Stochastic Gradient Estimate Variance in Contrastive Divergence and Persistent Contrastive Divergence
Contrastive Divergence (CD) and Persistent Contrastive Divergence (PCD) are popular methods for training the weights of Restricted Boltzmann Machines. However, both methods use an approximate method for sampling from the model distribution. As a side…
Authors: Mathias Berglund, Tapani Raiko
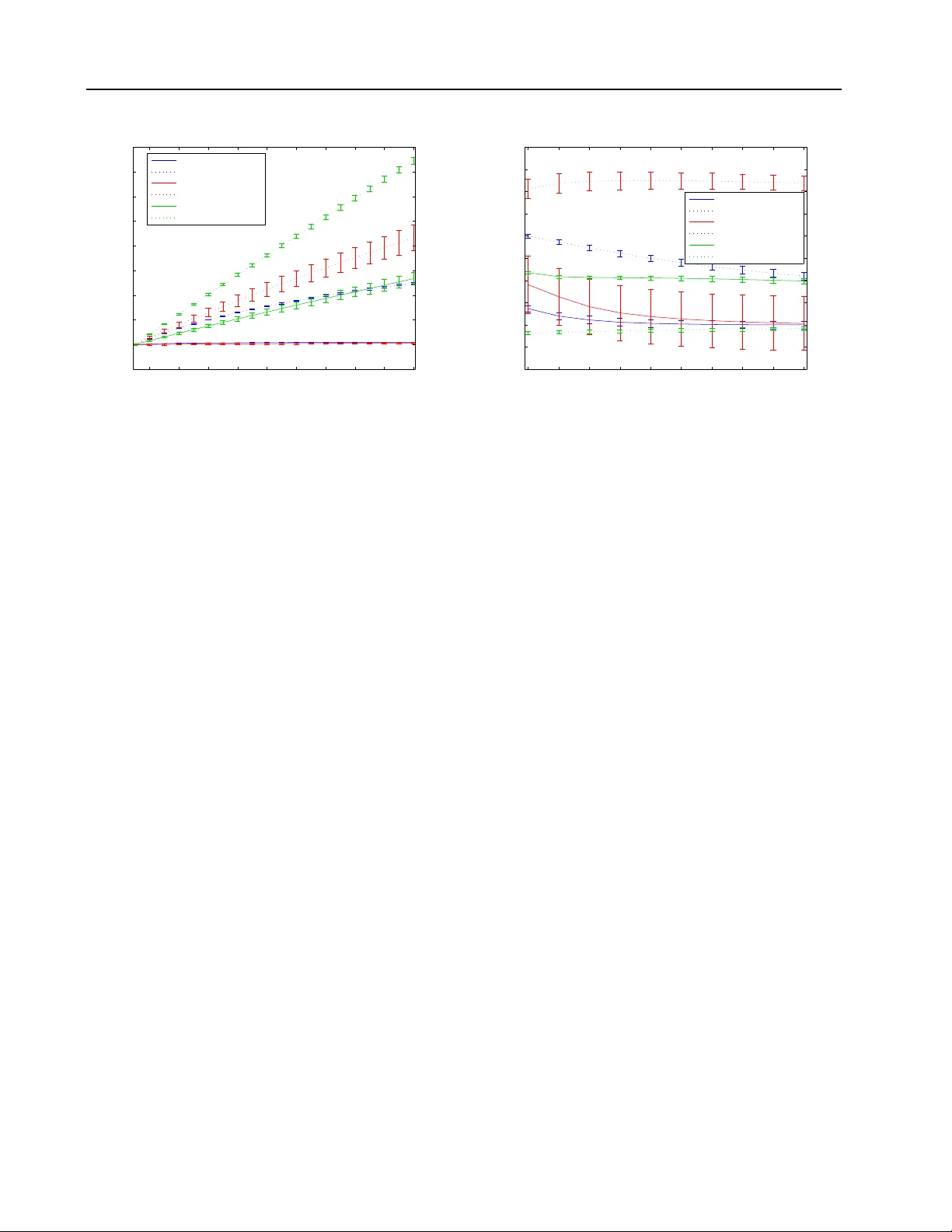
Stochastic Gradient Estimate V ariance in Contrastiv e Div ergence and P ersistent Contrastiv e Div ergence Mathias Berglund M A T H I A S . B E R G L U N D @ A A L T O . FI Aalto Univ ersity , Finland T apani Raik o TAPA N I . R A I K O @ A A L TO . FI Aalto Univ ersity , Finland Abstract Contrastiv e Div er gence (CD) and Persistent Con- trastiv e Di v ergence (PCD) are popular methods for training the weights of Restricted Boltzmann Machines. Howe v er , both methods use an ap- proximate method for sampling from the model distribution. As a side effect, these approxima- tions yield significantly dif ferent biases and vari- ances for stochastic gradient estimates of indi- vidual data points. It is well known that CD yields a biased gradient estimate. In this pa- per we howe ver sho w empirically that CD has a lower stochastic gradient estimate variance than exact sampling, while the mean of subsequent PCD estimates has a higher v ariance than exact sampling. The results give one explanation to the finding that CD can be used with smaller mini- batches or higher learning rates than PCD. 1. Introduction Popular methods to train Restricted Boltzmann Machines ( Smolensky , 1986 ) include Contrastive Div er gence ( Hin- ton , 2002 ; Hinton & Salakhutdinov , 2006 ) and Persistent Contrastiv e Diver gence 1 ( Y ounes , 1989 ; T ieleman , 2008 ). Although some theoretical research has focused on the properties of these tw o methods ( Bengio & Delalleau , 2009 ; Carreira-Perpinan & Hinton , 2005 ; T ieleman , 2008 ), both methods are still used in similar situations, where the choice is often based on intuition or heuristics. One known feature of Contrastive Diver gence (CD) learn- ing is that it yields a biased estimate of the gradient ( Bengio 1 PCD is also known as Stochastic Maximum Lik elihood Preliminary work. Under review . & Delalleau , 2009 ; Carreira-Perpinan & Hinton , 2005 ). On the other hand, it is kno wn to be fast for reaching good re- sults ( Carreira-Perpinan & Hinton , 2005 ; T ieleman , 2008 ). In addition to the computationally light sampling proce- dure in CD, it is claimed to benefit from a low variance of the gradient estimates ( Hinton , 2002 ; Carreira-Perpinan & Hinton , 2005 ). Howe v er , the current authors are not aware of any rigorous research on whether this claim holds true, and what the magnitude of the effect is 2 . On the other hand, Persistent Contrastiv e Di ver gence (PCD) has empirically been sho wn to require a lower learn- ing rate and longer training than CD 3 ( T ieleman , 2008 ). The authors propose that the low learning rate is required since the model weights are updated while the Markov chain runs, which means that in order to sample from a distribution close to the stationary distribution the weight cannot change too rapidly . Ho we ver , for similar reasons that CD updates are assumed to ha v e low variance, subse- quent PCD updates are likely