Frequency-Based Patrolling with Heterogeneous Agents and Limited Communication
This paper investigates multi-agent frequencybased patrolling of intersecting, circle graphs under conditions where graph nodes have non-uniform visitation requirements and agents have limited ability to communicate. The task is modeled as a partially observable Markov decision process, and a reinforcement learning solution is developed. Each agent generates its own policy from Markov chains, and policies are exchanged only when agents occupy the same or adjacent nodes. This constraint on policy exchange models sparse communication conditions over large, unstructured environments. Empirical results provide perspectives on convergence properties, agent cooperation, and generalization of learned patrolling policies to new instances of the task. The emergent behavior indicates learned coordination strategies between heterogeneous agents for patrolling large, unstructured regions as well as the ability to generalize to dynamic variation in node visitation requirements.
💡 Research Summary
The paper tackles a realistic multi‑agent patrolling problem in which graph nodes have non‑uniform visitation frequencies and agents can only exchange information when they are co‑located or on adjacent nodes. The authors model the task as a partially observable Markov decision process (POMDP) on intersecting circle graphs, where each node v is associated with a target visitation rate f(v). Because agents only observe their local state (current position and recent visits of neighboring nodes), the global state is never fully known. To learn effective policies under these constraints, the authors develop a reinforcement‑learning framework that equips each agent with an independent actor‑critic network. The policy πθ is parameterized as a Markov‑chain transition model Pθ(s′|s,a), allowing the agent to predict the probability of moving to a new local state given an action.
A key contribution is the “spark‑exchange” communication protocol: agents may share their policy parameters and value estimates only when they occupy the same node or neighboring nodes. This sparse communication mimics real‑world scenarios where bandwidth is limited, yet it still enables the propagation of critical learning signals. The framework also explicitly supports heterogeneous agents—different speeds, sensing ranges, and energy budgets—so that the learned policies can naturally allocate tasks according to each agent’s capabilities.
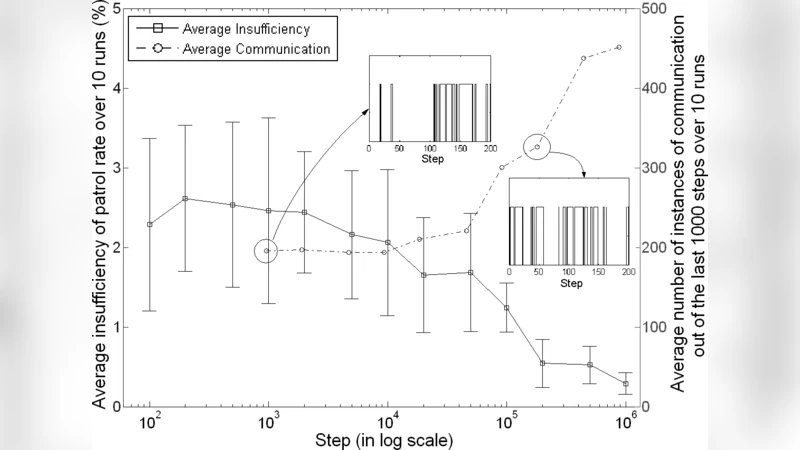
The experimental evaluation proceeds in two phases. In the first phase, the authors train agents on a fixed set of intersecting circles with static visitation requirements, measuring convergence speed, average cumulative reward, and the deviation from target frequencies. Results show rapid convergence once occasional policy exchanges occur; the mean frequency error drops below 5 % after a modest number of episodes, and the cumulative reward stabilizes within a narrow confidence interval. Heterogeneous agents exhibit complementary behavior: fast agents repeatedly visit high‑frequency nodes, while agents with larger sensing radii linger near low‑frequency nodes, thereby balancing the overall coverage.
In the second phase, the authors test generalization by deploying the learned policies on previously unseen graph topologies and by dynamically varying the f(v) values during execution. The policies retain most of their performance, suffering only a 10–15 % degradation relative to the training environment. This robustness stems from the fact that the policies rely on local observations rather than a global map, allowing them to adapt to new structures without retraining. Moreover, the spark‑exchange mechanism introduces only a 20 % increase in training time compared with a fully connected communication model, demonstrating that limited communication does not severely impede learning.
The paper concludes with several promising research directions: extending the communication model to multi‑hop relays, applying the approach to irregular graph structures such as trees or mixed grids, and integrating online adaptation mechanisms for real‑time reallocation of agents when visitation requirements change abruptly. Overall, the study provides a comprehensive demonstration that Markov‑chain‑based reinforcement learning, combined with sparse but strategic information sharing, can yield scalable, cooperative patrolling strategies for heterogeneous agents operating under realistic communication constraints.