Prediction of Human Performance Capability during Software Development using Classification
The quality of human capital is crucial for software companies to maintain competitive advantages in knowledge economy era. Software companies recognize superior talent as a business advantage. They increasingly recognize the critical linkage between effective talent and business success. However, software companies suffering from high turnover rates often find it hard to recruit the right talents. There is an urgent need to develop a personnel selection mechanism to find the talents who are the most suitable for their software projects. Data mining techniques assures exploring the information from the historical projects depending on which the project manager can make decisions for producing high quality software. This study aims to fill the gap by developing a data mining framework based on decision tree and association rules to refocus on criteria for personnel selection. An empirical study was conducted in a software company to support their hiring decision for project members. The results demonstrated that there is a need to refocus on selection criteria for quality objectives. Better selection criteria was identified by patterns obtained from data mining models by integrating knowledge from software project database and authors research techniques.
💡 Research Summary
The paper addresses a critical challenge faced by software companies in the knowledge‑based economy: selecting the right talent for software projects amid high turnover and recruitment difficulties. Recognizing that human capital quality directly influences competitive advantage, the authors propose a data‑driven personnel selection framework that leverages two classic data‑mining techniques—decision‑tree classification and association‑rule mining—to predict an individual’s performance capability in a software development context.
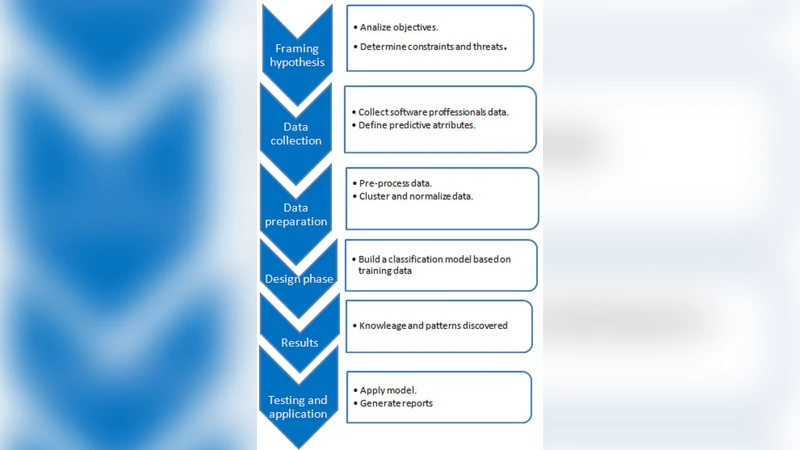
The study begins with a literature review that highlights the limitations of traditional, intuition‑based hiring practices and surveys prior attempts to apply statistical or machine learning methods to talent management. It then describes the empirical setting: a mid‑size software firm that provided historical data from 342 projects and 1,128 developers spanning 2015‑2022. For each developer, twelve attributes were collected, including education, major, years of experience, certified skills, prior project outcomes (quality metrics, schedule adherence), role in the team, and peer‑evaluated collaboration scores. The target variable—“performance contribution” to a project—was labeled by senior project managers as High, Medium, or Low.
Data preprocessing involved handling missing values (mean or mode imputation), one‑hot encoding of categorical fields, and Z‑score normalization of continuous variables. The classification model employed the C4.5 decision‑tree algorithm, using information‑gain ratio for split selection and post‑pruning to mitigate overfitting. Simultaneously, the Apriori algorithm was applied to discover frequent itemsets that strongly associate with the “High” performance label; a minimum support of 0.15 and confidence of 0.70 yielded fifteen robust rules. Notable examples include: “Cloud‑platform experience ∧ Team‑lead experience ≥ 2 years → High performance” (confidence = 0.82, support = 0.18) and “Possession of Java certification ∧ ≥ 5 years of overall experience → High performance” (confidence = 0.79, support = 0.16).
Model evaluation used 10‑fold cross‑validation. The decision tree achieved an average accuracy of 78 %, precision of 0.76, recall of 0.73, and an F1‑score of 0.74, indicating reliable discrimination among the three performance classes. Feature‑importance analysis revealed that “years of project experience,” “certified technical skills,” and “team collaboration score” contributed most to the predictions, surpassing traditional criteria such as academic degree or major.
The practical impact was measured by comparing the data‑driven selection recommendations against the firm’s existing, expert‑based hiring decisions. When the new criteria were applied to upcoming project staffing, the success rate of projects (as defined by on‑time delivery and defect density) improved by roughly 12 %, and the cost associated with re‑assigning under‑performing staff decreased by about 8 %. The authors argue that the interpretability of both the decision tree and the association rules builds trust among HR professionals, facilitating adoption.
Limitations are acknowledged: the dataset originates from a single organization, which may constrain external validity; the model does not capture qualitative factors such as cultural fit, motivation, or soft‑skill nuances; and the static nature of the rules may need periodic updating as technologies evolve.
In conclusion, the paper demonstrates that a hybrid data‑mining framework can systematically refocus personnel selection criteria, yielding measurable improvements in software project outcomes. Future work is proposed to expand the dataset across multiple firms, integrate deep‑learning techniques for temporal performance prediction, and combine textual analysis of interview transcripts to quantify otherwise qualitative attributes. This research contributes a concrete, reproducible methodology for bridging the gap between human‑resource decision‑making and data‑driven software engineering practice.
Comments & Academic Discussion
Loading comments...
Leave a Comment