to be correlated leading to a possibly undesirable ”momentum” in the updates. This be- havior would effecti vely increase the variance of the mean of subsequent updates, requiring either larger minibatches or smaller learning rates. In this paper we explore the v ariances of CD, PCD and e x- act stochastic gradient estimates. By doing so, we hope to shed light on the observed fast speed of CD learning, and on the required low learning rate for PCD learning com- pared to CD learning. Thereby we hope to contribute to the understanding of the difference between CD and PCD beyond the already well documented bias of CD. 2 The topic has been cov ered in e.g. ( W illiams & Agakov , 2002 ), although for a Boltzmann machine with only one visible and hidden neuron. 3 There are howe ver tricks to be able to increase the learning rate of PCD, see e.g. ( Swersky et al. , 2010 ) Gradient Estimate V ariance in CD and PCD 2. Contrastive Diver gence and P ersistent Contrastive Div ergence A restricted Boltzmann machine (RBM) is a Boltzmann machine where each visible neuron x i is connected to all hidden neurons h j and each hidden neuron to all visible neurons, but there are no edges between the same type of neurons. An RBM defines an energy of each state ( x , h ) by − E ( x , h | θ ) = b > x + c > h + x > Wh , and assigns the following probability to the state via the Boltzmann distri- bution: p ( x , h | θ ) = 1 Z ( θ ) exp {− E ( x , h | θ ) } , where θ = { b , c , W } is a set of parameters and Z ( θ ) normalizes the probabilities to sum up to one. The log likelihood of one training data point is hence φ = log P ( x ) = log ( P h exp {− E ( x , h | θ ) } ) − log Z ( θ ) = φ + − φ − . Sampling the positive phase of the gradient of the log likelihood ∂ φ + ∂ W is easy , but sampling the negative phase ∂ φ − ∂ W is intractable. A popular method to solve sampling of the negati ve phase is Contrasti ve Div ergence (CD). In CD, the negati v e parti- cle is sampled only approximately by running a Markov Chain a limited number of steps (often only one step) from the positiv e particle ( Hinton , 2002 ). Another method, called Persistent Contrastive Di ver gence (PCD) solves the sampling with a related method, only that the negati v e par - ticle is not sampled from the positi ve particle, but rather from the negati ve particle from the last data point ( Tiele- man , 2008 ). 3. Experiments In order to examine the v ariance of CD and PCD gradient estimates, we use an empirical approach. W e train an RBM and ev aluate the variance of gradient estimates from dif- ferent sampling strategies at different stages of the training process. The sampling strategies are CD-k with k rang- ing from 1 to 10, PCD, and CD-1000 that is assumed to correspond to an almost unbiased stochastic gradient. In addition, we test CD-k with independent samples (I-CD), where the negati ve particle is sampled from a random train- ing example. The v ariance of I-CD separates the ef fect of the negati ve particle being close to the data distribution in general, and the effect of the neg ativ e particle being close to the positiv e particle in question. W e use three different data sets. The first is a reduced size MNIST ( LeCun et al. , 1998 ) set with 14 × 14 pixel images of the first 1 000 training set data points of each digit, total- ing 10 000 data points. The second data set are the center 14 × 14 pixels of the first 10 000 CIF AR ( Krizhevsk y & Hinton , 2009 ) images con v erted into gray scale. The third are the Caltech 101 Silhouettes ( Marlin et al. , 2010 ), with 8 641 16 × 16 pix el black and white images. W e binarize 1 2 3 4 5 6 7 8 9 10 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 CD steps Variance compared to exact sampling 10 epochs MNIST 500 epochs MNIST 10 epochs CIFAR 500 epochs CIFAR 10 epochs Silhouettes 500 epochs Silhouettes Figure 1. CD-k gradient estimate variance for different values of k compared to CD-1000 after 10 and 500 epochs of training. Error bars indicate standard deviation between iterations. the grayscale images by sampling the visible units with ac- tiv ation probabilities equal to the pix el intensity . W e set the number of hidden neurons equal to the number of visible neurons. The biases are initialized to zero, while the weights are initially sampled from a zero-mean normal distribution with standard de viation 1 / √ n v + n h where n v and n h are the number of visible and hidden neurons, re- spectiv ely . W e train the model with CD-1, and e v aluate the variance of the gradient estimates after 10, and 500 epochs. W e use Adaptive learning rate ( Cho et al. , 2011 ) with an initial learning rate of 0.01. W e do not use weight decay . In all of the gradient estimates, the final sampling step for the probabilities of the hidden unit activ ations is omitted. The gradient estimate is therefore based on sampled binary visible unit acti v ations, b ut continuous hidden unit activ a- tion probabilities conditional on these visible unit activ a- tions. This process is called Rao-Blackwellisation ( Swer- sky et al. , 2010 ), and is often used in practice. The variance is calculated on indi vidual gradient estimates based on only one positi ve and negati v e particle each. In practice, the gra- dient is usually estimated by av eraging over a mini-batch of N independent samples, which diminishes the variance N- fold. W e ignore the bias gradient estimates. When analyzing subsequent PCD gradient estimates, the negati v e particles of the first estimate are sampled 1 000 steps from a random training example. Subsequent k es- timates are then averaged, where the positiv e particle is randomly sampled from the data for each step while the negati v e particle is sampled from the previous negati ve particle. No learning occurs between the subsequent es- timates. W e can therefore disentangle the effects of weight Gradient Estimate V ariance in CD and PCD 2 4 6 8 10 12 14 16 18 20 0 1 2 3 4 5 6 7 8 9 Subsequent PCD steps Variance compared to exact sampling 10 epochs MNIST 500 epochs MNIST 10 epochs CIFAR 500 epochs CIFAR 10 epochs Silhouettes 500 epochs Silhouettes Figure 2. The PCD vs CD-1000 ratio of the v ariance for the mean of k subsequent estimates after 10 and 500 epochs of training. Error bars indicate standard deviation between iterations. updates from the ef fect of correlation between subsequent estimates. W e iterate all results for 10 different random initializations of the weights, and ev aluate the variance by sampling gra- dient estimates of indi vidual training e xamples 10 times for each training example in the data set. The variance is cal- culated for each weight matrix element separately , and the variances of the indi vidual weights are then a v eraged. 4. Results As we can see from Figure 1 , the variance of Contrastiv e Div er gence is indeed smaller than for exact sampling of the negati ve particle. W e also see that the variance of CD estimates quickly increases with the number of CD steps. Howe v er , this effect is significant only in later stages of training. This phenomenon is expected, as the model is e x- pected not to mix as well in later stages of training as when the weights are close to the small initial random weights. If we sample the negati v e particle from a different train- ing example than the positi ve particle (I-CD), in Figure 3 we see that the v ariance is similar or e ven larger compared to the variance with exact sampling. Although it is triv- ial that the variance of the I-CD estimates is higher than for CD, the interesting result is that I-CD loses all of the variance advantage against e xact sampling. The result sup- ports the hypothesis that the low variance of CD precisely stems from the fact that the negati ve particle is sampled from the positive particle, and not from that the negati v e particle is sampled only a limited number of steps from a random training example. 1 2 3 4 5 6 7 8 9 10 0.9 0.95 1 1.05 1.1 1.15 1.2 1.25 1.3 1.35 1.4 I−CD steps Variance compared to exact sampling 10 epochs MNIST 500 epochs MNIST 10 epochs CIFAR 500 epochs CIFAR 10 epochs Silhouettes 500 epochs Silhouettes Figure 3. I-CD-k gradient estimate variance for different v alues of k compared to CD-1000 after 10 and 500 epochs of training. Error bars indicate standard deviation between iterations. For subsequent PCD updates, we see in Figure 2 that the variance indeed is considerably higher than for independent sampling. Again, as expected this effect is stronger the later during training the ev aluation is done. When looking at the magnitude of the variance difference, we see that for CD-1, the mean of 10 subsequent updates hav e a multiple times smaller v ariance than PCD. In ef fect, this means that ignoring any other effects and the effect of weight updates, PCD would need considerably smaller learning rates or larger minibatches to reach the same v ari- ance per minibatch. This magnitude is substantial, and might explain the empirical finding that PCD performs best with smaller learning rates than CD. 5. Conclusions Contrastiv e Div ergence or Persistent Contrastiv e Diver - gence are often used for training the weights of Restricted Boltzmann machines. Contrasti ve Div er gence is claimed to benefit from lo w variance of the gradient estimates when using stochastic gradients. Persistent Contrastive Div er - gence could on the other hand suffer from high correlation between subsequent gradient estimates due to poor mixing of the Markov chain estimating the model distrib ution. In this paper, we hav e empirically confirmed both of these findings. In experiments on three data sets, we find that the variance of CD-1 gradient estimates are considerably lower than when independently sampling with many steps from the model distribution. Con versely , the variance of the mean of subsequent gradient estimates using PCD is significantly higher than with independent sampling. This Gradient Estimate V ariance in CD and PCD effect is mainly observable towards the end of training. In effect, this indicates that