage sent from a type i to a contribution j enco des, for each possible action , th e p ayoff it expects to contribute. This is computed as the sum of the incoming messages from other contributions k 6 = j . Similarly , a message sent from a con tribution to a type i enco des the payo ff it can co ntribute conditioned on each available action to the agen t with type i . 8 M A X - P L U S iterati vely passes these messages over the ed ges of the factor grap h. Within each iteration, the messages are sent either in parallel or sequen tially with a fixed or rand om o rdering . When ru n on an acyclic factor graph (i.e., a tree), it is gua ranteed to conver ge to an optima l fixed point (Pearl, 19 88; W ainwright et al., 2004). In cyclic factor grap hs, suc h as those defin ed in Sec. 3.4, there ar e no g uarantee s that M A X - P L U S will conv erge. 9 Howe ver , experimental results have demonstrated tha t it works we ll in practice e ven when cycles are present (Kschisch ang et al., 200 1; Kok and Vlas sis, 200 6; Kuyer et al., 2 008). This requires n ormalizing the messages to pre vent them from gr owing ever larger, e.g. by taking a weighted sum of the new and old messages (damping ). As men tioned above, the compu tational com plexity of M A X - P L U S on a CGBG is exponential on ly in the size o f the lar gest local payoff fu nction’ s scope. More precisely , we show h ere that this claim h olds fo r one iteration of M A X - P L U S . In general, it is not po ssible to bo und the number of iterations, since M A X - P L U S is no t guaran teed to conv erge. H owe ver , by applying re normalizatio n and/or damping, M A X - P L U S con verges quickly in practice. Also, since M A X - P L U S is an anytime algorithm, it is possible to limit the number of iterations to a constant number . Theorem 3.3. One iteration of M A X - P L U S run on the factor g raph co nstructed fo r a CGBG is tractable for small local neighborh oods, i.e., the only e xpo nential dependence is in the size of the lar gest local scope. Pr oof. L emma 8.1 in the appendix characterizes the complexity of one iteration of M A X - P L U S as O m k · k 2 · l · F , (3.4) where, for a factor graph for a CGBG, the interpretation of the symbols is as follows: • m is the maximu m number of v alues a type variable can take. It is gi ven by m = | A ∗ | , the size of the largest action set. 8 For a det ailed description of how the messages are computed , see (Oliehoek, 2010, Sec. 5.5.3). 9 Ho weve r, recent varia nts of the message passing approach hav e slight modificati ons that yield con ve rgence guaran- tees (Globerson and Jaakkol a , 2008). Since we found t hat re gular M AX - P L U S performs well in our expe rimental settin g, we do not consider such v ariants in this article. 17 • k is the max imum degree of a contribution (factor), given by the largest local s co pe k = max e ∈ E | A ( u e ) | . • l is the max imum degree o f a type (variable). Again, each local payo ff func tion e ∈ E in wh ich it participates in duces O ( | Θ ∗ | k − 1 ) contributions to whic h it is con nected. Let ρ ∗ denote the maximum number of edges in which an agent participates. Then l = O ( ρ ∗ · | Θ ∗ | k − 1 ) . • F = O ( ρ · | Θ ∗ | k ) is the number of contributions, one for each local joint type. By sub stituting the se nu mbers an d reo rdering terms we get that one iteration of M A X - P L U S for a CGBG has cost: O | A ∗ | k · k 2 · ρ ρ ∗ | Θ ∗ | 2 k − 1 , (3.5) Thus, in the worst case, one iteration of M A X - P L U S scales po lynomially with respect to the number of local payoff function s ρ and the largest sets of actions | A ∗ | and t y pes | Θ ∗ | . It scales exponen tially in k . Giv en this result, we expect that M A X - P L U S will prove mor e effecti ve th an NDP at exploiting typ e inde - penden ce. In particular , we hypothesize that M A X - P L U S will per form better when applied to the A TI factor graph instead of the AI factor graph and that it will perform better than NDP applied to the A TI factor graph. In the following s ectio n, we present experiments e valuating these hyp otheses. 3.5 Random CGBG Experiments T o assess the relative perf ormance of NDP and M A X - P L U S , we co nduct a set o f empirical evaluations on random ly gene rated CGBGs. W e u se ran domly gener ated g ames beca use they allow for testing on a ran ge of different pro blem pa rameters. I n particular, we are interested in the effect of scalin g the number of agents n , the n umber of types | Θ i | that each agen t has, the nu mber of action s fo r each a gent | A i | , as well a s th e nu mber of agents in v olved in each pa yoff fu nction, | A ( e ) | . W e as sum e each p ayoff fu nction has an eq ual numb er of agents and refer to this proper ty as k = max e ∈ E | A ( e ) | , as in Theorem 3.3. Furthermo re, we em pirically evaluate the influen ce o f exploiting both agent and type in depend ence versus exploiting only o ne or the other . W e do so by ru nning b oth NDP and M A X - P L U S on th e agen t-indepen dence (AI) factor graph (Fig. 2(b)), the type-indep enden ce (T I) factor graph (Fig. 3), and the agent and type indepen- dence (A T I) factor graph (Fig. 6). These exp eriments serve thr ee m ain pu rposes. First, they emp irically validate Theo rems 3.2 and 3.3, con - firming the difference in c omputatio nal complexity between NDP and M A X - P L U S . Secon d, th ey qua ntify the magnitud e of the difference in runtim e performan ce between these two meth ods. Third, they she d ligh t on the quality of the solutions f ound by M A X - P L U S , which is guaran teed to be optimal only on tree-structur ed g raphs. 3.5.1 Experimental Setup For simplicity , when gener ating CGBGs, we assum e th at 1) the scop es of the local p ayoff functio ns have the same size k , 2) th e individual action sets have the same size | A i | , and 3 ) the ind ividual type sets have the same size | Θ i | . For each set of parameters, we generate 1 , 000 CGBGs on which to test. Each game is g enerated following a procedu re similar to that u sed by K ok and Vlassis (2006) for generating CGSGs. 10 W e start with a set of n a gents with n o local payoff functions define d, i.e., they for m an interactio n hypergrap h with no edges. As long as the interactio n hypergrap h is not yet connec ted, i.e., there does no t exist a path between ev er y pair of agents, we add a local payo ff function in volving k agents. 10 The mai n diffe rence is in the te rmination condition: we stop addi ng edges when the in teraction graph is ful ly connected instea d of adding a pre-de fined numbe r of edges. 18 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) n = 5, k = 2. P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) k = 3, left: n = 5, right: n = 8. P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (c) n = 8, k = 2. Figure 8: Examp le interaction hypergraphs of randomly generated CGBGs for dif feren t parameter settings. As a result, the number of ed ges in different CGBGs gener ated f or the sam e p arameter setting may differ significantly . The k agents that participate in a ne w edge are selected u niform ly at rand om from th e subset of agents inv olved in the fewest number of edges. Payoffs u e ( θ e , a e ) are drawn from a n ormal distribution N ( 0 , 1 ) , and the loc al joint type probabilities Pr ( θ e ) are drawn f rom a uniform distribution and t h en normalized. This algorithm r esults in fully connected in teraction h ypergrap hs that are balanced in ter ms of the n umber of payoff functions in wh ich each agent par ticipates. Fig. 8 sh ows some examp les of the inter action hy pergraphs generated . W e test the following methods: NDP Non -serial dyn amic progr amming (see Sec. 3.4. 1), run o n the agent-indepen dence factor gr aph (NDP- AI), the typ e-indep endence factor graph (NDP-TI), an d the pr oposed age nt-type indepen dence factor graph (NDP-A TI ). MP M A X - P L U S with th e f ollowing parameter s: 10 restarts, 25 maxim um iterations, sequential ran dom mes- sage passing sch eme, dampin g factor 0 . 2. Analogous to NDP , there are thr ee variations M A X - P L U S - AI, M A X - P L U S -TI, and M A X - P L U S -A TI. B A G A B A B Bayesian game bran ch and b ound ( B A G A B A B ) is a fast metho d for o ptimally solving CBGs (Oliehoek et al., 2010). It perfor ms heuristic search over partially specified policies. 11 A LT M A X Alternating Maximization with 10 restarts (see Sec. 2.3.3). CE Cro ss Entropy op timization (de Boer et al., 200 5) is a randomized optimization metho d that main tains a distribution over joint p olicies. It works b y iterating the following steps: 1) sampling a set of join t policies from the d istribution 2 ) using the best f raction of samples to update the distribution. W e used two p arameter setting s: one that ga ve goo d r esults accord ing to (Oliehoek et al., 200 8a) ( C E N O R M A L ), and one that is faster (C E FA S T ). 12 All method s were implem ented u sing the M ADP T oolb ox (Spaan and Oliehoek, 2 008); the NDP and M A X - P L U S implementatio ns also use L I B DA I (Mooij, 2008b). Expe riments in this section are run on an Intel Core i5 CPU (2 . 67GHz) u sing Linux , and the timing r esults are CPU time s. Each pro cess is limited to 1GB of m emory use and the compu tation time for solving a single CGBG is limited to 5 s . For each metho d, we report bo th the average payoff and the average CPU time need ed to com pute the solution. In the plots in this section, each data po int represents a n average over N g = 1 , 000 games. The reported payo ffs are normalize d with respect to those o f M A X - P L U S -A TI. As such, the pay off of M A X - P L U S - A T I is alw ays 1 . Error bars indicate the standard deviation of the sampled mean σ mean = σ / p N g . 11 In t he experimen ts we used th e ‘MaxContrib utionDif ference’ join t type ordering and use the ‘consiste nt complete information’ heuris- tic. 12 Both va riants perform 10 restarts, use a learning rate of 0 . 2 and perform w hat (Oliehoek et al., 2008a) refer to as ‘approximate ev alu- ation’ of joint policies. C E N O R M A L performs 300 and CE FA S T 100 simulations per joint polic y . C E N O R M A L performs I = 50 ite rations, in each of which N = 100 joint poli cies are sampled of whic h N b = 5 policies are used to upd ate the maintaine d d istributio n. C E FA S T uses I = 15 , N = 40 , N b = 2. 19 FG type num. factors ( F ) fact. size fact. deg. ( k ) num. vars var . size ( m ) var . deg. ( l ) AI ρ | A ∗ | | Θ ∗ | k | e ∗ | n | A ∗ | | Θ ∗ | ρ ∗ TI | Θ ∗ | n | A ∗ | n n n | Θ ∗ | | A ∗ | | Θ ∗ | n − 1 A T I ρ | Θ ∗ | k | A ∗ | k | e ∗ | n | Θ ∗ | | A ∗ | | Θ ∗ | k − 1 T able 4: A characterization of th e dif fe rent types o f factor grap hs: agen t-indepen dence ( AI), type-indepen dence (TI), agent-typ e indepen dence (A TI). The symbols relate to (3.4). 3.5.2 Comparing Methods First, we compare NDP-A TI an d M A X - P L U S -A TI with other m ethods that do n ot exploit a factor gr aph rep- resentation explicitly , the results of which are sh own in Fig. 9. T hese results demon strate that, as the nu mber of agen ts increases, the average payoff of the ap proxim ate non-g raphical methods goes down (Fig. 9(a)) while computatio n tim e g oes up (Fig . 9 (b)), given tha t the o ther p arameters are fixed at at k = 2 , | Θ i | = 3 , | A i | = 3. Note that a data point is not presented if the m ethod exceeded th e p re-defin ed resour ce limits on one o r mor e test runs. For instance , B A G A B A B can compute solution s on ly up to 4 agen ts. Also, Fig. 9( b) suggests that NDP-A TI would on average comple te within the 5s dead line for 6 agents. Ho wever , b ecause there is at least one run that does not, the data point is not included . Next, we fix the number of agen ts to 5, an d v ary the n umber of action s | A i | . While C E N O R M A L never meets th e ti me limit, the c omputatio n time that CE FA S T requir es is relati vely in depend ent of th e n umber o f actions (Fig. 9 (d)). Payoff, howe ver , d rops sharp ly when the num ber of actio ns increases (Fig. 9( c)). Th e C E solvers maintain a fixed-size p ool of po ssible solutio ns, wh ich explain s both ph enomen a: th e same numb er of samples need to cover a larger search space , but the cost of ev alua ting e ach samp le is relativ ely in sensiti ve to | A i | . Finally , we con sider the beh avior of the different method s when in creasing the n umber of ind ividual types | Θ i | (Fig . 