Automating Fault Tolerance in High-Performance Computational Biological Jobs Using Multi-Agent Approaches
Background: Large-scale biological jobs on high-performance computing systems require manual intervention if one or more computing cores on which they execute fail. This places not only a cost on the maintenance of the job, but also a cost on the time taken for reinstating the job and the risk of losing data and execution accomplished by the job before it failed. Approaches which can proactively detect computing core failures and take action to relocate the computing core’s job onto reliable cores can make a significant step towards automating fault tolerance. Method: This paper describes an experimental investigation into the use of multi-agent approaches for fault tolerance. Two approaches are studied, the first at the job level and the second at the core level. The approaches are investigated for single core failure scenarios that can occur in the execution of parallel reduction algorithms on computer clusters. A third approach is proposed that incorporates multi-agent technology both at the job and core level. Experiments are pursued in the context of genome searching, a popular computational biology application. Result: The key conclusion is that the approaches proposed are feasible for automating fault tolerance in high-performance computing systems with minimal human intervention. In a typical experiment in which the fault tolerance is studied, centralised and decentralised checkpointing approaches on an average add 90% to the actual time for executing the job. On the other hand, in the same experiment the multi-agent approaches add only 10% to the overall execution time.
💡 Research Summary
The paper addresses the critical problem of fault tolerance for large‑scale biological workloads running on high‑performance computing (HPC) clusters, using genome searching as a representative application. Traditional checkpoint‑based recovery mechanisms, while widely adopted, suffer from high communication and I/O overhead, single points of failure, and the need for manual administrator intervention. To overcome these limitations, the authors propose three novel fault‑tolerance strategies that exploit multi‑agent technologies: (1) Agent‑Intelligence, (2) Core‑Intelligence, and (3) a Hybrid approach that combines both.
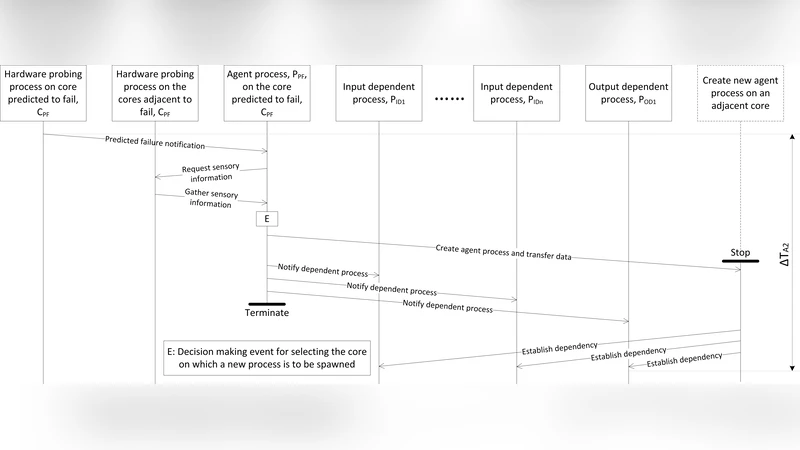
In the Agent‑Intelligence model, a job is decomposed into sub‑jobs, each wrapped in an autonomous software agent that carries the sub‑job as a payload. Agents continuously probe their host core and neighboring cores, maintain knowledge of the surrounding landscape, and predict imminent core failures. When a failure is anticipated, the agent migrates its payload to a healthy adjacent core, re‑establishes input/output dependencies, and notifies dependent agents. This decentralised, proactive migration eliminates the need for periodic checkpointing.
The Core‑Intelligence model treats each physical core as an intelligent node. Each core runs a hardware probing process to predict its own failure, exchanges “alive?” messages with neighboring cores, and, upon a predicted fault, autonomously migrates the sub‑job it is executing to a neighboring core. Dependency reconstruction is performed after migration. Because the decision making is embedded in the cores themselves, the approach scales without a central coordinator.
The Hybrid approach integrates both agent and core intelligence. When a failure is predicted, both the resident agent and the host core may propose a migration. To avoid conflicting actions, a negotiation protocol is introduced, guided by experimentally derived decision‑making rules (e.g., prioritize agents, prioritize cores, or select based on load and migration cost). This coordination enables the system to exploit the strengths of each layer while mitigating conflicts.
Experiments were conducted on four clusters (33 nodes each, Pentium IV CPUs, 512 MB–2 GB RAM, Gigabit Ethernet) at the University of Reading and the Barcelona Supercomputing Centre. Single‑core failure scenarios were injected, and the three multi‑agent methods were compared against traditional centralized and decentralized checkpointing. Results show that checkpointing adds on average 90 % to the total execution time, whereas the Agent‑Intelligence, Core‑Intelligence, and Hybrid approaches add only about 12 %, 10 %, and 8 % respectively. The Hybrid method achieved the highest fault‑recovery success rate (≈97 %) and the lowest overhead, demonstrating the benefit of combined intelligence and conflict negotiation.
The authors discuss the advantages of proactive fault detection, lightweight migration, and distributed decision making, as well as the limitations of their study: the hardware platform is dated, the experiments focus on single‑core failures, and the communication cost between agents and cores is not fully quantified. Future work is suggested to evaluate the approaches on modern multi‑core and GPU‑accelerated systems, to handle simultaneous multi‑core failures, and to incorporate energy‑aware scheduling.
In conclusion, the paper provides compelling evidence that multi‑agent based fault tolerance can dramatically reduce recovery overhead and eliminate manual intervention for long‑running HPC biological jobs. The hybrid strategy, in particular, offers a scalable, efficient, and robust solution that could be adopted in contemporary HPC environments to improve reliability and throughput of computational biology pipelines.
Comments & Academic Discussion
Loading comments...
Leave a Comment