Why Do You Spread This Message? Understanding Users Sentiment in Social Media Campaigns
Twitter has been increasingly used for spreading messages about campaigns. Such campaigns try to gain followers through their Twitter accounts, influence the followers and spread messages through them. In this paper, we explore the relationship between followers sentiment towards the campaign topic and their rate of retweeting of messages generated by the campaign. Our analysis with followers of multiple social-media campaigns found statistical significant correlations between such sentiment and retweeting rate. Based on our analysis, we have conducted an online intervention study among the followers of different social-media campaigns. Our study shows that targeting followers based on their sentiment towards the campaign can give higher retweet rate than a number of other baseline approaches.
💡 Research Summary
**
The paper investigates how the sentiment of Twitter users who follow a social‑media campaign influences their likelihood of spreading the campaign’s messages through retweets. Focusing on the controversial topic of hydraulic fracturing (“fracking”), the authors collect data from four Twitter accounts—two pro‑fracking and two anti‑fracking—over a one‑month period. They retrieve recent tweets from each campaign, as well as recent and historical tweets (up to 200 per user) from the followers of these accounts, distinguishing between topic‑relevant tweets (containing keywords such as “fracking”, “shale”, “oil”) and general tweets.
Because ground‑truth sentiment for followers is unavailable, the authors construct a sentiment‑prediction model. They first identify a set of users who have retweeted highly popular (≥100 retweets) pro‑ or anti‑fracking tweets, assuming that retweeting indicates endorsement. From this they obtain 1,000 positive, 1,000 negative, and 1,000 neutral users (the latter sampled randomly from the Twitter stream). Using the historical tweets of these 3,000 users, they train a three‑class classifier (positive, negative, neutral) based on unigram features. Experiments with WEKA show that an SVM achieves about 92 % accuracy (precision 0.93, recall 0.92, F‑measure 0.925) under 10‑fold cross‑validation.
To validate the model on real followers, the authors randomly select 200 followers (50 from each campaign) and have 100 crowd‑workers label each follower’s sentiment by inspecting their historical tweets. After filtering for agreement, 126 followers have reliable human labels, and the model’s predictions match these labels for 110 cases, yielding an 87.3 % agreement—indicating that the model’s performance degrades when applied to a broader, noisier population.
The core analysis examines the relationship between inferred sentiment and retweet behavior. For each follower, the authors compute two normalized retweet rates: (1) the proportion of the follower’s retweets that are of topic‑relevant campaign tweets, and (2) the proportion of retweets of any campaign tweet. Both rates are further normalized by the follower’s overall retweet volume in the last month. Sentiment scores are mapped to numeric values (1 = positive, 0 = neutral, –1 = negative for pro‑fracking campaigns; the opposite mapping for anti‑fracking campaigns). They also calculate a “sentiment strength” by multiplying the classifier’s probability estimate with the numeric score.
Pearson correlation analyses reveal statistically significant positive correlations (p < 0.05) between sentiment polarity and the normalized retweet rate of topic‑relevant messages for all four campaigns (correlation coefficients ranging from 0.60 to 0.80). Correlations for general campaign tweets are weaker and often not significant, but sentiment strength consistently shows stronger and significant correlations, suggesting that the confidence of the sentiment prediction adds predictive power.
Building on these findings, the authors develop predictive models of retweet rates. Regression models (logistic regression performed best) use either sentiment polarity or sentiment strength as the independent variable and the normalized retweet rate as the dependent variable. Mean absolute error (MAE) for predicting topic‑related retweet rates lies between 0.23 and 0.25, while MAE for general tweets is between 0.25 and 0.28; using sentiment strength reduces error modestly. Classification experiments treat followers with above‑median retweet rates as “high” and those below as “low”. Binary classifiers (SVM, Naïve Bayes, J48, Random Forest) achieve area‑under‑curve (AUC) scores ranging from 0.63 to 0.80, with sentiment strength again yielding better performance.
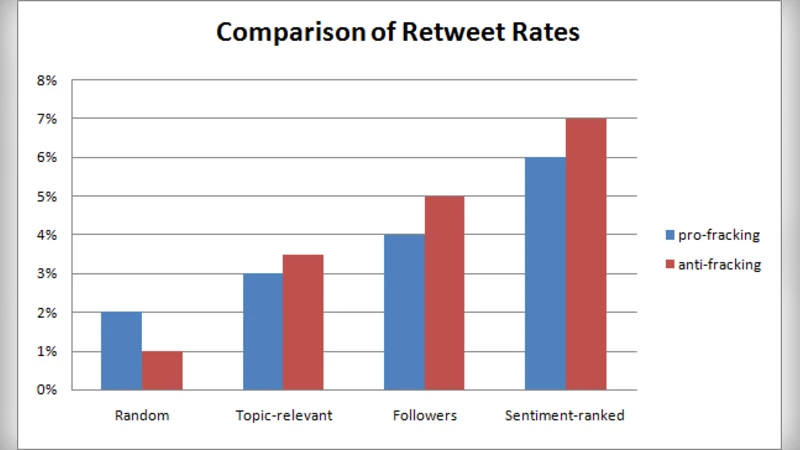
To test practical implications, the authors conduct an online engagement study. They create six new Twitter accounts (three pro‑fracking, three anti‑fracking) and compile pools of 10 pro‑ and 10 anti‑fracking messages, each requesting a retweet. For each campaign, they select three target groups: (a) the top 500 followers ranked by sentiment strength (sentiment‑ranked‑top), (b) 500 randomly chosen followers, (c) 500 random users from the Twitter stream, and (d) 500 users who recently mentioned “fracking”. Each group receives 500 messages (one per user) drawn randomly from the appropriate message pool. After a week, retweet rates are measured. The sentiment‑ranked‑top group consistently achieves the highest retweet rate—often two to three times higher than the other groups—demonstrating that targeting users with strong positive sentiment markedly improves campaign diffusion.
In conclusion, the study provides empirical evidence that (1) a user’s sentiment toward a campaign topic is positively associated with their likelihood of retweeting campaign content, especially when the content is directly related to the campaign’s core issue; (2) sentiment strength (probability‑weighted sentiment) is a more reliable predictor than simple polarity; (3) sentiment‑based targeting outperforms random or purely topic‑based targeting in real‑world diffusion experiments. The authors acknowledge limitations, including reliance on the assumption that retweet equals endorsement, the focus on a single controversial topic, and the modest accuracy of sentiment inference on unseen followers. Future work is proposed to (i) extend the analysis to multiple topics and other engagement actions (hashtag usage, mentions, original tweet creation), (ii) integrate additional predictors such as overall activity level, prior interactions, and network centrality, (iii) incorporate demographic and personality data via surveys, and (iv) test the generalizability of findings across different platforms and cultural contexts. This research contributes to the growing literature on social‑media analytics by linking affective states to concrete diffusion outcomes and offering a practical framework for sentiment‑driven campaign optimization.
Comments & Academic Discussion
Loading comments...
Leave a Comment