9 (e) and 9( f)). Since the number o f p olicies for a n a gent is expon ential in the nu mber of types, the existing meth ods scale p oorly . As established by Corollar y 1, NDP’ s com putation al costs also grow exponen- tially with the nu mber o f types. M A X - P L U S , in con trast, scales much better in th e num ber of types. Look ing at the quality of the found policies, we see that M A X - P L U S achiev es the optimal value in these exper iments, while the other appro ximate methods achie ve lo wer values. 3.5.3 Comparing Factor -Gra ph F ormulatio ns W e no w turn to a m ore in-depth analysis of the NDP and M A X - P L U S methods, in order to establish the ef fect of exploiting different types of ind ependen ce. In particu lar , we te st b oth metho ds on three different ty pes of fac- tor gr aphs: those with agent-ind ependen ce (AI), type-in depend ence (TI), and agent-type indep endence (A TI). T able 4 summarize s the types of factor graphs and the symbols used to describe their various characteristics. First, we consider scaling the nu mber of ag ents, using the same parameter s as in Fig. 9(a) and 9( b). Fig. 10(a) sho ws the payoff of the different methods. The difference between them is not significant. Howev er, Fig. 10(b) sh ows the computation time s of the same methods. As expected, the m ethods that use only type indepen dence scale po orly because the number of factors in their factor graph is exponential in the nu mber o f agents (T able 4). Fig. 10( c) and 10 (d) show similar co mparison s for payoff fu nctions inv olving three a gents, i.e. , k = 3 (example interaction hypergraph s are shown in Fig. 8(b)). The difference in payoff b etween NDP-A TI and M A X - P L U S -A TI is not sign ificant ( minimum p-value is 0.6 1907 for 6 agents). Dif fer ences with AM and the outlying po ints of M A X - P L U S -A I are sign ificant (p-value < 0 . 05). The NDP-AI and NDP- A T I method s scale 20 2 3 4 5 6 0.95 0.96 0.97 0.98 0.99 1 1.01 Varying # agents −− Payoffs Relative Payoffs # agents BaGaBaB AltMax CE fast CE normal MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) Scaling n : P ayoff s ( k = 2 , | Θ i | = 3 , | A i | = 3). 2 3 4 5 6 10 −3 10 −2 10 −1 10 0 Varying # agents −− Computation Times Computation time (s) # agents BaGaBaB AltMax CE fast CE normal MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) Sc aling n : Computation t imes ( k = 2 , | Θ i | = 3 , | A i | = 3). 2 3 4 5 6 7 8 9 10 0.8 0.85 0.9 0.95 1 Varying # actions −− Payoffs Relative Payoffs # actions BaGaBaB AltMax CE fast MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (c) Scaling | A i | : P ayoff ( k = 2 , | Θ i | = 3 , n = 5). 2 3 4 5 6 7 8 9 10 10 −2 10 −1 10 0 Varying # actions −− Computation Times Computation time (s) # actions BaGaBaB AltMax CE fast MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (d) Sc aling | A i | : Computation times ( k = 2 , | Θ i | = 3 , n = 5). 2 3 4 5 6 7 0.95 0.96 0.97 0.98 0.99 1 1.01 Varying # types −− Payoffs Relative Payoffs # types BaGaBaB AltMax CE fast CE normal MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (e) Scaling | Θ i | : P ayoff ( k = 2 , | A i | = 3 , n = 5). 2 3 4 5 6 7 10 −3 10 −2 10 −1 10 0 Varying # types −− Computation Times Computation time (s) # types BaGaBaB AltMax CE fast CE normal MaxPlus−ATI NDP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (f) Sc aling | Θ i | : Computation times ( k = 2 , | A i | = 3 , n = 5). Figure 9: Comparison of M A X - P L U S -A TI and ND P-A T I with other methods, scalin g the number of agen ts ((a) and (b)), the number of actions ((c) and (d))), and the number of types ((e) and (f)). 21 2 3 4 5 6 0.99 0.992 0.994 0.996 0.998 1 1.002 1.004 1.006 1.008 1.01 Varying # agents −− Payoffs Relative Payoffs # agents MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) Payoff, k = 2 , | Θ i | = 3 , | A i | = 3. 2 3 4 5 6 10 −3 10 −2 10 −1 10 0 Varying # agents −− Computation Times Computation time (s) # agents MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) C omputation times, k = 2 , | Θ i | = 3 , | A i | = 3. 3 4 5 6 7 8 0.94 0.95 0.96 0.97 0.98 0.99 1 1.01 Varying # agents −− Payoffs Relative Payoffs # agents AltMax MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (c) Payoff, k = 3 , | Θ i | = 3 , | A i | = 3. 3 4 5 6 7 8 10 −3 10 −2 10 −1 10 0 10 1 Varying # agents −− Computation Times Computation time (s) # agents AltMax MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (d) C omputation times, k = 3 , | Θ i | = 3 , | A i | = 3. 10 1 10 2 0 500 Varying # agents −− Payoffs Absolute Payoffs # agents 0 500 # edges # edges MaxPlus−AI Payoff MaxPlus−ATI Payoff P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (e) Payoff, k = 2 , | Θ i | = 4 , | A i | = 4, and the aver age num- ber of edges per game (note the two differ ent y -ax es in- dicat ed wit h two colors). 100 200 300 400 500 600 700 10 −2 10 −1 10 0 10 1 10 2 Varying # agents −− Computation Times Computation time (s) # agents MaxPlus−AI MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (f) Co mputation times, k = 2 , | Θ i | = 4 , | A i | = 4. Figure 1 0: Compa rison of th e p roposed factor-graph m ethods w hen scaling the number of agents n . Plo ts (a) and (b) consider k = 2 (analogo us to Fig. 9(a) and 9(b)), while ( c) and (d) show results for hyper-edges with k = 3. Plots (e) and (f) display the scaling behavior for many agents. 22 to 6 agents, while M A X - P L U S - AI and M A X - P L U S -A TI scale beyond. The pay off of M A X - P L U S -AI is worse and m ore erratic than the pay off o f M A X - P L U S -A TI. In this case, d ue to increased problem co mplexity , the M A X - P L U S methods typically do not attain the true optimum. These experiments clearly demon strate that only M A X - P L U S -AI and M A X - P L U S -A TI scale to larger num- bers of agents. The po or scalability of the non- factor-graph methods is due to their failure to explo it the indepen dence in CGBGs. The metho ds using TI factor gr aphs scale p oorly beca use they igno re inde penden ce between agen ts. As hyp othesized, NDP is not able to effecti vely exploit type independe nce and co nsequen tly NDP-A TI does n ot ou tperfor m NDP- AI. In fact, the experiments show that, in som e cases, NDP-AI sligh tly outperf orms NDP-A TI. Fig. 10(e) and 10(f) show the performance of M A X - P L U S -A I and M A X - P L U S -A TI for games with k = 2 , | Θ i | = 4 , | a i | = 4 and larger number s of agents, from n = 10 up to n = 72 5 (limited by the allocated memory space). For this experim ent, the metho ds were allowed 30 s per CGBG instance. Fig. 10( e) shows the absolu te payoff obtained by both methods and the growth in the number of payoff functions (edges). The results demon - strate that th e M A X - P L U S -A TI payoffs do not deteriorate when increasing the n umber of payoff functions. Instead, they in crease steadily at a rate similar to the num ber of pa yoff fu nctions. This is as expected, since more payoff f unctions means there is more reward to be collected. M A X - P L U S -AI s cales only to 50 agents, and its payoffs ar e close to those obtained by M A X - P L U S -A TI. Fig. 10(f) provides clear expe rimental corrobor ation of Theor em 3.3 (which states that there is no e xp onential dependen ce on th e num ber of agents), by showing scalability to 725 agents. Analogou sly to Sec. 3.5.2, we compar e the different factor-graph methods when increasing the n umber of action s and ty pes. Fig. 11(b ) shows that M A X - P L U S - A T I scales b etter in th e n umber of actio ns wh ile obtaining p ayoffs close to optimal (when a vailable) and b etter than other M A X - P L U S variations (Fig. 11(a)) (differences are n ot sig nificant). In fact, it is the only m ethod who se com putation time incr eases only sligh tly when in creasing the number of actions: the size of each factor is only | A ∗ | k compare d to | A ∗ | | Θ ∗ | k for AI and | A ∗ | n for TI (T able 4). In this case k = 2 and n = 5, and in general k ≪ n in the domains we consider . When scaling the number of ty pes (Fig. 1 1(c) and 1 1(d)), again the re are n o significant d ifferences in payoffs. Howe ver , as e xpe cted gi ven the lack o f expon ential dep endenc e on | Θ i | (T ab le 4), M A X - P L U S -A TI perfor ms much better in terms of compu tation times. Overall, the results presented in this section demonstrate that the prop osed method s substan tially outper form existing solution m ethods fo r CBGs. In ad dition, th e experim ents confirm th e hy pothesis that NDP is n ot ab le to e ffecti vely explo it typ e indep endence , resultin g in exponential scaling w ith r espect to the number of types. M A X - P L U S on A TI factor g raphs is a ble to effecti vely exploit both ag ent and type in depend ence, resu lting in much better scaling behavior with respect to all mod el parameter s. Finally , the experiments showed tha t the value of the found solutions was not significantly lower than the optimal value and, in many case, s ign ificantly better than that found by other approxim ate solution methods. 3.6 Generalized Fire Fighting Expe riments The re sults pr esented above demon strate that M A X - P L U S -A TI can improve p erform ance on a wide range of CGBGs. However , all of th e CGBGs used in those experim ents were rand omly g enerated. In th is sectio n, we aim to demon strate that the advantages of M A X - P L U S -A TI extend to a more realistic problem. T o this end, we apply it to a 2-dimensional implemen tation of the G E N E R A L I Z E D F I R E F I G H T I N G problem describe d in Sec. 3.2. Each method was limited to 2Gb of memory and allo wed 30 s computation time. In this implem entation, the N H houses ar e un iformly sprea d acr oss a 2- dimensiona l plane, i.e ., the x an d y coordin ates for each house are drawn from a u niform distribution over the interval [ 0 , 1 ] . Similarly , each of the n agen ts is assigned a rand om locatio n an d can choose to fight fire at any of N A nearest ho uses, subject to th e constraint that at mo st k agents can figh t fire at a particular house. W e enforc e this constraint by making a house 23 2 3 4 5 6 7 8 9 10 0.99 0.992 0.994 0.996 0.998 1 1.002 1.004 1.006 1.008 1.01 Varying # actions −− Payoffs Relative Payoffs # actions MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) Scaling | A i | : P ayoff ( k = 2 , | Θ i | = 3 , n = 5). 2 3 4 5 6 7 8 9 10 10 −3 10 −2 10 −1 10 0 Varying # actions −− Computation Times Computation time (s) # actions MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) Sc aling | A i | : Computation times ( k = 2 , | Θ i | = 3 , n = 5). 2 3 4 5 6 7 0.99 0.992 0.994 0.996 0.998 1 1.002 1.004 1.006 1.008 1.01 Varying # types −− Payoffs Relative Payoffs # types MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (c) Scaling | Θ i | : P ayoff ( k = 2 , | A i | = 3 , n = 5). 2 3 4 5 6 7 10 −3 10 −2 10 −1 10 0 Varying # types −− Computation Times Computation time (s) # types MaxPlus−AI MaxPlus−ATI MaxPlus−TI NDP−AI NDP−ATI NDP−TI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (d) Sc aling | Θ i | : Computation times ( k = 2 , | A i | = 3 , n = 5). Figure 1 1: Compa rison of th e p ropo sed factor -gr aph methods when scaling the num ber of actions and th e number of types. Plots (a ) and (b) consider scaling | A i | ( analogou s to Fig . 9 (c) and 9(d)), while (c) and (d) show results increasing | Θ i | (cf. Fig. 9(e) and 9(f)). unav ailable to additional agents once it is in the action sets of k agents. 13 In addition, each agent is assigned, i n a similar fashion, the N O nearest ho uses that it can o bserve. As mentio ned in Sec. 3 .2, a type θ i is defin ed b y the N O observations the agent receives from the surrounding houses: θ i ∈ { F i , N i } N O . W e assume that N O ≤ N A to ensure that no local p ayoff function depen ds on an agent simply due to that agen t’ s type, i.e., a n agent never observes a house at which it cannot fight fire. T o ensure th ere ar e always en ough hou ses, the number of houses is made pro portion al to both th e nu mber of ag ents and actions: N H = ceil ( N d · N A · n ) , wh ere N d is set to 1 . 