Self-healing networks: redundancy and structure
We introduce the concept of self-healing in the field of complex networks. Obvious applications range from infrastructural to technological networks. By exploiting the presence of redundant links in recovering the connectivity of the system, we introduce self-healing capabilities through the application of distributed communication protocols granting the “smartness” of the system. We analyze the interplay between redundancies and smart reconfiguration protocols in improving the resilience of networked infrastructures to multiple failures; in particular, we measure the fraction of nodes still served for increasing levels of network damages. We study the effects of different connectivity patterns (planar square-grids, small-world, scale-free networks) on the healing performances. The study of small-world topologies shows us that the introduction of some long-range connections in the planar grids greatly enhances the resilience to multiple failures giving results comparable to the most resilient (but less realistic) scale-free structures.
💡 Research Summary
The paper introduces a minimalist “self‑healing” framework for infrastructure‑type networks (e.g., power, water, gas, and communication grids). The authors assume that the operational network is a spanning tree (the “active tree”) rooted at a single source node, and that a set of dormant backup links (redundant edges) is pre‑installed but initially inactive. When a failure occurs—modelled as the random removal of k active links (a node failure is equivalent to removing all its incident links)—the subtree downstream of each broken link becomes disconnected and its nodes are unserved. Each node possesses only local knowledge: the identities of its immediate neighbours through either active or dormant links. A distributed routing protocol then attempts to reactivate a subset of the dormant links so as to reconstruct a new spanning tree that reconnects as many nodes as possible to the source. The performance metric is the fraction of served nodes (FoS) after recovery.
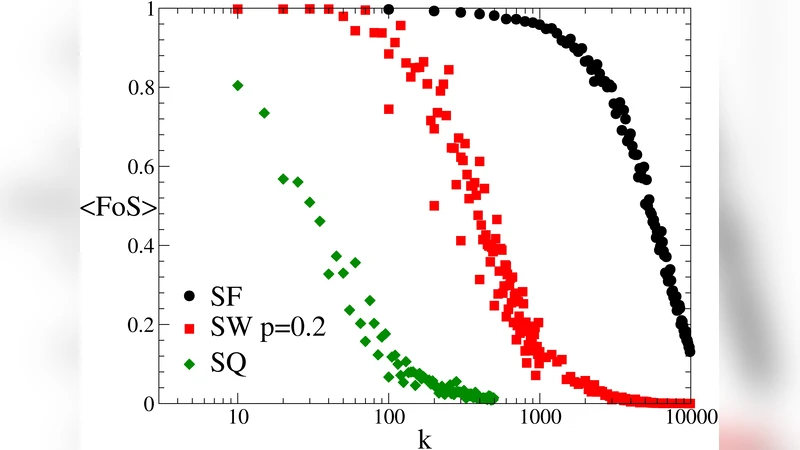
Three underlying topologies are examined on networks of size N = 10⁴: (i) a planar square grid (SQ), representing typical physical distribution networks; (ii) a scale‑free (SF) network generated by the Barabási‑Albert preferential‑attachment model; (iii) a small‑world (SW) network obtained by rewiring a fraction p of the grid edges according to the Watts‑Strogatz algorithm. For each topology, a random spanning tree is first selected as the active tree, and a fraction r of the remaining edges is designated as usable backup links. The authors vary r (0.1, 0.2, 0.3) and the number of simultaneous failures k (0 … 500) and record FoS.
Key findings:
- Square Grid (SQ): Even a modest redundancy (r ≈ 0.1) is sufficient to achieve near‑maximum recovery; FoS declines sharply with increasing k, but the dependence on r is weak. This reflects the regular geometry where a few long‑range shortcuts can reconnect most isolated subtrees.
- Scale‑Free (SF): Random failures are tolerated extremely well. With r = 0.1 the network can sustain up to k ≈ 400 failed links while still serving > 95 % of nodes. The hub‑centric architecture provides high error tolerance but makes the system highly vulnerable to targeted attacks on the hub—a classic SF property.
- Small‑World (SW): Introducing long‑range links (p = 0.2) dramatically improves resilience compared with the pure grid. FoS now shows a pronounced dependence on r; higher redundancy yields substantially higher recovery rates. The SW topology bridges the gap between the realistic SQ and the idealised SF, delivering robustness comparable to SF while remaining physically plausible.
A direct comparison with r fixed at 0.33 and p = 0.2 for SW shows that SF remains the most robust, but its implementation on planar infrastructures is impractical due to economic and spatial constraints. The SW approach, by adding a modest number of long‑range connections, offers a cost‑effective way to boost resilience of real distribution grids.
The authors emphasize that their protocol is implementable with existing routing technologies, requiring only local neighbour information and the ability to toggle pre‑installed backup links. They discuss extensions such as incorporating link capacities, multiple sources, dynamic load redistribution, and cold‑start scenarios (e.g., post‑black‑out restoration). The study underscores that strategic placement of a small set of long‑range redundant links can substantially increase the survivability of otherwise vulnerable planar networks, providing a practical design guideline for future resilient infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment