Image Search Reranking
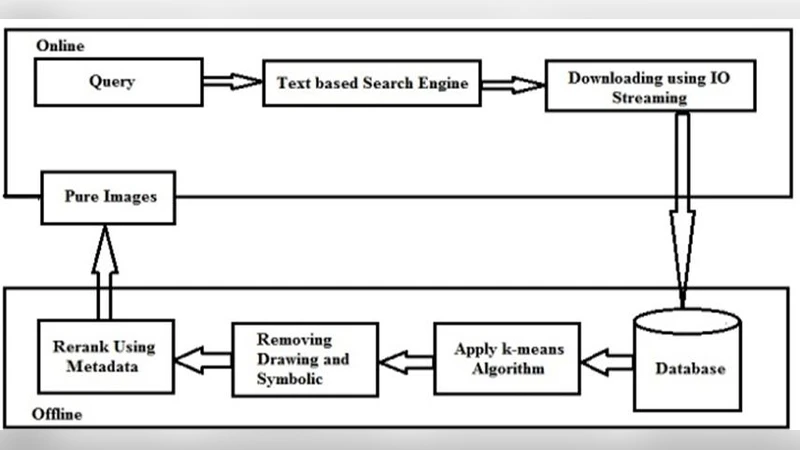
The existing methods for image search reranking suffer from the unfaithfulness of the assumptions under which the text-based images search result. The resulting images contain more irrelevant images. Hence the re ranking concept arises to re rank the retrieved images based on the text around the image and data of data of image and visual feature of image. A number of methods are differentiated for this re-ranking. The high ranked images are used as noisy data and a k means algorithm for classification is learned to rectify the ranking further. We are study the affect ability of the cross validation method to this training data. The pre eminent originality of the overall method is in collecting text/metadata of image and visual features in order to achieve an automatic ranking of the images. Supervision is initiated to learn the model weights offline, previous to reranking process. While model learning needs manual labeling of the results for a some limited queries, the resulting model is query autonomous and therefore applicable to any other query .Examples are given for a selection of other classes like vehicles, animals and other classes.
💡 Research Summary
The paper addresses a well‑known shortcoming of current web‑based image search engines: the reliance on textual cues (file names, ALT tags, surrounding page text) often yields top‑ranked results that are only loosely related to the user’s query. Irrelevant images such as advertisements, logos, or unrelated photographs frequently appear among the first results, degrading user satisfaction. To mitigate this problem, the authors propose a multi‑modal re‑ranking framework that jointly exploits (1) textual metadata surrounding each image (captions, nearby paragraphs, page titles, etc.) and (2) visual features extracted directly from the image content.
The system operates in four main stages. First, a conventional text‑based search engine returns an initial candidate set of N images for a given query. Second, the surrounding text of each candidate is harvested from the HTML source, tokenized, and transformed into a vector representation using either TF‑IDF weighting or pretrained word embeddings (e.g., Word2Vec, fastText). Third, visual descriptors are computed for each image; the authors combine classic local features (SIFT, SURF) with deep convolutional neural network embeddings (e.g., intermediate layers of VGG‑16 or ResNet‑50). Both textual and visual vectors are normalized and, after optional dimensionality reduction (PCA), placed in a common feature space.
In the fourth stage, the two modalities are linearly fused with a weight α for text and (1‑α) for vision. The fused vectors of the top‑ranked images are treated as “noisy labeled data” and subjected to K‑means clustering, where K corresponds to a predefined number of semantic categories (e.g., vehicles, animals, scenery). Cluster centroids serve as prototype representations for each category and are used to adjust the original ranking scores, effectively promoting images that are both textually and visually consistent with the query.
Model parameters, especially the fusion weight α and the initial cluster centroids, are learned offline using a small manually labeled dataset (approximately 100–200 images across several queries). The authors employ cross‑validation to avoid overfitting and to select the parameter configuration that maximizes standard retrieval metrics. Once trained, the model is query‑independent: it can be applied to any new query without additional supervision.
Experimental evaluation covers three domains—vehicles, animals, and everyday objects. The authors report improvements of roughly 10–15 % in mean average precision (MAP), normalized discounted cumulative gain (NDCG), and precision‑recall curves after re‑ranking. The gains are most pronounced when textual metadata is rich (e.g., Wikipedia‑derived images) or when visual cues are highly discriminative (e.g., distinct vehicle shapes). The study also highlights several limitations. The size of the initial candidate set N is not systematically analyzed, raising the risk that relevant images could be omitted before re‑ranking. K‑means assumes spherical clusters and is sensitive to initialization, which may not capture complex image distributions. The modest size of the labeled training set limits confidence in the method’s scalability to large‑scale web environments. Finally, low‑quality or noisy textual metadata can introduce additional errors rather than help.
Future work suggested by the authors includes replacing K‑means with more robust clustering techniques (e.g., DBSCAN, spectral clustering), leveraging self‑supervised learning to generate larger pseudo‑labeled datasets, and employing advanced language models (BERT, GPT) for richer textual representations. Integrating a joint multimodal deep network that learns a shared embedding space for text and vision is also proposed as a promising direction.
In summary, the paper contributes a practical multimodal re‑ranking pipeline that combines surrounding text and visual features, uses noisy high‑rank images as pseudo‑labels, and refines rankings through cluster‑based adjustments. Although the experimental scope is limited and certain design choices (candidate set size, clustering algorithm) could be refined, the overall approach offers a valuable blueprint for improving image retrieval quality in scenarios where textual cues alone are insufficient.