from a v ariance perspectiv e, PCD would require considerably lower learning rates or larger minibatches than CD. As CD is kno wn to be a biased esti- mator , it therefore seems that the choice between CD and PCD is a trade-off between bias and v ariance. Although the results in this paper are practically significant, the approach in this paper is purely empirical. Further the- oretical analysis of the v ariance of PCD and CD gradient estimates would therefore be warranted to confirm these findings. In addition, we intend to repeat the experiments with a larger data set, and train the models and replace the CD-1000 baseline with better approximations of exact sam- pling using e.g. Enhanced gradient ( Cho et al. , 2011 ) and parallel tempering ( Cho et al. , 2010 ). References Bengio, Y oshua and Delalleau, Oli vier . Justifying and gen- eralizing contrastiv e di ver gence. Neural Computation , 21(6):1601–1621, 2009. Carreira-Perpinan, Miguel A and Hinton, Geoffre y E. On contrastiv e diver gence learning. In Artificial Intelligence and Statistics , volume 2005, pp. 17, 2005. Cho, K yungHyun, Raik o, T apani, and Ilin, Ale xander . Par- allel tempering is ef ficient for learning restricted boltz- mann machines. In IJCNN , pp. 1–8. Citeseer , 2010. Cho, KyungHyun, Raiko, T apani, and Ilin, Alexander . En- hanced gradient and adaptive learning rate for train- ing restricted Boltzmann machines. In Pr oceedings of the 28th International Confer ence on Mac hine Learning (ICML-11) , pp. 105–112, 2011. Hinton, Geoffrey E. Training products of experts by min- imizing contrastive di ver gence. Neural computation , 14 (8):1771–1800, 2002. Hinton, Geoffrey E and Salakhutdinov , Ruslan R. Reduc- ing the dimensionality of data with neural networks. Sci- ence , 313(5786):504–507, 2006. Krizhevsk y , Alex and Hinton, Geoffrey . Learning multi- ple layers of features from tiny images. Master’ s thesis, Department of Computer Science, University of T oronto , 2009. LeCun, Y ann, Bottou, L ´ eon, Bengio, Y oshua, and Haffner , Patrick. Gradient-based learning applied to document recognition. Pr oceedings of the IEEE , 86(11):2278– 2324, 1998. Marlin, Benjamin M, Swersky , K e vin, Chen, Bo, and Fre- itas, Nando D. Inductiv e principles for restricted Boltz- mann machine learning. In International Conference on Artificial Intelligence and Statistics , pp. 509–516, 2010. Smolensky , P aul. Information processing in dynamical sys- tems: F oundations of harmony theory . 1986. Swersky , Ke vin, Chen, Bo, Marlin, Ben, and de Freitas, Nando. A tutorial on stochastic approximation algo- rithms for training restricted boltzmann machines and deep belief nets. In Information Theory and Applica- tions W orkshop (IT A), 2010 , pp. 1–10. IEEE, 2010. T ieleman, Tijmen. T raining restricted Boltzmann machines using approximations to the likelihood gradient. In Pr o- ceedings of the 25th international conference on Ma- chine learning , pp. 1064–1071. A CM, 2008. W illiams, Christopher KI and Agakov , Felix V . An analy- sis of contrasti v e di ver gence learning in Gaussian Boltz- mann machines. Institute for Adaptive and Neural Com- putation , 2002. Y ounes, Laurent. Parametric inference for imperfectly ob- served gibbsian fields. Pr obability Theory and Related F ields , 82(4):625–645, 1989.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment