Improving adaptation of ubiquitous recommander systems by using reinforcement learning and collaborative filtering
The wide development of mobile applications provides a considerable amount of data of all types (images, texts, sounds, videos, etc.). Thus, two main issues have to be considered: assist users in finding information and reduce search and navigation time. In this sense, context-based recommender systems (CBRS) propose the user the adequate information depending on her/his situation. Our work consists in applying machine learning techniques and reasoning process in order to bring a solution to some of the problems concerning the acceptance of recommender systems by users, namely avoiding the intervention of experts, reducing cold start problem, speeding learning process and adapting to the user’s interest. To achieve this goal, we propose a fundamental modification in terms of how we model the learning of the CBRS. Inspired by models of human reasoning developed in robotic, we combine reinforcement learning and case-based reasoning to define a contextual recommendation process based on different context dimensions (cognitive, social, temporal, geographic). This paper describes an ongoing work on the implementation of a CBRS based on a hybrid Q-learning (HyQL) algorithm which combines Q-learning, collaborative filtering and case-based reasoning techniques. It also presents preliminary results by comparing HyQL and the standard Q-Learning w.r.t. solving the cold start problem.
💡 Research Summary
**
The paper addresses several persistent challenges in context‑aware recommender systems (CBRS) for mobile environments: reliance on expert‑defined profiles, the cold‑start problem, slow adaptation to user interests, and the need for rapid learning. To tackle these issues simultaneously, the authors propose a hybrid reinforcement‑learning algorithm named HyQL, which integrates Q‑learning, collaborative filtering (CF), and case‑based reasoning (CBR).
In the proposed framework, a user’s situation—characterized by four contextual dimensions (cognitive, temporal, geographic, and social)—is treated as the state s in a Markov decision process. Possible recommendations constitute the action set A. Traditional Q‑learning updates the action‑value function Q(s,a) using the Bellman equation, balancing exploration and exploitation via an ε‑greedy policy. HyQL modifies the exploration component: instead of selecting a completely random action, it selects an action derived from the preferences of the user’s social group, as computed by a hybrid CF module (memory‑based filling of missing ratings followed by item‑based similarity). This substitution enables the system to draw on the behavior of peers (e.g., teammates) even when the target user has no prior interaction data, thereby mitigating the cold‑start problem without expert input.
To accelerate convergence, HyQL incorporates CBR at each learning step. The current context is compared against a case base; if a sufficiently similar case is found, its associated action is retrieved and, if necessary, adapted before being considered for execution. This reuse of past solutions reduces the number of purely exploratory steps that standard Q‑learning would otherwise require, addressing the slow learning issue.
The complete HyQL algorithm proceeds as follows: (1) initialize Q‑values arbitrarily; (2) for each episode, sense the current context to obtain state s; (3) compute similarity to stored cases and retrieve/adapt a case if applicable; (4) select an action using the modified ε‑greedy rule (Equation 2) that chooses either the CF‑derived “social‑group” action or the greedy Q‑action; (5) execute the action, observe reward r and next state s′; (6) update Q(s,a) via the standard Q‑learning update; (7) repeat until a stopping condition is met.
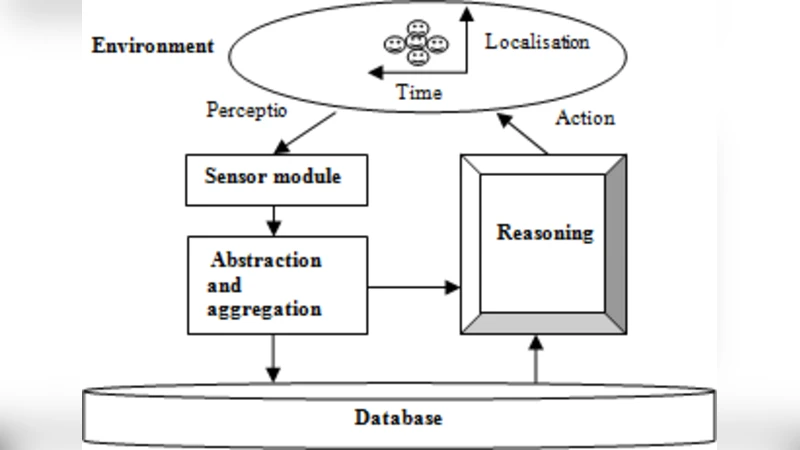
The system architecture comprises sensing modules for each contextual dimension, an inference layer that employs ontologies (OWL‑Time for temporal reasoning and a custom geographic ontology), and a reasoning module that invokes either plain Q‑learning or HyQL to decide the recommendation. All components share a unified database partitioned into user profiles, preference logs, device specifications, and interaction history (both action and event logs).
Preliminary evaluation is conducted through a simulation of two corporate teams (Paul and John) equipped with smartphones. Over 100 recommendation trials, the system must suggest one of 100 resources; a recommendation is deemed correct if the user selects the suggested resource. Precision (the proportion of correct recommendations) is measured in 10‑trial windows. Results (Figure 3) show that HyQL consistently outperforms standard Q‑learning, achieving higher precision across most intervals and only matching Q‑learning at trial 50. The improvement is attributed to the early availability of socially‑informed actions via CF and the rapid convergence facilitated by case reuse.
While the findings are promising, the authors acknowledge limitations: the experiments are confined to simulated data, the social group model is simplistic (team‑level only), and scalability concerns regarding case‑base maintenance and CF computation are not fully addressed. Future work will involve deploying the system in real mobile settings, refining social network modeling (e.g., incorporating friendship or interest graphs), and investigating online learning strategies to manage memory and computational overhead.
In summary, the HyQL approach demonstrates that a synergistic combination of reinforcement learning, collaborative filtering, and case‑based reasoning can effectively reduce cold‑start latency, eliminate the need for expert‑defined profiles, accelerate learning, and adapt to evolving user interests in context‑aware recommender systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment