Learning Transformations for Classification Forests
This work introduces a transformation-based learner model for classification forests. The weak learner at each split node plays a crucial role in a classification tree. We propose to optimize the splitting objective by learning a linear transformatio…
Authors: Qiang Qiu, Guillermo Sapiro
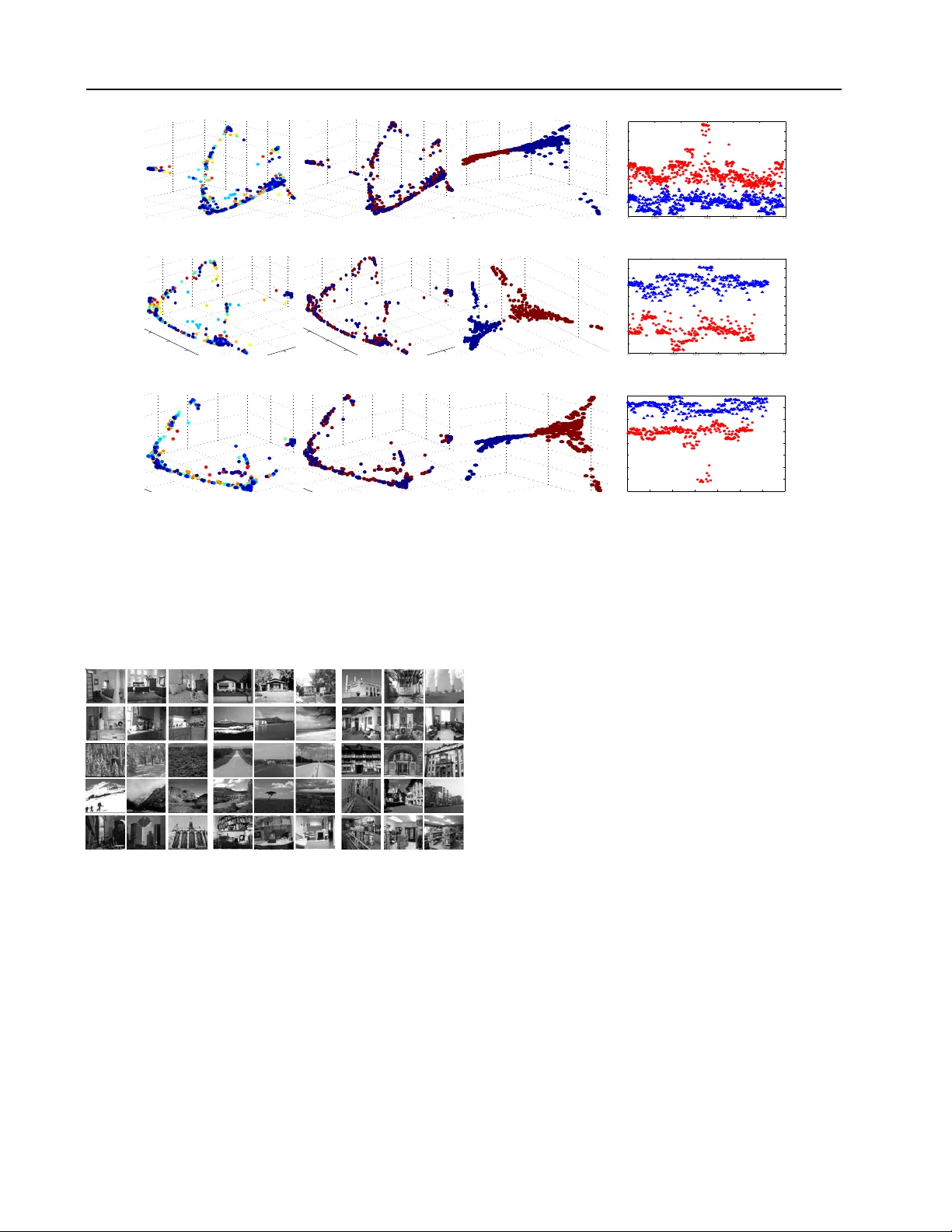
Learning T ransf ormations f or Classification F or ests Qiang Qiu Q I A N G . Q I U @ D U K E . E D U Department of Electrical and Computer Engineering, Duke Uni versity , Durham, NC 27708, USA Guillermo Sapiro G U I L L E R M O . S A P I RO @ D U K E . E D U Department of Electrical and Computer Engineering, Department of Computer Science, Department of Biomedical Engineering, Duke Uni versity , Durham, NC 27708, USA Abstract This work introduces a transformation-based learner model for classification forests. The weak learner at each split node plays a crucial role in a classification tree. W e propose to optimize the splitting objectiv e by learning a linear transfor- mation on subspaces using nuclear norm as the optimization criteria. The learned linear trans- formation restores a lo w-rank structure for data from the same class, and, at the same time, max- imizes the separation between different classes, thereby improving the performance of the split function. Theoretical and experimental results support the proposed framew ork. 1. Introduction Classification Forests ( Breiman , 2001 ; Criminisi & Shot- ton , 2013 ) ha ve recently shown great success for a large va- riety of classification tasks, such as pose estimation ( Shot- ton et al. , 2012 ), data clustering ( Moosmann et al. , 2007 ), and object recognition ( Gall & Lempitsky , 2009 ). A classi- fication forest is an ensemble of randomized classification trees. A classification tree is a set of hierarchically con- nected tree nodes, i.e., split (internal) nodes and leaf (ter- minal) nodes. Each split node is associated with a different weak learner with binary outputs (here we focus on binary trees). The splitting objecti ve at each node is optimized us- ing the training set. During testing, a split node ev aluates each arriving data point and sends it to the left or right child based on the weak learner output. The weak learner associated with each split node plays a crucial role in a classification tree. An analysis of the effect of various popular weak learner models can be found in ( Criminisi & Shotton , 2013 ), including decision stumps, general oriented hyperplane learner, and conic sec- tion learner . In general, e v en for high-dimensional data, we usually seek for low-dimensional weak learners that sepa- rate different classes as much as possible. High-dimensional data often have a small intrinsic dimen- sion. For example, in the area of computer vision, face im- ages of a subject ( Basri & Jacobs , 2003 ), ( Wright et al. , 2009 ), handwritten images of a digit ( Hastie & Simard , 1998 ), and trajectories of a moving object ( T omasi & Kanade , 1992 ), can all be well-approximated by a low- dimensional subspace of the high-dimensional ambient space. Thus, multiple class data often lie in a union of lo w- dimensional subspaces. These theoretical low-dimensional intrinsic structures are often violated for real-world data. For example, under the assumption of Lambertian re- flectance, ( Basri & Jacobs , 2003 ) sho w that face images of a subject obtained under a wide variety of lighting condi- tions can be accurately approximated with a 9-dimensional linear subspace. Howe ver , real-world face images are often captured under additional pose variations; in addition, faces are not perfectly Lambertian, and exhibit cast shadows and specularities ( Cand ` es et al. , 2011 ). When data from the same low-dimensional subspace are arranged as columns of a single matrix, the matrix should be approximately lo w-rank. Thus, a promising way to han- dle corrupted underlying structures of realistic