Extracting Networks of Characters and Places from Written Works with CHAPLIN
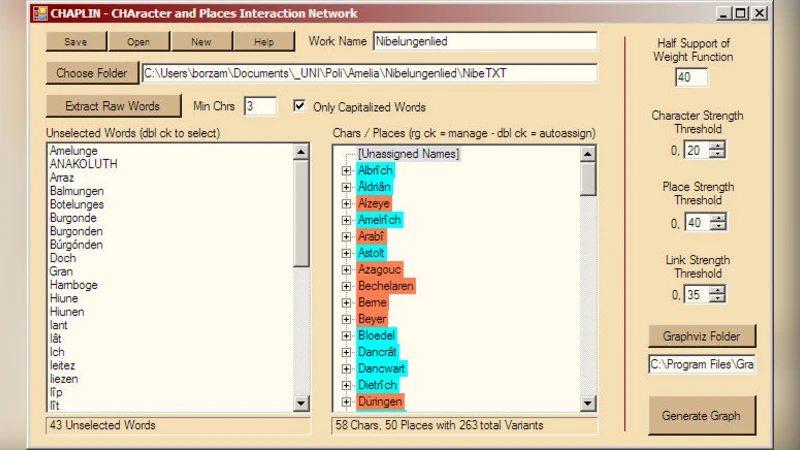
We are proposing a tool able to gather information on social networks from narrative texts. Its name is CHAPLIN, CHAracters and PLaces Interaction Network, implemented in VB.NET. Characters and places of the narrative works are extracted in a list of raw words. Aided by the interface, the user selects names out of them. After this choice, the tool allows the user to enter some parameters, and, according to them, creates a network where the nodes are the characters and places, and the edges their interactions. Edges are labelled by performances. The output is a GV file, written in the DOT graph scripting language, which is rendered by means of the free open source software Graphviz.
💡 Research Summary
The paper presents CHAPLIN (CHAracters and PLaces Interaction Network), a software tool designed to extract and visualize social networks embedded in narrative texts such as novels, historical chronicles, and screenplays. The authors begin by outlining the need for quantitative analysis of character and place interactions, noting that while many existing tools can visualize networks, they often lack integrated mechanisms for extracting entities from literary sources where names may appear in varied forms, be ambiguous, or be used metaphorically. CHAPLIN addresses this gap by combining automated preprocessing with a user‑driven selection interface, thereby creating a hybrid workflow that leverages human expertise to resolve ambiguous or variant name forms.
The preprocessing pipeline, implemented in VB.NET, tokenizes the input text, removes punctuation, and extracts candidate nouns and proper nouns using regular expressions. This produces a raw list of words that may correspond to characters, locations, or other entities. The user then interacts with a graphical interface to mark which items in the list are genuine characters or places, optionally adding synonyms or alternative spellings. These selections are stored in an internal dictionary that maps each canonical entity to its associated variants.
Once the entity set is defined, CHAPLIN computes pairwise interactions based on co‑occurrence within the same sentence or paragraph. Users can specify parameters such as a minimum co‑occurrence threshold, weighting factors for dialogue versus narrative mentions, and a “performance” metric that combines raw frequency with contextual importance. The tool iterates through the text, counts joint appearances, applies the user‑defined weights, and assigns a numeric strength to each edge. Nodes are sized and colored according to individual occurrence frequencies, while edge thickness and hue reflect interaction strength.
The final output is a Graphviz DOT file (GV format) that encodes the network structure, node attributes, and edge labels. Because DOT is a standard graph description language, the resulting file can be rendered by Graphviz into PNG, SVG, or other visual formats, allowing researchers to produce publication‑ready diagrams or to feed the data into further analytical pipelines such as Gephi or NetworkX.
To validate the system, the authors applied CHAPLIN to Shakespeare’s “Hamlet” and Mark Twain’s “Adventures of Huckleberry Finn.” In both cases, the tool successfully identified the main cast of characters and key locations despite the presence of multiple aliases (e.g., “Prince of Denmark,” “Polonius,” “Lord Polonius”). By setting a co‑occurrence threshold of three, the generated graphs highlighted central characters (Hamlet, Claudius, Ophelia; Huck, Jim, Tom) and revealed the structural backbone of the narratives—clusters of dialogue‑heavy interactions and pathways linking scenes across geographic settings. Quantitative analysis of edge weight distributions showed that a small subset of edges carried the majority of interaction weight, confirming the expected narrative focus on principal protagonists.
The discussion acknowledges several strengths: the interactive entity selection mitigates errors common in fully automated Named Entity Recognition on literary texts; the parameterizable weighting scheme allows researchers to tailor the network to specific analytical questions (e.g., emphasizing spoken dialogue versus descriptive narration). Limitations include dependence on the initial raw word list, which may miss entities if the underlying lexical resources are incomplete, and the potential for variability in results due to differing user selections, affecting reproducibility. The authors propose future enhancements such as integrating machine‑learning‑based NER modules to automate entity detection, extending support to multiple languages, and optimizing the system for large‑scale corpora.
In conclusion, CHAPLIN offers a practical, flexible solution for digital humanities scholars seeking to construct and explore character‑place interaction networks from narrative texts. Its combination of automated preprocessing, human‑in‑the‑loop entity validation, customizable interaction metrics, and standard DOT output makes it both accessible and extensible, positioning it as a valuable addition to the toolbox of literary network analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment