OCCA: A unified approach to multi-threading languages
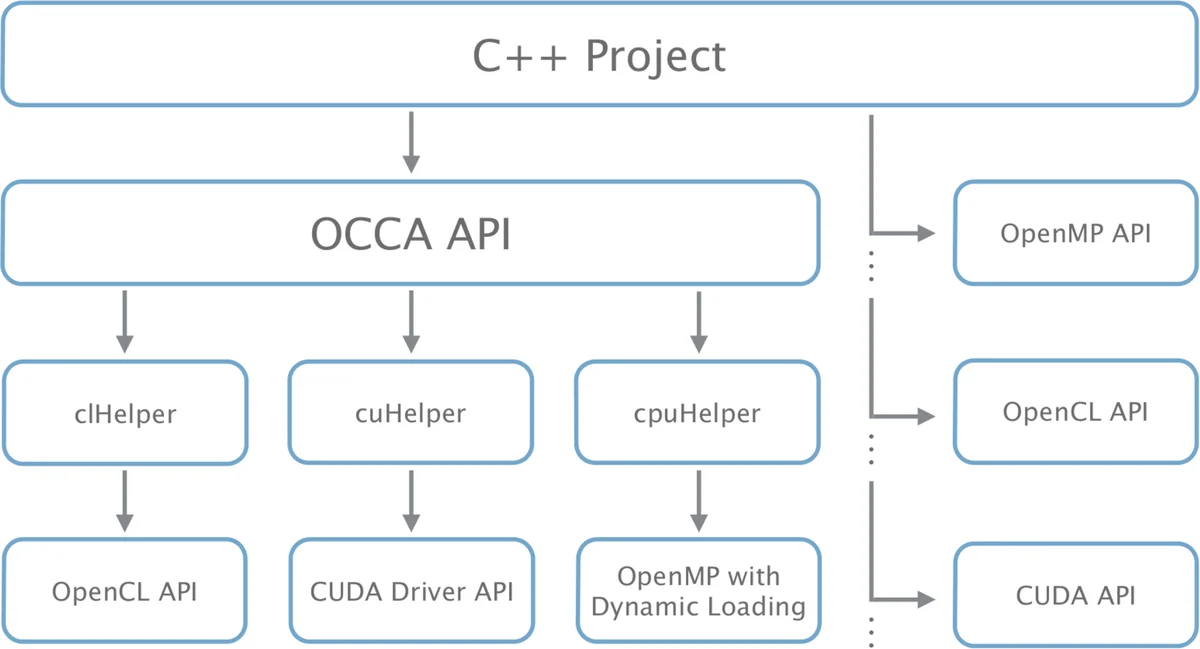
The inability to predict lasting languages and architectures led us to develop OCCA, a C++ library focused on host-device interaction. Using run-time compilation and macro expansions, the result is a novel single kernel language that expands to multiple threading languages. Currently, OCCA supports device kernel expansions for the OpenMP, OpenCL, and CUDA platforms. Computational results using finite difference, spectral element and discontinuous Galerkin methods show OCCA delivers portable high performance in different architectures and platforms.
💡 Research Summary
The paper addresses the growing difficulty of writing portable high‑performance code in an ecosystem where GPUs, many‑core CPUs, and accelerator cards such as Xeon Phi appear and disappear rapidly. Existing solutions either perform source‑to‑source translation (e.g., Swan, CU2CL) or provide high‑level APIs that hide the device but limit flexibility (e.g., ViennaCL, PyFR). The authors propose OCCA, a C++ library that abstracts both the host‑side device management and the kernel language itself, allowing a single kernel source to be compiled at run time into OpenMP, OpenCL, or CUDA code.
The OCCA host API consists of three classes: occaDevice, occaMemory, and occaKernel. occaDevice creates a self‑contained context and command queue for the chosen backend, handling memory allocation and kernel compilation. occaMemory wraps device‑specific memory handles while leaving explicit data movement to the programmer for performance control. occaKernel unifies function pointers (OpenMP), cl_kernel objects (OpenCL), and CUfunction objects (CUDA) behind a common interface; kernel launches receive grid and block dimensions through macro arguments.
The kernel side is built around a macro‑based “single kernel language”. Core macros such as occaOuterFor, occaInnerFor, occaBarrier, and occaShared express work‑group and work‑item loops, synchronization, and shared memory in a hardware‑agnostic way. When the target is OpenCL or CUDA, these macros expand to empty placeholders, preserving the native GPU execution model. For OpenMP, the same macros are replaced by #pragma omp parallel for constructs and explicit loop nests, effectively mapping GPU‑style parallelism onto thread‑based CPU execution. This approach eliminates the need for heavyweight source‑to‑source translators; the only transformation occurs during preprocessing, keeping the build pipeline simple and debugging straightforward.
Runtime compilation is performed via JIT for OpenCL and CUDA, while OpenMP kernels are compiled with the host compiler after macro substitution. Because the backend is chosen at runtime, adding a new language (e.g., SYCL, HIP, OpenMP 5.0) merely requires defining a new set of macros, preserving existing kernel code.
To validate the framework, the authors implement three numerical methods—finite‑difference, spectral‑element, and discontinuous‑Galerkin—using OCCA kernels. Benchmarks on a variety of platforms (Intel Xeon CPUs, AMD GPUs, NVIDIA GPUs, and Xeon Phi) show that OCCA‑generated kernels achieve performance comparable to hand‑written native code on each platform. The experiments demonstrate that a single source file can be compiled for all backends without code duplication, and that memory‑transfer overheads remain under programmer control.
The paper also discusses integration with external libraries, noting that OCCA’s host API is non‑intrusive and can coexist with other frameworks. By keeping the abstraction at the macro level, OCCA maintains fine‑grained control over synchronization (local vs. global barriers) and memory hierarchy (shared, local, global), which is essential for achieving high performance on modern GPUs.
In conclusion, OCCA offers a pragmatic solution to the portability‑performance trade‑off in heterogeneous computing. Its macro‑based kernel language, combined with a lightweight host API and runtime JIT compilation, enables developers to write once and run efficiently on multiple threading models. The framework’s design encourages extensibility, making it a valuable tool for current and future heterogeneous architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment