Thoughts on a Recursive Classifier Graph: a Multiclass Network for Deep Object Recognition
We propose a general multi-class visual recognition model, termed the Classifier Graph, which aims to generalize and integrate ideas from many of today’s successful hierarchical recognition approaches. Our graph-based model has the advantage of enabling rich interactions between classes from different levels of interpretation and abstraction. The proposed multi-class system is efficiently learned using step by step updates. The structure consists of simple logistic linear layers with inputs from features that are automatically selected from a large pool. Each newly learned classifier becomes a potential new feature. Thus, our feature pool can consist both of initial manually designed features as well as learned classifiers from previous steps (graph nodes), each copied many times at different scales and locations. In this manner we can learn and grow both a deep, complex graph of classifiers and a rich pool of features at different levels of abstraction and interpretation. Our proposed graph of classifiers becomes a multi-class system with a recursive structure, suitable for deep detection and recognition of several classes simultaneously.
💡 Research Summary
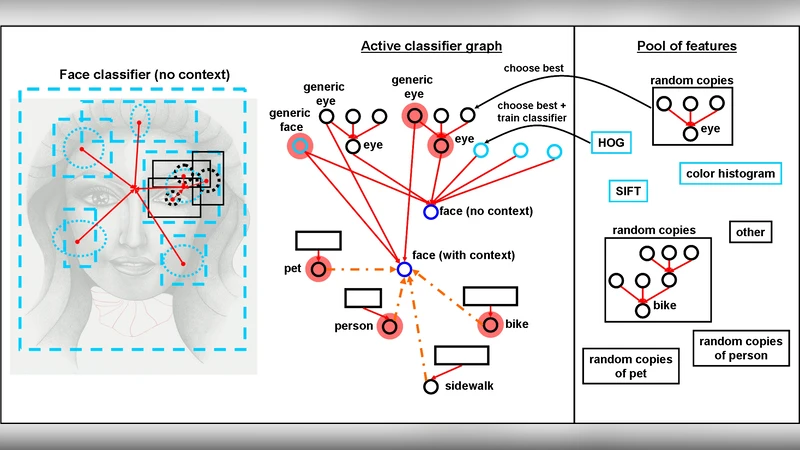
The paper introduces the “Classifier Graph,” a novel multi‑class visual recognition framework that treats every concept—low‑level features, parts, objects, attributes, or scenes—as a logistic linear classifier node within a directed graph. Each node operates as a detector defined by a specific location, scale, and search region; its output can serve as an input feature to any child node, enabling both bottom‑up and top‑down contextual influence. The system starts with a manually designed pool of low‑level descriptors (e.g., HOG, color, texture) sampled at many scales and positions. During learning, a new node is added by selecting the most informative subset of existing features (using a clustering‑based “ClusterBoost” procedure) and training a logistic regression classifier. Once trained, the node is duplicated across various scales, locations, and search windows and re‑added to the feature pool, allowing the graph to grow both deeper and wider in a step‑by‑step fashion.
A key insight is the use of multiple classifiers for the same semantic class. For instance, a “chair” may be recognized by a simple HoG‑based classifier and simultaneously by a higher‑level scene‑context classifier that incorporates outputs from many other nodes. These classifiers have different failure modes, providing robustness to missing or ambiguous cues. Moreover, classifiers can be instantiated for the same class at different spatial extents (e.g., “person in the right half of the image” vs. “person at a precise location”), mirroring max‑pooling and max‑out concepts from convolutional networks.
The graph explicitly models co‑occurrence, part‑whole, and antagonistic relationships between classes. Edges can be excitatory or inhibitory, allowing a detected “room” to boost the confidence of a “chair” and vice‑versa, or to suppress mutually exclusive categories. The authors argue that such interconnectedness mirrors human cognition, where related concepts are learned and remembered as coherent stories.
Training proceeds iteratively: after each epoch a new node is added, its parameters are learned quickly via logistic regression, and the expanded feature pool is used for the next iteration. Human intervention can be incorporated to inject new feature types or adjust clustering criteria.
The authors claim that this recursive, feature‑as‑classifier architecture overcomes limitations of traditional deep hierarchies (which often enforce a strict low‑to‑high abstraction pipeline) by allowing flexible, multi‑level interactions and by reusing learned classifiers as higher‑level features. While promising, the approach raises concerns about scalability (graph size and memory), handling of cycles (the paper enforces a feed‑forward order), and the expressive power of linear classifiers. Future work is suggested on graph pruning, incorporation of non‑linear units, and large‑scale empirical validation.
Comments & Academic Discussion
Loading comments...
Leave a Comment