Automatic Tracker Selection w.r.t Object Detection Performance
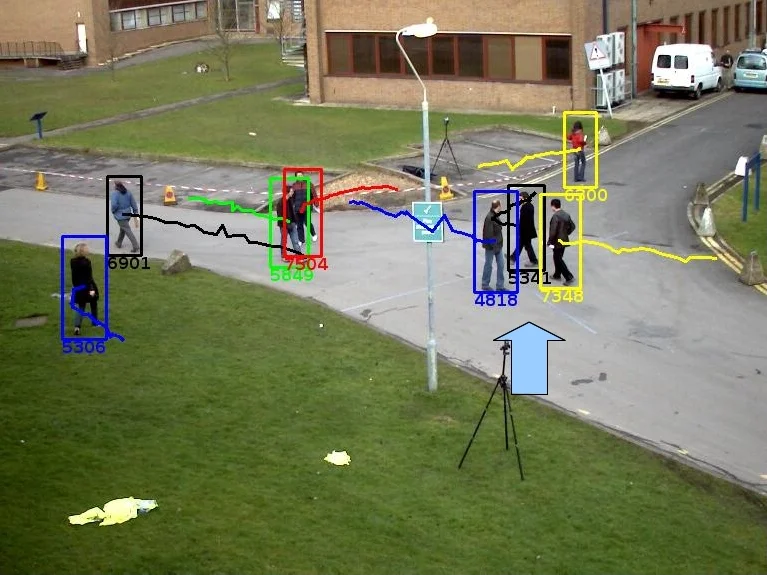
The tracking algorithm performance depends on video content. This paper presents a new multi-object tracking approach which is able to cope with video content variations. First the object detection is improved using Kanade- Lucas-Tomasi (KLT) feature tracking. Second, for each mobile object, an appropriate tracker is selected among a KLT-based tracker and a discriminative appearance-based tracker. This selection is supported by an online tracking evaluation. The approach has been experimented on three public video datasets. The experimental results show a better performance of the proposed approach compared to recent state of the art trackers.
💡 Research Summary
The paper addresses the well‑known problem that a single tracking algorithm cannot reliably handle the wide variety of video conditions encountered in multi‑object tracking (e.g., crowd density, illumination changes, occlusions, and similar‑looking neighboring objects). To overcome this limitation, the authors propose a hybrid framework that dynamically selects the most suitable tracker for each object at each frame. The system consists of three main components: (1) detection error evaluation and correction using Kanade‑Lucas‑Tomasi (KLT) feature tracking, (2) a discriminative appearance‑based tracker that exploits five complementary descriptors (2‑D shape ratio, 2‑D area, color histogram, color covariance, and dominant color) with adaptive descriptor weights, and (3) an online tracking evaluation module that decides, for every “inactive” track, whether the appearance tracker or the KLT tracker should be used to link the track to a new detection.
Detection evaluation works by labeling KLT points that belong to each detected object. If a detection at time t contains KLT points with more than one label (i.e., it overlaps several objects from t‑1), the detection is considered erroneous. The correction step splits such a bounding box into several smaller boxes, each covering a single label cluster, and rescales them using the size information from the previous frame. This process mitigates missed detections and over‑segmentation caused by occlusions.
The appearance‑based tracker computes a similarity score for each descriptor. Shape ratio and area use simple ratios; color histogram and dominant color are compared with the Earth Mover’s Distance; color covariance uses a matrix distance. To handle situations where neighboring objects have similar appearance, the authors introduce a discriminative weighting scheme. For a given object, the weight of descriptor k is proportional to the logarithm of the inverse similarity between that object and its spatial neighbors, encouraging descriptors that better separate close objects to receive higher influence. The global similarity between a detection at t and a track from t‑n is the weighted product of the five descriptor similarities, and the Hungarian algorithm solves the resulting assignment problem.
The KLT tracker follows the classic pipeline: select KLT points inside each detection, track them across frames, and define a similarity between two detections as the ratio of matched points to the minimum number of points in the two detections. This tracker excels when reliable texture exists but fails when few points are available or when points lie on background.
The core of the framework is the online tracking evaluation. For each inactive track, the system builds models of the five descriptors from the last Q observations. Assuming independence, the probability that a candidate detection belongs to a given model is computed: Gaussian PDFs for shape and area, Earth Mover’s Distance for color histograms, matrix similarity for color covariance, and averaged dominant‑color similarity. These probabilities are multiplied across descriptors, yielding a joint likelihood for each candidate. The same likelihood is computed separately for the appearance tracker and for the KLT tracker; the tracker that gives the higher likelihood is selected for that object. If both likelihoods are low, the system assumes occlusion or missed detection and temporarily suspends tracking until a new detection matches the suspended track.
A noise‑filtering step removes spurious objects generated during the detection‑splitting phase if they do not achieve a sufficient likelihood, preventing background clutter from contaminating the output.
The authors evaluate the method on three public datasets: PETS 2009, CAVIAR, and TUD, using a HOG‑based background‑subtraction detector. Quantitative results (MOTA, MOTP, ID‑switches) show consistent improvements over recent state‑of‑the‑art multi‑tracker approaches such as NCC, mean‑shift optical flow, and online random forest. Qualitatively, the system handles crowded scenes, severe illumination changes, and close‑by objects with similar appearance better than any single tracker.
In summary, the paper contributes (1) a KLT‑based detection error correction mechanism, (2) a discriminative appearance tracker with adaptive descriptor weighting, and (3) an online evaluation‑driven tracker selection strategy that jointly exploits appearance and motion cues. While effective, the approach incurs additional computational cost due to KLT point extraction and per‑object model updates, which may limit real‑time deployment on high‑resolution streams. Future work could explore lightweight feature representations or deep‑learning‑based descriptors to retain accuracy while improving efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment