Pentago is a First Player Win: Strongly Solving a Game Using Parallel In-Core Retrograde Analysis
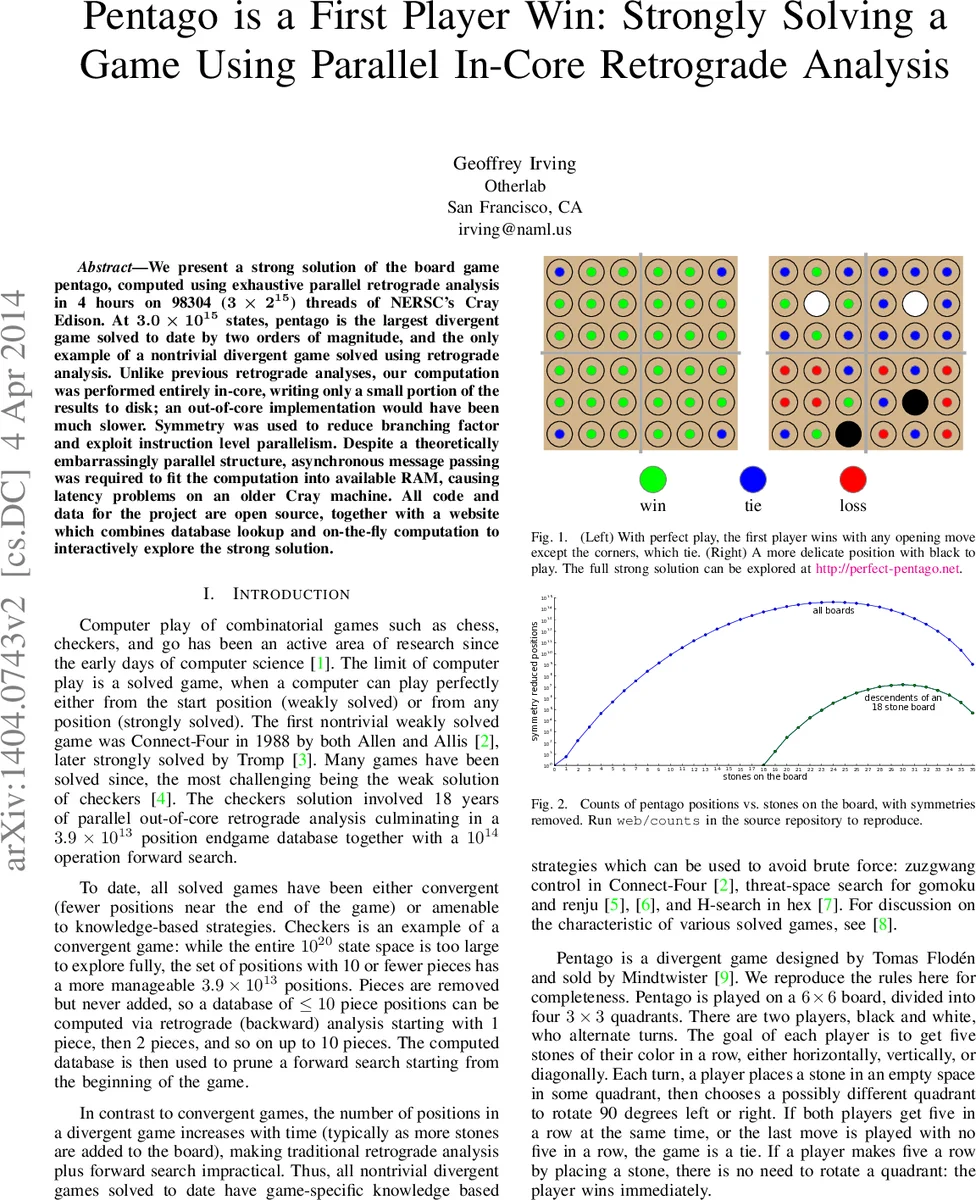
We present a strong solution of the board game pentago, computed using exhaustive parallel retrograde analysis in 4 hours on 98304 ($3 \times 2^{15}$) threads of NERSC’s Cray Edison. At $3.0 \times 10^{15}$ states, pentago is the largest divergent game solved to date by two orders of magnitude, and the only example of a nontrivial divergent game solved using retrograde analysis. Unlike previous retrograde analyses, our computation was performed entirely in-core, writing only a small portion of the results to disk; an out-of-core implementation would have been much slower. Symmetry was used to reduce branching factor and exploit instruction level parallelism. Despite a theoretically embarrassingly parallel structure, asynchronous message passing was required to fit the computation into available RAM, causing latency problems on an older Cray machine. All code and data for the project are open source, together with a website which combines database lookup and on-the-fly computation to interactively explore the strong solution.
💡 Research Summary
The paper presents a strong solution of the board game Pentago, demonstrating that the first player can force a win from any legal opening except the four corner moves, which result in a draw. The authors achieved this by performing an exhaustive parallel retrograde (backward) analysis on the NERSC Cray Edison supercomputer, employing 98 304 threads (3 × 2¹⁵) and completing the computation in roughly four hours. The state space of Pentago, after removing symmetries, contains about 3 × 10¹⁵ positions—by far the largest divergent game ever solved by retrograde analysis, exceeding the previous record (Checkers at 3.9 × 10¹³) by a factor of 77.
Key technical contributions include:
-
Rotation‑abstracted representation – Each board is treated together with all 256 possible quadrant rotations. By pre‑computing the outcome for every rotation, the factor‑8 branching caused by the mandatory rotation step is eliminated, reducing the effective average branching factor from ~97 to ~12.
-
Exploitation of symmetry – The full symmetry group of Pentago is the dihedral group D₄ (8 elements) combined with independent 90° rotations of each of the four 3×3 quadrants, forming an abelian group Z₄⁴. The authors construct the semidirect product G = Z₄⁴ ⋊ D₄ (2048 elements) and store a single “representative” board per G‑equivalence class together with a 256‑bit table mapping each local rotation to its win/loss/draw value. This reduces storage while only modestly inflating the number of effective positions (≈15 % overhead).
-
In‑core retrograde analysis – Unlike earlier large‑scale game solutions that relied heavily on out‑of‑core disk storage, the entire computation was performed in RAM. Two adjacent “stone slices” (positions with n and n + 1 stones) are kept simultaneously, requiring a peak of 213 TB before compression. The authors used fast, weak compression to fit within the 217 TB memory budget of the Cray Edison node, writing only a small final database (3.7 TB) to disk.
-
Data layout and block decomposition – Positions are grouped into “sections” defined by the number of stones of each colour in each quadrant. Each section is a four‑dimensional array; to obtain fine‑grained parallelism, the array is further divided into 8×8×8×8 blocks. A block’s value depends on up to four child sections (one per possible quadrant where a stone can be placed). The computation follows a gather‑compute‑scatter pattern: input block lines are gathered from child sections, processed (including the rmax operation that accounts for the opponent’s possible rotations), and the results are scattered back to the owning processes.
-
Asynchronous communication and deterministic pseudo‑random partitioning – Because a block may require data from several remote processes, the authors adopted a fully asynchronous message‑passing scheme: a process requests a needed block, the owner immediately replies, and the requester proceeds without waiting for other messages. To balance memory and compute load, each slice’s block lines are permuted using a deterministic pseudo‑random permutation (based on the Threefry generator and an arbitrary‑size cipher). Each process receives a contiguous chunk of this shuffled ordering, and blocks are assigned to the owner of one of their four input lines. This approach yields near‑perfect load balance without sophisticated graph partitioning tools.
-
Performance and scalability – The algorithm scales well despite the theoretically embarrassingly parallel nature of retrograde analysis, because the asynchronous communication hides latency and the random partitioning equalizes work. The total wall‑clock time of four hours includes all phases: slice generation, backward propagation, compression, and final database assembly.
The resulting database encodes the optimal outcome (win, loss, or draw) for every position with 0–18 stones (the 19‑stone slice is generated on demand). The authors have released the source code, the compressed database, and an interactive web portal (http://perfect‑pentago.net) that allows users to query optimal moves or explore the full solution tree in real time.
In summary, this work demonstrates that massive parallelism, careful exploitation of game‑specific symmetries, and a fully in‑core retrograde algorithm can solve a non‑trivial divergent game that was previously considered out of reach. It sets a new benchmark for the size of games solvable by retrograde analysis and provides a valuable open‑source framework for future research on other complex combinatorial games.
Comments & Academic Discussion
Loading comments...
Leave a Comment