Multiprocessor Scheduling of Dependent Tasks to Minimize Makespan and Reliability Cost Using NSGA-II
Algorithms developed for scheduling applications on heterogeneous multiprocessor system focus on asingle objective such as execution time, cost or total data transmission time. However, if more than oneobjective (e.g. execution cost and time, which may be in conflict) are considered, then the problem becomes more challenging. This project is proposed to develop a multiobjective scheduling algorithm using Evolutionary techniques for scheduling a set of dependent tasks on available resources in a multiprocessor environment which will minimize the makespan and reliability cost. A Non-dominated sorting Genetic Algorithm-II procedure has been developed to get the pareto- optimal solutions. NSGA-II is a Elitist Evolutionary algorithm, and it takes the initial parental solution without any changes, in all iteration to eliminate the problem of loss of some pareto-optimal solutions.NSGA-II uses crowding distance concept to create a diversity of the solutions.
💡 Research Summary
The paper addresses the problem of scheduling a set of dependent tasks on heterogeneous multiprocessor systems with the dual objectives of minimizing makespan (the completion time of the last task) and reliability cost (a measure of system failure risk during execution). The authors model the application as a Directed Acyclic Graph (DAG) G = (T, E), where each task τi has a known execution time t_i,j on processor pj and each edge e_k,l carries a data volume d_k,l that must be transferred after the predecessor finishes. The problem is static: the mapping of tasks to processors is decided before execution and does not change at run‑time.
Traditional genetic‑algorithm (GA) approaches have been applied to similar scheduling problems, but they usually optimize a single objective or, when multi‑objective, fail to preserve a diverse set of Pareto‑optimal solutions. To overcome these shortcomings, the authors employ the Non‑Dominated Sorting Genetic Algorithm II (NSGA‑II), an elitist evolutionary algorithm that uses non‑dominated sorting and crowding‑distance based diversity preservation.
The proposed NSGA‑II procedure starts by generating an initial population based on the “height” of tasks in the DAG. Tasks with the same height are grouped, and all permutations within each height group are enumerated to produce feasible schedules that respect precedence constraints. Each individual encodes a complete mapping of tasks to processors. The algorithm then iteratively creates a child population via selection, crossover, and mutation, merges it with the parent population, and performs non‑dominated sorting to obtain fronts F1, F2, … . Within each front, crowding distance is computed for each individual by normalising the distances between neighbouring solutions in each objective space; individuals with larger crowding distance are preferred to maintain spread. Elitism guarantees that the best individuals from the current generation are carried unchanged into the next generation, preventing loss of Pareto‑optimal solutions.
Crossover is performed by selecting a random height level c, locating the last task at that height on each processor, and swapping the “bottom halves” of the two parent chromosomes at that point. Mutation randomly picks a task and exchanges it with another task of the same height, thereby preserving precedence while introducing new mappings. The authors use low crossover and mutation probabilities to balance exploration and exploitation.
The two objective functions are defined as follows:
- Makespan – the maximum finish time across all processors, expressed as min max {t_i^F}.
- Reliability Cost – a sum of processor failure rates f_j multiplied by the execution time of tasks assigned to that processor, plus communication‑link failure rates g_kb weighted by the data volume transferred between dependent tasks. Formally, R_ij = f_j·X_ij·t_i(j) + Σ_{k∈pred(i)} g_kb·w_ik·X_kb, where X_ij is a binary assignment variable. Minimising R_ij maximises overall system reliability.
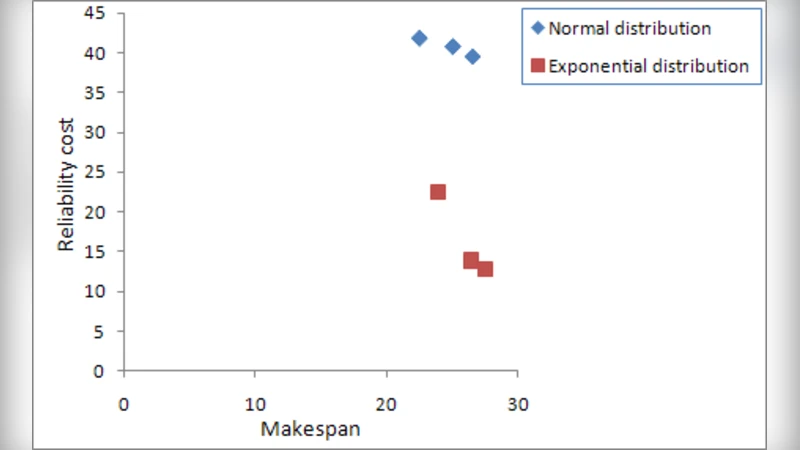
Experimental evaluation uses the P‑Method to generate random DAGs with varying edge‑probability ε (from fully sequential to highly parallel structures). For each generated graph, the authors run NSGA‑II and a conventional single‑objective GA for 100 generations, recording the obtained Pareto fronts. Results show that NSGA‑II consistently yields a broader Pareto front, achieving lower reliability costs while keeping makespan comparable to or slightly better than the baseline. The crowding‑distance mechanism is credited for maintaining solution diversity, and elitism for preserving high‑quality individuals.
The paper’s contributions are: (i) formulation of a static, dependent‑task scheduling problem with explicit reliability cost; (ii) adaptation of NSGA‑II to this domain, including a novel initialization based on task heights; (iii) demonstration of superior Pareto‑front quality compared with traditional GA.
Nevertheless, the study has limitations. The computational overhead of non‑dominated sorting and crowding‑distance calculation is not analysed, nor are the effects of population size, crossover/mutation rates, or termination criteria explored in depth. All experiments are confined to synthetic DAGs; real‑world cloud or grid workloads are not examined, leaving questions about scalability and practical applicability. Moreover, the static scheduling assumption precludes handling dynamic task arrivals or runtime failures, which are common in modern distributed systems. Future work could extend the approach to dynamic, online scheduling, incorporate fault‑tolerant mechanisms, and validate performance on real heterogeneous platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment