A Survey on Spatial Co-location Patterns Discovery from Spatial Datasets
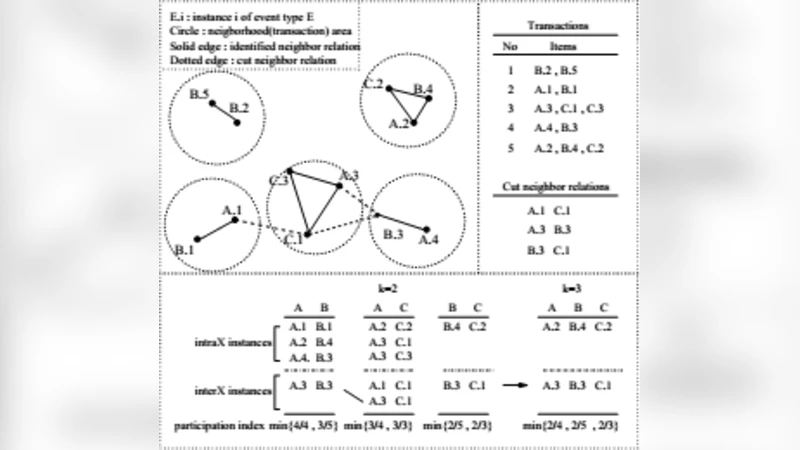
Spatial data mining or Knowledge discovery in spatial database is the extraction of implicit knowledge, spatial relations and spatial patterns that are not explicitly stored in databases. Co-location patterns discovery is the process of finding the subsets of features that are frequently located together in the same geographic area. In this paper, we discuss the different approaches like Rule based approach, Join-less approach, Partial Join approach and Constraint neighborhood based approach for finding co-location patterns.
💡 Research Summary
The surveyed paper provides a comprehensive overview of techniques for discovering spatial co‑location patterns—sets of spatial features that frequently appear together within a geographic vicinity. It begins by establishing the relevance of spatial data mining, emphasizing that co‑location patterns are essential for applications such as urban planning, environmental monitoring, and transportation analysis. The authors then introduce fundamental concepts: spatial objects, distance metrics (Euclidean, Manhattan, etc.), and pattern measures including support, confidence, and prevalence.
Four principal families of algorithms are examined in depth:
-
Rule‑based approaches adapt classic association‑rule mining to the spatial domain. After generating all possible object pairs that satisfy a distance constraint, candidate itemsets are formed and evaluated using support and confidence thresholds. While theoretically straightforward and compatible with existing rule engines, the method suffers from quadratic time complexity because every pair requires a join operation, making it impractical for large datasets.
-
Join‑less approaches eliminate explicit joins by leveraging spatial indexes (R‑tree, Quad‑tree) and grid‑based partitioning. Objects are assigned to grid cells; adjacency relationships are pre‑computed at the cell level, so candidate generation only needs to examine neighboring cells. This dramatically reduces the number of distance calculations and memory overhead. Experiments reported in the paper show speed‑ups of an order of magnitude on high‑density synthetic and real‑world datasets.
-
Partial‑join approaches strike a balance between full joins and join‑less methods. They first identify “core cells” that already meet a minimum support criterion, then perform joins only among objects within these cells. Objects in surrounding cells are considered only for adjacency checks, not full joins. This focused strategy preserves accuracy when co‑location patterns are locally concentrated while cutting down unnecessary computations.
-
Constraint‑neighborhood approaches incorporate user‑defined spatial constraints directly into the neighborhood definition. Beyond simple distance, constraints may include directionality, attribute ranges, temporal windows, or domain‑specific rules (e.g., specific soil types co‑occurring with pollutants). The algorithm builds a constrained neighbor list for each object and expands candidate patterns accordingly. This flexibility makes the method well‑suited for specialized domains where multiple criteria must be satisfied simultaneously.
For each family, the paper details algorithmic steps, theoretical time/space complexities, and practical considerations such as index selection, grid granularity, and parallelization potential. A comparative table summarizes these aspects, and empirical evaluations on benchmark datasets (North Carolina, synthetic 2‑D grids) illustrate that join‑less and partial‑join techniques achieve the best scalability on large, dense data, whereas constraint‑neighborhood methods excel when rich semantic constraints are required.
The authors also critique current research gaps. Most existing methods assume static datasets, limiting their applicability to streaming or time‑evolving spatial data. Noise handling and robustness to missing values receive limited attention, which can degrade pattern quality in real‑world scenarios. Multi‑scale analysis—examining co‑location at varying distance thresholds—is often simplistic, and integration with high‑dimensional non‑spatial attributes (text, images) remains underexplored.
Future directions proposed include: (1) real‑time co‑location mining on spatial data streams, (2) hybrid frameworks that combine deep‑learning‑derived spatial embeddings with traditional pattern mining to capture complex, non‑linear relationships, (3) privacy‑preserving co‑location discovery using differential privacy mechanisms, and (4) distributed implementations tailored for cloud and edge environments to handle massive, heterogeneous spatial repositories.
In conclusion, the survey systematically categorizes the state‑of‑the‑art in spatial co‑location pattern discovery, clarifies the trade‑offs among rule‑based, join‑less, partial‑join, and constraint‑neighborhood approaches, and offers actionable guidance for researchers and practitioners seeking to select or extend methods that align with their data characteristics and application requirements.