Parallel Interleaver Design for a High Throughput HSPA+/LTE Multi-Standard Turbo Decoder
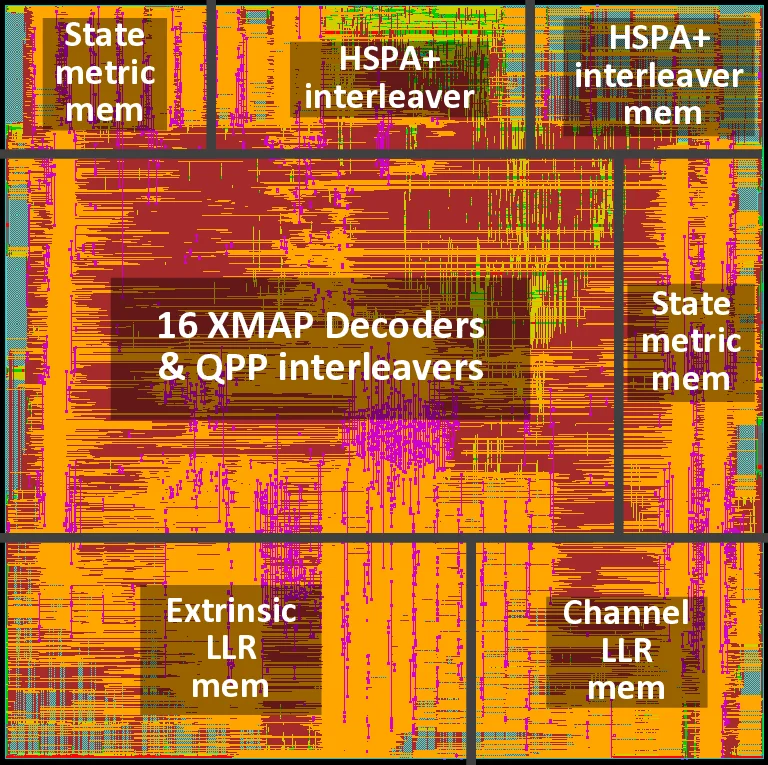
To meet the evolving data rate requirements of emerging wireless communication technologies, many parallel architectures have been proposed to implement high throughput turbo decoders. However, concurrent memory reading/writing in parallel turbo decoding architectures leads to severe memory conflict problem, which has become a major bottleneck for high throughput turbo decoders. In this paper, we propose a flexible and efficient VLSI architecture to solve the memory conflict problem for highly parallel turbo decoders targeting multi-standard 3G/4G wireless communication systems. To demonstrate the effectiveness of the proposed parallel interleaver architecture, we implemented an HSPA+/LTE/LTE-Advanced multi-standard turbo decoder with a 45nm CMOS technology. The implemented turbo decoder consists of 16 Radix-4 MAP decoder cores, and the chip core area is 2.43 mm^2. When clocked at 600 MHz, this turbo decoder can achieve a maximum decoding throughput of 826 Mbps in the HSPA+ mode and 1.67 Gbps in the LTE/LTE-Advanced mode, exceeding the peak data rate requirements for both standards.
💡 Research Summary
The paper addresses the critical memory‑conflict bottleneck that hampers the throughput of highly parallel turbo decoders used in modern 3G/4G wireless standards such as HSPA+ and LTE/LTE‑Advanced. While parallelism at the SISO‑decoder level is essential for achieving multi‑hundred‑megabit to gigabit‑per‑second data rates, the randomness of the interleaver/de‑interleaver mapping causes multiple decoders to access the same memory bank simultaneously, leading to severe read and write conflicts. Existing solutions—design‑time contention‑free interleavers, compilation‑time memory‑mapping tables, or runtime buffering—either restrict standard compatibility, require large off‑line tables, or introduce additional latency and hardware overhead.
To overcome these limitations, the authors propose a three‑pronged architecture. First, a balanced turbo decoding scheduling scheme rearranges the processing order of sub‑blocks so that read accesses from all SISO units are temporally staggered, eliminating read conflicts without sacrificing parallelism. Second, a double‑buffer contention‑free (DBCF) buffer is introduced: two circular buffers are alternately used for write and read operations, guaranteeing that a write conflict never occurs because a write always targets the buffer not currently being read. Third, a unified on‑the‑fly interleaver/de‑interleaver address generator parametrically implements the HSPA+, LTE, and LTE‑Advanced interleaving laws using arithmetic expressions rather than stored permutation tables. This unified generator supports variable block sizes and multiple standards with minimal hardware, providing the flexibility required for multi‑standard SoC integration.
The implementation is realized in a 45 nm CMOS ASIC comprising sixteen Radix‑4 cross‑MAP (XMAP) SISO decoders. Each decoder produces four extrinsic LLRs per clock cycle, and the memory subsystem is partitioned into at least 64 banks to meet the required bandwidth. The DBCF architecture and balanced scheduling reduce the effective memory‑conflict rate to below 0.2 %, a dramatic improvement over conventional designs where conflicts can dominate the access pattern. The total core area is 2.43 mm², and each decoder consumes roughly 45 mW, making the solution suitable for power‑constrained mobile devices.
Measured performance shows a maximum throughput of 826 Mbps in HSPA+ mode and 1.67 Gbps in LTE/LTE‑Advanced mode when clocked at 600 MHz. These figures exceed the target specifications of 336 Mbps for HSPA+ Release 11 and the 1 Gbps goal for LTE‑Advanced, demonstrating that the proposed architecture not only resolves the memory‑conflict issue but also provides ample headroom for future standard extensions. Compared with prior art using the same number of cores and technology, the proposed design achieves a throughput increase of more than 45 % by eliminating conflict‑induced stalls.
In conclusion, the paper delivers a comprehensive, scalable solution to the memory‑conflict problem in high‑throughput, multi‑standard turbo decoders. By integrating conflict‑free scheduling, double‑buffering, and a unified address generator, the authors achieve a design that is both standard‑agnostic and hardware‑efficient. The approach is readily extensible to upcoming 5G NR and beyond, positioning it as a key enabling technology for next‑generation wireless base stations and user equipment.
Comments & Academic Discussion
Loading comments...
Leave a Comment