On Cloud-based Oversubscription
Rising trends in the number of customers turning to the cloud for their computing needs has made effective resource allocation imperative for cloud service providers. In order to maximize profits and reduce waste, providers have started to explore the role of oversubscribing cloud resources. However, the benefits of cloud-based oversubscription are not without inherent risks. This paper attempts to unveil the incentives, risks, and techniques behind oversubscription in a cloud infrastructure. Additionally, an overview of the current research that has been completed on this highly relevant topic is reviewed, and suggestions are made regarding potential avenues for future work.
💡 Research Summary
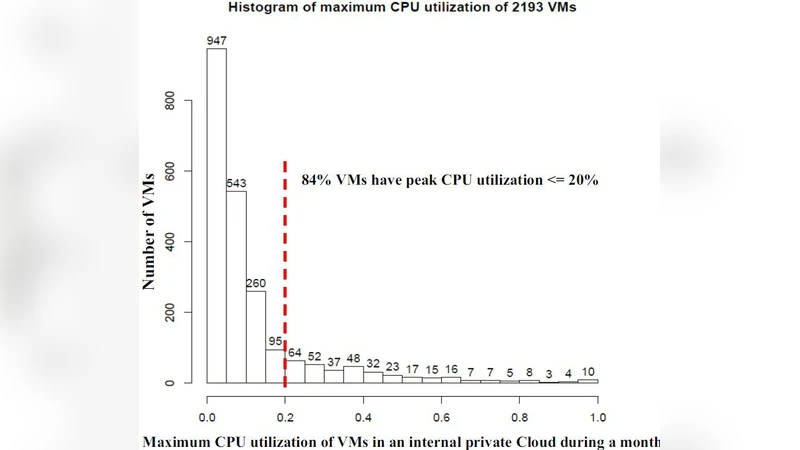
The rapid adoption of cloud computing has turned efficient resource allocation into a decisive factor for service providers seeking to stay competitive. This paper focuses on “oversubscription,” a strategy whereby providers allocate more virtual resources than the underlying physical capacity would normally allow, based on the observation that average utilization of CPU, memory, storage, and network bandwidth in data centers rarely exceeds 70 %. By deliberately over‑booking resources, providers can push utilization toward 90 % or higher, thereby increasing revenue per unit of fixed infrastructure cost.
The authors first outline the economic incentives behind oversubscription. They cite industry reports showing that idle capacity represents a substantial opportunity cost and that modest increases in the oversubscription ratio can yield double‑digit profit improvements without requiring additional hardware. However, they also stress that this approach introduces three primary categories of risk: performance degradation (e.g., increased latency, higher tail response times), reliability threats (e.g., SLA violations, service interruptions), and financial exposure (e.g., penalties, customer churn). The paper quantifies these risks using probabilistic models that map the likelihood of resource contention to oversubscription levels, showing that the probability of SLA breach rises sharply once the aggregate demand exceeds the physical limit by more than 20 %.
To mitigate these risks, the paper surveys four major technical pillars.
-
Predictive demand modeling – Machine‑learning techniques such as LSTM time‑series forecasting, Prophet, and Bayesian regression are employed to predict workload spikes at fine granularity (per‑minute or per‑second). The predicted demand distribution is then used to compute a safe oversubscription factor that adapts in real time.
-
Multi‑layer resource guarantees – Minimum guaranteed quotas are defined for each resource type (CPU cycles, memory pages, IOPS, network bandwidth). The “buffer pool” concept reserves a fraction of physical capacity that can be drawn upon when contention occurs, ensuring that high‑priority tenants always receive their baseline share.
-
Real‑time scheduling and elastic migration – When contention is detected, low‑priority virtual machines are live‑migrated to less‑loaded hosts, or containers are rescheduled using Kubernetes’ Horizontal Pod Autoscaler and Cluster Autoscaler. This dynamic redistribution reduces hot‑spot formation and keeps tail latency within SLA bounds.
-
Incentive‑aligned pricing and penalties – Tiered pricing schemes charge a premium for “burstable” resources while offering discounts for workloads that voluntarily accept lower guarantees. Penalty clauses are calibrated to make oversubscription costs visible to customers, encouraging them to provide accurate demand forecasts and to select appropriate priority levels.
The literature review is organized into three clusters. The first cluster consists of statistical and stochastic analyses that derive closed‑form expressions for the optimal oversubscription ratio under given confidence intervals. The second cluster presents system‑level prototypes built on hypervisors (Xen, KVM, VMware ESXi) and container orchestration platforms, demonstrating that average response times increase by only 5–15 % while overall utilization climbs to 85–95 %. The third cluster explores business‑model implications, including differential pricing, option contracts, and elasticity‑based billing, and shows how these mechanisms can shape tenant behavior toward more predictable usage patterns.
Finally, the authors outline several promising research directions. They argue that multi‑cloud and edge‑computing environments demand unified oversubscription policies that respect latency‑sensitive edge nodes while still exploiting central data‑center slack. They propose the use of reinforcement learning to continuously adjust oversubscription levels based on observed reward signals (e.g., profit vs. SLA compliance). They also call for investigations into security and privacy risks, such as side‑channel leakage amplified by resource sharing, and suggest hardened isolation techniques. Lastly, they highlight the potential to align oversubscription with sustainability goals, using energy‑aware scheduling to reduce the carbon footprint of over‑booked infrastructure.
In summary, oversubscription offers a compelling avenue for cloud providers to boost profitability and reduce waste, but it must be paired with robust predictive analytics, layered guarantees, agile scheduling, and carefully designed economic incentives. By integrating these components, providers can achieve a balanced strategy that maximizes resource efficiency while preserving the performance and reliability guarantees that customers expect.
Comments & Academic Discussion
Loading comments...
Leave a Comment