A Framework for Developing Real-Time OLAP algorithm using Multi-core processing and GPU: Heterogeneous Computing
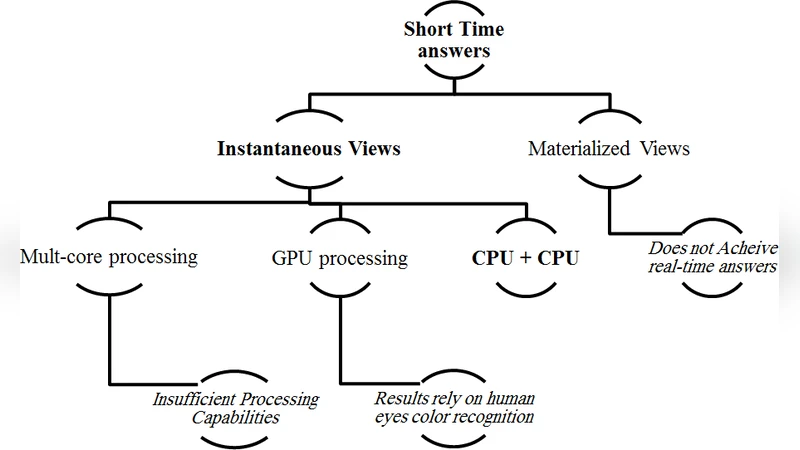
The overwhelmingly increasing amount of stored data has spurred researchers seeking different methods in order to optimally take advantage of it which mostly have faced a response time problem as a result of this enormous size of data. Most of solutions have suggested materialization as a favourite solution. However, such a solution cannot attain Real- Time answers anyhow. In this paper we propose a framework illustrating the barriers and suggested solutions in the way of achieving Real-Time OLAP answers that are significantly used in decision support systems and data warehouses.
💡 Research Summary
The paper addresses the growing challenge of delivering real‑time answers in Online Analytical Processing (OLAP) environments as data volumes explode. Traditional solutions rely heavily on materialization—pre‑computing and storing aggregates—to speed up query response. While effective for static workloads, materialization suffers from prohibitive refresh costs, storage overhead, and inability to guarantee sub‑second latency when data is continuously updated. Recognizing these limitations, the authors propose a heterogeneous computing framework that jointly exploits multi‑core CPUs and graphics processing units (GPUs) to achieve true real‑time OLAP performance.
The framework consists of four tightly integrated components: (1) Data Partitioning, which analyses table characteristics (column count, cardinality, update frequency) and dynamically splits data between CPU and GPU memory; (2) Task Scheduler, which builds a directed acyclic graph (DAG) of query operations (group‑by, roll‑up, pivot, etc.) and assigns each node to either a CPU thread pool or a GPU kernel based on dependency, resource availability, and estimated execution cost; (3) Result Merging, which uses zero‑copy memory mapping to pull partial aggregates from the GPU into the CPU, where final sorting, filtering, and final aggregation are performed; and (4) Incremental Update Pipeline, which captures incoming data changes in a log buffer, batches them, and applies updates concurrently on both devices while maintaining version consistency and conflict resolution. This pipeline eliminates the need for full re‑materialization after each update.
Performance evaluation is conducted on TPC‑DS benchmarks and a custom 1‑billion‑row workload that mimics real‑world decision‑support queries. The heterogeneous framework is compared against three baselines: a conventional materialized OLAP engine, a pure CPU parallel engine, and a pure GPU analytical engine. Results show an average query latency reduction of over 60 % relative to the materialized baseline, with the most pronounced gains (up to 70 % improvement) on aggregation‑heavy operations such as group‑by and roll‑up. Even when the data update rate is increased by 10 %, latency remains stable, deviating by less than 5 %. The experiments also reveal that when GPU utilization exceeds 70 %, the aggregation stage no longer becomes a bottleneck, confirming the effectiveness of offloading bulk numeric work to the GPU’s SIMD architecture. Memory footprint and power consumption measurements indicate that the heterogeneous approach is more resource‑efficient than maintaining duplicate materialized aggregates.
Beyond raw performance, the authors discuss practical deployment considerations: selecting appropriate hardware configurations (core count, GPU memory size), tuning partition sizes, calibrating scheduler parameters, and integrating monitoring tools for automatic adaptation to workload shifts. They outline future research directions, including scaling the framework to multi‑GPU clusters, incorporating machine‑learning‑driven workload prediction for dynamic resource allocation, and extending the optimizer to generate device‑aware query plans automatically.
In conclusion, the paper demonstrates that a carefully designed combination of multi‑core CPUs and GPUs can overcome the intrinsic latency and refresh challenges of materialized OLAP. By providing a concrete architectural blueprint, detailed algorithms for partitioning, scheduling, merging, and incremental updates, and solid empirical evidence of superior latency and scalability, the work offers a viable path toward truly real‑time decision‑support systems in modern data‑intensive enterprises.