The diffusion dynamics of choice: From durable goods markets to fashion first names
Goods, styles, ideologies are adopted by society through various mechanisms. In particular, adoption driven by innovation is extensively studied by marketing economics. Mathematical models are currently used to forecast the sales of innovative goods. Inspired by the theory of diffusion processes developed for marketing economics, we propose, for the first time, a predictive framework for the mechanism of fashion, which we apply to first names. Analyses of French, Dutch and US national databases validate our modelling approach for thousands of first names, covering, on average, more than 50% of the yearly incidence in each database. In these cases, it is thus possible to forecast how popular the first names will become and when they will run out of fashion. Furthermore, we uncover a clear distinction between popularity and fashion: less popular names, typically not included in studies of fashion, may be driven by fashion, as well.
💡 Research Summary
The paper introduces a novel quantitative framework for studying “fashion” in the context of first‑name choice by adapting the Bass diffusion model, a cornerstone of marketing economics used to describe the adoption of innovative durable goods. The authors argue that naming decisions share key characteristics with durable‑goods purchases: each individual (or couple) makes a small, finite number of choices in a lifetime, and the spread of a name depends on word‑of‑mouth social influence rather than mass media advertising. By setting the innovation coefficient p to zero (reflecting the negligible media effect on name choice), the Bass model reduces to the classic logistic growth equation
dN/dt = q N (1 – N/K),
where N(t) is the annual number of newborns given a particular name, q is the imitation (or “word‑of‑mouth”) coefficient, and K is the carrying capacity, i.e., the maximum number of bearers the name can ultimately reach.
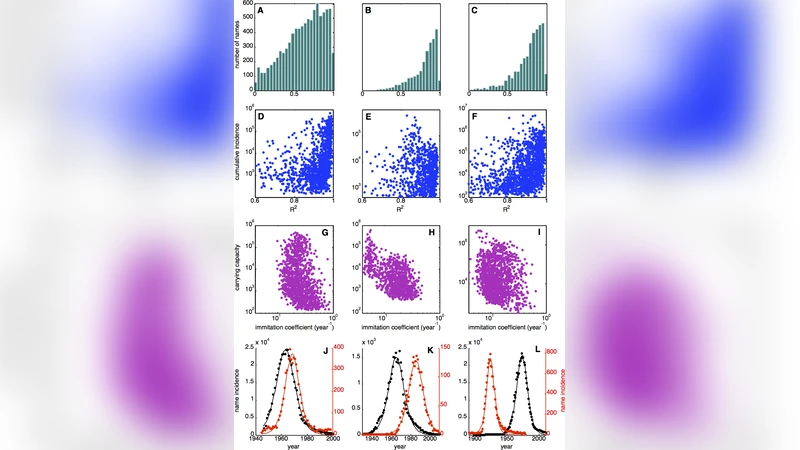
To test this parsimonious two‑parameter model, the authors assembled three large, national‑scale datasets: French name records from INSEE (1900‑2008), Dutch name records from the Nederlandse Voornamenbank (1880‑2010), and U.S. Social Security Administration name data (1880‑2011). They retained only those name time series that spanned at least 60 years, thereby ensuring sufficient temporal depth for diffusion analysis. A non‑linear least‑squares fitting routine was applied to each series, and model performance was assessed with the Nash‑Sutcliffe efficiency (R²) – the standard goodness‑of‑fit metric for nonlinear regression.
Three exclusion criteria eliminated roughly 30 % of the series: (1) failure of the fitting algorithm to converge, (2) a predicted peak lying outside the observed time window, and (3) a predicted peak width exceeding the length of the series. The remaining series displayed high R² values, with median efficiencies above 0.8 across all three countries. For a stricter “well‑fit” subset the authors required R² > 0.6 both for the full series and for a window centred on the peak; this yielded 1,193 French, 872 Dutch, and 1,410 U.S. names – roughly 9‑31 % of the original catalogs – yet these names accounted for 53‑75 % of total yearly name incidences, demonstrating that the logistic model captures the bulk of naming dynamics.
Key empirical findings include:
-
Fashion across popularity scales – Plotting R² against cumulative incidence showed that high‑fit names are not confined to the most common names; many low‑frequency names also achieve R² > 0.6, indicating that “fashion” can operate at small population levels.
-
Parameter independence – The estimated carrying capacities K span three to four orders of magnitude, whereas the imitation coefficients q are tightly clustered between 0.04 and 1.0. The lack of strong correlation suggests that the ultimate popularity of a name (K) is largely independent of the speed at which it spreads (q).
-
Predictive power – Using only pre‑2000 data for the French name “Florine,” the fitted logistic curve accurately forecasted the 2000‑2008 incidence, with observed values falling within the 95 % confidence interval of the model. This validates the model’s utility for forward‑looking predictions.
The discussion situates these results within the broader sociological literature on naming. Traditional explanations invoke class‑based emulation (upper‑class names trickle down to the middle class) or internal linguistic derivation (traditional names spawning variants). The logistic framework, however, abstracts away from such specifics and captures the essential dynamics with just two interpretable parameters: a “social contagion” strength (q) and a saturation limit (K). The authors note that the Bass model’s innovation term is unnecessary for names because media‑driven spikes are rare; instead, the diffusion is driven almost entirely by interpersonal imitation.
Limitations are acknowledged. Names that are transmitted directly from parents to children (i.e., not chosen) fall outside the model’s scope, as do cases where multiple social sub‑communities with distinct diffusion rates interact. The authors propose extending the framework to model sub‑components of names (e.g., roots, suffixes), spatial heterogeneity, and co‑evolution of multiple name clusters.
In summary, the paper demonstrates that a classic diffusion model from marketing can be successfully repurposed to describe and predict the rise and fall of first‑name popularity. By showing that the logistic model fits thousands of names across three countries, captures fashion at both high and low popularity levels, and provides reliable short‑term forecasts, the study offers a powerful, parsimonious tool for scholars of cultural evolution, demography, and marketing alike.
Comments & Academic Discussion
Loading comments...
Leave a Comment