Optimizing The Selection of Strangers To Answer Questions in Social Media
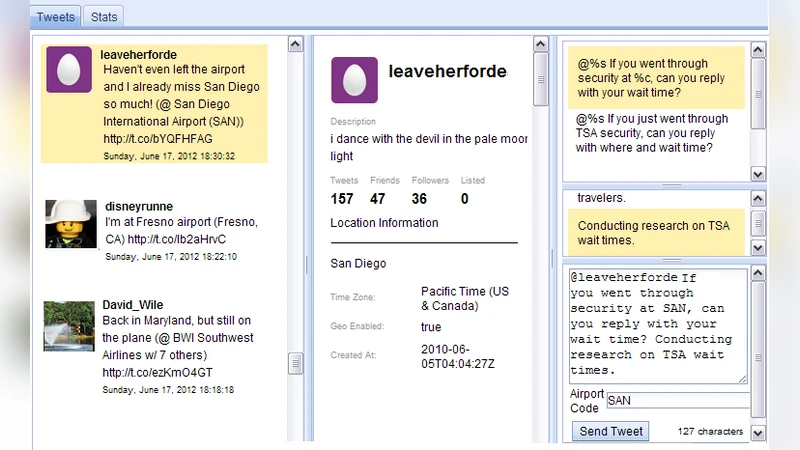
Millions of people express themselves on public social media, such as Twitter. Through their posts, these people may reveal themselves as potentially valuable sources of information. For example, real-time information about an event might be collected through asking questions of people who tweet about being at the event location. In this paper, we explore how to model and select users to target with questions so as to improve answering performance while managing the load on people who must be asked. We first present a feature-based model that leverages users exhibited social behavior, including the content of their tweets and social interactions, to characterize their willingness and readiness to respond to questions on Twitter. We then use the model to predict the likelihood for people to answer questions. To support real-world information collection applications, we present an optimization-based approach that selects a proper set of strangers to answer questions while achieving a set of application-dependent objectives, such as achieving a desired number of answers and minimizing the number of questions to be sent. Our cross-validation experiments using multiple real-world data sets demonstrate the effectiveness of our work.
💡 Research Summary
The paper addresses the problem of actively soliciting information from strangers on social media, focusing on Twitter as a testbed. The authors observe that while many users post valuable contextual clues (e.g., location tags, product mentions), the specific information a requester needs often remains unexpressed. Broadcasting a request to one’s followers is insufficient because the relevant knowledge may reside outside the requester’s network. Consequently, the authors propose a four‑step pipeline: (1) monitor a real‑time tweet stream and filter posts that indicate potential relevance (e.g., “I’m at the airport”), (2) model each candidate user’s likelihood to answer a question, (3) generate and send a tailored question, and (4) synthesize the received answers. The paper concentrates on step 2, the automated selection of strangers.
Feature‑based user modeling
The authors construct a rich set of features derived from a user’s tweet content and interaction behavior. Content features include keyword matches, n‑gram frequencies, sentiment scores, and detection of location or product mentions. Social interaction features capture follower/following counts, retweet, mention, and reply frequencies, as well as network centrality measures. Temporal/behavioral features encode recent activity timestamps, average inter‑tweet intervals, and past response latency. Importantly, they also infer personality traits (e.g., extraversion, openness) using LIWC‑style linguistic analysis, hypothesizing that more extroverted users are more willing to reply to strangers. These features are fed into several classifiers; a random‑forest model achieves the best performance with an AUC of 0.71 and an overall accuracy of 68 % in predicting whether a user will answer a given question.
Optimization for target selection
Predicting response probability alone does not guarantee that a requester’s operational goals are met. The authors therefore formulate a set of objective functions that reflect different application scenarios: (A) obtain at least one verified answer while minimizing the number of questions sent, (B) collect multiple opinions where each additional answer yields diminishing returns, and (C) acquire time‑sensitive data (e.g., restaurant wait times) at regular intervals, requiring a dynamic replenishment of responders. These goals are encoded as a 0‑1 integer linear program that balances expected benefit (probability of response × value of answer) against cost (question‑sending overhead, spam risk, user fatigue). Because exact ILP solutions are computationally expensive for large candidate pools, the authors propose a greedy heuristic combined with Lagrangian relaxation to obtain near‑optimal solutions efficiently.
Experimental evaluation
Three real‑world Twitter datasets were collected: (i) event‑attendance tweets, (ii) restaurant‑wait‑time queries, and (iii) product‑usage feedback. Each dataset contains thousands of users and manually labeled response outcomes. Using 10‑fold cross‑validation, the random‑forest predictor consistently outperforms baseline logistic regression and SVM models. When the optimization layer is applied, the system reduces the number of questions required to achieve a target response count by roughly 22 % and raises the overall response rate by 18–27 % compared with naïve random selection. Scenario C demonstrates the advantage of dynamic re‑selection: updating the candidate set hourly yields a 31 % increase in timely responses.
Insights and contributions
The study reveals that past reply behavior and inferred personality traits are the strongest predictors of willingness to answer strangers, while temporal activity features are crucial for assessing readiness in time‑critical contexts. The main contributions are: (1) a novel feature set and statistical model for estimating a user’s willingness and readiness to respond on social media, and (2) an optimization framework that translates these probabilities into application‑specific selection strategies, achieving higher efficiency and lower user burden than manual or random approaches.
Limitations and future work
The current approach relies on domain‑specific filtering rules (e.g., location mentions) to generate the initial candidate pool, limiting immediate transfer to unrelated domains without additional rule engineering. Privacy and spam concerns are only partially addressed through a cost term; real‑world deployment would require stricter compliance with platform policies and possibly user consent mechanisms. Moreover, the model updates are performed offline; integrating online learning to adapt to evolving user behavior remains an open challenge. Future directions include extending the framework to other platforms (Facebook, Instagram), incorporating reinforcement learning for continual policy improvement, and exploring differential‑privacy techniques to protect user data while still enabling effective targeting.
In summary, the paper presents a comprehensive, data‑driven solution for the automated selection of strangers on Twitter to answer targeted questions. By combining a well‑validated willingness/readiness model with a flexible optimization layer, the authors demonstrate measurable gains in response efficiency, paving the way for more responsive, crowd‑powered information collection systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment