A General Framework for Interacting Bayes-Optimally with Self-Interested Agents using Arbitrary Parametric Model and Model Prior
Recent advances in Bayesian reinforcement learning (BRL) have shown that Bayes-optimality is theoretically achievable by modeling the environment’s latent dynamics using Flat-Dirichlet-Multinomial (FDM) prior. In self-interested multi-agent environments, the transition dynamics are mainly controlled by the other agent’s stochastic behavior for which FDM’s independence and modeling assumptions do not hold. As a result, FDM does not allow the other agent’s behavior to be generalized across different states nor specified using prior domain knowledge. To overcome these practical limitations of FDM, we propose a generalization of BRL to integrate the general class of parametric models and model priors, thus allowing practitioners’ domain knowledge to be exploited to produce a fine-grained and compact representation of the other agent’s behavior. Empirical evaluation shows that our approach outperforms existing multi-agent reinforcement learning algorithms.
💡 Research Summary
This paper proposes a novel generalization of Bayesian Reinforcement Learning (BRL) called Interactive BRL (I-BRL), which enables Bayes-optimal interaction with self-interested agents by integrating an arbitrary class of parametric models and model priors. The work identifies critical practical limitations of the standard Flat-Dirichlet-Multinomial (FDM) prior commonly used in BRL theory. While computationally convenient, FDM relies on an independence assumption that treats the transition dynamics for each state-action pair as separate multinomial distributions. This assumption breaks down in multi-agent settings where the primary source of uncertainty is the stochastic behavior of the other agent, which is often governed by a common set of latent parameters across different states (e.g., a driver’s consistent style, spatial correlation in environmental phenomena). Consequently, FDM cannot generalize the opponent’s behavior across states nor incorporate structured prior domain knowledge, leading to poor performance in large-scale, practical problems.
To overcome these limitations, the authors introduce a new Bayesian modeling paradigm for the opponent’s behavior. The behavior is defined by a set of action selection probabilities (p^v_s(\lambda)) parameterized by (\lambda). The key innovation is that the initial prior belief (b(\lambda)) and the likelihood (p^v_s(\lambda)) are not restricted to being conjugate (Dirichlet-multinomial). This grants practitioners the flexibility to design informed, structured priors that reflect domain expertise. Theorem 1 proves that even without conjugacy, if the initial prior can be represented by a finite set of parameters, then the posterior belief after any sequence of observations can also be represented exactly in parametric form, with belief updates performed simply by incrementing hyper-parameters.
The core I-BRL framework is then formally developed. The agent’s goal is to find a Bayes-optimal policy that maximizes the expected discounted sum of rewards, accounting for both immediate payoff and the value of information gained by updating the belief. Theorems 2 and 3 establish that the optimal value function can be represented by a finite set of piecewise linear α-functions. Most importantly, Theorem 4 demonstrates that each α-function can be expressed as a linear combination of functions from the family (\Phi(\lambda)), which are products of likelihood functions (p^v_s(\lambda)). This generalizes the previous result under FDM where α-functions were linear combinations of multivariate monomials. This theoretical foundation ensures that the parametric form of the α-functions is closed under the Bellman backup operation, enabling the derivation of the optimal policy.
Based on this theory, the paper outlines a constructive, exact algorithm for computing the sets of α-functions through iterative backup operations. This algorithm, while conceptually clear, can be computationally intensive. The paper’s contribution lies in providing the first theoretical and algorithmic framework for deriving non-myopic, Bayes-optimal policies against opponents modeled with arbitrary parametric forms and priors, subsuming FDM as a special case.
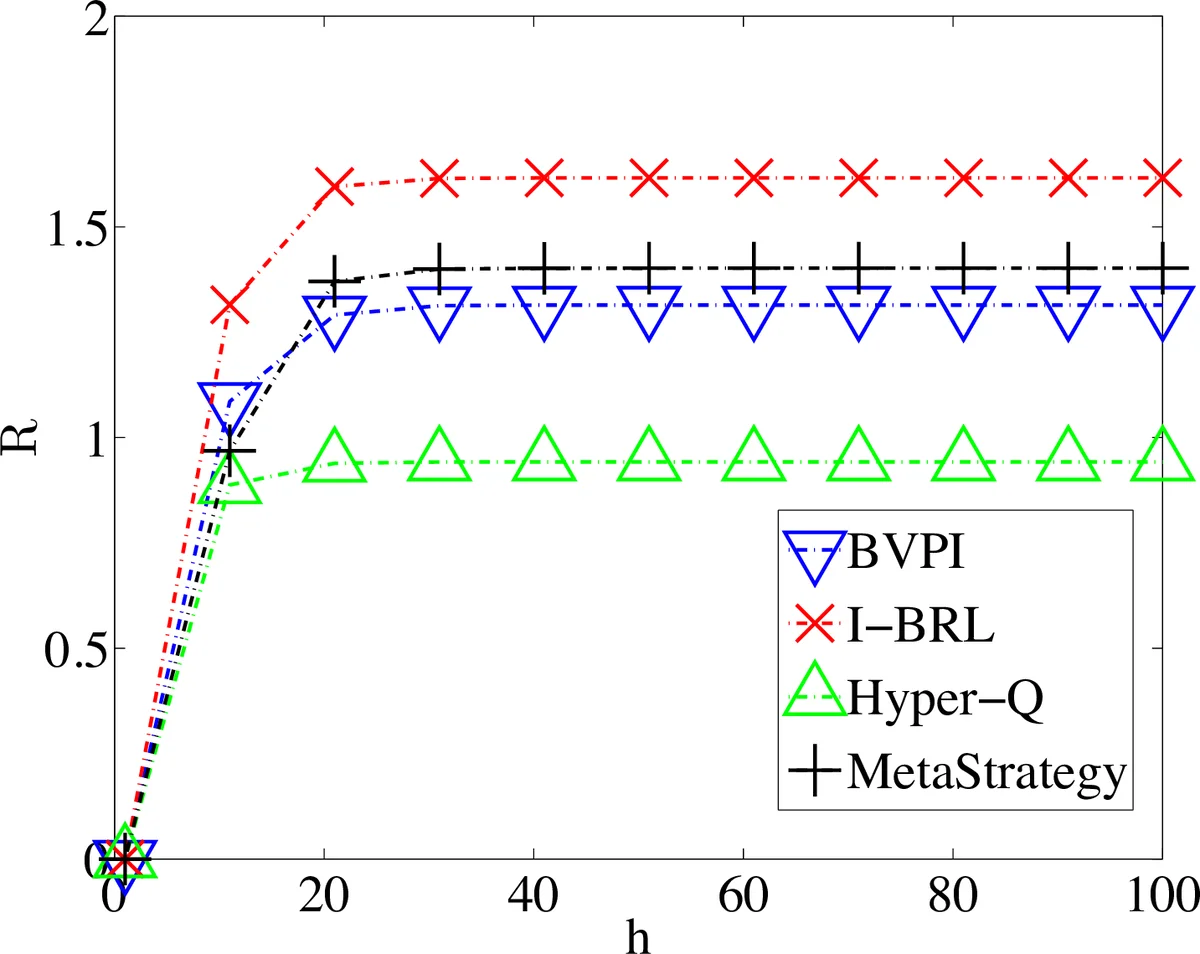
Finally, the paper presents an empirical evaluation in a traffic scenario modeled after a real-world situation. The results show that I-BRL, leveraging a structured parametric model for driver behavior, outperforms a prior state-of-the-art Bayesian method (BPVI) restricted to FDM. This validates the practical advantage of I-BRL: it allows for a fine-grained and compact representation of opponent behavior by incorporating domain knowledge, leading to more efficient learning and better generalization across states. In summary, this work bridges a significant gap between BRL theory and practice, offering a flexible framework that empowers domain experts to embed their knowledge into the learning process for effective interaction with self-interested agents.
Comments & Academic Discussion
Loading comments...
Leave a Comment