2 un less n oted other wise. Each house h as a fire level th at is d rawn unif ormly f rom { 0 , . . . , N f − 1 } . T he pr obability th at an agent r eceives the ob servation F fo r a house H d epends on it s fir e level, as s hown in T able 5. Observations of different houses by a single agent i are assumed to be independen t, but observations of dif fer ent agents that can observe the same house are coupled throu gh the hidden st ate. 13 While this can lead to a sub-opt imal assignment, we do not need the best assignment of action sets in order to compare methods. 24 x H Pr ( F | x H ) 0 0 . 2 1 0 . 5 > 1 0 . 8 T able 5: T he observation proba bilities of a house H . The local rew ard ind uced by each house is de pends on the fire lev el an d the number of agents that cho se to fight fire at that house. It is specified by R ( x H , n present ) = − x H · 0 . 7 n present . As in Sec. 2. 3.1, this re ward can be transformed to a (in this case local) utility fun ction b y tak ing the expectation with respect to the hidden state: u H ( θ H , a H ) = N f ∑ x H = 1 Pr ( x H | θ H ) R ( x H , CountAgentsAtHouse ( x H , a H )) , where CountAge ntsAtHouse() counts the numb er of agents for which a H specifies to fight fire at house H . This formu lation of G E N E R A L I Z E D F I R E F I G H T I N G , while still a bstract, cap tures the essential co ordina- tion challenges inherent in many realistic problems. For instance, this formu lation m ay directly map to the problem of fire fighting in the Roboc up Rescue Simu lation league (Kitan o et al., 1999): fire fighting agents are distributed in a city and m ust decide at which h ouses to fight fire. While limited commu nication may be possible, it is inf easible for e ach agent to broadcast all its ob servations to all the other agents. If instead it is feasible to co mpute a joint BG-policy based on the agents’ positions, then the y can effecti vely coord inate without b roadcasting their o bservations. When interpretin g th e houses as qu eues, it also directly corr esponds to problems in queueing networks (Cogill et al., 2004). The results of our experiments in this domain, s hown in Fig. 12, demo nstrate that M A X - P L U S has the most desirable scaling beh avior in a v ariety of d ifferent paramete rs. In particular, Fig. 12(a) an d 12(b) show tha t all appro ximate method s scale well with respect to the nu mber of action s per ag ent, but M A X - P L U S perfor ms best. Fig. 12(c) shows th at this scalab ility does not come at th e expense of solution q uality . For all settings, all the metho ds computed solutions with the same value ( other plots of value are thus omitted for bre vity ). The advantage of exploiting agent in depend ence is illustrated in Fig. 1 2(d), which demon strates th at M A X - P L U S scales well with th e n umber of agen ts, in contr ast to the other methods. In Fig. 12( e) we varied th e N d parameter, which determines how many houses are present in t h e domain. It shows tha t M A X - P L U S is s ensitive to k , the maximum n umber of agents tha t pa rticipate in a ho use. Howe ver , it also dem onstrates th at wh en the interaction is spa rse (i.e., when ther e are many h ouses per ag ent an d ther efore o n average f ewer than k ag ents per house) th e increase in r untime is much b etter than the worst-case exponential gr owth. 14 Fig. 12(f) shows how runtime scales with N O , th e numb er of hou ses observed by ea ch agen t. Since the numb er of typ es is exponential in N O , M A X - P L U S ’ s run time is also expo nential in N O . Nonetheless, it sub stantially o utperfo rms the other appro ximate methods. 14 The dense setting N d = 0 . 5 does not have data p oints a t k = 1 because i n thi s case there a re not enough houses t o be assigned to t he agents. 25 2 3 4 5 6 7 8 9 10 10 −3 10 −2 10 −1 10 0 10 1 10 2 Computation time (s) Number of actions (houses) per agent BaGaBaB AltMax CE MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) Runtime for varyi ng number of actions when each agent observes 1 house (2 type s per agent). 2 3 4 5 6 7 8 9 10 10 −2 10 −1 10 0 10 1 10 2 Computation time (s) Number of actions (houses) per agent BaGaBaB AltMax CE MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) R untime for varyin g number of actions when each agen t observe s 2 houses (4 types per agent). 2 3 4 5 6 7 8 9 10 −50 −45 −40 −35 −30 −25 −20 −15 −10 −5 Number of actions (houses) per agent Payoff BaGaBaB AltMax CE MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (c) T he v alues for Fig. 12(a). The value decreases since the number of houses is proport ional to t he number of actio ns. 0 10 20 30 40 50 10 −3 10 −2 10 −1 10 0 10 1 10 2 Computation time (s) Number of agents BaGaBaB AltMax CE MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (d) V aryi ng number of agents. Each agent observe s 2 houses (4 types per agent ). 1 2 3 4 10 −3 10 −2 10 −1 10 0 Computation time (s) Max scope size (k) N d 0.5, AltMax N d 0.5, MP−ATI N d 0.9, AltMax N d 0.9, MP−ATI N d 1.2, AltMax N d 1.2, MP−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (e) Runtime for varyin g k , the maximum number of agen ts that participate in a payo ff compo nent. Result s are fo r 4 agents with 3 a ctions a nd 2 observed houses (4 types), for dif ferent val ues of N d . 1 2 3 4 5 10 −3 10 −2 10 −1 10 0 10 1 10 2 Computation time (s) Number of houses observed BaGaBaB AltMax CE MaxPlus−ATI P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (f) Ru ntime for v arying number of hou ses that are observ ed per agent. Note that the number of type s is exponen tial in this number . R esults are for 4 agents with 5 actions. Figure 12: Results for the G E N E RA L I Z E D F I R E F I G H T I N G problem. 26 4 Exploiting Independence in Dec-POMDPs While CBGs model an important class of collaborative decision-making problems, the y apply only to one-sho t settings, i.e., wh ere each agent need s to select o nly one actio n. Ho wever , the methods for exploiting agent and type independ ence that we prop osed in Sec. 3 can also p rovide substantial leverage in sequential tasks, in which agents take a series of actions over time as the state of the environment e volves. In par ticular , many sequential collaborative decision- making tasks can b e f ormalized as dece ntralized p artially ob servable Markov d ecision pr ocesses (Dec- POMDPs) (Bernstein et al., 2002). In this section we demo nstrate how C GBGs can be u sed in a planning method for the subclass of factor ed Dec-POMDPs with additi vely factored re wards (Oliehoek et al., 2008c). The resulting method, called F AC T O R E D F S P C, can find ap proxim ate solution s for classes of p roblems that cannot be addre ssed at all by any other planning methods. Our aim is not to present F AC T O R E D F S P C as a main contribution of this article. Instead, we merely use it as a vehicle for illustratin g th e utility o f th e CGBG f ramework. Th erefore, for the sake of conciseness, w e do not describe this method in full technica l deta il. Instead, we merely sketch the solution appro ach and sup ply referenc es to other work containing more detail. 4.1 Fact ored Dec-POMDPs In a Dec -POMDP , multiple agents m ust co llaborate to maximiz e the sum of th e com mon rew ard s they receive over multiple timesteps. Their actions affect n ot o nly their imm ediate r ew ard s but also the state to which they transition. While the current state is not kn own to the agen ts, at each timestep each agent re ceiv es a priv ate observation c orrelated with th at state. In a factored Dec-POMDP , the state consists of a vector of state variables and the rew ard func tion is the sum of a set of local re ward functions. Definition 4.1. A factored Dec-POMDP is a tuple D , S , A , T , R , O , O , b 0 , h , where • D = { 1 , . . . , n } is the set of agents. • S = X 1 × . . . × X | X | is the factored state space. Th at is, S is spann ed by X = X 1 , . . . , X | X | , a set of state variables, or factors. A state correspo nds to an assignment of values for all factors s = x 1 , . . . , x | X | . • A = × i A i is the set of joint actions , where A i is the set of actions av ailable to agent i . • T is a tr ansition function specifying the state transition probab ilities Pr ( s ′ | s , a ) . • R = { R 1 , . . . , R ρ } is the set of ρ local rew ar d fun ctions. Again, these correspo nd to a interaction graph with (hyper) edges E su ch that the total immediate rew ard R ( s , a ) = ∑ e ∈ E R e ( x e , a e ) . • O = × i O i is the set of joint observations o = h o 1 ,..., o n i . • O is the observation function, which specifies observation probabilities P r ( o | a , s ′ ) . • b 0 is the initial state distribution at time t = 0. • h is the horizon, i.e., the number of stages. W e co nsider the case where h is finite. At each stage t = 0 . . . h − 1, each agent takes an in dividual action and receives an individual observation. Their g oal is to ma ximize the expec ted cu mulative r ewar d or return . The plan ning task entails finding a joint policy π = h π 1 , . . . , π n i , tha t specifies an ind ividual po licy π i for each agent i . Such an individual po licy in general specifies an in dividual actio n f or each action-observation h istory ¯ θ t i = ( a 0 i , o 1 i , . . . , a t − 1 i , o t i ) , e.g ., π i ( ¯ θ t i ) = a t i . Howe ver , when only allo wing deterministic or pur e policies, π i maps each observation h istory ( o 1 i , . . . , o t i ) = ¯ o t i ∈ ¯ O t i to an ac tion, e.g ., π i ( ¯ o t i ) = a t i . In a factored Dec-POMDP , the tran sition and ob servation model can b e compactly represen ted in a dynamic Bayesian network (DBN) (Boutilier et al., 1999). 27 4.1.1 Sequential Fire Fighting As a runn ing e xam ple we consider the S E Q U E N T I A L F I R E F I G H T I N G prob lem, which is a sequen tial v ar iation of G E N E R A L I Z E D F I R E F I G H T I N G fr om Sec. 3 .2, originally introduce d b y Olieh oek et al. (200 8c ). 15 In this version, e ach h ouse, in stead o f simp ly bein g on fire o r n ot, ha s an integer fire level th at can change over time. Thus, th e state of the en viron ment is f actor ed, u sing one state variable for th e fire level in each ho use. Each agent rece iv es an ob servation about the h ouse at which it foug ht fire in the la st stage. It ob serves flames ( F ) at this house with prob ability 0 . 2 if x H = 0, with probab ility 0 . 5 if x H = 1, and with proba bility 0 . 8 otherw ise. At each stage, each agent i chooses at which of its a ssigned ho uses to fight fire. These actio ns affect (prob abilistically) to what state th e environment transitions: the fire level of each h ouse H is influenced b y its previous value, by the actions o f the age nts that can go to H and th e fire level of the neighbor ing houses. The transitions in turn d etermine what rew ard is generated . Specifically , each house generates a ne ga ti ve rew ard equal to its e xpe cted fire level at the next stag e x ′ 1 . T hus, the rew ard fun ction can be described as the sum of local re ward fu nctions, one for each ho use. W e consider the case of N H = 4 as shown in Fig. 4. For h ouse H = 1 the reward is specified by R 1 ( x { 1 , 2 } , a 1 ) = ∑ x ′ 1 − x ′ 1 Pr ( x ′ 1 | x { 1 , 2 } , a 1 ) , (4.1) where x { 1 , 2 } denotes h x 1 , x 2 i . This f ormulation is possible b ecause x 1 , x 2 and a 1 are the only variables that influence the pr obability of x ′ 1 . Similarly , the other local reward functions are given by R 2 ( x { 1 , 2 , 3 } , a { 1 , 2 } ) , R 3 ( x { 2 , 3 , 4 } , a { 2 , 3 } ) and R 4 ( x { 3 , 4 } , a 3 ) . For more details abo ut the formu lation of S E Q U E N T I A L F I R E F I G H T I N G as a factored Dec-POMDP , see (Olieho ek, 2010). 4.1.2 Solving Dec-POMDPs Solving a Dec-POMDP entails finding an optimal joint policy . Unfortun ately , optim ally solving Dec-POMDPs is NEXP-complete (Bernstein et al., 2002), as is finding an ε -appro ximate solution (Rabinovich et al., 2003). Giv en these difficulties, most research efforts ha ve focused on special cases that are mo re tractable. I n par- ticular , assumption s of transition an d observatio n indepen dence (TOI) (Becker et al., 2004) h av e b een investi - gated to explo it ind ependen ce between agents, e.g., as in ND-POMDPs (Nair et al., 2005; V arakan tham et al., 2007). Howe ver , gi ven the T OI assumption, many interesting tasks, such as two robots carrying a chair , cannot be modeled . Recently , W itwicki and Durfe e (2010) proposed transition-decoupled Dec-POMDPs, in which there is lim ited intera ction be tween the agents. While this app roach spe eds u p both op timal and appr oximate solutions of this su bclass, scalability remains limited (the a pproach has not b een tested with mo re than tw o agents) and the sub-class still is quite restrictive (e.g., it does not admit the chair carrying scenario). Other w ork has considered approx imate m ethods for the general class of Dec-POMDPs based on represent- ing a Dec-POM DP using CBGs (Emery- Montemer lo et al., 2004) o r on ap proxim ate dynamic programmin g (Seuken and Zilberstein, 2007). I n the remainder of this section, we show CGB Gs can help th e former c ategory of methods achieve unpreceden ted scalability with respect to the number of agents. 