Stochastic processes and feedback-linearisation for online identification and Bayesian adaptive control of fully-actuated mechanical systems
This work proposes a new method for simultaneous probabilistic identification and control of an observable, fully-actuated mechanical system. Identification is achieved by conditioning stochastic process priors on observations of configurations and n…
Authors: Jan-Peter Calliess, Antonis Papachristodoulou, Stephen J. Roberts
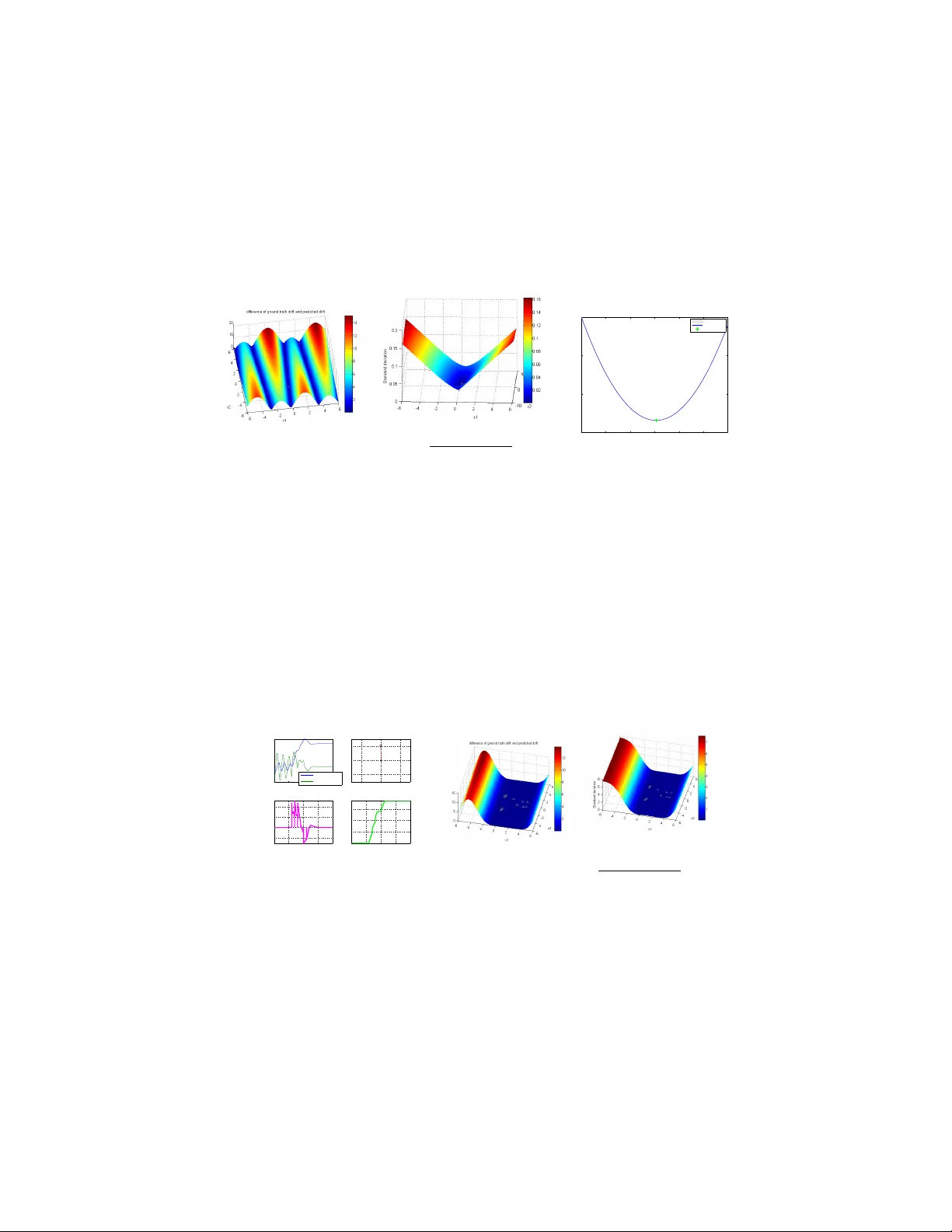
Sto c hastic pro cesses and feedbac k-linearisation for online iden tification and Ba y esian adaptiv e con trol of fully-actuated mec hanical systems Jan-P . Calliess, An tonis Papac hristodoulou and Stephen J. Rob erts Departmen t of Engineering Science, Oxford Universit y , UK Marc h 2, 2022 Abstract This w ork prop oses a new method for simultaneous proba- bilistic iden tification and control of an observ able, fully-actuated mec hanical system. Iden tification is ac hieved b y conditioning sto c hastic process priors on observ ations of configurations and noisy estimates of configuration deriv ativ es. In con trast to previous w ork that has used sto c hastic pro cesses for identi- fication, we leverage the structural knowledge afforded b y La- grangian mec hanics and learn the drift and control input ma- trix functions of the control-affine system separately . W e utilise feedbac k-linearisation to reduce, in exp ectation, the uncertain nonlinear control problem to one that is easy to regulate in a desired manner. Thereb y , our metho d combines the flexibility of nonparametric Ba yesian learning with epistemological guar- an tees on the exp ected closed-lo op tra jectory . W e illustrate our metho d in the context of torque-actuated p endula where the dynamics are learned with a combination of normal and log-normal pro cesses. 1 In tro duction Con trol may b e regarded as decision making in a dynamic environmen t. Deci- sions hav e to b e based on b eliefs ov er the consequences of actions enco ded by a mo del. Dealing with uncertain or changing dynamics is the realm of adaptive con trol. In its classical form, parametric approac hes are considered (e.g. [20] ) and, t ypically , uncertain ties are mo delled by Brownian motion (yielding sto chas- tic adaptive con trol [6, 11]) or via set-based considerations (an approach fol- lo wed b y robust adaptiv e control [15]). In contrast, w e adopt an epistemological tak e on probabilistic control and bring to bear Ba yesian nonparametric learning metho ds whose introspective qualities [7] can aide in addressing theexploration- exploitation trade-offs relative to one’s sub jective b eliefs in a principled man- 1 ner [1]. Based on these Bay esian learning metho ds, it is our am bition to dev elop adaptiv e con trollers with probabilistic guarantees (in terpreted in an epistemo- logical sense) on control success. In contrast to classical adaptive control where inference has to b e restricted to finite-dimensional parameter space, the nonparametric approach affords the learning algorithms with greater flexibility to identify and control systems with v ery few mo del assumptions. This is p ossible b ecause these metho ds grant the flexibilit y to p erform Bay esian inference o ver rich, infinite-dimensional function spaces that could encode the dynamics. This prop ert y has led to a surge of in terest in Bay esian nonparametrics; particularly benefiting their algorithmic adv ancement and application to a plethora of learning problems. Due to their fa vourable analytic prop erties, normal or Gaussian pro cesses (GPs) [2, 16] hav e b een the main choice of metho d in recent y ears. Among other domains, GPs ha ve b een applied to learning discrete-time dynamic systems in the context of mo del-predictiv e control [9, 10, 12, 17], learning the error of inv erse kinematics mo dels [13, 14], dual control [1] as well as reinforcement learning and dynamic programming [4, 5, 8, 18]. On the flip side, the extent of flexibility can lead to the temptation to use the approach in a black-box fashion, disregarding most structural knowledge of the underlying dynamics [8–10, 12, 18]. This can result in unnecessarily high- dimensional learning problems, slow con v ergence rates and often necessitates large training corp ora, t ypically to b e collected offline. In the extreme, the latter requirement can cause slow prediction and conditioning times. Moreo ver, they ha v e b een used in com bination with computationally intensiv e planning metho ds such as dynamic programming [4, 5, 18] rendering real-time applicability difficult. In con trast to all this w ork, we will incorporate structural a-priori kno wledge of the dynamics afforded by Lagrangian mechanics (without sacrificing the flex- ibilit y afforded by the nonparametric nature). This requires, in some instances, partial departure from Gaussianit y (e.g. if the sign of a function component of the dynamics is known) but improv es the detail with whic h the system is iden tified and can reduce the dimensionalit y of the identification problem. F ur- thermore, our metho d will use the uncertain ties of the mo dels to decide up on training example incorp oration and decision making. Aside from learning, our metho d emplo ys feedbac k-linearisation [19] in an outer-lo op control law to reduce the complexit y of the control problem. Thereb y , in exp ectation, the problem is reduced to controlling a double-integrator via an inner-lo op con trol la w. If we com bine the outer-lo op controller with an inner- lo op controller that has desirable guarantees (e.g. stabilit y) for the double- in tegrator, these prop erties can extend to the exp ected given non-linear closed- lo op dynamics. The resulting approac h enables rapid decision making and can b e deploy ed online. Our work is presented at the AMLSC W orkshop at NIPS, 2013. During the review pro cess, w e w ere made a w are of GP-MRA C [3]. The authors utilise a Gaussian pro cess on joint state-cont rol space to learn the error of an inv ersion con troller in mo del-reference adaptive control. Under the assumption that the 2 GP could b e stated as an SDE of time, they prov e stabilit y . In con trast to this w ork, our method is capable of identifying the drift and control input v ector fields constituting the underlying control-affine system individually , yielding a more fine-grained identification result. While this b enefit requires the introduc- tion of probing signals to the control during online learning, each of the coupled learning problems has state space dimensionality only . Moreov er, our metho d and stabilit y results are not limited to Gaussian processes. If the con trol-input v ector fields are iden tified with a log-normal pro cess, our controller will auto- matically b e cautious in scarcely explored regions. 2 Metho d 2.1 Mo del Dynamics. Let I ⊂ R b e a (usually con tinuous) set of times, Q denote the configuration space, X the state space and U the control space. Via the principle of least action and the resulting Euler-Lagrange equation, Lagrangian mechanics leads to the conclusion that controllable mec hanical systems are of second order and can b e written in c ontr ol-affine form: ¨ q = a ( q , ˙ q ) + b ( q , ˙ q ) u. (1) Here, q ∈ Q is a generalized co ordinate of the configuration and u ∈ U is the con trol input. F unctions a, b are called drift and input functions, resp ectiv ely . In the p endulum con trol domain we consider b elo w, q will encode join t angles and u is a torque ¨ q is prop ortional to. Defining x 1 := q , x 2 := ˙ q ∈ Q , we can write the state as x := [ x 1 , x 2 ]. The dynamics can b e restated as the system of equations ˙ x 1 = x 2 (2) ˙ x 2 = a ( x 1 , x 2 ) + b ( x 1 , x 2 ) u (3) = a ( x 1 , x 2 ) + m X j =1 u j b j ( x 1 , x 2 ) (4) where m = dim U and b j ( x 1 , x 2 ) is the j th row of matrix b ( x 1 , x 2 ) ∈ R n × m . In this work, we assume the system is ful ly actuate d . That is, we assume that b ( q, ˙ q ) alw ays is full-rank: rank b ( q , ˙ q ) = dim Q =: n, ∀ q . That is, full-actuation en- ables us to instantaneously set the acceleration in all dimensions of Q . How ever, w e do not hav e immediate control o ver join t-angle velocities. Incorp orating this kind of knowledge afforded by Lagrangian mechanics is b eneficial b oth from a principled Ba yesian v an tage p oin t and in order to decompose the dimensionalit y of the learning task. Epistemic uncertain ty and learning. Both dynamics functions a and b can b e uncertain a priori. That is, a priori our uncertaint y is mo delled by 3 the assumption that a ∼ Π a , b ∼ Π b where Π a , Π b are sto c hastic pro cesses. The pro cesses reflect our epistemic uncertain t y ab out the true underlying (determin- istic) dynamics functions a and b . If data b ecomes av ailable ov er the course of the state evolution, w e can update our b eliefs o ver the dynamics in a Bay esian fashion. That is, at time t ∈ I w e assume a ∼ Π a |D t , b ∼ Π b |D t where D t is the data recorded up to time t . The pro cess of conditioning is often referred to as (Ba yesian) le arning . Data collection. W e assume our controller can b e called at an ordered set of times I u ⊂ I . A t each time t ∈ I u , the controller is able to observe the state x t = x ( t ) 1 and to set the con trol input u t = u ( t, x t ). The con troller may c ho ose to evok e learning at an ordered subset I λ ⊂ I u of times. T o this end, at each time τ ∈ I λ , the controller ev okes a procedure explicated in Sec. 2.2 if it decides to incorp orate an additional data p oin t ( t, x t , u t ) in to data set D t ( t > τ ). The decision on whether to up date the data will b e based on the b elief ov er the data p oin t’s an ticipated informativeness as appro ximated by its v ariance. 2 F or simplicity , we assume that learning can o ccur every ∆ λ seconds and the con troller is called every ∆ u ≤ ∆ λ seconds. A con tinuous control takes place in the limit of infinitesimal ∆ u . 2.2 Learning pro cedure T o enable learning, w e will require deriv atives of the state (that is estimates of ¨ q and ˙ q ). If we do not hav e physical means to measure v elo cities and acceler- ations, obtaining numerical estimates b ecomes necessary based on observ ations of q ( t ) = x 1 ( t ). T o estimate deriv atives, we chose a second-order method. That is, our state deriv ative estimates are ˙ y ( t i + ∆ o ) := x ( t i +2∆ o ) − x ( t i ) 2∆ 0 where ∆ o is a p eriod length with whic h w e can observe states. In this work, we assume ∆ o = ∆ u . Assuming online learning, the data sets D t are found incrementally . Since it is hard to use the data to infer a and b sim ultaneously , w e will hav e to actively decide which one w e desire to learn ab out (and set the control accordingly – whic h we will then refer to as a pr obing c ontr ol ). T o this end, we distinguish b et w een the following learning comp onen ts: • Learning a ( x ): Assume we are at time t ∈ I λ and that w e decide to learn ab out a . This decision is made, whenever our uncertain ty about a t := a ( x t ), encoded by v ar[ a ( x t )], is abov e a certain threshold θ a v ar . When learning is initiated, we k eep the control constant for tw o more time steps t + ∆ u , t + 2∆ u to obtain a go od deriv ativ e estimate as described ab ov e. T o remo ve additional uncertain ty due to ignorance ab out b , w e set probing con trol u t = u t +∆ u = u t +2∆ u = 0 yielding dynamics ˙ x 2 = a ( x ) during time interv al [ t, t + 2∆ u ). On the basis of a deriv ative estimate ˙ y 2 ( t ), we 1 In fact, w e can only observ e q and hav e to obtain noisy observ ations of ˙ q as w e will describ e below. 2 V ariance is known to approximate entropic measures of uncertainty (cf. [1]) and often easier to compute than en tropy . 4 can determine a noisy estimate ˜ a t +∆ u of unkno wn function v alue a t +∆ u at time t as p er ˜ a t +∆ u = ˙ y 2 ( t + ∆ u ) . So, ( t + ∆ u , ˜ a t +∆ u , 0) is added to the data after time t + 2∆ u . • Learning b j ( x ): At time t ∈ I λ , w e c ho ose to learn ab out function b j when- ev er our uncertaint y ab out a ( x ( t i )) is sufficiently small (i.e. v ar[ a ( x i )] ≤ θ a ) and our uncertain t y ab out b j is sufficien tly large (v ar[ b j ( x i )] > θ b ). When learning is initiated, we k eep the con trol constant for tw o more time steps t + ∆ u , t + 2∆ u to obtain a go od deriv ative estimate as describ ed ab o v e. Let e j ∈ R m b e the j th unit vector. T o learn ab out b j ( x ) at state x , w e apply a control action u = u j e j where u j ∈ R \{ 0 } . Inspecting Eq. 4 w e can then see that b j ( x ) = ˙ x 2 − a ( x ) u j . Since a ( x ) will generally be a random v ariable, so is b j ( x ) having mean h b j ( x ) i = ˙ x 2 −h a ( x ) i u j and v ariance v ar[ b j ( x )] = 1 u 2 j v ar[ a ( x )]. W e obtain a noisy estimate ˙ y of its deriv ativ e analogously to ab o ve. Mo delling ˙ x 2 as a random v ariable with mean ˙ y 2 , b j ( x ) b ecomes a random v ariable with mean h b j ( x ) i = ˙ y 2 − h a ( x ) i u j (5) and v ariance v ar[ b j ( x )] = v ar[ ˙ x 2 ] + v ar[ a ( x )] u 2 j ≤ v ar[ ˙ x 2 ] + θ a u 2 j . (6) Therefore, after time t +2∆ u , we add training p oin t x t +∆ u , h b j ( x t +∆ u ) i , u t to the data set. The additional v ariance (as per Eq. 6) is captured by setting observ ational noise levels for Π b accordingly . 2.3 Con trol law Unless the control actions are chosen to aid system identification (as described ab o v e), w e will wan t to base our control actions on our probabilistic b elief mo del ov er the dynamics. Given such an uncertain mo del, it remains to define an (outer-lo op) control p olicy u with desirable prop erties. In this work, we prop ose to define a control law that, when not learning, uses the probabilistic mo del to guaran tee desired b ehaviour in exp ectation. In this work, our attention will b e restricted to exp ected stability . Let a t := a ( x ( t )), b t := b ( x ( t )) and q t := q ( t ). Acceleration ¨ q t = a t + b t u ( t ) is a random v ariable with mean h ¨ q t i = h a t |D t i + h b t |D t i u. Hence, when applying inv ersion control la w u ( t, x ; u 0 ) := h b ( x ) |D t i − 1 −h a ( x ) |D t i + u 0 (7) 5 w e get an exp ected closed-lo op dynamics of h ˙ q t |D t i = h x 2 ( t ) |D t i = h ˙ x 1 ( t ) |D t i = ˙ y 1 (8) h ¨ q t |D t , x i = h ˙ x 2 ( t ) |D t , x i = h a t |D t i + h b t |D t ih b t |D t i − 1 −h a t |D t i + u 0 = u 0 (9) h ˙ x 2 ( t ) |D t i = Z X h ˙ x 2 ( t ) |D t , x i P . ( x ) = Z X u 0 ( t, x )P . ( x ) = h u 0 ( t, x ) i . (10) where u 0 ( t, x ) is an inner-lo op control law. Theorem 2.1. Assume we ar e not p erforming pr obing actions anymor e. That is, we ar e at time t ≥ t 0 such that t 0 > sup I λ . L et u 0 ( t, x ) b e a c ontr ol law that is line ar in state x and that ensur es the double-inte gr ator dynamics of the form ˙ z 1 = z 2 , ˙ z 2 = u 0 ( t, z ; ξ ) to have ξ as a glob al ly asymptotic al ly stable e quilibrium p oint. Final ly, supp ose that exp e ctation and derivative c ommute. That is, ∇ t h x i ( t ) |D t 0 i = h∇ t x i ( t ) |D t 0 i . Then, our c ontr ol law as p er Eq. 7, with inner c ontr ol law u 0 ( x, t ; ξ ) , ensur es ξ is a glob al ly asymptotic al ly stable e quilibrium of the exp e cte d dynamics. In p articular, lim t →∞ kh q t − ξ 1 |D t 0 ik 2 = 0 ∧ lim t →∞ kh ˙ q t − ξ 2 |D t 0 ik 2 = 0 . Pr o of. (Sketc h) Let ∇ t denote the differential operator with respect to time. Lev eraging the linearit y of the differential op erator, we can exc hange it with the exp ectation op erator. Thereby , we conclude from Eq. 8 and Eq. 10 that ∇ t h x 1 ( t ) |D t 0 i = h∇ t x 1 ( t ) |D t 0 i = h x 2 ( t ) |D t 0 i and ∇ t h x 2 ( t ) |D t 0 i = h∇ t x 2 ( t ) |D t 0 i = h u 0 ( t, x ; ξ ) i = u 0 ( t, h x i ; ξ ) where the last step follo ws b y linearity of the con trol law. Defining z i := h x i ( t ) |D t 0 i yields the quadratic regulator problem : ∇ t z 1 = z 2 , ∇ t z 2 = u 0 ( t, z ). By assump- tion, w e know that u 0 ensures that ξ is a globally asymptotic equilibrium p oin t of this dynamic system. Hence, in particular, lim t →∞ k z 1 ( t ) − ξ 1 k 2 = 0 ∧ lim t →∞ k ˙ z 2 ( t ) − ξ 2 k 2 = 0. Resubstituting the definitions of h x i ( t ) |D t 0 i for z i and subsequen tly , of q = x 1 , ˙ q = x 2 , yields the desired statement. R emark 2.2 . The requirement that differential and exp ectation op erator can b e in terchanged has to b e chec ked on a case b y case basis and dep ends on the inter- pretation of the random differen tial equation or the particular kinds of pro cesses driving the equation. Examples of where the assumption is met are white-noise limits or, when the integral curve x ( t ) is an L 2 pro cess with differentiable co- v ariance function (here, ∇ t x is the mean-square deriv ative). An alternative w ould b e to show exp ected stabilit y for ev ery Euler-approximation and prov e con vergence in the mean of these Euler approximations to the contin uous-time equation. Consequen tly , we ha ve given conditions under which our control law guar- an tees feedback-linearisation in exp ectation (and of the dynamics of the mean tra jectory). That is, by choosing u 0 to imp ose desired b eha viour for the double 6 in tegrator problem ¨ q = u 0 (whic h is easy), we can re-shap e the dynamics such that the exp ected closed-lo op dynamics is stable. F or instance, a simple metho d of guaran teeing global asymptotic conv ergence of the state to w ards a goal state ξ = [ ξ 1 , ξ 2 ] w ould b e to set the inner-most con trol law to the proportional feedbac k law u 0 ( t, x ; w ) := w 1 ( ξ 1 − x 1 ) + w 2 ( ξ 2 − x 2 ) (11) where w 1 , w 2 > 0. 3 Exp erimen ts – Learning to control a torque- con trolled damp ed p endulum with a com bi- nation of normal and log-normal pro cesses W e explored our metho d’s prop erties in sim ulations of a rigid p endulum with (a priori unknown) drift a ( x ) := − g l sin( x 1 ) − r ( x 1 ) ml 2 x 2 and constant input function b ( x ) = 1 m l 2 . Here, x 1 = q , x 2 = ˙ q ∈ R are joint angle position and velocity , r denotes a friction co efficien t, g is acceleration due to gravit y l is the length and m the mass of the p endulum. The con trol input u ∈ R applies a torque to the joint that corresp onds to joint-angle acceleration. The p endulum could b e con trolled b y application of a torque u to its pivotal p oin t. q = 0 enco de the p endulum pointing do wnw ard and q = 0 denoted the p osition in which the p endulum is upw ard. Given an initial configuration x 0 = [ q 0 , ˙ q 0 ] w e desired to steer the state to a terminal configuration ξ = [ q f , 0]. F or learning, w e assumed that a ∼ G P (0 , K a ) and b ∼ log G P (0 , K b ) had b een dra wn from a log-normal pro cess. 3 The latter assumption enco des a priori kno wledge that con trol input function b can only assume p ositiv e v alues (but, to demonstrate the idea of cascading pro cesses, we had discarded the information that b was a constan t). During learning, the latter pro cess was based on a standard normal process conditioned on log-observ ations of ˜ b . T o compute the con trol as p er Eq. 7, w e need to conv ert the p osterior mean ov er log b into the exp ected v alue ov er b . The required relationship is known to b e as follo ws: h b ( x ) |D t i = exp h log b ( x ) |D t i + 1 2 v ar[log b ( x ) |D t ] . (12) If required the p osterior v ariance can b e obtained as v ar[ b ( x ) |D t ] = exp 2 h log b ( x ) |D t i + v ar[log b ( x ) |D t ] exp v ar[log b ( x ) |D t ] − 1 . Note, the p osterior mean o ver b increases with the v ariance of our normal pro cess in log-space, and, the control law as p er Eq. 7 is inv ersely prop ortional to the magnitude of this mean. Hence, the resulting controller is c autious , in 3 F or details on normal processes see [16]. 7 the sense that control output magnitude is damp ed exp onen tially in regions of high uncertain ty (v ariance). T o simulate a discrete 0th order sample-and-hold controller in a con tinuous en vironment, w e simulated the dynamics b et w een tw o consecutive controller calls (o ccurring every ∆ u seconds) emplo ying standard ODE-solving pack ages (i.e. Matlab’s o de45 routine). W e illustrated the b ehaviour of our controllers in a sequence of four ex- p erimen ts. The parameter settings are pro vided in T ab. 1. Recorded control energies and errors (in comparison to contin uous prop ortional con trollers) are pro vided in T ab. 2. Our Bay esian con troller maintains an epistemic beliefs ov er the dynamics. These b eliefs gov ern our con trol decisions (including those when to learn). F urther- more, to keep prediction times lo w, b eliefs are only up dated when the current v ariance indicated a sufficient of uncertaint y . Therefore, one would exp ect to observ e three prop erties of our controller: (i) When the priors are chosen sensibly (could b e indicated by the dynamic functions’ lik eliho od under the probabilistic models), we expect go od control p erformance. (ii) Prior training impro ves control p erformance and, reduces learning, but is not necessary to reac h the goal. Both prop erties can b e observ ed in Exp.1 and Exp. 3. (iii) When the controller is ignorant of the inaccuracy of its beliefs ov er the dynamics (i.e. the actual dynamics are unlikely but the v ariances are low), con trol may fail since the false b eliefs are not up dated. An example of this is pro vided in Exp. 2. (iv) W e can ov ercome such problems practically , by employing the stan- dard technique (see [16]) of choose the prior hyper-parameters that maximise marginal lik eliho o d. In Exp. 3, this approach was successfully applied to the con trol problem of Exp. 2. P arameter ( s ) : (l,r,m) ∆ u ∆ l ( θ a var , θ log b var ) x 0 ξ ( w 1 , w 2 ) t f Exp. 1 (1,1,0.5) .01 .5 (.001, .005) (0,-2) ( π , 0) (1,1) 20 Exp. 2 (1,0.5,4) .01 1 (.001, .005) (0,-2) ( π , 0) (2,2) 15 Exp. 3 (1,0.5,4) .01 1 (.001, .005) (0,-2) ( π , 0) (2,2) 20 T able 1: Parameter settings. Exp erimen t 1. W e started with a zero-mean normal pro cess prior o ver a ( · ) endow ed with a rational quadratic kernel with automated relev ance detec- tion (RQ-ARD) [16]. The kernel hyper-parameters w ere fixed. Observ ational noise v ariance was set to 0 . 01. The log-normal pro cess ov er b ( · ) was imple- men ted b y placing a normal ov er log b ( · ) with zero mean and RQ-ARD k ernel with fixed hyper-parameters and observ ational noise lev el 0 . 1. Note, the latter w as set higher to reflect the uncertaint y due to Π a . In the future, w e will con- sider incorp orating hetereoscedastic observ ational noise based on v ar[ a ] and the 8 R I u 2 adapt ( t ) dt R I ( x ( t ) − ξ ) 2 dt ( D a t f , D b t f ) C ontr oller : P1 P100 SP1 SP2 P1 P100 SP1 SP2 SP1 SP2 Exp. 1 134 644 139 57 137 10 59 25 (18, 20) (23, 53) Exp. 2 552 11942 14759 17029 139 10 82 72 (2,1) (2,1) Exp. 3 730 11942 3753 1619 184 10 83 17 (12,2) (12,2) T able 2: Cum ulative con trol energies, squared errors and data sizes (rounded to in teger v alues). P k : P-con troller with feedback gain k . P1 failed to reach the goal state in all exp erimen ts. High-gain controller P100 succeeded in reaching the goal in all exp erimen ts but required a lot of energy . SP1: sto c hastic process - based con troller with empty data set to start with. SP2: reset SP1 with training data collected from the first run. 0 5 10 15 −2 0 2 Time State State evolution angle angle velocity 0 5 10 15 0 2 4 6 Time Control Control evolution 0 5 10 15 0 50 100 Time Control energy −1 0 1 0 1 2 (a) Control with un trained prior. 0 5 10 15 −2 0 2 Time State State evolution angle angle velocity 0 5 10 15 −2 0 2 4 6 Time Control Control evolution 0 5 10 15 0 20 40 Time Control energy −1 0 1 0 1 2 (b) Control evolution with trained prior from the first round. Figure 1: Exp erimen t 1. Comparison of runs with un trained and pre-trained pro cesses. The top-right image shows the final p osition of the p endulum having successfully reac hed the target angle ξ 1 = π . The dips in the control signal represen t probing control actions arising during online learning. sampling rate. Also, one could incorp orate knowledge ab out p eriodicity in the k ernel. Results are depicted in Fig. 1 and 2. W e see that the system was accurately iden tified b y the sto c hastic processes. When restarting the con trol task with sto c hastic pro cesses pre-trained from the first round, the task was solved with less learning, more swiftly and with less control energy . Exp erimen t 2. W e inv estigated the impact of inappropriate magnitudes of confidence in a wrong mo del. W e endow ed the con troller’s priors with zero mean functions and SE-ARD kernels [16]. Length scales of k ernel K a w ere set to 20 and the output scale to 0 . 5. In addition to the low output-scale, we set observ ational noise v ariance to a low v alue of 0.0001 suggesting (ill-founded) high confidence in the prior. The length scale of kernel K b w as set to 50 with lo w output scales and observ ational noise v ariance of 0.5 and 0.001, resp ectively . The results, depicted in Fig. 3. As to be expected, the con troller fails to realise the inadequateness its beliefs. This results in a failure to up date its b eliefs and consequently , in a failure to conv erge to the target state. 9 (a) a ( x ) − h a ( x ) | D t f i . (b) Posterior standard de- viation q v ar[ a ( x ) | D t f ]. (c) Posterior ov er log b . Figure 2: Exp erimen t 1. P osterior mo dels of SP1. Stars indicate training examples. The sto c hastic pro cess has learned the dynamics functions in explored state space with sufficient accuracy . 0 5 10 −2 −1 0 1 2 Time State State evolution angle angle velocity 0 5 10 0 20 40 Time Control Control evolution 0 5 10 0 5000 10000 Time Control energy −1 0 1 0 1 2 (a) Control evolution of SP1, with un- trained prior. 0 5 10 −2 −1 0 1 2 Time State State evolution angle angle velocity 0 5 10 20 30 40 50 60 Time Control Control evolution 0 5 10 0 5000 10000 15000 Time Control energy −1 0 1 0 1 2 (b) Control evolution of controller SP2, b enefiting from learning experience from the first round. Figure 3: Exp erimen t 2. Comparison of runs with un trained and pre-trained pro cesses. Neither run succeeds in arriving at the target state due to b eing o verly confident. Of course, this could b e o vercome with an actor-critic approac h. Such solu- tions will b e inv estigated in the context of future work. Exp erimen t 3. Exp. 2 was rep eated. This time, how ever, the kernel h yp er-parameters were found by maximizing the marginal lik eliho o d of the data. The automated identi- fication of hyper-parameters is b eneficial in practical scenarios where definition of a go od prior for the underlying dynamics ma y b e hard to conceive. The optimiser succeeded in finding sensible parameters that allo wed go od con trol p erformance. As b efore, the metho d b enefited from prior training yield- ing faster conv ergence and lo wer control effort. Both untrained and pre-trained metho ds outperformed the P -controllers either in terms of con trol energy or con vergence. Finally , the SP controllers with hyper-parameter optimisation outp erformed the SP controllers with fixed hyper-parameters set in Exp. 2 (c.f. T ab. 2). 10 (a) a ( x ) − h a ( x ) | D t f i . (b) Posterior standard devi- ation q v ar[ a ( x ) | D t f ]. −6 −4 −2 0 2 4 6 −1.8 −1.795 −1.79 −1.785 Prediction std posterior mean data (c) Posterior ov er log b . Figure 4: Exp erimen t 2. P osterior mo dels of SP1. Stars indicate training examples. Note, the low posterior v ariance suggests misleading confidence in an inaccurate mo del. 0 5 10 15 −2 0 2 Time State State evolution angle angle velocity 0 5 10 15 −20 0 20 40 Time Control Control evolution 0 5 10 15 0 1000 2000 3000 Time Control energy −1 0 1 0 1 2 (a) Control evolution of SP1, with un trained prior. (b) a ( x ) − h a ( x ) | D t f i . (c) P osterior stan- dard deviation q v ar[ a ( x ) | D t f ]. Figure 5: Exp erimen t 3. P osterior mo dels of SP1. Stars indicate training exam- ples. The optimisation pro cess succeeded in finding a sufficiently appropriate mo del. 11 4 Conclusions W e ha ve applied Bay esian nonparametric metho ds to learn online the drift and con trol input functions of a fully-actuated con trol-affine second-order dynamical system. P aired with the idea of feedback-linearisation we devised a control law that switc hes betw een probing actions for learning and control signals that driv e the exp ected tra jectory tow ards a given setp oin t. Our simulations hav e illus- trated our controller’s b ehaviour in the con text of a pendulum regulator problem and that it can successfully solve the identification and con trol problems. They ha ve also serv ed as an illustration of the inheren t pitfalls of Bay esian con trol – that is, guarantees are stated relative to epistemological b eliefs (enco ded by a p osterior) ov er the dynamical system in question. Therefore, the controller’s p erformance ma y b e undermined by ignorance ov er the p oten tial falsity of prior b eliefs (cf. Exp. 3). How ever, as illustrated in Exp. 3, ev en the most simple mo del selection methods can alleviate the burden of having to conceive a go o d fixed prior. In futur e work , we will explore ho w to emplo y a predictor-corrector approac h to uncov er ov er-confidence of our mo dels and to initiate learning. A t presen t, our con trol la w ac hieves desired performance of the expected tra jectory . W e will in vestigate ho w to extend the guaran tees to ac hieve p erformance guarantees in exp ectation and within probability b ounds. Other theoretical questions under in vestigation are analysis of the trade-offs betw een the impact of probing actions (to learn), the desire to keep prediction time lo w, information gain and control refresh cycle length ∆ u . Finally , we will assess our metho ds’ p erformance in higher-dimensional systems. References [1] T ansu Alpcan. Dual Con trol with Active Learning using Gaussian Pro cess Re- gression. Arxiv preprint , pages 1–29, 2011. [2] H. Bauer. Wahrscheinlichkeitsthe orie . deGruyter, 2001. [3] Girish Chowd hary , HA Kingravi, JP Ho w, and P A V ela. Bay esian Nonparametric Adaptiv e Con trol using Gaussian Pro cesses. T echnical rep ort, MIT, 2013. [4] MP Deisenroth, J. P eters, and C. E. Rasm ussen. Approximate dynamic program- ming with gaussian pro cesses. ACC , June 2008. [5] M.P . Deisenroth, C. E. Rasm ussen, and J. Peters. Gaussian process dynamic programming. Neur o c omputing , 2009. [6] T.E. Duncan and B.Pasik-Duncan. Adaptive con trol of a scalar linear sto c hastic system with a fractional bro wnian motion. In F AC World Congr ess , 2008. [7] H. Grimmett, R. Paul, R. T rieb el, and I. Posner. Kno wing when we dont kno w: In trosp ectiv e classification for mission-critical decision making. In ICRA , 2013. [8] J. Ko, D. Klein, D. F ox, and D. Haehnel. Gaussian Pro cesses and Reinforcement Learning for Iden tification and Control of an Autonomous Blimp. In ICRA , 2007. [9] J. Kocijan and R. Murra y-Smith. Nonlinear Predictive Control with a Gaussian. L ectur e Notes in Computer Scienc e 3355, Springer , pages 185–200, 2005. 12 [10] J. Ko cijan, R. Murray-Smith, C.E. Rasmussen, and B. Lik ar. Predictive con- trol with Gaussian pro cess models. In The IEEE R e gion 8 EUR OCON 2003. Computer as a T o ol. , v olume 1, pages 352–356. Ieee, 2003. [11] P . R. Kumar. A surv ey of some results in stochastic adaptive control. Siam J. Contr ol and Optimization , 23, 1985. [12] Ro deric k Murray-smith, Carl Edward Rasmussen, and Agathe Girard. Gaussian Pro cess Mo del Based Predictiv e Con trol. In IEEE Euro c on 2003: The Interna- tional Confer ence on Computer as a T o ol , 2003. [13] D. Nguy en-T uong and J. P eters. Using model knowledge for learning inv erse dynamics. In IEEE Int. Conf. on Rob otics and Automation (ICRA) , 2010. [14] D Nguy en-T uong, J. P eters, M. Seeger, and B. Sch¨ olkopf. Learning inv erse dy- namics: a comparison. In Eur op. Symp. on Artif. Neural Netw. , 2008. [15] Ioannou P . and J. Sun. R obust A daptive Contr ol . Pren tice Hall, 1995. [16] C.E. Rasm ussen and C. K. I. Williams. Gaussian Pr o c esses for Machine L e arning . MIT Press, 2006. [17] Alex Rogers, Sasan Maleki, Siddhartha Ghosh, and N.R. Jennings. Adaptiv e Home Heating Control Through Gaussian Pro cess Prediction and Mathematical Programming. In 2nd Int. Workshop on A gent T e chnolo gy for Ener gy Systems (A TES 2011) , 2011. [18] A. Rottmann and W. Burgard. Adaptive Autonomous Con trol using Online V alue Iteration with Gaussian Pro cesses. In ICRA , 2009. [19] M. W. Sp ong. P artial feedback linearization of underactuated mechanical systems. In Pr o c. IEEE Int. Conf. on Intel. R obots and Sys. (IROS) , 1994. [20] K.Y. V olyanskyy , M.M. Haddad, and A.J. Calise. A new neuroadaptive control arc hitecture for nonlinear uncertain dynamical systems: Beyond sigma- and e- mo difications. In CDC , 2008. 13
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment