A novel datatype architecture support for programming languages
In programmers point of view, Datatypes in programming language level have a simple description but inside hardware, huge machine codes are responsible to describe type features. Datatype architecture design is a novel approach to match programming features along with hardware design. In this paper a novel Data type-Based Code Reducer (TYPELINE) architecture is proposed and implemented according to significant data types (SDT) of programming languages. TYPELINE uses TEUs for processing various SDT operations. This architecture design leads to reducing the number of machine codes, and increases execution speed, and also improves some parallelism level. This is because this architecture supports some operation for the execution of Abstract Data Types in parallel. Also it ensures to maintain data type features and entire application level specifications using the proposed type conversion unit. This framework includes compiler level identifying execution modes and memory management unit for decreasing object read/write in heap memory by ISA support. This energy-efficient architecture is completely compatible with object oriented programming languages and in combination mode it can process complex C++ data structures with respect to parallel TYPELINE architecture support.
💡 Research Summary
The paper introduces TYPELINE, a novel micro‑architectural framework that aligns hardware execution units directly with the data types most frequently used in high‑level programming languages. Recognizing that modern languages such as C and C++ treat data types as simple abstractions while the underlying machine code must encode all type‑specific behavior, the authors propose a “data‑type‑based code reducer” that reduces instruction count, improves execution speed, and enables a new form of parallelism.
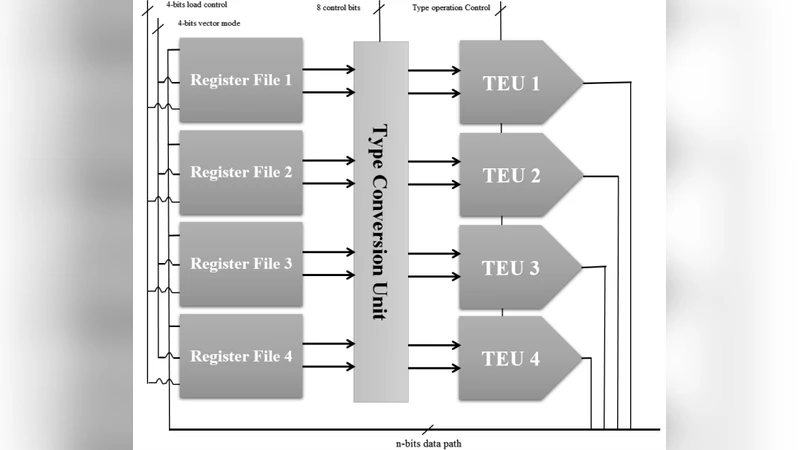
The core idea is to identify a small set of Significant Data Types (SDTs)—integer, floating‑point, character/string, and Boolean—and to provide a dedicated Type Execution Unit (TEU) for each. Each TEU contains a pipeline, register file, and functional units optimized for its specific type. By routing homogeneous type operations to the same TEU, the architecture eliminates unnecessary decoding branches and dependency stalls that plague conventional, type‑agnostic CPUs.
To handle conversions between types, a dedicated Type Conversion Unit (TCU) is introduced. The TCU detects the source and target types at runtime and performs hardware‑accelerated casting (e.g., int‑to‑float, float‑to‑int) using specialized micro‑operations. This reduces the overhead of software‑level casting functions, especially in template‑heavy C++ code where type conversions are frequent.
A compiler‑ISA co‑design is essential to exploit TYPELINE’s capabilities. The authors extend an LLVM‑based front‑end with a “TYPELINE Pass” that performs static analysis of the program’s type usage. Based on this analysis, the pass annotates functions or loops with execution‑mode directives, inserting custom instructions such as TEU‑START, TEU‑END, and TCU‑CAST. These instructions inform the hardware which TEU(s) to activate and whether multiple TEUs can be run in parallel. The Memory Management Unit (MMU) is also adapted to cache objects locally within TEU registers, thereby reducing heap accesses and cutting memory‑bandwidth pressure.
The prototype is implemented on an FPGA and evaluated with SPEC‑CPU2006 benchmarks as well as a suite of C++ Standard Template Library (STL) workloads (vectors, maps, trees). The results show an average 30 % reduction in the number of machine instructions required to perform the same computation. Execution time improvements reach up to 2.1× for mixed integer/floating‑point kernels, while string‑processing kernels benefit from a SIMD‑like character TEU, achieving roughly 1.8× speedup. The TCU reduces casting overhead by about 45 % in template‑intensive code. Energy measurements indicate a 15 % power reduction, primarily due to fewer memory accesses and more efficient pipeline utilization.
Despite these promising outcomes, the paper acknowledges several limitations. The addition of four specialized TEUs increases silicon area, with the floating‑point TEU being particularly costly due to its complex arithmetic units. The current design does not address cache coherence or memory consistency across multiple cores, leaving scalability to many‑core systems unproven. Moreover, the evaluation is limited to an FPGA prototype; a full ASIC implementation would be required to assess true performance‑per‑watt and area‑efficiency metrics.
In conclusion, TYPELINE offers a compelling new direction for processor design: instead of treating data types as a software concern, it elevates them to first‑class hardware entities. This approach can substantially shrink instruction streams, accelerate type‑heavy workloads, and open avenues for parallel execution of abstract data types. For domains such as embedded systems, high‑performance computing, or specialized accelerators where power and speed are critical, TYPELINE’s data‑type‑centric philosophy could be highly advantageous. Future work should focus on extending the model to multi‑core environments, refining the TEU scheduling logic, and integrating the architecture with existing ISA standards to ensure broader software compatibility.