4.2 Fact ored Dec-POMDPs as Series of CGBGs A stage t o f a Dec-POMDP can be represented as a CBG, given a past joint policy ϕ t . Su ch a ϕ t = ( δ 0 , . . . , δ t − 1 ) specifies the jo int decision ru les fo r the first t stages. An in dividual decision rule δ t i of ag ent i correspo nds to the part of its po licy that specifies actions fo r stage t . That is, δ t i maps fro m observation histories ¯ o t i to actio ns a i . Giv en a ϕ t , the correspo nding CGB is constructe d as follows: 15 In (Oliehoek et al., 2008c), this problem is referred to as F I R E F I G H T I NG G R A P H . W e use a differe nt name here to d istinguish it from G E N E RA L I Z E D F I R E F I G H T I N G , whi ch is also graphical . 28 • Th e action sets are the same as in the Dec-POMDP , • Eac h i ’ s action -observation history ¯ θ t i correspo nds to its type: θ i ≡ ¯ θ t i , • Th e probability of joint types is specified by Pr ( ¯ θ t | b 0 , ϕ t ) = ∑ s t Pr ( s t , ¯ θ t | b 0 , ϕ t ) . • Th e payoff function u ( θ , a ) = Q ( ¯ θ t , a ) , the expected payoff for the remaining stages. Similarly , a factored Dec-POMDP can be represented by a series of CGBGs. T his is po ssible b ecause, in general, the Q- function is factored. I n o ther words, it is the su m o f a set of loca l Q-fu nctions of the fo llowing form: Q e ( x t e , ¯ θ t e , a e ) . Each local Q- function depen ds on a subset of state factors (th e state factor scope) and the action-ob servation histories and actions of a subset of agents (the agen t s co pe) (Oliehoek, 2010). Constructing a CGBG for a stage t is similar to constru cting a CBG. Given a past joint policy ϕ t , we can construct the local payoff functions for the CGBG: u e ( θ e , a e ) ≡ Q e ϕ t ( ¯ θ t e , a e ) = ∑ x t e Pr ( x t e | ¯ θ t e , b 0 , ϕ t ) Q e ( x t e , ¯ θ t e , a e ) . (4.2) As such, the structure of the CGBG is induced by the structure of the Q-value function. As an example, con sider 3- agent h = 2 S E Q U E N T I A L F I R E F I G H T I N G . Th e last stage t = 1 can be repre- sented as a CGBG given a past joint p olicy ϕ 1 . Also, since it is the last stage, the factored im mediate reward function , (e.g. , as in E quation 4.1) represen ts all the expected f uture r ew ard. That is, it coincides with an optimal factored Q-value function (Oliehoek et al., 2008c) and can be written as follows: Q 1 ϕ 1 ( ¯ θ 1 e , a e ) = ∑ x 1 e Pr ( x 1 e | ¯ θ 1 e , b 0 , ϕ 1 ) R 1 ( x 1 e , a e ) . (4.3) This situation can be repre sented using a CGBG, b y using the Q-value func tion as the pa yoff fun ction: u e ( θ e , a e ) ≡ Q e ϕ t ( ¯ θ t e , a e ) as shown in Fig . 13. The figure shows the 4 comp onents of the CGBG, each one correspo nding to the payo ff associated with one hou se. It also indicates an arbitrar y BG policy for agent 2. Note that, since comp onents 1 and 4 of the Q- value fu nction have scop es that are ‘subscopes’ of comp onents 2 and 3 respecti vely , the form er can be absorbe d in to the latter, redu cing th e num ber of compo nents with out increasing the size of those that remain. The following theo rem by Oliehoek et al. (2008c), shows that modeling a factored Dec-POMDP in this way is in principle exact. Theorem 4.1. Modeling a facto r ed Dec-POMDP with ad ditive re war ds usin g a series of CGBGs is e xact: it yields the optimal solution when using an optimal Q-value function . While an optimal Q-value function is factored, the last stage contains the most in depend ence: when moving back in time towards t = 0, the scope of depen dence grows, du e to the transition and observation function s. Fig. 14 illustrates this pr ocess in S E QU E N T I A L F I R E F I G H T I N G . Thu s, e ven though the value fu nction is factored, the scopes of its componen ts may at earlier stages include all state factors and agents. 4.3 Fact ored Forward Sweep P olicy Computation Defining the payoff fu nction for each C BG represen ting a s tage of a Dec-POMDP requires computing Q ( ¯ θ t , a ) , an o ptimal pay off function. Unfortun ately , doing so is intractab le. Therefo re, Dec-POMDP m ethods b ased on CBGs typically u se approximate Q-v alue functions in stead. One option (Q BG ) is to assume that each agent always has access to the joint observations for all previous stage s, b ut can access only its individual observation for the current stage . Anoth er cho ice is based on the underly ing POMDP (Q POMDP ), i.e., a POMDP with the 29 θ 1 ( F ) H 1 − 0 . 25 H 2 − 1 . 10 ( N ) H 1 − 0 . 14 H 2 − 0 . 79 Q e = 1 , A = { 1 } θ 2 ( F ) ( N ) θ 1 H 2 H 3 H 2 H 3 ( F ) H 1 − 0 . 55 − 1 . 60 − 0 . 50 − 1 . 50 H 2 0 − 0 . 55 0 − 0 . 50 ( N ) H 1 − 0 . 16 − 1 . 10 − 0 . 14 − 1 . 00 H 2 0 − 0 . 16 0 − 0 . 14 Q e = 2 , A = { 1 , 2 } θ 3 ( F ) H 3 − 1 . 50 H 4 − 0 . 51 ( N ) H 3 − 1 . 10 H 4 − 0 . 15 Q e = 4 , A = { 3 } θ 2 ( F ) ( N ) θ 3 H 2 H 3 H 2 H 3 ( F ) H 3 − 1 . 10 0 − 0 . 71 0 H 4 − 1 . 90 − 1 . 10 − 1 . 70 − 0 . 71 ( N ) H 3 − 1 . 00 0 − 0 . 58 0 H 4 − 1 . 90 − 1 . 00 − 1 . 60 − 0 . 58 Q e = 3 , A = { 2 , 3 } Figure 13: A CGBG f or t = 1 o f S E Q U E N T I A L F I R E F I G H T I N G . Gi ven a past join t policy ϕ 1 , each join t type θ correspo nds to a joint action-ob servation history ¯ θ 1 . The entries gi ve the Q-values Q e ( ¯ θ t e , a e ) . Highligh ted is an arbitrary policy for agent 2. same transition and ob servation function in which a single agen t receiv es the joint ob servations and takes joint actions. A third option is based on the underly ing MDP (Q MDP ), in which this single agent can directly observe the state. Giv en an ap proxim ate Q-fu nction, an appr oximate solution for the Dec-POMDP can be computed via forwar d-sweep policy computation (F S P C ) by simply solving the CBGs for stages 0 , 1 , . . . , h − 1 consecutively . The solution to each CB G is a joint decision rule specified by δ t ≡ β t , ∗ that is used to augment the past policy ϕ t + 1 = ( ϕ t , δ t ) . The CBGs are solved co nsecutively be cause b oth the probabilities and the payoffs at each stage depend on the past policy . It is also possible to compute an optimal policy via backtracking , as in multiagent A ∗ ( M A A ∗ ). Howe ver , since doing so is much more computationally intensi ve, we focus on F S P C in this ar ticle. In the r emainder of this section, we d escribe a me thod we call F A C T O R E D F S P C for appro ximately solving a b roader class o f factored Dec -POMDPs in a way that scales well in the nu mber of agents. The main idea is simply to replace the CBGs used in each stage of the Dec-POMDPs with CGBGs, which are then solved using the methods presented in Sec. 3. Since findin g even bounded approximate solutions for Dec-POMDPs is NEXP-co mplete, any compu ta- tionally efficient method must n ecessarily make unb ounde d approximation s. Belo w , w e describe a set o f such approx imations designed to make F AC TO R E D F S P C a pr actical algorithm. While we present only an o verview here, comp lete details are a vailable in (Oliehoek, 2010). Also, thou gh the results we present in this article ev aluate only the c omplete resulting method, Oliehoek (2010) empirically e valuated each of the compone nt approx imations separately . 30 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n h − 3 h − 2 h − 1 x 1 x 1 x 1 x ′ 1 a 1 a 1 a 1 o 1 o 1 R 1 x 2 x 2 x 2 x ′ 2 a 2 a 2 a 2 o 2 o 2 R 2 x 3 x 3 x 3 x ′ 3 a 3 a 3 a 3 o 3 o 3 R 3 x 4 x 4 x 4 x ′ 4 R 4 Figure 14 : The scope of Q 1 , illustrated by sh ading, in creases when g oing back in time in S E Q U E N T I A L F I R E F I G H T I N G . 4.3.1 Ap proximat e Infer ence One sour ce of intractability in F AC T O R E D F S P C lies in the marginalization required to c ompute the prob - abilities Pr ( ¯ θ t e | b 0 , ϕ t ) and Pr ( x t e | ¯ θ t e , b 0 , ϕ t ) . In pa rticular, constructing each CGBG requires gen erating each compon ent e separately . Howe ver , as ( 4.2) sho ws, in general th is requires the probab ilities Pr ( x t e | ¯ θ t e , b 0 , ϕ t ) . Moreover , in any efficient solu tion algorithm for Dec-POMDPs, th e probab ilities Pr ( ¯ θ t e | b 0 , ϕ t ) are necessary , as illustrated b y (3 .1). Since m aintaining and marginalizing over P r ( s , ¯ θ t | b 0 , ϕ t ) is intra ctable, we resort to ap - proxim ate inference, as is stand ard practice wh en comp uting probab ilities ov er states with m any factors. Such methods per form well in m any cases and th e er ror they in troduce can in so me cases be th eoretically bo unded (Boyen and K oller, 1998). In our case, we use the factored frontier (FF) algorithm (Murphy and W eiss, 200 1) to perform approximate inference on a DB N constructed for the past joint policy ϕ t under concern. T his DBN models stages 0 , . . . , t and has both state factors and actio n-observation histories as its n odes. W e use FF becau se it is simple an d allows computatio n of s om e useful intermediate representatio ns when a heuristic of the form Q e ( x t e , a t e ) (e.g., factored Q MDP ) is used. Other appro ximate inference algorithms (e.g., Murphy 2002; Mooij 2008a), could also be used. 4.3.2 Ap proximat e Q-V alue Functions Computing the op timal value functions to use as pay offs for the CGBG for each stage is intractab le. For small Dec-POMDPs, heuristic payoff fun ctions su ch as Q MDP and Q POMDP are typically used instead (Oliehoek et al., 2008b). Howe ver, for Dec-POMDPs of th e size we consider in this article , solving the underlying MDP or POMDP is also intractable. Furthermo re, factored Dec-POMDPs pose an add itional pro blem: the scopes o f Q ∗ increase when going backwards in time , such that they are ty pically fu lly coupled f or earlier stages (see Fig. 14). T his problem is exacerbated when Q MDP and Q POMDP are used as heuristic payoff f unction s b ecause they become fully coupled throug h just one backup (due to the maximiza tion o ver joint actions that is conditioned on the state or belief). Fortunately , many research ers ha ve considered factored ap proxim ations fo r facto red MDPs and factored POMDPs (Schweitze r and Seidman, 1985; Koller and P arr, 1 999, 200 0; Schuurm ans and Patrascu, 2 002; Guestrin et al., 2001a,b, 2003; de Farias and V an Roy, 2 003; Szita and L ¨ orin cz, 2008). W e follow a similar ap proach for Dec- POMDPs by u sing value functio ns with pred etermined a pprox imate scop es. The idea is that in many cases the influen ce o f a state factor q uickly vanishes with the num ber of links in the DBN. For instanc e, in th e case 31 of transition an d ob servation indepen dence (TOI), th e o ptimal scopes equ al th ose o f the factored immediate rew ard functio n. In many cases where there is no complete TOI, the amount of interaction is s till limited, mak- ing it possible to determine a reduced set of sco pes for each stage th at affords a good appr oximate solution. For exam ple, con sider the optima l scopes shown in Fig. 14. T hough x 4 at h − 3 ca n influence x 2 at h − 1, the magnitud e of this influence is likely to be small. Ther efore, restricting the scope of Q 1 to exclude x 4 at h − 3 is a reasonab le approx imation. Follo wing the literature on factor ed MDPs, we use manually specified scope structures (this is eq uiv alent to specifying basis functions). I n the experiments presented in this article, we simply use the immediate re ward scopes at each stage, though m any alternative strategies are possible. While de veloping methods for finding such scope structur es automatically is an im portant goal, it is beyond the scope o f this article. A heur istic approa ch suf fices to validate the utility o f the CGBG fram ew ork becau se our metho ds require only a goo d approx imate f actor ed v alue function whose scopes preserve some independen ce. T o compute a he uristic gi ven a specified scope structure, we use an appro ach we call tr an sfer planning . T ransfe r planning is moti vated by the observ ation that, for a factored Dec-POMDP , the value function is ‘more factored’ th an for a factored MDP . In the f ormer, depen dence pr opagates over time, while the latter beco mes fully coupled throu gh just one bac kup. Therefo re, it may be pre ferable to directly approximate the factored Q-value function of the Dec-POMDP rath er th an th e Q MDP function . T o do so, we use the solu tion of smaller sour ce pro blems that in volve fewer agents. That is, transfer plannin g directly tr ies to find h euristic values Q e ϕ t ( ¯ θ t e , a e ) ≡ Q s ( ¯ θ t , a ) by solving tasks that are similar (but sm aller) a nd using th eir value fun ctions Q s . T he Q s can result from the solutions of the smaller Dec-POMDPs, or of their underlyin g MDP or POMDP . In order to map the v alues Q s of the source tasks to the CGB G compo nents Q e ϕ t , we specify a mapping from agents participating in a compon ent e to agents in the source prob lem. Since no fo rmal claims can be made about these approx imate Q-values, we cannot gu arantee that they constitute an ad missible heuristic. Howev er, since we rely o n F S P C , wh ich does no t backtrac k, an ad missible heuristic is not ne cessarily b etter . Per forman ce depen ds o n th e acc uracy , not the admissibility of the heur istic (Oliehoek et al., 2 008b). T he experim ents we present b elow dem onstrate that these ap proxim ate Q-values are accurate enough to enable high quality solutions. 4.4 Experiments W e ev aluate F AC T O R E D F S P C on two pro blem domain s: S E Q U E N T I A L F I R E F I G H T I N G and the A L O H A pr ob- lem (Olieho ek, 201 0). The la tter consists of a n umber o f island s, each equipp ed with a radio u sed to transmit messages to its loc al population . Each islan d has a qu eue of messages that it need s to send and at ea ch time step can decide whether or not to send a message. When two neighbor ing islands attempt to send a message in the same timestep, a collision occurs. E ach island can noisily observe whether a successful transmission (by itself or the neighbors), no tr ansmission, or a collision occurred. At each timestep, eac h island recei ves a r ew ard of − 1 for ea ch m essage in its queue. A L O H A is c onsiderab ly more comp lex than S E Q U E N T I A L F I R E F I G H T - I N G . First, it has 3 o bservations per ag ent, wh ich m eans th at the n umber of o bservation histories grows much faster . Also, the transition mod el o f A L O H A is mo re densely conn ected than S E Q U E N T I A L F I R E F I G H T I N G : the rew ard com ponen t for each island is affected by the is land itself and all its n eighbor s. As a result, in all th e A L O H A pro blems we consider, there is at least one imm ediate rew ard fu nction whose scope con tains 3 agents, i.e., k = 3 . Fig. 1 5 illu strates the case with fou r islands in a square configu ration. The exper iments below also consider variants in which isl an ds are connected in a line. In all cases, we use im mediate r ew ard scopes th at h av e been red uced (i.e., scopes that form a prop er sub - scope of anoth er scope are rem oved) before comp uting the factored Q- value functions. This means th at for a ll stages, the factored Q-value f unction ha s the same factoriza tion a nd thu s the A TI factor g raphs h av e identical shapes (alth ough the numb er of types differ). For S E Q U E N T I A L F I R E F I G H T I N G , the A TI factor gr aph for 32 P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n Figure 15: The A L O H A pr oblem with four islands arranged in a square. ... ... ... ... ... ... ... ... ... ... ... P S f r a g r e p l a c e m e n t s V a l u e t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n u 1 u 2 u 3 u 4 C h N 1 , N 2 i C h 1 , 1 , 1 i C h 1 , 1 , M i C h 1 , M , 1 i C h 1 , M , M i C h M , 1 , 1 i C h M , 1 , M i C h M , M , 1 i C h M , M , M i ¯ θ t 1 , 1 ¯ θ t 1 , M ¯ θ t 2 , 1 ¯ θ t 2 , M ¯ θ t 3 , 1 ¯ θ t 3 , M ¯ θ t 4 , 1 ¯ θ t 4 , M β 1 β 2 β 3 β 4 Figure 16 : T he A TI factor grap h for imm ediate reward scopes in A L O H A . T he conn ections of u 2 are shown in detail by the black dashed lines; connections for other factors are summarized abstractly by the blue s olid lines. a stage t is the same as that fo r G E N E R A L I Z E D F I R E F I G H T I N G (see Fig. 6), except that the types θ k i now correspo nd to action- observation histor ies ¯ θ t i , k . The A TI factor g raph fo r a s tage t of the A L O H A proble m is shown in Fig. 16. T o c ompute Q T P , the transf er-planning h euristic, for the S E Q U E N T I A L F I R E F I G H T I N G pro blem, we use 2-agen t S E QU E N T I A L F I R E F I G H T I N G as th e sou rce p roblem for a ll th e edg es and m ap th e lower ag ent in dex in a scope to ag ent 1 and the higher index to agent 2. For the A L O H A problem, we u se th e 3 -island in -line variant as the source problem and perf orm a similar mapping , i.e., the lo west ag ent index in a scope is mapp ed to agent 1, the middle to agent 2 an d the highest to age nt 3. For both problems we use the Q MDP and Q BG heuristic for the source problem s. For p roblem s small enough to solve optimally , we compare the solution quality of F AC T O R E D F S P C to that of GMAA*-ICE, the state-of-the- art method for optimally solving Dec-POMDPs (Spaan et al., 2011). W e also compare ag ainst several o ther ap proxim ate methods fo r so lving Dec -POMDPs, in cluding non -factored F S P C and direct cross-entropy po licy search ( D I C E ) (Olieho ek et al., 20 08a), one of the few meth ods demonstrated to work on Dec-POMDPs with more than th ree agents that are no t transition and observation independent. For 33 -14 -12 -10 -8 -6 -4 2 3 4 5 6 Optimal n=2 ff QMDP n=2 ff QBG n=2 Fixed Action n=2 Random n=2 Optimal n=3 ff QMDP n=3 ff QBG n=3 Fixed Action n=3 Random n=3 P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) Horizon N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (a) S E QU E N T I AL F I R E F I G H T I N G . -25 -20 -15 -10 -5 0 2 3 4 5 Optimal n=3 ff QMDP n=3 Fixed Action n=3 Random n=3 Optimal n=4 ff QMDP n=4 Fixed Action n=4 Random n=4 P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) Horizon N u m b e r o f a g e n t s I s l a n d c o n fi g u r a t i o n (b) A L O H A . Figure 17: F A C T O R E D F S P C (ff) solution quality compared to optimal and the baselines. non-factor ed F S P C, we use alternatin g m aximization with 10 restarts to solve the CBGs. For D I C E we ag ain use the two parameter settings described in Sec. 3.5 (D I C E -no rmal and D I C E -fast). As baselines, we in clude a ran dom jo int policy and the best joint po licy in which each agent selec ts th e same fixed action for all possible histories (thoug h the agents can select different actions from each other). Naturally , these simp le p olicies are sub optimal. Howe ver , in the case of th e fixed- action baseline, simplicity is a virtue. The reason stems from a fundamen tal d ilemma Dec- POMDP agents face ab out how m uch to e xp loit their p riv ate observations. Doing so help s them accr ue more local reward b ut makes their behavior less predictab le to other agents, complicating co ordin ation. Becau se it does not exploit pri vate observations at all, the disadvantages of the fixed- action policy are partially com pensated by the a dvantages of predictability , yielding a surprising ly strong baseline. W e also co nsidered includin g a b aseline in which the ag ents are allowed to select d ifferent actions at each timestep (but are still con strained to a fixed action for all h istories of a given length). Howe ver , computing th e best fixed policy o f this fo rm proved intractab le. 16 Note th at it is n ot possible to use the solution to the u nder- lying factor ed MDP as a baseline, for two re asons. First, computing such solutions is n ot feasible for p rob- lems of the size w e consider in this ar ticle. Second, such solutions would n ot co nstitute mea ningfu l baselines for comp arison. On the c ontrary , since such solutions cann ot be executed in a decentralized fashion without commun ication, they provide only a l o ose upper b ound on the p erform ance po ssible with a Dec-POMDP , as quantitatively demonstrated by Oliehoek et al. (2008b). The experimen tal setup is a s presented in Sec. 3 .5.1, but with a mem ory limit of 2Gb and a maximum computatio n time of 1 hou r . The repor ted s tatistics are m eans over 10 restarts of each method. On ce joint policies have been computed, we perfor m 10 , 00 0 simulation runs to estimate their true values. Fig. 17 comp ares F AC T O R E D F S P C ’ s solutions to optima l solutions on bo th p roblems. Fig. 17( a) show the r esults for S E Q U E N T I A L F I R E F I G H T I N G with two (red ) and th ree agen ts (gr een). Optimal solution s were computed up to horizon 6 in the former and horizon 4 in the latter problem. F AC T O R E D F S P C with the Q BG TP heuristic achiev es the optimal value for all these instances. When using the Q MDP TP heuristic, results are near 16 In fact, the complexity of doing so is O ( | A nh ∗ ) , i.e., exponentia l in both the number of agents and the horizon. This is consistent with the c omplexity result for the non-observ able problem (NP-c omplete) (Pynadath and T ambe, 2002). By sea rching for an open-loop plan, we ef fecti vely treat the problem as nonobserva ble. 34 -22 -20 -18 -16 -14 -12 -10 -8 -6 2 3 4 5 6 7 8 9 10 ff QMDP ff QBG non fact. FSPC DICE-normal DICE-fast Fixed Action Random P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n Number of agents I s l a n d c o n fi g u r a t i o n (a) V al ue for h = 5. 10 -2 10 -1 10 0 10 1 10 2 10 3 2 3 4 5 6 7 8 9 10 ff QMDP ff QBG non fact. FSPC DICE-normal DICE-fast Fixed Action P S f r a g r e p l a c e m e n t s V a l u e time (s) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n Number of agents I s l a n d c o n fi g u r a t i o n (b) R untime for h = 5. Figure 18 : A compar ison of F AC T O R E D F S P C (ff) with d ifferent heuristics and other meth ods on th e S E Q U E N T I A L F I R E F I G H T I N G proble m. optimal. For three agents, the optimal v alue is av ailable only up t o h = 4. None theless, the curve o f F AC T O R E D F S P C ’ s values has the same shap e of as that o f the optim al v alue s for two agen ts, which sug gests these p oints are nea r optim al as well. While the fixed action baselines performs relatively well for shorter h orizon s, it is worse than rand om for lon ger horizo ns because there always is a cha nce that th e no n-selected hou se will keep burning fore ver . Fig. 17(b) sho ws results for A L O H A . T he Q BG TP heuristic is omitted since it performed the same as using Q MDP . For all setting s at which we cou ld com pute the optim al value, F AC T O R E D F S P C matches this value. Since th e A L O H A p roblem is more comp lex, F AC T O R E D F S P C has d ifficulty computing solutio ns for hig her horizon s. In add ition, the fixed action b aseline perf orms surp risingly well, perf orming op timally for 3 islands and near optimally for 4 islands. As with S E Q U E N T I A L F I R E F I G H T I N G , we expect that it would perform worse fo r lo nger horizons: if one agent sends messages f or se veral steps in a row , its neighb or is more likely to have messages ba cked up in its q ueue. Howe ver , we cannot test this assumption since there a re no existing methods capable of solving A L O H A to such ho rizons against which t o comp are. Fig. 1 8 comp ares F AC T O R E D F S P C to oth er appr oximate metho ds on the S E Q U E N T I A L F I R E F I G H T I N G domain with h = 5. For all numbe rs of agents, F AC TO R E D F S P C finds so lutions as good as or better than those of non-factor ed F S P C , D I C E -no rmal, D I C E -fast, an d the fixed-action and random baselines. In addition, its run ning time scales much better than that of n on-factored F S P C and the fixed-action baseline. Hence, this result hig hlights the comp lexity of the pr oblem, as e ven a simple b aseline scales p oorly . F AC T O R E D F S P C also runs substantially mo re q uickly than D I C E -norm al and s ligh tly more q uickly than D I C E -fast, both of which run out of memory when there are more than fi ve agents. Fig. 19 presents a similar com parison for the A L O H A p roblem with h = 3. D I C E - fast is omitted from these plots because D I C E -normal outp erform ed it. Fig. 19(a) shows that the value a chieved by F AC TO R E D F S P C matches or n early match es that of all the other meth ods on all island co nfiguratio ns. Fig. 19(b ) shows the runtime resu lts for the inline configur ations. 17 While th e run time o f F AC T O R E D F S P C is consistently better than that o f D I C E -no rmal, non-factor ed FS P C an d the fix ed- action baseline are faster for small number s of agents. Non -factored F S P C is faster fo r three agen ts becau se the proble m is fully c oupled: there are 3 local 17 W e om it the four agents i n a square configuration in orde r to more c learly illust rate ho w runtime in the inli ne configurations scales with respect to the number of agents. 35 -20 -15 -10 -5 0 3-line 4-line 4-square 5-line 6-line 7-line ff QMDP FSPC DICE-normal Fixed Action Random P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s Island configu ration (a) E xpecte d v alue for h = 3. 10 -1 10 0 10 1 3 4 5 6 7 ff QMDP (Non-fac) FSPC DICE-normal Fixed Action P S f r a g r e p l a c e m e n t s V a l u e time (s) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n N u m b e r o f a g e n t s Island configurat ion (b) R untime for h = 3. Figure 1 9: A co mparison of F AC T O R E D F S P C with different heuristics and other method s on the A L O H A problem with h = 3. payoff functions inv olving 2, 3 , an d 2 agen ts, so k=3. T hus F AC T O R E D F S P C in curs the overhead of dealing with multip le factors and con structing the FG but ach iev es no speedup in re turn. Howe ver , the ru ntime of F AC T O R E D F S P C scales much better as the number of agents increases. Overall, these results d emonstrate that F AC T O R E D F S P C is a substan tial improvement over existing ap- proxim ate Dec-POMDP method s in terms of scaling with respect to the number of agents. Howe ver, the ability of F AC T O R E D F S P C to scale with re spect to the horizon remains limited, sinc e th e n umber o f typ es in the CGBGs still g rows e xpo nentially with the ho rizon. In futu re work we hop e to address this p roblem by cluster- ing types ( Emery-M ontemerlo et al., 200 5; Olieh oek et al., 20 09; W u et al., 20 11). In pa rticular, by clu stering the individual types o f an agent th at induc e similar pay off profiles ( Emery-M ontemerlo et al., 200 5) or pr oba- bilities over types of other ag ents (Oliehoek et al., 2 009) it is possible to scale to much lo nger horiz ons. When aggressively clustering to a constant n umber of typ es, runtime c an be made linear in the horizon (W u et al., 2011). Howe ver, since such a n impr ovement is orthog onal to the u se of CGBGs, it is beyond the scope o f the current article. Moreover, we empirically e valuate the error introduced by a minimal number of approx imations required to achieve scalability with respect to the numb er of agents. Introd ucing further appro ximation s would confou nd these results. Nonetheless, even in its existing fo rm, F AC TO R E D F S P C sho ws grea t prom ise due to its ability to exploit both agent and ty pe ind ependen ce in the CGB G stage games. T o determine th e limits of its scalability with respect to the num ber of agents, we co nducted additional experiments applying F AC T O R E D F S P C with the Q MDP TP heuristic to S E QU E N T I A L F I R E F I G H T I N G with many more agents. The resu lts, shown in Fig. 2 0, do not include a fixed a ction baseline because 1) p erformin g simulations of all considered fixed action joint policies becomes expensi ve for many agen ts, and 2) the number of such joint policies grows exponentially with the number of agents. As shown in Fig. 20(a), F AC T O R E D F S P C successfully comp uted solu tions for up to 1 000 agen ts for h = 2 , 3 and 750 agents for h = 4. For h = 5 , it comp uted solu tions for up to 300 agen ts; even f or h = 6 it com puted solutions for 100 agen ts, as shown in Fig. 20(b). Note that, fo r the comp uted en tries for h = 6, the expected value is roughly equal to h = 5. This implies that the proba bility of any fire remaining at stage t = 5 is close to zero, a pattern we also observed for the optimal solution in Fig. 17. As such, we expect that the foun d solutions for these settings with many agents are in fact close to optimal. The r untime results, shown in Fig. 20 (c), 36 -2000 -1500 -1000 -500 0 10 50 100 200 300 400 500 750 1000 ff QMDP h=2 Random, h=2 ff QMDP h=3 Random, h=3 ff QMDP h=4 Random, h=4 P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n Number of agents I s l a n d c o n fi g u r a t i o n (a) E xpecte d v alue for h = 2 , . . . , 4. -300 -250 -200 -150 -100 -50 0 10 20 30 40 50 75 100 150 ff QMDP h=5 Random, h=5 ff QMDP h=6 Random, h=6 P S f r a g r e p l a c e m e n t s V alue t i m e ( s ) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n Number of agents I s l a n d c o n fi g u r a t i o n (b) Expe cted va lue for h = 5 , 6. 10 -2 10 -1 10 0 10 1 10 2 10 50 100 200 300 400 500 750 1000 ff QMDP h=2 ff QMDP h=3 ff QMDP h=4 ff QMDP h=5 ff QMDP h=6 P S f r a g r e p l a c e m e n t s V a l u e time (s) g e n e r a l i z e d M A A ∗ T i m e ( s ) H o r i z o n Number of agents I s l a n d c o n fi g u r a t i o n (c) Runtime for h = 2 , . . . , 6. Figure 20: F A C T O R E D F S P C results on S E Q U E N T I A L F I R E F I G H T I N G with many agents. 37 increase linearly with resp ect to the n umber of agents. While the runtime incr eases with the nu mber of agents, the bottleneck in our experiments preventing e ven furthe r scalability was insufficient memory , not computation time. These results are a large improvement in the state of the art with respect to s calab ility in the numb er of agents. Previous ap proach es for g eneral Dec -POMDPs scaled only to 3 (Oliehoek et al., 2 008c) or 5 agents (Oliehoek et al., 2008a). 18 Even when makin g mu ch stricter assumption s such as transition an d observ ation indepen dence, previous approaches h av e not scaled b eyond 15 agents ( V a rakantha m et al., 2007; Mareck i et al., 2008; V a rakantha m et al., 2009; Kumar and Zilberstein, 2009). Thoug h these experimen ts ev alu ate only the c omplete F AC T O R E D F S P C meth od, in (Oliehoek, 20 10) we have empirically e valuated e ach of its compo nent approximatio ns separately . For the sak e of brevity , we do not present those experiments in this article. However , the results confirm that each approximation is re asonable. In particular, they show that 1) approximate inference has no s ign ificant i n fluence on p erform ance, 2) M A X - P L U S solves CGBGs as well as o r better th an alternating maxim ization, 3) th e use o f 1-step back -projecte d scopes (i.e., scopes grown by one projection b ack in the DBN) can sometim es slightly o utperfo rm the use of im mediate rew ard scopes, 4 ) th ere is n ot a large perf ormanc e dif feren ce when using op timal scopes, and 5) d epend ing on the heuristic, allowing backtracking can improve perfor mance. 5 Related W ork The wid e r ange o f resear ch related to the work presented in this article can be mined for various alterna ti ve strategies for solving CGBGs. In this section, we briefly survey these alternati ves, which fall in to tw o cate- gories: 1 ) con verting CGBGs to other type s of games, 2) converting th em to con straint optimization problems. W e also discuss the relatio n to the framew or k of action-g raph games (Jiang and Leyton-Brown , 2008). The first strategy is to con vert th e CGBG to another type of ga me. In particular, CGBGs can be con verted to CGSGs in th e same way CBGs can b e co n verted to SGs. These CGSGs can b e mo deled using inter action h yper- graphs or factor gr aphs such a s th ose shown in Fig . 2 a nd solved by a pplying NDP or M A X - P L U S . Howe ver, since this app roach doe s not exploit type indep endence, the size o f lo cal payoff function s scales expon entially in the nu mber of types, mak ing it impractical for large prob lems. In fact, this ap proach corre sponds directly to the methods, t ested in Sec. 3.5, that exploit only agent indepen dence (i.e., NDP-AI and MaxPlus-AI). The poor perfor mance of these metho ds in those e xpe riments underscores the disadv an tages of converting to CGSGs. CGBGs can a lso be c onv erted to non-collab orative graphical SGs, for which a host of solution a lgorithms have recently em erged (V ickrey and K oller, 200 2; Or tiz and K ear ns, 2 003; Daskalakis and Papadimitrio u , 2006). Howe ver , to do so, the CGBG must first be con verted to a CGSG, again f orgoing the ch ance to exploit ty pe indepen dence. Furth ermore, in the resulting CGSG, all the pay off functio ns in which a gi ven age nt partici- pates must then be combined into an individual payoff fu nction. This process, which corresponds to con verting from an edge-based decom position to an agen t-based o ne, re sults in the worst case in yet an other expon ential increase in the size of the payoff function (K ok an d Vlassis, 2006). Another option is to convert the CGBG into a no n-collabo rative graph ical BG (Singh et al., 2004) by com - bining the local p ayoff function s into in dividual payoff function s directly at the level of the Bayesian game. Again, this ma y lead to an exp onential increase in the size of th e pa yoff function s. Each BNE in the r esulting graphica l BG co rrespon ds to a local op timum of the original CGBG. So ni et al. (2007) recently prop osed a solution me thod for gr aphical BGs, which can then be applied to find locally op timal solutions. Howev er, this method con verts the graphical BG into a CGSG and t h us suf fers an exponential b low-up in the size of the payoff function s, just like the other con version approaches. 18 Ho weve r, in ver y recent work, W u et al. (2010) present results for up to 20 agents on general Dec-POMDPs. 38 The secon d strategy is to ca st the problem o f maximization over the CGBG’ s factor gr aph in to a (dis- tributed) c onstraint o ptimization pr oblem ((D) COP) (Mod i et al., 2 005). As su ch, any algo rithm, exact or approx imate, for (D)COPs can be used to find a solution f or th e CGBG (Liu and Sycara, 1995; Y okoo, 20 01; Modi et al., 2 005; Pearce and T ambe, 20 07; Marine scu and Dechter, 20 09). Oliehoek et al. (2010) prop ose a heuristic searc h a lgorithm fo r CBGs that uses this approach a nd exploits type indep endenc e (additivity o f th e value f unction) at the lev el of joint types. Kumar and Zilberstein (20 10) employ state-of-the-a rt m ethods for weighted constraint satisfaction pro blems to instances of CBGs in the context o f solving Dec-POMDPs. The Dec-POMDPs are solved backwards using dynamic programmin g, resulting in CBGs with fe w types but many actions. This approach e xp loits ty pe independence but has been tested only as part of a Dec- POMDP solu- tion meth od. T hus, ou r r esults in Sec. 4.4 pr ovide additio nal co nfirmation o f the a dvantage of exp loiting typ e indepen dence in Dec-POMDPs, while ou r results in Sec . 3.5 isolate an d qu antify this advantage in individual CGBGs. Furthermo re, the appro ach presented in this article differs f rom both these alternatives in that it makes the use of type independ ence explicit and simultaneously exploits agent indepen dence as well. Finally , ou r work is also related to the framework of action -graph g ames (A GGs), whic h was recently extended to hand le imperfect inf ormation and can model any BG (Jiang and Leyton -Brown , 2010). Th is work propo ses two solu tion meth ods for general- sum Bay esian A GGs (BA GGs): the Govindan-W ilson algorithm and simplicial subdivision. Both in volve computatio n o f t h e expected payoff of each agent gi ven a current pr ofile as a key step in an inner lo op of th e algorithm. Jiang and Leyton- Brown (20 10) show how this expected pay off ca n be co mputed efficiently for each (ag ent, typ e)-pair, thereby exploiting type (and possibly ag ent) inde penden ce in this inn er loop . As s u ch, this appr oach m ay c ompute a sample Nash equ ilibrium m ore ef ficiently than witho ut using this structure. On the on e hand, B A GGs are more general than CGBGs since the y additionally allo w representation of context-specific indepen dence and anonymity . Further more, the s o lution method is more general s ince it works for g eneral-sum g ames. On the other hand, in th e co ntext of collab orative games, a sample Nash equilibrium is not guar anteed to be a PONE ( but only a local optimum). In co ntrast, we solve for the g lobal optimum and thus a PONE. In addition, their ap proach does no t exploit the synergy that independ ence brings in the identical payoff setting . In contrast, NDP an d M A X - P L U S , by o perating directly on the factor graph, explo it indepen dence not just within an in ner loop b ut throug hout the compu tation of the solutio n. Finally , note that ou r algorithm s also work for co llaborative B A GGs that po ssess the same form of stru cture as CGBGs (i.e. , ag ent and typ e indepe ndence) . In c ases wh ere there is n o anon imity or context-specific indepen dence (e.g., as in the CGBGs generate d for Dec-POMDPs), the B AGG framework offers no adv antag es. 6 Futur e W ork The work p resented in this article op ens several intere sting avenues for future work. A straightforward extension of our method s would replace M A X - P L U S with more recent message passing algorithms for belief propagation that are g uaranteed to co n verge (Globe rson and Jaakkola, 2008). Since these algorith ms ar e guar anteed to compute the exact MAP configuration for perfect graphs with binary variables (Jeb ara, 2009), th e resulting approa ch would be able to efficiently compu te o ptimal solutions f or CGBGs with two a ctions and perfect interaction graph s. Another avenue would be to inv estigate whe ther ou r algo rithms can b e extend ed to work on a br oader class of collaborative Bayesian A GGs. Doing so could enab le our approach to also exploit context-specific indepen dence and anonymity . A com plementary idea is to extend ou r algor ithms to the non -collabor ativ e case by re phrasing the task of finding a sample Nash equilibriu m as o ne of minimizin g regret, as sugg ested by V ickrey and K oller (2 002). Our ap proach to solving Dec-POMDPs w ith CGBGs co uld b e in tegrated with metho ds for clustering h is- tories (Em ery-Mon temerlo et al., 2 005; Olieho ek et al., 2 009) to allow scaling to larger hor izons. In add ition, 39 there is great potential for further improvement in the accuracy and ef ficiency of computing approximate v alue function s. In particu lar , the transfer planning approach could be extended to transfer tasks with different action and/or ob servation spac es, as d one in tr ansfer learnin g (T aylor et al., 20 07). Fu rthermo re, it m ay be possi- ble to automatically id entify suitable source tasks and mappings b etween tasks, e.g., u sing qu alitativ e DBNs (Liu and Stone, 2006). 7 Conclusions In this article, we con sidered the intera ction of several agents und er uncer tainty . In par ticular, we fo cused on settings in which mu ltiple collabor ativ e agen ts, each possessing some pr iv ate infor mation, must coo rdinate their action s. Such settings can be form alized by the Bayesian g ame fram ew ork . W e pre sented an overview of game-theo retic models used for collaborative decision making and delineated two d ifferent ty pes of structure in collaborative games: 1) agent independen ce, and 2) type independen ce. Subsequen tly , we pro posed the collab orative graphical Bayesian ga me (CGBG) as a model tha t facilitates more ef ficient decision making by decomposing the global payoff function as the sum of local payoff functions that depend on only a fe w agents. W e showed ho w CGB Gs c an be represented as factor grap hs (FGs) that capture bo th agen t and type in depend ence. Since a m aximizing c onfigur ation of the factor g raph cor respond s to a solution of the CGBG, this representation also makes it possible to ef fectively exploit this independence. W e con sidered two solution meth ods: n on-serial dyna mic pro grammin g (NDP) and M A X - P L U S message passing. The former has a comp utational com plexity that is expon ential in the indu ced tree wid th of the FG, which we proved to b e exponential in the number of individual ty pes. The latter is tractable when there is enoug h inde penden ce between agents; we showed that it is exponential only in k , the maximum number of agents that pa rticipate in the same local pay off function. An em pirical ev aluation showed tha t exploiting both agent an d type agen t in depend ence can lead to a large pe rforma nce increa se, co mpared to explo iting just one form of ind epende nce, without sacrificing so lution q uality . For example, the experiments showed that this approa ch allows for th e solution of co ordinatio n prob lems with imper fect information f or up to 75 0 agents, limited only by a 1GB memory constraint. W e also showed that CGBGs an d their solution m ethods provid e a key missing compon ent in the approx- imate solutio n of Dec-POMDPs with m any a gents. I n particular, we propo sed F AC T O R E D F S P C , wh ich ap- proxim ately so lves Dec-POMDPs by representing them as a series of CGBGs. T o estimate the payoff functions of these CGBGs, we com puted approximate factored v alue fu nctions given predeterm ined scope structures via a metho d we call transfer plan ning . It uses value f unctions f or smaller sou rce pro blems as com ponents of the factored Q-v alue func tion for the or iginal target problem. An empir ical evaluation showed that F AC T O R E D F S P C significantly outper forms state-of-the-art methods for solving Dec-POMDPs with more than two agents and scales well with respect to the num ber of agents. In p articular, F AC T O R E D F S P C foun d (near-)optimal solutions on prob lem i n stances for which the optimum can be compu ted. For larger problem instances it found solutions as good as or b etter than compar ison Dec-POMDP m ethods in almost all cases an d in all cases out- perfor med the baselines. Th e most salient result fr om our experimen tal e valuation is that the propo sed method is able to compute solutions for problems that cannot be tackled by any other methods at all (not e ven the base- lines). In particular, it found good solu tions for up to 10 00 agents, wh ere previously only prob lems with small to moderate number s of agents (up to 20) had been tackled. Ackno wledgements W e would like to thank Nikos Vlassis fo r extensive discussions on the top ic, an d Kevin Leyton-Brown, Da vid Silver and Leslie Kaelbling for their v alua ble input. This research w as partly perform ed u nder the Interac- 40 ti ve Collab orative Information System s ( ICIS) pro ject, su pported by the Dutch Ministry of Economic Affairs, grant nr: BSIK030 24. T he resear ch is supported in p art by AFOSR MURI project #F A9550-09 -1-05 38. This work was partly fund ed by Fun dac ¸ ˜ ao p ara a Ci ˆ encia e a T ecnologia (ISR/IST pluriannu al funding) through the PIDD AC Program funds and was supported by project PTDC/EEA-A CR/73266/2 006. 8 A ppendix Lemma 8.1 (Complexity of M A X - P L U S ) . The comp lexity of one iter atio n of M A X - P L U S is O m k · k 2 · l · F , (8.1) wher e, F is the n umber of factors, th e maximum degr ee of a facto r is k , the maximum degr ee of a va riable is l , the maximum number of values a variable can take is m. Pr oof. W e can directly derive that the number of edges is bounded by e = F · k . Messages sent by a v ariab le are constructed by summ ing over incomin g messages. A s a variable has at most l neighbo rs, this inv olves addin g at most l − 1 inco ming messages of size m . Th e cost of constructing one message for on e variable therefor e is: O ( m · ( l − 1 )) . This mean s tha t the total cost of constructing all e = O ( F · k ) messages sent by variables, one over each edge, is O ( m · ( l − 1 ) · F · k ) (8.2) Now we consid er the m essages sen t by factors. Reca ll that the max imum size of a factor is m k . The construction of each message entails factor -m essage addition (see, e.g., Oliehoek (2010), Sec. 5.5.3) with k − 1 incoming messages, each one has cost O ( m k ) . This leads to a cost of O (( k − 1 ) · m k ) = O ( k · m k ) per factor message, and a total cost of O ( F · k 2 · m k ) . (8.3) The complexity of a single iter ation of M A X - P L U S is the sum of (8. 2) and (8.3), which can b e redu ced to (8.1). Refer ences S. Arnbor g, D. Corneil, and A. Prosku rowski. Complexity of finding embeddings in a k-tree. SIAM J ournal of Algeb raic and Discr ete Methods , 8(2):277–284, 1987. R. Becker , S. Zilberstein, V . L esser , and C. V . Goldman. Solving transition independent decentralized Mark ov decision processes. Journal of Artificial Intelligenc e Resear ch , 22:423 –455, December 2004. D. S . Bernstein, R. Gi van, N. Immerman, and S. Zilberstein. The comp lexity of decentralized control of Marko v decision processes. Mathematics of Operations Resear ch , 27(4):819–84 0, 2002. U. Bertele and F . Brioschi. Nonserial Dynamic Pr ogr amming . Academic Press, Inc., 1972 . U. Bertel ` e and F . Bri oschi. On no n-serial dynamic programming. Journ al of Combinatorial Theory , Series A , 14(2):137 – 148, 1973. C. M. Bishop. P attern Reco gnition an d Mac hine Learning . Springer-V erlag New Y ork, Inc., 2006. 41 P .-T . de Boer, D. P . Kroese, S. Mannor , and R. Y . Rubinstein. A tu torial on the cross-en tropy method. Annals of Op erations Resear ch , 134(1):19–67 , 2005. C. Bo utili er . Planning, learning and coordination in multiagent decision processes. In Pr oc. of the 6th Confer ence on Theor etical Aspects of Rationality and Knowledge , pages 195–21 0, 1996. C. Bo utili er , T . Dean, and S. Hanks. Decision-th eoretic planning: Structural assu mptions and compu tational lev erage. J ournal of A rtificial Intelligen ce Resear ch , 11:1–9 4, 1999 . X. Boyen and D. K oller . Tractab le inference for complex stochastic proc esses. In Pr oc. of Uncertainty i n Artificial Intelli- gence , pages 33–42 , 1998. L. Bus ¸ oniu, R. Babuˇ ska, and B. De Schutter. A comprehensi ve survey of multi-agent reinforcement learning. IEEE T ransac tions on Sys tems, Man , and Cybern etics, P art C: Applications and Reviews , 38 (2):156–172, Mar . 2008. R. Cogill and S. Lall. An approx imation algorithm for the discrete team decision problem. SIAM J ournal on Contro l and Optimization , 45(4):1359–1 368, 2006. R. Cogill, M. Rotkowitz, B. V . Ro y , and S. Lall. An approximate dynamic programming approach to decen trali zed control of stochastic systems. In Proc . of the 2004 Allerton Con ferenc e on Communication, Contr ol, and Computing , 2004. C. Daskalakis and C. H. Papadimitriou. Computing pure Nash equ ili bria in grap hical games via Marko v random fields. In Pr oc. of the 7th ACM confer ence on Electr onic commer ce , pages 91–99, 2006. D. P . de F arias and B. V an Roy . The li near programming approach to approximate dynamic programming. Operations Resear ch , 51(6):850–86 5, 2003. R. Dechter . Bucket elimination: a unifying framewo rk for reasoning . Artificial Intelligence , 113 :41–85, Sept. 1999. R. Emery-Mon temerlo, G. Gordon, J. Schneider , and S. Thrun. Approximate solutions for partially ob servable stochastic games wit h common payof fs. I n Proc . of the International Joint Confer ence on Autonomou s Ag ents and Multi Agent Systems , pages 136–143 , 2004. R. Emery-Montem erlo, G. Gordon, J. S chneider , and S. Thrun. Game theoretic control for robot teams. In Proc. of the IEEE International Confer ence on Robotics and Automation , pages 1175–1 181, 2005 . A. Farinelli, A. Rogers, A. Petcu, and N. R. Jennings. Decentralised coordination of low-po wer embedded de vices using the max-sum algorithm. In Pr oc. of the International J oint Confer ence on Autonomous Agents an d Multi A gent Systems , pages 639–646 , 2008. A. Gl oberson and T . Jaakkola. Fixing max-product: Con vergent message passing algorithms for map lp-relaxations. In Advances in Neural Information Pr ocessing Systems 20 , 200 8. C. Guestrin, D. Ko ller, and R. Parr . Max-norm projections for f actored MDPs. In Pr oc. of the International Joint Confer ence on Artificial Intelligence , pages 673– 680, 2001a . C. Guestrin, D. Koller , and R. Parr . Solving factored POMDPs with linear value functions. In IJCAI ’01 workshop on Planning under Uncertainty and Incomplete Information , pages 67–75, 2001b. C. Guestrin, D. Ko ll er , an d R. Parr . Multiagent planning wit h factored MDPs. In Advances in Neural Information Pro cessing Systems 14 , pages 1523–1 530, 2002. C. Guestrin, D. Koller , R. P arr, and S. V enkatarama n. Ef ficient solution algo rithms for factored MDPs. Journa l of Art ificial Intelligence Resear ch , 19:39 9–468, 2003. J. C. Harsan yi. Games with incomp lete information played by ‘Bayesian’ players, parts I, II and II. Manag ement Science , 14:159–1 82, 320–3 34, 486–50 2, 1967–1 968. 42 M. N. Huhns, editor . Distributed Artificial Intelligenc e . Pitman Publishing Ltd., 1987. T . Jebara. MAP estimation, message passing, and perfect graphs. In Proc. of Uncertainty in Art ificial Intelligence , 200 9. A. X. Jiang and K. Leyton-Brown . Acti on-graph games. T ech nical R eport TR-2008-13, Unive rsit y of British Columbia, September 2008. A. X. Jiang and K. Leyton-Bro wn. Bayesian action-graph games. In Advances in Neural I nformation Pr ocessing Systems 23 , pages 991–999 , 2010. L. P . Kaelbling, M. L. Littman, and A. R. Cassandra. Planning and acting in partially observ able stochastic domains. Artificial Intelligence , 101(1-2):99 –134, 199 8. M. J. K earns. Gr aphical games. In N. Nisan, T . Ro ughgarden, E. T ardos, and V . V azirani, editors, Algorithmic Game Theory . Cambridge Univ ersity Press, Sept. 2007. M. J. Kearns, M. L. L ittman, an d S. P . Singh. Graphical models fo r ga me t heory . In Pr oc. of Unc ertainty i n Artificial Intelligence , page s 253– 260, 2001 . Y . Kim, M. Krainin, and V . L esser . Application of max -sum algorithm to radar coo rdination and scheduling. In The 12th International W orkshop on Distributed Constr aint Reasoning , 2010. H. Kitano, S. T adok oro, I. N oda, H. Matsubara, T . T akahash i, A. S hinjoh, and S . Shimada. Robocup rescue: S earch and rescue in larg e-scale disasters as a domain for autonomous agents r esearch. In P r oc. of the International Confer ence on Systems, Man and Cybernetics , pages 739–7 43, Oct. 1999. J. R. K ok and N. Vlassis. Using the max-plus algorithm for multiagent decision making in coordination graphs. In RoboCup- 2005: Robot Soccer W orld Cup IX , Osaka, Japan , July 2005 . J. R. Ko k and N. Vlassis. Collaborativ e multi agent reinforcement learning by payoff propagation. Journa l of Machine Learning Resear ch , 7:1789– 1828, 2006. D. K oller and B. Milch. Multi-agent influen ce diagrams f or represen ti ng and solving games. Games and Economic Behav- ior , 45(1):181–22 1, Oct. 2003. D. K oller and R. Parr . Computing factored v alue functions for policies in structured MDPs. In Proc. of the International J oint Confere nce on Artificial Intellige nce , pag es 133 2–1339, 19 99. D. K oller and R. Parr . Policy it eration for f actored MDPs. In Pr oc. of Uncertainty in Artificial In tell igence , pag es 326–334, 2000. F . R. Kschischang, B. J. Frey , and H. -A. Loeliger . Factor graphs and the sum-product algorithm. IE EE Tr ansactions on Information Theory , 47(2):498–5 19, 2001. A. Kumar and S. Zilberstein. Constraint-based dyn amic programming for decentralized POMDPs with structured interac- tions. In Pr oc. of the Internationa l J oint Confer ence on Autonomous Agen ts and Multi Agent Systems , pages 561–568 , 2009. A. Kumar and S. Zilberstein. Point-based backup for decentralized POMDPs: Complexity and ne w algorithms. In Pr oc. of the International J oint Confere nce on Auton omous Agents and Multi Agent Systems , pages 1315–132 2, 2010. L. Ku yer, S. W hiteson, B. Bakker , and N. Vlassis. Multiagent reinforcemen t l earning for urban traffic con trol using coordi- nation graphs. In Proc. of t he Eur opean Confer ence on Machine Learning , pages 656–671 , 2008. J. Li u and K. P . Sycara. Exploiting problem structure for distr ibuted constraint op timizati on. I n P r oc. of the Interna tional Confer ence on Multiagent Systems , pages 246–25 3, 1995. 43 Y . L iu and P . Stone. V alue-function-based t ransfer for reinforcement learning us ing structure mapping. In Pr oc. of the National Confer ence on Artificial Intelligence , pages 415–20, 2006. H.-A. Loeliger . An introduction to factor graphs. I EEE Signal Pr ocessing Magazine , 21(1):28– 41, 2004. J. Marecki, T . Gupta, P . V arakantha m, M. T ambe , and M. Y okoo. Not all agents are equal: scaling up distributed POMDPs for agent networks. In Pr oc. of the I nternational Joint Confer ence on A utonomous Agents and Multi Ag ent S ystems , pages 485–492 , 2008. R. Marinescu and R. Dechter . An d/or branch -and-bound search for combina torial optimization in graphical models. Artifi- cial Intelligence , 173(1 6-17):1457–1491 , 2009. P . J. Modi, W . min Shen, M. T ambe, and M. Y okoo. Adop t: Asynchronous distrib uted constraint optimization with quality guarantees. Arti ficial Intelligen ce , 161 :149–180, 2005 . J. M. Mooij. Understanding and Impr oving Belief Pr opagation . PhD thesis, R adboud Uni versity Nijmegen, May 2008 a. J. M. Mooij. libDAI: library fo r discrete ap proximate inference, 200 8b. URL http://w ww.jorismooij.nl/ . K. P . Murph y . Dynamic Bayesian Networks: Repr esentation, Inferen ce and Learning . PhD thesis, UC Berkeley , Computer Science Div ision, July 2002. K. P . Murph y and Y . W eiss. The f actored frontier algorithm for approximate inference in DBNs. In Proc. of Uncertainty in Artificial Intelligence , pages 378–38 5, 200 1. R. Nair, P . V arakantham, M. T ambe, and M. Y okoo . Networke d distrib uted POMDPs: A synthesis of distributed constraint optimization and POMDPs. In Proc. o f t he National Confer ence on Artificial Intelligence , pages 133–139 , 2005. J. F . Nash. Equilibrium po ints in N-person ga mes. Proc. of the Nation al Academy of Scien ces of the United States of America , 36:48–49, 1950. F . A. Oliehoek. V alue-based Planning for T eams of Agen ts in Stoc hastic P artially Observable Envir onments . PhD thesis, Informatics Institute, Uni versity of Amsterdam, Feb. 2010. F . A. Oliehoek, J. F . K ooij, and N. Vlassis. The cross-entrop y method for po licy search in decentralized POMDPs. Infor- matica , 32:341–35 7, 2008a. F . A. Oliehoek, M. T . J. Spaan, and N. Vlassis. Optimal and approximate Q-v alue functions f or decentralized PO MDPs. J ournal of A rtificial Intelligen ce Resear ch , 32:289 –353, 2008 b. F . A. Oliehoek, M. T . J. Spaan, S. Whiteson, and N. Vlassis. Exploiting locality of interaction in factored Dec-POMDPs. In Pr oc. of the International J oint Confer ence on Autono mous Agents and Multi Agent Systems , pages 517–524, May 2008c. F . A. Oliehoek, S. Whiteson, and M. T . J. Spaan. Lossless clustering of histories in decentralized POMDPs. In Pr oc. of the International J oint Confere nce on Auton omous Agents and Multi Agent Systems , pages 577–584 , May 2009. F . A. Oliehoek, M. T . J. S paan, J. S. Di bango ye, and C . Amato. Heuristic search for identical payof f Bayesian games. In Pr oc. of the International J oint C onfer ence on Autonomous A gents and Multi Agent Systems , p ages 1115–1122, May 2010. F . A. Oliehoek, S. Whiteson, and M. T . J. Spaan. Exploiting structure in cooperativ e Baye sian games. In Pr oc. of Uncertainty in Artificial Intelligence , pages 654 –664, Aug. 2012 . F . A. Oliehoek, S. Whiteson, and M. T . J. Spaan. Approximate solutions for factored Dec-POMDPs with man y agents. In Pr oc. of the International Jo int C onfer ence on Autonomous Agents an d Multi Agen t Sy stems , pag es 563 –570, 2013. 44 L. E. Ortiz and M. Kearns. Nash propagation for loopy graphical games. In Advances in Neural Information Pr ocessing Systems 15 , pages 793–80 0, 2003. M. J. Osborne and A. Rubinstein. A C ourse in Game Theo ry . The MIT Press, July 1994. L. P anait and S. Luk e. Cooperati ve multi-agent learning: The state of the art. Autonomous Ag ents and M ulti-A gent Systems , 11(3):387–4 34, 2005. J. P . Pearce and M. T ambe. Quality guarantees on k-optimal solutions for distri buted constraint optimization prob lems. In Pr oc. of the International Jo int C onfer ence on Artificial Intelli genc e , pages 14 46–1451, 2007. J. Pearl. P r obabilistic Reasoning In Intelligent Systems: Networks of Plausible Infer ence . Mor gan Kaufmann, 1988. D. V . Pynadath and M. T ambe. T he communicativ e multiagent team decision problem: An alyzing teamwork theories and models. Journ al of Artificial Intelligence Resear ch , 16:38 9–423, 20 02. Z. Rabino vich, C. V . Goldman, and J. S. Rosensc hein. The c omplexity of multiagent systems: the price of silence. In Pr oc. of the International Jo int Conferen ce on Auton omous A gents an d Multi Ag ent Systems , pa ges 1102–1103, 2003. D. Schuurman s and R. Patrascu. Direct v alue-approximation for factored MDPs. In Advances in Neu ral Information Pr ocessing Systems 14 , pages 1579–1586 . MIT Press, 2002. P . J. Schweitzer and A. Seidman. Generalized polynomial approximations in Mark ovian decision processes. J ournal of Mathematical Analysis and Applications , 110:568–5 82, 1985. S. Seuken and S. Zilberstein. Memory-bounded dynamic programming for DEC-P OMDPs. In Proc. of the International J oint Confere nce on Artificial Intellige nce , pag es 200 9–2015, 20 07. S. Singh, V . Soni, an d M. W ellman. Computing approximate Bayes-Nash equilibria in tree-games of incomplete i nforma- tion. In P r oc. of the 5th ACM confer ence on Electr onic commer ce , pages 81–90, 2004. V . Soni, S . Singh, and M. W ellman. Constraint satisfaction algorithms for graphical games. In Pr oc. of the International J oint Confere nce on Auton omous Agents and Multi Agent Systems , pages 423–4 30. A CM Press, 2007. M. T . J. Spaan and F . A. Oliehoek. The MultiAgent Decision Process toolbox: software for decision-theoretic planning in multiagent systems. In P r oc. of th e AA MAS W orkshop o n Mu lt i-Agent Sequential Decision Making in Unce rtain Domain s (MSDM) , pages 107–121 , 2008. M. T . J. Spaan, F . A. Oliehoek , and C. Amato. Scaling up optimal heuristic search in Dec-POMDPs via incremental expan sion. In Pr oc. of the International Jo int Confer ence on Artificial Intelligence , 201 1. (to appear). K. P . Sycara. Multiagent systems. AI Ma gazine , 19(2):79–92, 1998. I. Szita and A. L ¨ orin cz. Factored v alue iteration con verg es. Acta Cybernetica , 18(4):615–6 35, 2008. M. E. T aylor , P . Stone, an d Y . Liu. Tran sfer learning via i nter-task mappings for temporal dif ference learning. Journ al of Mach ine Learning Resear ch , 8(1):21 25–2167, 200 7. J. Tsitsiklis and M. Athans. On the c omplexity of decentralized d ecision m aking and de tection pro blems. IEEE Tr ansactions on Automatic Contr ol , 30 (5):440–446, 1985 . P . V arakantham, J. Mareck i, Y . Y abu, M. T ambe, and M. Y okoo . Letting loo se a SPIDER on a network of POMDP s: Generating quality guaranteed policies. In Pr oc. of the International J oint Con ferenc e on Autono mous Ag ents and Multi Agent Systems , 2007 . P . V arakantham, J. young Kwak, M. T aylo r, J. Marecki, P . Scerri, and M. T ambe. Exploiting coordination locales in distributed POMDPs via social model shaping. In Pr oc. of the International Confer ence on Automated Planning and Sched uling , 200 9. 45 D. Vick rey and D. Koller . Multi-agent al gorithms for solving graphical games. In Pr oc. of the National Conferen ce on Artificial Intelligence , pages 345–35 1, 200 2. N. Vl assis. A Concise Intr oduction to Multiagent Systems and Distributed Artificial I ntelligence . Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Clayp ool Publishers, 2007. M. W ainwright, T . Jaakkola, and A. Willsky . T ree c onsistency and bou nds on the performa nce of the max -product algorithm and its generalizations. Statisti cs and Computing , 14(2):143– 166, 2004. S. J. W itwicki and E. H. Du rfee. Influence-based policy abstraction for weakly-coupled Dec-POMDPs. In Pr oc. of the International Confer ence on Automated Planning and Sc heduling , page s 185–192, May 201 0. F . W u, S. Zilberstein, and X. Chen . Rollout sampling policy it eration for decentralized POMDPs. In Proc . of Uncertainty in Artificial Intelligence , 2010. F . W u, S. Zilberstein, and X. Chen. Online planning for multi-agent systems with bounded communication. Artificial Intelligence , 175 (2):487–511, 2011 . M. Y oko o. Distributed c onstraint satisfaction: founda tions of coop eration in mult i-ag ent systems . Springer -V erlag, 2001. 46
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment