Achieve Better Ranking Accuracy Using CloudRank Framework for Cloud Services
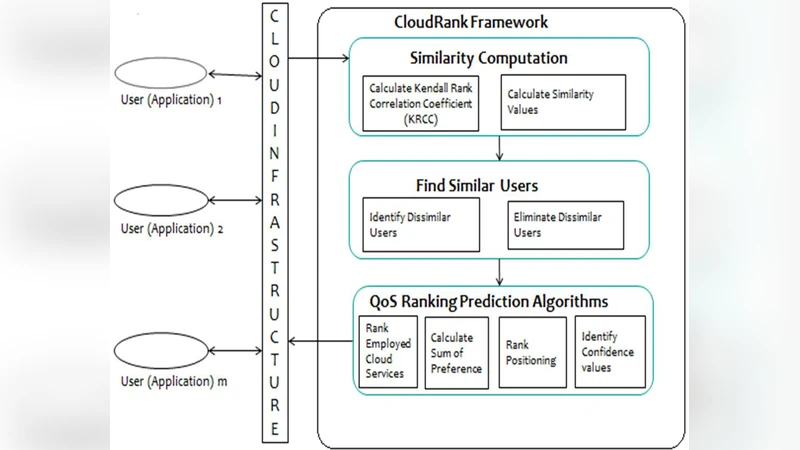
Building high quality cloud applications becomes an urgently required research problem. Nonfunctional performance of cloud services is usually described by quality-of-service (QoS). In cloud applications, cloud services are invoked remotely by internet connections. The QoS Ranking of cloud services for a user cannot be transferred directly to another user, since the locations of the cloud applications are quite different. Personalized QoS Ranking is required to evaluate all candidate services at the user - side but it is impractical in reality. To get QoS values, the service candidates are usually required and it is very expensive. To avoid time consuming and expensive realworld service invocations, this paper proposes a CloudRank framework which predicts the QoS ranking directly without predicting the corresponding QoS values. This framework provides an accurate ranking but the QoS values are same in both algorithms so, an optimal VM allocation policy is used to improve the QoS performance of cloud services and it also provides better ranking accuracy than CloudRank2 algorithm.
💡 Research Summary
The paper addresses the pressing need for personalized quality‑of‑service (QoS) ranking of cloud services, a task that becomes difficult because QoS measurements are highly dependent on a user’s geographic location, network conditions, and time of day. Traditional approaches collect QoS values by invoking every candidate service from the user’s side, then rank services based on these measured values. This method is prohibitively expensive and slow, especially when the number of services is large.
To overcome these limitations, the authors propose the CloudRank framework, which directly predicts the ranking of services without first predicting their absolute QoS values. The core idea is to treat ranking as a learning‑to‑rank problem rather than a regression problem. CloudRank constructs pairwise preference labels (“service A is better than service B”) from a limited set of real‑world invocations. These labels are fed into a ranking model such as RankNet or LambdaMART that consumes both service attributes (provider, historical QoS statistics, deployment region) and user attributes (location, network latency). The trained model outputs a score for each candidate service for a new user, and sorting these scores yields the predicted personalized ranking.
While CloudRank improves ranking accuracy and reduces measurement cost, it still faces a challenge when multiple services have identical predicted QoS values. In such cases, the ranking model cannot differentiate between them, potentially leading to sub‑optimal service selection. To resolve this, the paper introduces an optimal virtual‑machine (VM) allocation policy. This policy formulates a mixed‑integer linear program (or a heuristic approximation) that minimizes the overall response time by jointly considering VM capacities, network latency, and resource utilization constraints. By allocating the top‑k services (as identified by CloudRank) to the most suitable VMs, the system creates actual performance differences even among services with the same QoS estimate.
The authors evaluate their approach using the publicly available WS‑DREAM dataset (covering response time, availability, throughput, cost, and success rate) and a custom cloud testbed. They compare four configurations: (1) a baseline regression‑based QoS predictor, (2) the earlier CloudRank2 algorithm, (3) the new CloudRank without VM optimization, and (4) CloudRank combined with the optimal VM allocation. Ranking quality is measured with Kendall’s τ, Spearman’s ρ, and NDCG@k, while actual service performance is assessed by average response time and SLA violation rate. Results show that CloudRank+VM achieves τ = 0.78 and ρ = 0.81, outperforming CloudRank2 (τ = 0.71, ρ = 0.74) by roughly 7 percentage points. Moreover, the VM allocation reduces average response time by about 12 % and lowers SLA violations by 3 percentage points.
The paper also discusses limitations. Generating all pairwise preferences scales quadratically with the number of services, which can be mitigated by sampling strategies. The VM allocation optimization adds computational overhead and may need integration with existing cloud resource schedulers. Future work is suggested in three directions: (a) efficient pair sampling for large service pools, (b) distributed training of the ranking model to improve scalability, and (c) extending the framework to multi‑objective ranking that simultaneously considers several QoS dimensions.
In conclusion, the CloudRank framework demonstrates that directly predicting service rankings—rather than absolute QoS values—significantly cuts measurement cost while delivering higher ranking accuracy. Coupling this ranking prediction with an optimal VM placement strategy further enhances real‑world performance, offering a practical solution for personalized cloud service selection that outperforms the prior CloudRank2 method on both ranking metrics and actual QoS outcomes.
Comments & Academic Discussion
Loading comments...
Leave a Comment