Improving Deep Neural Networks with Probabilistic Maxout Units
We present a probabilistic variant of the recently introduced maxout unit. The success of deep neural networks utilizing maxout can partly be attributed to favorable performance under dropout, when compared to rectified linear units. It however also …
Authors: Jost Tobias Springenberg, Martin Riedmiller
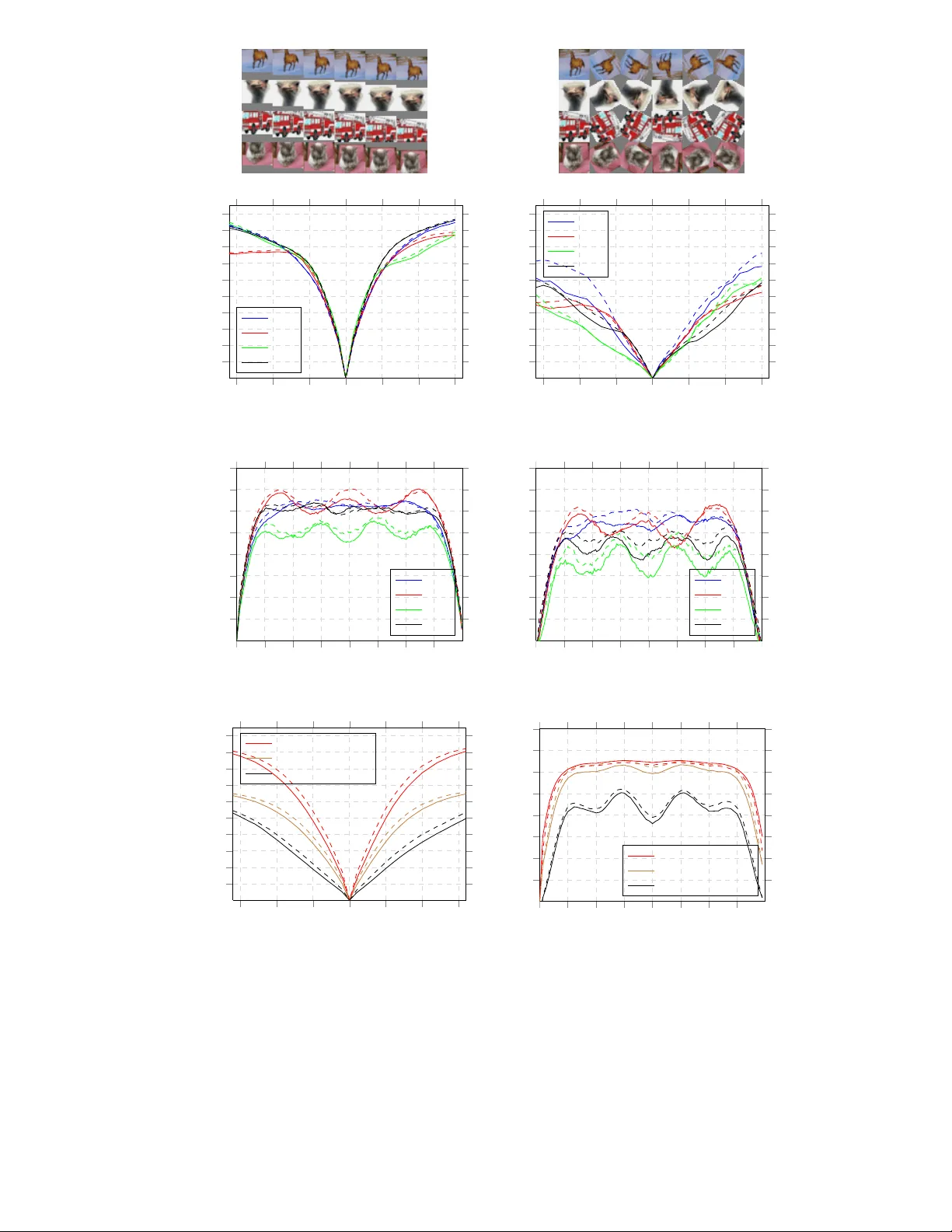
Impr oving Deep Neural Netw orks with Pr obabilistic Maxout Units Jost T obias Springenberg and Martin Riedmiller Department of Computer Science Univ ersity of Freib urg 79110, Freibur g im Breisgau, German y { springj,riedmiller } @cs.uni-freiburg.de Abstract W e present a probabilistic v ariant of the recently introduced maxout unit. The suc- cess of deep neural networks utilizing maxout can partly be attributed to f av orable performance under dropout, when compared to rectified linear units. It howe ver also depends on the fact that each maxout unit performs a pooling operation ov er a group of linear transformations and is thus partially in v ariant to changes in its input. Starting from this observ ation we ask the question: Can the desirable prop- erties of maxout units be preserved while improving their in v ariance properties ? W e argue that our probabilistic maxout ( pr obout ) units successfully achieve this balance. W e quantitatively v erify this claim and report classification performance matching or exceeding the current state of the art on three challenging image clas- sification benchmarks (CIF AR-10, CIF AR-100 and SVHN). 1 Introduction Regularization of large neural networks through stochastic model a veraging was recently shown to be an ef fecti ve tool against ov erfitting in supervised classification tasks. Dropout [1] w as the first of these stochastic methods which led to improv ed performance on several benchmarks ranging from small to large scale classification problems [2, 1]. The idea behind dropout is to randomly drop the activ ation of each unit within the network with a probability of 50% . This can be seen as an extreme form of bagging in which parameters are shared among models, and the number of trained models is exponential in the number of these model parameters. During testing an approximation is used to av erage ov er this large number of models without instantiating each of them. When combined with efficient parallel implementations this procedure opened the possibility to train large neural networks with millions of parameters via back-propagation [2, 3] . Inspired by this success a number of other stochastic regularization techniques were recently de vel- oped. This includes the work on dropconnect[4], a generalization of dropout, in which connections between units rather than their activ ation are dropped at random. Adaptiv e dropout [5] is a recently introduced variant of dropout in which the stochastic regularization is performed through a binary belief network that is learned alongside the neural network to decrease the information content of its hidden units. Stochastic pooling [6] is a technique applicable to con volutional networks in which the pooling operation is replaced with a sampling procedure. Instead of changing the regularizer the authors in [7] searched for an activ ation function for which dropout performs well. As a result they introduced the maxout unit, which can be seen as a gen- eralization of rectified linear units (ReLUs) [8, 9], that is especially suited for the model av eraging performed by dropout. The success of maxout can partly be attributed to the fact that maxout aids the optimization procedure by partially preventing units from becoming inacti ve; an artifact caused by the thresholding performed by the rectified linear unit. Additionally , similar to ReLUs, they are 1 piecewise linear and – in contrast to e.g. sigmoid units – typically do not saturate, which makes networks containing maxout units easier to optimize. W e argue that an equally important property of the maxout unit ho wev er is that its activ ation func- tion can be seen as performing a pooling operation ov er a subspace of k linear feature mappings (in the following referred to as subspace pooling). As a result of this subspace pooling operation each maxout unit is partially in variant to changes within its input. A natural question arising from this observation is thus whether it could be beneficial to replace the maximum operation used in maxout units with other pooling operations, such as L2 pooling. The utility of different subspace pooling operations has already been e xplored in the context of unsupervised learning where e.g. L2-pooling is known give rise to interesting inv ariances [10, 11, 12]. While work on generalizing maxout by replacing the max-operation with general Lp -pooling exists [13], a de viation from the standard max- imum operation comes at the price of discarding some of the desirable properties of the maxout unit. For e xample abandoning piece wise linearity , restricting units to positi ve values and the introduction of saturation regimes, which potentially worsen the accuracy of the approximate model averaging performed by dropout. Based on these observations we propose a stochastic generalization of the maxout unit that pre- serves its desirable properties while improving the subspace pooling operation of each unit. As an additional benefit when training a neural network using our proposed probabilistic maxout units the gradient of the training error is more evenly distributed among the linear feature mappings of each unit. In contrast, a maxout network helps gradient flow through each of the maxout units but not through their k linear feature mappings. Compared to maxout our probabilistic units thus learn to better utilize their full k-dimensional subspace. W e ev aluate the classification performance of a model consisting of these units and show that it matches the state of the art performance on three challenging classification benchmarks. 2 Model Description Before defining the probabilistic maxout unit we briefly re view the notation used in the follo wing for defining deep neural network models. W e adopt the standard feed-forward neural network formula- tion in which giv en an input x and desired output y (a class label) the network realizes a function computing a C -dimensional vector o – where C is the number of classes – predicting the desired output. The prediction is computed by first sequentially mapping the input to a hierarchy of N hid- den layers h (1) , . . . , h ( N ) . Each unit h ( l ) i within hidden layer l ∈ [1 , N ] in the hierarchy realizes a function h ( l ) i ( v ; w ( l ) i , b ( l ) i ) mapping its inputs v (given either as the input x or the output of the previous layer h ( l − 1) ) to an activ ation using weight and bias parameters w ( l ) i and b ( l ) i . Finally the prediction is computed based on the last layer output h N . This prediction is realized using a softmax layer o = sof tmax ( W N +1 h ( N ) + b N +1 ) with weights W N +1 and bias b N +1 . All parameters θ = { W (1) , b (1) , . . . , W ( N +1) , b ( N +1) } are then learned by minimizing the cross entropy loss be- tween output probabilities o and label y : L ( o, y ; x ) = − P C i =1 y i log( o i ) + (1 − y i ) log (1 − o i ) . 2.1 Probabilistic Maxout Units The maxout unit was recently introduced in [7] and can be formalized as follows: Gi ven the units input v ∈ R d (either the activ ation from the previous layer or the input vector) the activ ation of a maxout unit is computed by first computing k linear feature mappings z ∈ R k where z i = w i v + b i , (1) and k is the number of linear sub-units combined by one maxout unit. Afterwards the output h maxout of the maxout hidden unit is giv en as the maximum ov er the k feature mappings: h maxout ( v ) = max[ z 1 , . . . , z k ] . (2) When formalized like this it becomes clear that (in contrast to con v entional acti v ation functions) the maxout unit can be interpreted as performing a pooling operation over a k-dimensional subspace of linear units [ z 1 , . . . , z k ] each representing one transformation of the input v . This is similar to spatial max-pooling which is commonly employed in conv olutional neural networks. Howe v er , unlike in 2 1.8 0.9 0.1 -0.5 max 1.8 a) Image b) spa tial pooling c) max out (subs pace pooling) fi lter fi lters 0.8 -0.3 max 0.8 fi lters 0.8 -0.3 0.8 z z 0.75 0.25 sa mple : i ~ e.g. i = 1 d) pr obout (subs pace pooling) pr obabilities Figure 1: Schematic of different pooling operations. a) An exemplary input image taken from the ImageNet dataset together with the depiction of a spatial pooling region (cyan) as well as the input to one maxout / probout unit (marked in magenta). b) Spatial max-pooling proceeds by computing the maximum of one filter response at the four different positions from a). c) Maxout computes a pooled response of two linear filter mappings applied to one input patch. d) The activ ation of a probout unit is computed by sampling one of the linear responses according to their probability . spatial pooling the maxout unit pools ov er a subspace of k different linear transformations applied to the same input v . In contrast to this, spatial max-pooling of linear feature maps would compute a pooling ov er one linear transformation applied to k different inputs. A schematic of the dif ference between sev eral pooling operations is gi ven in Fig. 1 . As such maxout is thus more similar to the subspace pooling operations used for example in topo- graphic ICA [10] which is known to result in partial in v ariance to changes within its input. On the basis of this observ ation we propose a stochastic generalization of the maxout unit that preserves its desirable properties while improving gradient propagation among the k linear feature mappings as well as the in v ariance properties of each unit. In the following we call these generalized units pr obout units since they are a direct probabilistic generalization of maxout. W e deriv e the probout unit activ ation function from the maxout formulation by replacing the maxi- mum operation in Eq. (2) with a probabilistic sampling procedure. More specifically we assume a Boltzmann distribution over the k linear feature mappings and sample the acti v ation h ( v ) from the activ ation of the corresponding subspace units. T o this end we first define a probability for each of the k linear units in the subspace as: p i = e λz i P k j =1 e λz j , (3) where λ is a hyperparameter (referred to as an inv erse temperature parameter) controlling the vari- ance of the distribution. The acti vation h probout ( x ) is then sampled as h probout ( v ) = z i , where i ∼ M ultinomial { p 1 , . . . , p k } . (4) Comparing Eq. (4) to Eq. (2) we see that both, are not bounded from above or belo w and their activ ation is always giv en as one of the linear feature mappings within their subspace. The probout unit hence preserves most of the properties of the maxout unit, only replacing the sub-unit selection mechanism. W e can further see that Eq. (4) reduces to the maxout activ ation for λ → ∞ . For other values of λ the probout unit will behave similarly to maxout when the activ ation of one linear unit in the subspace dominates. Howe ver , if the acti v ation of multiple linear units dif fers only slightly they will be selected with almost equal probability . Futhermore, each acti ve linear unit will have a chance to be selected. The sampling approach therefore ensures that gradient flows through each of the k linear subspace units of a gi ven probout unit for some examples (given that λ is sufficiently small). W e hence argue that probout units can learn to better utilize their full k-dimensional subspace. In practice we want to combine the probout units described by Eq. (4) with dropout for re gularizing the learned model. T o achiev e this we directly include dropout in the probabilistic sampling step by 3 re-defining the probabilities as: ˆ p 0 = 0 . 5 (5) ˆ p i = e λz i 2 · P k j =1 e λz j . (6) Consequently , we sample the probout activ ation function including dropout ˆ h probout ( v ) as ˆ h probout ( v ) = 0 if i = 0 z i else , where i ∼ M ultinomial { ˆ p 0 , ˆ p 1 , . . . , ˆ p k } . (7) 2.2 Relation to other pooling operations The idea of using a stochastic pooling operation has been explored in the context of spatial pooling within the machine learning literature before. Among this work the approach most similar to ours is [14]. There the authors introduced a probabilistic pooling approach in order to deriv e a conv olutional deep believe network (DBN). They also use a Boltzmann distribution based on unit activ ations to calculate a sampling probability . The main difference between their work and ours is that they calculate the probability of sampling one unit at different spatial locations whereas we calculate the probability of sampling a unit among k units forming a subspace at one spatial location. Another difference is that we forward propagate the sampled activ ation z i whereas they use the calculated probability to activ ate a binary stochastic unit. Another approach closely related to our w ork is the stochastic pooling presented in [6]. Their stochastic pooling operation samples the activ ation of a pooling unit p i proportionally to the ac- tiv ation a of a rectified linear unit [8] computed at different spatial positions. This is similar to Eq. (4) in the sense that the activ ation is sampled from a set of different activ ations. Similar to [14] it howe v er differs in that the sampling is performed over spatial locations rather than acti v ations of different units. It should be noted that our work also bears some resemblance to recent work on training stochastic units, embedded in an autoencoder network, via back-propagation [15, 16]. In contrast to their w ork, which aims at using stochastic neurons to train a generative model, we embrace stochasticity in the subspace pooling operation as an effecti v e means to regularize a discriminati v e model. 2.3 Inference At test time we need to account for the stochastic nature of a neural network containing probout units. During a forward pass through the network the v alue of each probout unit is sampled from one of k values according to their probability . The output of such a forward pass thus alw ays represents only one of k M different instantiations of the trained probout netw ork; where M is the number of probout units in the network. When combined with dropout the number of possible instantiations increases to ( k + 1) M . Evaluating all possible models at test time is therefore clearly infeasible. The Dropout formulation from [1] deals with this large amount of possible models by removing dropout at test time and halving the weights of each unit. If the network consists of only one softmax layer then this modified network performs exact model averaging [1]. For general models this computation is merely an approximation of the true model av erage which, howe ver , performs well in practice for both deep ReLU networks [2] and the maxout model [7]. W e adopt the same procedure of halving the weights for removing the influence of dropout at test- time and rescale the probabilities such that P k i =1 ˆ p i = 1 and ˆ p 0 = 0 , ef fecti vely replacing the sampling from Eq .(7) with Eq. (4). W e further observe that from the k M models remaining after removing dropout only few models will be instantiated with high probability . W e therefore resort to sampling a small number of outputs o from the networks softmax layer and average their values. An ev aluation of the e xact ef fect of this model av eraging can be found in Section 3.1.1 . 3 Evaluation W e ev aluate our method on three different image classification datasets (CIF AR-10, CIF AR-100 and SVHN) comparing it against the basic maxout model as well as the current state of the art on 4 w 1 w 2 w 1 w 2 Figure 2: V isualization of pairs of first layer linear filters learned by the maxout model (left) as well as the probout model (right). In contrast to the maxout filters the filter pairs learned by the probout model appear to mostly be transformed versions of each other . all datasets. All experiments were performed using an implementation based on Theano and the pylearn2 library [17] using the fast conv oltion code of [2]. W e use mini-batch stochastic gradient descent with a batch size of 100. For each of the datasets we start with the same network used in [7] – retaining all of their hyperparameter choices – to ensure comparability between results. W e replace the maxout units in the network with probout units and choose one λ ( l ) via crossvalidation for each layer l in a preliminary experiment on CIF AR-10. 3.1 Experiments on CIF AR-10 W e begin our experiments with the CIF AR-10 [18] dataset. It consists of 50 , 000 training images and 10 , 000 test images that are grouped into 10 cate gories. Each of these images is of size 32 × 32 pixels and contains 3 color channels. Maxout is kno wn to yield good performance on this dataset, making it an ideal starting point for ev aluating the dif ference between maxout and probout units. 3.1.1 Effect of replacing maxout with pr obout units W e conducted a preliminary experiment to ev aluate the effect of the probout parameters λ ( l ) on the performance and compare it to the standard maxout model. For this purpose we use a fi ve layer model consisting of three con volutional layers with 48, 128 and 128 probout units respecti vely which pool o ver 2 linear units each. The penultimate layer then consists of 240 probout units pooling ov er a subspace of 5 linear units. The final layer is a standard softmax layer mapping from the 240 units in the penultimate layer to the 10 classes of CIF AR-10. The receptiv e fields of units in the con v olutional layers are 8, 8 and 5 respectiv ely . Additionally , spatial max-pooling is performed after each con volutional layer with pooling size of 4 × 4 , 4 × 4 and 2 × 2 using a stride of 2 in all layers. W e split the CIF AR-10 training data retaining the first 40000 samples for training and using the last 10000 samples as a validation set. W e start our ev aluation by using probout units ev erywhere in the network and cross-validate the choice of the in verse-temperature parameters λ ( l ) ∈ { 0 . 1 , 0 . 5 , 1 , 2 , 3 , 4 } keeping all other hyperpa- rameters fixed. W e find that annealing the λ ( l ) parameter during training to a lo wer value improv ed performance for all λ ( l ) > 0 . 5 and hence linearly decrease λ ( l ) to a v alue that is 0 . 9 lower than the initial λ in these cases. As shown in Fig. 3a the best classification performance is achiev ed when λ is set to allow higher variance sampling for the first two layers, specifically when λ (1) = 1 and λ (2) = 2 . For the third as well as the fully connected layer we observ e a performance increase when λ (3) is chosen as λ (3) = 3 and λ (4) = 4 , meaning that the sampling procedure selects the maximum value with high probability . This indicates that the probabilistic sampling is most effecti ve in lo wer layers. W e v erified this by replacing the probout units in the last two layers with maxout units which did not significantly decrease classification accuracy . W e hypothesize that increasing the probability of sampling a non maximal linear unit in the subspace pulls the units in the subspace closer together and forces the network to become “more in variant” to changes within this subspace. This is a property that is desired in lower layers but might turn to be detrimental in higher layers where the model averaging effect of maxout is more important than achieving inv ariance. Here sampling units with non-maximal acti vation could result in unwanted correlation between the “submodels”. T o qualitatively v erify this claim we plot the first layer linear filters learned using probout units alongside the filters learned by a model consisting only of maxout 5 0 . 1 0 . 5 1 2 3 4 12 . 5 12 . 6 12 . 7 12 . 8 12 . 9 13 13 . 1 13 . 2 13 . 3 13 . 4 λ ( l ) Class. Error (validation set) l = 2 (with λ (1) = 1 ) l = 1 (with λ (2) = 2 ) (a) 1 510 20 30 40 50 60 70 80 90 100 13 14 15 Model ev aluations Classification error Maxout baseline Probout Maxout + sampling (b) Figure 3: (a) V alidation of the λ ( l ) parameter for layers l ∈ [1 , 2] on CIF AR-10. W e plot the error on the validation set after training (using 50 model e v aluations). When e valuating the choice of λ (1) (red curve) the second parameter fix ed λ (2) = 2 . Likewise, for the experiments regarding λ (2) (blue curve) λ (1) = 1 . (b) Evolution of the classification error and standard deviation on the CIF AR- 10 dataset for a changing number E of model ev aluations. W e average the activ ation o ∈ R C of the softmax layer over all E ev aluations and compute the predicted class label ˆ y as the maximum ˆ y = arg max i ∈{ 1 ,...,C } o i . The standard de viation is computed o ver 10 runs of E model ev aluations. units in Fig. 2. When inspecting the filters we can see that many of the filters belonging to one subspace formed by a probout unit seem to be transformed v ersions of each other , with some of then resembling “quadrature pairs” of filters. Among the linear filters learned by the maxout model some also appear to encode in v ariance to local transformations. Most of the filters contained in a subspace howe v er are seemingly unrelated. T o support this observation empirically we probed for changes in the feature vectors of different layers (extracted from both maxout and probout models) when they are applied to translated and rotated images from the validation set. Similar to [19, 3] we calculate the normalized Euclidean distance between feature vectors extracted from an unchanged image and a transformed version. W e then plot these distances for sev eral exemplary images as well as the mean over 100 randomly sampled images. The result of this experiment is given in Fig. 4, showing that introducing probout units into the network has a moderate positive effect on both inv ariance to translation and rotations. Finally , we ev aluate the computational cost of the model averaging procedure described in Section 2.3 at test time. As depicted in Fig. 3b the classification error for the probout model decreases with more model ev aluations saturating when a moderate amount of 50 e v aluations is reached. Con- versely , using sampling at test time in conjunction with the standard maxout model significantly decreases performance. This indicates that the maxout model is highly optimized for the maximum responses and cannot deal with the noise introduced through the sampling procedure. W e addition- ally also tried to replace the model averaging mechanism with cheaper approximations. Replacing the sampling in the probout units with a maximum operation at test time resulted in a decrease in performance, reaching 14 . 13% . W e also tried to use probability weighting during testing [6] which howe v er performed e ven worse, achie ving 15 . 21% . 3.1.2 Evaluation of Classification P erformance As the next step, we ev aluate the performance of our model on the full CIF AR-10 benchmark. W e follow the same protocol as in [7] to train the probout model. That is, we first preprocess all images by applying contrast normalization followed by ZCA whitening. W e then train our model using the first 40000 examples from the training set using the last 10000 examples as a v alidation set. T raining then proceeds until the v alidation error stops decreasing. W e then retrain the model on the complete training set for the same amount of epochs it took to reach the best validation error . T o comply with the experiments in [7] we used a larger version of the model from Section 3.1.1 in all experiments. Compared to the preliminary experiment the size of the con volutional layers was 6 T able 1: Classification error of different models on the CIF AR-10 dataset. M E T HO D E R RO R C O N V . N E T + S P E A R M IN T [ 2 0] 1 4 . 98 % C O N V . N E T + M A X O U T [ 7 ] 1 1 . 69 % C O N V . N E T + P R OB O U T 1 1 . 35 % 1 2 × C O N V . N E T + D RO P C ON N E C T [ 4 ] 9 . 3 2 % C O N V . N E T + M A X O U T [ 7 ] 9 . 3 8 % C O N V . N E T + P R OB O U T 9 . 3 9 % increased to 96 , 192 and 192 units respectively . The size of the fully connected layer was increased to 500 probout units pooling ov er a 5 dimensional subspace. The top half of T able 1 shows the result of training this model as well as other recent results. W e achiev e an error of 11 . 35% , slightly better than – but statistically tied to – the previous state of the art giv en by the maxout model. W e also ev aluated the performance of this model when the training data is augmented with additional transformed training examples. For this purpose we train our model using the original training images as well as add randomly translated and horizontally flipped versions of the images. The bottom half of T able 1 sho ws a comparison of dif ferent results for training on CIF AR-10 with additional data augmentation. Using this augmentation process we achiev e a classification error of 9 . 39% , matching, b ut not outperforming the maxout result. 3.2 CIF AR-100 The images contained in the CIF AR-100 dataset [18] are – just as the CIF AR-10 images – taken from a subset of the 10-million images database. The dataset contains 50 , 000 training and 10 , 000 test e xamples of size 32 × 32 pixels each. The dataset is hence similar to CIF AR-10 in both size and image content. It, howe ver , dif fers from CIF AR-10 in its label distribution. Concretely , CIF AR-100 contains images of 100 classes grouped into 20 “super -classes”. The training data therefore contains 500 training images per class – 10 times less examples per class than in CIF AR-10 – which are accompanied by 100 examples in the test-set. W e do not make use of the 20 super-classes and train a model using a similar setup to the experiments we carried out on CIF AR-10. Specifically , we use the same preprocessing and training procedure (determining the amount of epochs using a validation set and then retraining the model on the com- plete data). The same network as in Section 3.1.1 was used for this experiment (adapted to classify 100 classes). Again, this is the same architecture used in [7] thus ensuring comparability between results. During testing we use 50 model ev aluations to av erage ov er the sampled pr obout units. The result of this experiment is gi ven in T able 2. In agreement with the CIF AR-10 results our model performs marginally better than the maxout model (by 0 . 45% 1 ). As also shown in the table the current best method on CIF AR-100 achie ves a classification error of 36 . 85% [21], using a larger con v olutional neural network together with a tree-based prior on the classes formed by utilizing the super-classes. A similar performance increase could potentially be achieved by combining their tree-based prior with our model. 3.3 SVHN The street view house numbers dataset [22] is a collection of images depicting digits which were obtained from google street view images. The dataset comes in two variants of which we restrict ourselves to the one containing cropped 32 × 32 pixel images. Similar to the well known MNIST dataset [23] the task for this dataset is to classify each image as one of 10 digits in the range from 0 to 9. The task is considerably more dif ficult than MNIST since the images are cropped out of natural image data. The images thus contain color information and show significant contrast vari- 1 While we were writing this manuscript it came to our attention that the experiments on CIF AR-100 in [7] were carried out using a different preprocessing than mentioned in the original paper . T o ensure that this does not substantially effect our comparison we ran their experiment using the same preprocessing used in our experiments. This resulted in a slightly improved classification error of 38 . 50% . 7 T able 2: Classification error of different models on the CIF AR-100 dataset. M E T HO D E R RO R R E C EP T I V E F I E L D L E AR N I N G [ 2 4 ] 4 5 . 17 % L E A RN E D P O O L I N G [ 2 5] 4 3 . 71 % C O N V . N E T + S T O C HA S T I C P O O L IN G [ 6 ] 4 2 . 5 1 % C O N V . N E T + D R O P O U T + T R E E [ 2 1 ] 3 6 . 8 5 % C O N V . N E T + M A X O U T [ 7 ] 3 8 . 5 7 % C O N V . N E T + P R O B O U T 3 8 . 1 4 % ation. Furthermore, although centered on one digit, several images contain multiple visible digits, complicating the classification task. The training and test set contain 73 , 257 and 20 , 032 labeled examples respectively . In addition to this data there is an “extra” set of 531 , 131 labeled digits which are somewhat less difficult to differentiate and can be used as additional training data. As in [7] we build a validation set by selecting 400 examples per class from the training and 200 e xamples per class from the e xtra dataset. W e conflate all remaining training images to a lar ge set of 598 , 388 images which we use for training. The model trained for this task consists of three con v olutional layers containing 64, 128 and 128 units respectively , pooling over a 2 dimensional subspace. These are follo wed by a fully connected and a softmax layer of which the fully connected layer contains 400 units pooling over a 5 dimen- sional subspace. This yields a classification error of 2 . 39% (using 50 model ev aluations at test- time), matching the current state of the art for a model trained on SVHN without data augmentation achiev ed by the maxout model ( 2 . 47% ). A comparison to other results can be found in T able 3 . This includes the current best result with data augmentation which was obtained using a generalization of dropout in conjunction with a large netw ork containing rectified linear units [4]. T able 3: Classification error of dif ferent models on the SVHN dataset. The top half sho ws a compar- ison of our result with the current state of the art achieved without data augmentation. The bottom half giv es the best performance achie ved with data augmentation as additional reference. M E T H O D E R R O R C O N V . N E T + S T O C H A S T I C P O O L I N G [ 6 ] 2 . 8 0 % C O N V . N E T + D R O P O U T [ 2 6 ] 2 . 7 8 % C O N V . N E T + M A X O U T [ 7 ] 2 . 4 7 % C O N V . N E T + P R O B O U T 2 . 3 9 % C O N V . N E T + D R O P O U T [ 2 6 ] 2 . 6 8 % 5 × C O N V . N E T + D R O P C O N N E C T [ 4 ] 1 . 9 3 % 4 Conclusion W e presented a probabilistic version of the recently introduced maxout unit. A model built using these units was shown to yield competiti ve performance on three challenging datasets (CIF AR-10, CIF AR-100, SVHN). As it stands, replacing maxout units with probout units is computationally expensi ve at test time. This problem could be diminished by developing an approximate inference scheme similar to [2, 3] which we see as an interesting possibility for future work. W e see our approach as part of a larger body of work on exploring the utility of learning “complex cell like” units which can gi ve rise to interesting in v ariances in neural networks. While this paradigm has extensiv ely been studied in unsupervised learning it is less explored in the supervised scenario. W e believ e that w ork tow ards building activ ation functions incorporating such in variance properties, while at the same time designed for use with ef ficient model averaging techniques such as dropout, is a worthwhile endea vor for adv ancing the field. Acknowledgments The authors want to thank Alexe y Dosovistkiy for helpful discussions and comments, as well as Thomas Brox for generously providing additional computing resources. 8 References [1] Alex Krizhe vsky Ilya Sutsk ev er Ruslan R. Salakhutdino v Geoffre y E. Hinton, Nitish Sri v astav a. Improv- ing neural networks by pre venting co-adaptation of feature detectors. arxiv:cs/1207.0580v3. [2] Alex Krizhevsk y , Ilya Sutskev er , and Geoff Hinton. Imagenet classification with deep con volutional neural networks. In Advances in Neural Information Processing Systems 25 . 2012. [3] Matthew Zeiler and Rob Fergus. V isualizing and understanding con volutional networks. arxiv:cs/1311.2901v3. [4] Li W an, Matthew D. Zeiler, Sixin Zhang, Y ann LeCun, and Rob Fer gus. Regularization of neural networks using dropconnect. In International Conference on Machine Learning (ICML) , 2013. [5] Jimmy Ba and Brendan Fre y . Adaptiv e dropout for training deep neural networks. In Advances in Neur al Information Pr ocessing Systems 26 . 2013. [6] Matthew D. Zeiler and Rob Fergus. Stochastic pooling for regularization of deep con v olutional neural networks. In International Confer ence on Learning Repr esentations (ICLR): W orkshop track , 2013. [7] Ian J. Goodfellow , David W arde-Farley , Mehdi Mirza, Aaron Courville, and Y oshua Bengio. Maxout networks. In International Confer ence on Machine Learning (ICML) , 2013. [8] V inod Nair and Geoffre y E. Hinton. Rectified linear units improve restricted boltzmann machines. In International Conference on Machine Learning (ICML) , 2010. [9] Xavier Glorot, Antoine Bordes, and Y oshua Bengio. Deep sparse rectifier neural networks. In AIST A TS 2011 , April 2011. [10] Jarmo Hurri Aapo Hyvrinen and Patrik O. Hoyer . Natural Image Statistics . [11] Y oshua Bengio and James S. Bergstra. Slow , decorrelated features for pretraining complex cell-like networks. In Advances in Neural Information Processing Systems 22 . 2009. [12] Will Y . Zou, Shenghuo Zhu, Andre w Y . Ng, and Kai Y u. Deep learning of in v ariant features via simulated fixations in video. In Neural Information Processing Systems (NIPS 2012) , 2012. [13] Razvan Pascanu Y oshua Bengio Caglar Gulcehre, K yunghyun Cho. Learned-norm pooling for deep neural networks. arxiv:stat/1311.1780v3. [14] Honglak Lee, Roger Grosse, Rajesh Ranganath, and Andrew Y Ng. Con volutional deep belief networks for scalable unsupervised learning of hierarchical representations. pages 1–8, 2009. [15] Y oshua Bengio. Estimating or propagating gradients through stochastic neurons. [16] Jason Y osinski Y oshua Bengio, ric Thibodeau-Laufer . Deep generativ e stochastic networks trainable by backprop. [17] Pascal Lamblin V incent Dumoulin Mehdi Mirza Razvan Pascanu James Bergstra Frdric Bastien Y oshua Bengio Ian J. Goodfello w , David W arde-F arley . Pylearn2: a machine learning research library . arxiv:stat/1308.4214. [18] A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. 2009. [19] Koray Kavukcuoglu, Marc’Aurelio Ranzato, Rob Fergus, and Y ann LeCun. Learning inv ariant features through topographic filter maps. In Pr oc. International Conference on Computer V ision and P attern Recognition (CVPR) , 2009. [20] Jasper Snoek, Hugo Larochelle, and Ryan Prescott Adams. Practical bayesian optimization of machine learning algorithms. In Advances in Neural Information Pr ocessing Systems 25 , 12/2012 2012. [21] Nitish Srivasta v a and Ruslan Salakhutdinov . Discriminative transfer learning with tree-based priors. In Advances in Neur al Information Pr ocessing Systems 26 , pages 2094–2102. 2013. [22] Y uval Netzer, T ao W ang, Adam Coates, Alessandro Bissacco, Bo W u, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. In NIPS W orkshop on Deep Learning and Unsupervised F eatur e Learning 2011 , 2011. [23] Y ann LeCun, Lon Bottou, Y oshua Bengio, and Patrick Haf fner . Gradient-based learning applied to docu- ment recognition. In Pr oceedings of the IEEE , number 11, 1998. [24] Y angqing Jia, Chang Huang, and T rev or Darrell. Beyond spatial pyramids: Receptiv e field learning for pooled image features. In CVPR , 2012. [25] Mateusz Malino wski and Mario Fritz. Learnable pooling re gions for image classification. In International Confer ence on Learning Repr esentations (ICLR): W orkshop tr ack , 2013. [26] Nitish Sriv astav a. Improving neural networks with dropout. In Master’ s thesis, University of T oronto, 2013. 9 (a) (b) − 15 − 10 − 5 0 5 10 15 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 1 . 8 2 V ertical translation (pixels) Distance Horse Bird Truck Cat (c) − 15 − 10 − 5 0 5 10 15 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 1 . 8 2 V ertical translation (pixels) Distance Horse Bird Truck Cat (d) 0 45 90 135 180 225 270 315 360 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 Rotation Angle (Degrees) Distance Horse Bird Truck Cat (e) 0 45 90 135 180 225 270 315 360 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 Rotation Angle (Degrees) Distance Horse Bird Truck Cat (f) − 15 − 10 − 5 0 5 10 15 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 1 . 8 2 V ertical translation (pixels) Mean Distance Conv . Layer 1 Conv . Layer 2 Fully Connected Layer 4 (g) 0 45 90 135 180 225 270 315 360 0 . 2 0 . 4 0 . 6 0 . 8 1 1 . 2 1 . 4 1 . 6 Rotation Angle (Degrees) Mean Distance Conv . Layer 1 Conv . Layer 2 Fully Connected Layer 4 (h) Figure 4: Analysis of the impact of vertical translation and rotation on features extracted from a maxout and probout network. W e plot the distance between normalized feature vectors extracted on transformed images and the original, unchanged, image. The distances for the probout model are plotted using thick lines. The distances for the maxout model are depicted using dashed lines. (a,b) 4 ex emplary images undergoing different vertical translations and rotations respectively . (c,d) Euclidean distance between feature vectors from the original 4 images depicted in (a,b) and trans- formed images for Layer 1 (con volutional) and Layer 4 (fully connected) respecti vely . (e,f) Eu- clidean distance between feature vectors from the original 4 images and transformed versions for Layer 2 (con volutional) and Layer 4 (fully connected) respecti vely . (g,h) Mean Euclidean distance between feature vectors e xtracted from 100 randomly selected images and their transformed versions for different layers in the netw ork. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment