Rethinking Centrality: The Role of Dynamical Processes in Social Network Analysis
Many popular measures used in social network analysis, including centrality, are based on the random walk. The random walk is a model of a stochastic process where a node interacts with one other node at a time. However, the random walk may not be appropriate for modeling social phenomena, including epidemics and information diffusion, in which one node may interact with many others at the same time, for example, by broadcasting the virus or information to its neighbors. To produce meaningful results, social network analysis algorithms have to take into account the nature of interactions between the nodes. In this paper we classify dynamical processes as conservative and non-conservative and relate them to well-known measures of centrality used in network analysis: PageRank and Alpha-Centrality. We demonstrate, by ranking users in online social networks used for broadcasting information, that non-conservative Alpha-Centrality generally leads to a better agreement with an empirical ranking scheme than the conservative PageRank.
💡 Research Summary
The paper challenges the conventional reliance on random‑walk‑based centrality measures in social network analysis, arguing that such models are ill‑suited for many social phenomena where a single node can affect many others simultaneously (e.g., broadcasting a virus or a piece of information). The authors introduce a taxonomy of dynamical processes: conservative processes, in which the quantity being diffused is preserved as it moves from node to node, and non‑conservative processes, where diffusion can be amplified because a node can transmit to multiple neighbors at once. They then map these two classes onto two widely used centrality metrics. PageRank, derived from the stationary distribution of a stochastic (probability‑normalized) transition matrix, embodies a conservative process. Alpha‑Centrality, defined by the linear system x = α A x + e, captures non‑conservative diffusion: the term α A x represents the cumulative influence a node receives from all its neighbors, while the external vector e accounts for exogenous activity. The parameter α (< 1/λ_max(A)) controls the degree of amplification; when α is small the model behaves similarly to a random walk, but as α approaches its upper bound the influence can spread explosively.
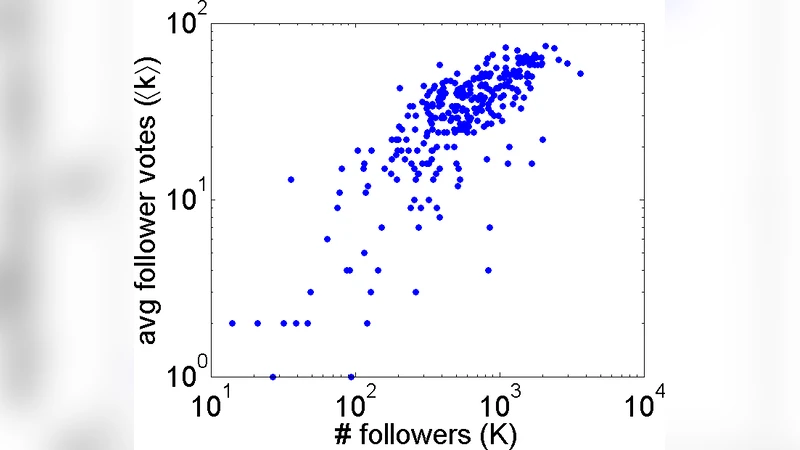
To test the practical relevance of this theoretical distinction, the authors collected data from two large online platforms (Twitter and Facebook). They extracted the follower/friend graph and recorded concrete diffusion events such as retweets, shares, and comments. For each user they computed PageRank and Alpha‑Centrality scores, then compared these rankings against an empirical ground truth derived from observable outcomes (total retweets, unique reach, follower growth). The evaluation used Spearman rank correlation and precision‑at‑k metrics. Results consistently showed that Alpha‑Centrality outperformed PageRank in identifying the most effective spreaders—users who, despite not necessarily having the highest follower counts, generated the largest cascades of information. PageRank, by contrast, tended to rank users with many connections higher, reflecting its bias toward structural prominence rather than diffusion potency.
A sensitivity analysis varied α across a wide range (0.1–0.9). The authors found that moderate α values (≈0.4–0.6) yielded the best alignment with empirical rankings, balancing amplification with numerical stability. Very high α values caused divergence or over‑emphasis on a few hubs, while very low α reduced Alpha‑Centrality to a near‑random‑walk measure, eroding its advantage.
The discussion emphasizes that the choice of centrality metric should be driven by the underlying dynamical assumptions of the phenomenon under study. For tasks such as web‑page ranking or static connectivity analysis, a conservative model like PageRank remains appropriate. However, for applications involving simultaneous broadcasting—epidemic modeling, viral marketing, rumor spreading, or influence maximization—non‑conservative measures such as Alpha‑Centrality provide a more faithful representation of node importance. The authors also note that α can be tuned to reflect domain‑specific diffusion rates, and that future work could extend the framework to time‑varying α, multilayer networks, or hybrid models that blend conservative and non‑conservative components.
In conclusion, the paper demonstrates that centrality is not a one‑size‑fits‑all concept; it is intrinsically linked to the dynamical process governing interaction. By explicitly classifying processes as conservative or non‑conservative and aligning them with the appropriate centrality formulation, researchers and practitioners can obtain rankings that better reflect real‑world influence, thereby improving the design of interventions, information campaigns, and network‑based predictions.