data, and as such, deviations from ideal subspaces, is to restore such low-rank structure. Recent efforts have been in v ested in seeking transformations such that the transformed data can be decomposed as the sum of a low-rank matrix compo- nent and a sparse error one ( Peng et al. , 2010 ; Shen & W u , 2012 ; Zhang et al. , 2011 ). ( Peng et al. , 2010 ) and Learning T ransformations f or Classification F orests ( Zhang et al. , 2011 ) are proposed for image alignment (see ( Kuybeda et al. , 2013 ) for the extension to multiple-classes with applications in cryo-tomograhy), and ( Shen & W u , 2012 ) is discussed in the context of salient object detection. All these methods build on recent theoretical and computa- tional advances in rank minimization. In this paper, we present a new formulation for random forests, and propose to learn a linear discriminative trans- formation at each split node in each tree to improve the class separation capability of weak learners. W e optimize the data splitting objectiv e using matrix rank, via its nu- clear norm con v ex surrogate, as the learning criteria. W e show that the learned discriminative transformation recov- ers a lo w-rank structure for data from the same class, and, at the same time, maximize the subspace angles between different classes. Intuitiv ely , the proposed method shares some of the attrib utes of the Linear Discriminant Analy- sis (LD A) method, b ut with a significantly dif ferent metric. Similar to LDA, our method reduces intra-class v ariations and increases inter-class separations to achiev e improved data splitting. Howe ver , we adopt the matrix nuclear norm as the key criterion to learn a transformation, being this appropriate for data expected to be in (the union of) sub- spaces. As sho wn later , our method significantly outper- forms the LD A method, as well as state-of-the-art learners in classification forests. The learned transformations help in other classification task as well, e.g., subspace based methods ( Qiu & Sapiro , 2013 ). 2. T ransf ormation F orests A classification forest is an ensemble of binary classifica- tion trees, where each tree consists of hierarchically con- nected split (internal) nodes and leaf (terminal) nodes. Each split node corresponds to a weak learner , and ev alu- ates each arri ving data point and sends it to the left or right child based on the weak learner binary outputs. Each leaf node stores the statistics of the data points that arri v ed dur- ing training. During testing, each classification tree returns a class posterior probability for a test sample, and the forest output is often defined as the av erage of tree posteriors. In this section, we introduce transformation learning at each split node to dramatically improve the class separation ca- pability of a weak learner . Such learned transformation is virtually computationally free at the testing time. 2.1. Learning T ransf ormation Learners Consider two-class data points Y = { y i } N i =1 ⊆ R d , with each data point y i in one of the C low-dimensional sub- spaces of R d , and the data arranged as columns of Y . W e assume the class labels are kno wn beforehand for training purposes. Y + and Y − denote the set of points in each of the two classes respectively , points again arranged as columns of the corresponding matrix. W e propose to learn a d × d linear transformation T , 1 arg T min || TY + || ∗ + || TY − || ∗ − || T [ Y + , Y − ] || ∗ , (1) s.t. || T || 2 = 1 , where [ Y + , Y − ] denotes the concatenation of Y + and Y − , and ||·|| ∗ denotes the matrix nuclear norm, i.e., the sum of the singular values of a matrix. The nuclear norm is the con ve x en velop of the rank function over the unit ball of matrices ( Fazel , 2002 ). As the nuclear norm can be op- timized efficiently , it is often adopted as the best con v ex approximation of the rank function in the literature on rank optimization (see, e.g., ( Cand ` es et al. , 2011 ) and ( Recht et al. , 2010 )). The normalization condition || T || 2 = 1 pre- vents the tri vial solution T = 0 ; ho wev er , the ef fects of different normalizations is interesting and is the subject of future research. Throughout this paper we keep this partic- ular form of the normalization which was already proven to lead to excellent results. As shown later , such linear transformation restores a low- rank structure for data from the same class, and, at the same time, maximizes the subspace angles between classes. In this way , we reduce the intra-class v ariation and introduce inter-class separations to improve the class separation ca- pability of a weak learner . 2.2. Theoretical Analysis One fundamental factor that affects the performance of weak learners in a classification tree is the separation be- tween dif ferent class subspaces. An important notion to quantify the separation between two subspaces S i and S j is the smallest principal angle θ ij ( Miao & Ben-Israel , 1992 ), ( Elhamifar & V idal , 2013 ), defined as θ ij = min u ∈S i , v ∈S j arccos u 0 v || u || 2 || v || 2 . (2) Note that θ ij ∈ [0 , π 2 ] . W e sho w ne xt that the learned trans- formation T using the objective function ( 1 ) maximizes the angle between subspaces of different classes, leading to im- prov ed data splitting in a tree node. W e start by presenting some basic norm relationships for matrices and their corre- sponding concatenations. Theorem 1. Let A and B be matrices of the same r ow dimensions, and [ A , B ] be the concatenation of A and B , we have || [ A , B ] || ∗ ≤ || A || ∗ + || B || ∗ , with equality obtained if the column spaces of A and B are orthogonal. 1 W e can also consider learning a s × d matrix, s < d , and simultaneously reducing the data dimension. Learning T ransformations f or Classification F orests 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Original subspaces (a) θ AB = 0 . 79 , θ AC = 0 . 79 , θ B C = 1 . 05 Y + = { A ( g reen ) , B ( blue ) } , Y − = { C ( r ed ) } . 0 0.02 0.04 0.06 0.08 0.1 0 0.05 0.1 −0.04 −0.02 0 0.02 0.04 0.06 0.08 Transformed subspaces (b) T = 0 . 42 0 . 33 − 0 . 13 0 . 39 0 . 32 − 0 . 16 − 0 . 17 − 0 . 14 0 . 81 ; θ AB = 0 . 006 , θ AC = 1 . 53 , θ B C = 1 . 53 . 0 0.2 0.4 0.6 0.8 1 −0.5 0 0.5 1 0 0.2 0.4 0.6 0.8 1 Original subspaces (c) θ AB = 1 . 05 , θ AC = 1 . 05 , θ AD = 1 . 05 , θ B C = 1 . 32 , θ B D = 1 . 39 , θ C D = 0 . 53 , Y + = { A ( blue ) , B ( lig ht blue ) } , Y − = { C ( y ellow ) , D ( red ) } . 0 0.02 0.04 0.06 0.08 −0.01 0 0.01 0.02 0.03 −0.02 0 0.02 0.04 0.06 0.08 0.1 0.12 Transformed subspaces (d) T = 0 . 48 0 . 08 − 0 . 03 0 . 18 0 . 04 − 0 . 16 − 0 . 03 − 0 . 01 0 . 98 ; θ AB = 0 . 03 , θ AC = 1 . 41 , θ AD = 1 . 40 , θ B C = 1 . 41 , θ B D = 1 . 41 , θ C D = 0 . 01 . Figure 1. Learning transformation T using ( 1 ). W e denote the angle between subspaces A and B as θ AB (and analogous for the other pairs of subspaces). As indicated in (a) and (c), we assign subspaces to dif ferent classes Y + and Y − . Using ( 1 ), we transform subspaces in (a),(c) to (b),(d) respectively . W e observe that the learned transformation T increases the inter -class subspace angle towards the maximum π 2 , and reduces intra-class subspace angle tow ards the minimum 0 . Pr oof. See Appendix A . Based on this result we hav e that || TY + || ∗ + || TY − || ∗ − || T [ Y + , Y − ] || ∗ ≥ 0 , (3) and the proposed objective function ( 1 ) reaches the min- imum 0 if the column spaces of two classes are orthogo- nal after applying the learned transformation T ; or equiv a- lently , ( 1 ) reaches the minimum 0 when the angle between subspaces of two classes is maximized after transforma- tion, i.e., the smallest principal angle between subspaces equals π 2 . W e now discuss the advantages of adopting the nuclear norm in ( 1 ) over the rank function and other (popular) ma- trix norms, e.g., the induced 2-norm and the Frobenius norm. When we replace the nuclear norm in ( 1 ) with the rank function, the objecti ve function reaches the minimum when subspaces are disjoint, but not necessarily maximally distant. If we replace the nuclear norm in ( 1 ) with the in- duced 2-norm norm or the Frobenius norm, as shown in Appendix B , the objective function is minimized at the tri v- ial solution T = 0 , which is prevented by the normalization condition || T || 2 = 1 . Thus, we adopt the nuclear norm in ( 1 ) for two major ad- vantages that are not so fav orable in the rank function or other (popular) matrix norms: (a) The nuclear norm is the best conv ex approximation of the rank function ( Fazel , 2002 ), which helps to reduce the variation within classes (first term in ( 1 )); (b) The objecti ve function ( 1 ) is in gen- eral optimized when the distance between subspaces of different classes is maximized after transformation, which helps to introduce separations between the classes. Learning T ransformations f or Classification F orests 2.3. Synthetic Examples W e no w illustrate the properties of the above mentioned learned transformation T using synthetic examples in Fig. 1 (real-world examples are presented in Section 3 ). W e adopt a simple gradient descent optimization method (though other modern nuclear norm optimization tech- niques could be considered) to search for the transforma- tion matrix T that minimizes ( 1 ). As shown in Fig. 1 , the learned transformation T via ( 1 ) increases the inter-class subspace angle tow ards the maximum π 2 , and reduces intra- class subspace angle tow ards the minimum 0 . 2.4. T ransformation Lear ner Model for a Classification T ree During training, at the i -th split node, we denote the ar- riving training samples as Y + i and Y − i . When more than two classes are present at a node, we randomly di- vide classes into two categories. This step is to purposely introduce node randomness to av oid duplicated trees as dis- cussed later . W e then learn a transformation matrix T i us- ing ( 1 ), and represent the subspaces of T i Y + i and T i Y − i as D + i and D − i respectiv ely . The weak learner model at the i -th split node is now defined as θ i = ( T i , D + i , D − i ) . During both training and testing, at the i -th split node, each arriving sample y uses T i y as the feature, and is assigned to D + i or D − i that giv es the smaller reconstruction error . V arious techniques are available to perform the above ev aluation. In our implementation, we obtain D + i and D − i using the K-SVD method ( Aharon et al. , 2006 ) and denote a transformation learner as θ i = ( T i , D + i ( D + i ) † , D − i ( D − i ) † ) , where D † = ( D T D ) − 1 D T . The split ev aluation of a test sample y , | T i y − D + i ( D + i ) † T i y | , only inv olves matrix multiplication, which is of low computational complexity at the testing time. Giv en a data point y ⊆ R d , in this paper , we considered a square linear transformation T of size d × d . Note that, if we learn a “fat” linear transformation T of size r × d , where ( r < d ) , we enable dimension reduction along with transformation to handle very high-dimensional data. 2.5. Randomness in the Model: T ransf ormation F orest During the training phase, we introduce randomness into the forests through a combination of random training set sampling and randomized node optimization. W e train each classification tree on a dif ferent randomly selected training set. As discussed in ( Breiman , 2001 ; Criminisi & Shotton , 2013 ), this reduces possible overfitting and improv es the generalization of classification forests, also significantly re- ducing the training time. The randomized node optimiza- tion is achieved by randomly dividing classes arriving at each split node into two categories (given more than two classes), to obtain the training sets Y + and Y − . In ( 1 ), we learn a transformation optimized for a two-class problem. This randomly class di viding strate gy reduces a multi-class problem into a two-class problem at each node for transfor - mation learning; furthermore, it introduces node random- ness to avoid generating duplicated trees. Note that ( 1 ) is non-con ve x and the employed gradient descent method con ver ges to a local minimum. Initializing the transforma- tion T with different random matrices might lead to dif fer- ent local minimum solutions. The identity matrix initial- ization of T in this paper leads to e xcellent performance, howe v er , understanding the node randomness introduced by adopting different initializations of T is the subject of future research. 3. Experimental Evaluation This section presents experimental e valuations using pub- lic datasets: the MNIST handwritten digit dataset, the Ex- tended Y aleB face dataset, and the 15-Scenes natural scene dataset. The MNIST dataset consists of 8-bit grayscale handwritten digit images of “0” through “9” and 7000 ex- amples for each class. The Extended Y aleB face dataset contains 38 subjects with near frontal pose under 64 light- ing conditions (Fig. 2 ). All the images are resized to 16 × 16 for the MNIST and the Extended Y aleB datasets, which giv es a 256-dimensional feature. The 15-Scenes dataset contains 4485 images falling into 15 natural scene cate- gories (Fig. 3 ). The 15 categories include images of living rooms, kitchens, streets, industrials, etc. W e also present results for 3D data from the Kinect datatset in ( Denil et al. , 2013 ). W e first compare man y learners in a tree context for accuracy and testing time; then we compare with learners that are common for random forests. 3.1. Illustrative Examples Figure 2. Example illumination in the extended Y aleB dataset. W e construct classification trees on the extended Y aleB face dataset to compare different learners. W e split the dataset into two halves by randomly selecting 32 light- ing conditions for training, and the other half for testing. Fig. 4 illustrates the proposed transformation learner model in a classification tree constructed on faces of all 38 sub- jects. The third column shows that transformation learn- ers at each split node enforce separation between two ran- domly selected categories, and clearly demonstrates how data in each class is concentrated while the dif ferent classes Learning T ransformations f or Classification F orests −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.02 −0.01 0 0.01 0.02 −0.02 −0.01 0 0.01 0.02 0.03 0.04 (a) . −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.02 −0.01 0 0.01 0.02 −0.02 −0.01 0 0.01 0.02 0.03 0.04 (b) Original. −0.02 −0.01 0 0.01 0.02 0.03 0.04 −0.05 0 0.05 0.1 0.15 −0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 (c) T ransformed. 0 100 200 300 400 500 600 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.025 0.03 0.035 (d) . −0.01 0 0.0 1 0.02 0.03 −0.02 −0.01 0 0.01 0.0 2 0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05 0.06 (e) . −0.01 0 0.0 1 0.02 0.03 −0.02 −0.01 0 0.01 0.0 2 0.03 −0.02 −0.01 0 0.01 0.02 0.03 0.04 0.05 0.06 (f) Original. −0.03 −0.02 −0.01 0 0.01 0.02 0.03 −0.05 0 0.05 −0.04 −0.02 0 0.02 0.04 0.06 0.08 (g) T ransformed. 0 50 100 150 200 250 300 350 −0.025 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.025 (h) . −0.02 −0.01 0 0.01 0.02 0.03 −0.02 −0.01 0 0.01 0.02 0.03 −0.02 0 0.02 0.04 0.06 0.08 (i) . −0.02 −0.01 0 0.01 0.02 0.03 −0.02 −0.01 0 0.01 0.02 0.03 −0.02 0 0.02 0.04 0.06 0.08 (j) Original. −0.06 −0.04 −0.02 0 0.02 −0.1 −0.05 0 0.05 0.1 −0.08 −0.06 −0.04 −0.02 0 0.02 0.04 (k) T ransformed. 0 50 100 150 200 250 300 350 −0.06 −0.05 −0.04 −0.03 −0.02 −0.01 0 0.01 0.02 (l) . Figure 4. Transformation learners in a classification tree constructed on faces of 38 subjects. The root split node is shown in the first row and its two child nodes are in the 2nd and 3rd rows. The first column denotes training samples in the original subspaces, with different classes (subjects) in different colors. For visualization, the data are plotted with the dimension reduced to 3 using Laplacian Eigenmaps ( Belkin & Niyogi , 2003 ). As shown in the second column, we randomly divide arriving classes into two cate gories and learn a discriminativ e transformation using ( 1 ). The transformed samples are shown in the third column, clearly demonstrating how data in each class is concentrated while the different classes are separated. The fourth column sho ws the first dimension of transformed samples in the third column. Figure 3. 15-Scenes natural scene dataset. are separated. A maximum tree depth is typically specified for random forests to limit the size of a tree ( Criminisi & Shotton , 2013 ), which is dif ferent from algorithms like C4.5 ( Quin- lan , 1993 ) that gro w the tree only relying on termination criterion. The tree depth in this paper is the maximum tree depth. T o av oid under/over -fitting, we choose the maxi- mum tree depth through a validation process. W e also im- plement additional termination criteria to prev ent further training of a branch, e.g., the number of samples arri ving at a node. In T able 1 , we construct classification trees with a max- imum depth of 9 using different learners ( no maximum depth is defined for the C4.5 tree.). For reference pur - pose, we also include the performance of several subspace learning methods, which provide state-of-the-art classifi- cation accuracies on this dataset. Using a single classi- fication tree, the proposed transformation learner already significantly outperforms the popular weak learners deci- sion stump and conic section ( Criminisi & Shotton , 2013 ), where 100 trees are used (30 tries are adopted here). W e ob- serve that the proposed learner also outperforms more com- plex split functions SVM and LD A. The identity learner denotes the proposed framework but replacing the learned transformation with the identity matrix. Using a single tree, the proposed approach already outperforms state-of-the-art results reported on this dataset. As shown later , with ran- domness introduced, the performance in general increases further by employing more trees. While our learner has higher complexity compared to weak learners like decision stump, the performance for random forests is judged by the accuracy and test time. Increasing the number of trees (sublinearly) increases accuracy , at the Learning T ransformations f or Classification F orests 5 10 15 20 0.2 0.4 0.6 0.8 The number of trees (depth=9) Classification accuracy Transformation learner Decision stump Conic section (a) MNIST . 5 10 15 20 0.2 0.4 0.6 0.8 The number of trees (depth=5) Classification accuracy Transformation learner Decision stump Conic section (b) 15-Scenes. 5 10 15 20 25 30 0.2 0.4 0.6 0.8 The number of trees (depth=9) Classification accuracy Transformation learner Decision stump Conic section (c) Kinect. Figure 5. Classification accuracy using transformation learner forests. T able 1. Classification accuracies (%) and testing time for the Extended Y aleB dataset using classification trees with different learners. Method Accuracy T esting (%) time (s) Non-tree based methods D-KSVD ( Zhang & Li , 2010 ) 94.10 - LC-KSVD ( Jiang et al. , 2011 ) 96.70 - SRC ( Wright et al. , 2009 ) 97.20 - Classification trees Decision stump (1 tree) 28.37 0.09 Decision stump (100 trees) 91.77 13.62 Conic section (1 tree) 8.55 0.05 Conic section (100 trees) 78.20 5.04 C4.5 (1 tree) ( Quinlan , 1993 ) 39.14 0.21 LD A (1 tree) 38.32 0.12 LD A (100 trees) 94.98 7.01 SVM (1 tree) 95.23 1.62 Identity learner (1 tree) 84.95 0.29 T ransformation learner (1 tree) 98.77 0.15 cost of (linearly) increased test time ( Criminisi & Shotton , 2013 ). As shown in T able 1 , our learner exhibits similar test time as other weaker learners, but with significantly im- prov ed accuracy . By increasing the number of trees, other learners may approach our accurac y but at the cost of or - ders of magnitude more test time. Thus, the fact that 1-2 orders of magnitude less trees with our learned matrix out- performs standard random forests illustrates the importance of the proposed general transform learning framew ork. 3.2. Randomized T rees W e now ev aluate the effect of random training set sam- pling using the MNIST dataset. The MNIST dataset has a training set of 60000 examples, and a test set of 10000 examples. W e train 20 classification trees with a depth of 9, each using only 10% randomly selected training sam- ples (In this paper, we select the random training selection rate to provide each tree about 5000 training samples). As shown in Fig. 5a , the classification accuracy increases from 93.74% to 97.30% by increasing the number of trees to 20. Fig. 6 illustrates in detail the proposed transformation learner model in one of the trees. As discussed, increas- ing the number of trees (sublinearly) increases accuracy , at the cost of (linearly) increased test time. Though report- ing a better accuracy with hundreds of trees is an option (with limited pedagogical v alue), a few ( ∼ 20) trees are suf- ficient to illustrate the trade-off between accuracy and per- formance. Using the 15-Scenes dataset in Fig. 3 , we further ev aluate the ef fect of randomness introduced by randomly dividing classes arri ving at each split node into two categories. W e randomly use 100 images per class for training and used the remaining data for testing. W e train 20 classification trees with a depth of 5, each using all training samples. As sho wn in Fig. 5b , the classification accuracy increases from 66.23% to 79.06% by increasing the number of trees to 20. W e notice that, with only 20 trees, the accuracy is already comparable to state-of-the-art results reported on this dataset shown in T able 2 . W e in general expect the performance increases further by employing more trees. T able 2. Classification accuracies (%) for the 15-Scenes dataset. Method Accuracy (%) ScSPM ( Y ang et al. , 2009 ) 80.28 KSPM ( Lazebnik et al. , 2006 ) 76.73 KC ( Gemert et al. , 2008 ) 76.67 LSPM ( Y ang et al. , 2009 ) 65.32 T ransformation forests 79.06 3.3. Microsoft Kinect W e finally e valuate the proposed transformation learner in the task of predicting human body part labels from a depth Learning T ransformations f or Classification F orests −0.02 −0.01 0 0.01 0.02 −0.02 −0.01 0 0.01 0.02 −0.03 −0.02 −0.01 0 0.01 0.02 (a) . −0.02 −0.01 0 0.01 0.02 −0.02 −0.01 0 0.01 0.02 −0.03 −0.02 −0.01 0 0.01 0.02 (b) Original. −0.03 −0.02 −0.01 0 0.01 −0.02 −0.01 0 0.01 −0.03 −0.02 −0.01 0 0.01 0.02 (c) T ransformed. 0 200 400 600 800 1000 1200 1400 1600 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.025 (d) . −0.01 −0.005 0 0.005 0.01 0.015 0.02 −0.02 −0.01 0 0.01 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 (e) . −0.01 −0.005 0 0.005 0.01 0.015 0.02 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.03 −0.02 −0.01 0 0.01 0.02 0.03 (f) Original. −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 −0.01 −0.005 0 0.005 0.01 0.015 0.02 −0.04 −0.02 0 0.02 0.04 (g) T ransformed. 0 100 200 300 400 500 600 700 800 900 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 (h) . −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.04 −0.02 0 0.02 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 (i) . −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.04 −0.02 0 0.02 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 (j) Original. −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 −0.02 −0.01 0 0.01 0.02 −0.015 −0.01 −0.005 0 0.005 0.01 0.015 0.02 0.025 (k) T ransformed. 0 200 400 600 800 1000 1200 −0.02 −0.015 −0.01 −0.005 0 0.005 0.01 (l) . Figure 6. Transformation-based learners in a classification tree constructed on the MNIST dataset. The root split node is shown in the first row and its two child nodes are in the 2nd and 3rd rows. The first column denotes training samples in the original subspaces, with different classes in different colors. For visualization, the data are plotted with the dimension reduced to 3 using Laplacian Eigenmaps ( Belkin & Niyogi , 2003 ). As sho wn in the second column, we randomly di vide arri ving classes into two categories and learn a discriminative transformation using ( 1 ). The transformed samples are shown in the third column, clearly demonstrating how data in each class is concentrated while the dif ferent classes are separated. The fourth column shows the first dimension of transformed samples in the third column. image. W e adopt the Kinect datatset provided in ( Denil et al. , 2013 ), where pairs of 640 × 480 resolution depth and body part images are rendered from the CMU mocap dataset. The 19 body parts and one background class are represented by 20 unique color identifiers in the body part image. For this experiment, we only use the 500 testing poses from this dataset. W e use the first 450 poses for train- ing and remaining 50 poses for testing. During training, we sample 10 pixels for each body part in each pose and pro- duce 190 data points for each depth image. Each pixel is represented using depth difference from its 96 neighbors with radius 8, 32 and 64 respectively , forming a 288-dim descriptor . W e train 30 classification trees with a depth of 9, each using 5% randomly selected training samples. As shown in Fig. 5c , the classification accuracy increases from 55.48% to 73.12% by increasing the number of trees to 30. Fig. 7 shows an example input depth image, the groud truth body parts, and the prediction using the proposed method. 4. Conclusion W e introduced a transformation-based learner model for classification forests. Using the nuclear norm as opti- mization criteria, we learn a transformation at each split node that reduces variations/noises within the classes, and increases separations between the classes. The final classi- fication results combines multiple random trees. Thereby we expect the proposed framework to be very robust to noise. W e demonstrated the effecti veness of the proposed learner for classification forests, and provided theoretical support to these experimental results reported for very di- verse datasets. (a) Depth. (b) Groundtruth. (c) Prediction. Figure 7. Body parts prediction from a depth image using trans- formation forests. Learning T ransformations f or Classification F orests A. Proof of Theor em 1 Pr oof. W e know that (( Srebro et al. , 2005 )) || A || ∗ = min U , V A = UV 0 1 2 ( || U || 2 F + || V || 2 F ) . W e denote U A and V A the matrices that achie ve the mini- mum; same for B , U B and V B ; and same for the concate- nation [ A , B ] , U [ A , B ] and V [ A , B ] . W e then have || A || ∗ = 1 2 ( || U A || 2 F + || V A || 2 F ) , || B || ∗ = 1 2 ( || U B || 2 F + || V B || 2 F ) . The matrices [ U A , U B ] and [ V A , V B ] obtained by con- catenating the matrices that achiev e the minimum for A and B when computing their nuclear norm, are not neces- sarily the ones that achiev e the corresponding minimum in the nuclear norm computation of the concatenation matrix [ A , B ] . It is easy to show that || [ A , B ] || 2 F = || A || 2 F + || B || 2 F , where ||·|| F denotes the Frobenius norm. Thus, we have || [ A , B ] || ∗ = 1 2 ( || U [ A , B ] || 2 F + || V [ A , B ] || 2 F ) ≤ 1 2 ( || [ U A , U B ] || 2 F + || [ V A , V B ] || 2 F ) = 1 2 ( || U A || 2 F + || U B || 2 F + || V A || 2 F + || V B || 2 F ) = 1 2 ( || U A || 2 F + || V A || 2 F ) + 1 2 ( || U B || 2 F + || V B || 2 F ) = || A || ∗ + || B || ∗ . W e no w show the equality condition. W e perform the sin- gular value decomposition of A and B as A = [ U A1 U A2 ] Σ A 0 0 0 [ V A1 V A2 ] 0 , B = [ U B1 U B2 ] Σ B 0 0 0 [ V B1 V B2 ] 0 , where the diagonal entries of Σ A and Σ B contain non-zero singular values. W e hav e AA 0 = [ U A1 U A2 ] Σ A 2 0 0 0 [ U A1 U A2 ] 0 , BB 0 = [ U B1 U B2 ] Σ B 2 0 0 0 [ U B1 U B2 ] 0 . The column spaces of A and B are considered to be or- thogonal, i.e., U A1 0 U B1 = 0 . The above can be written as AA 0 = [ U A1 U B1 ] Σ A 2 0 0 0 [ U A1 U B1 ] 0 , BB 0 = [ U A1 U B1 ] 0 0 0 Σ B 2 [ U A1 U B1 ] 0 . Then, we hav e [ A , B ][ A , B ] 0 = AA 0 + BB 0 = [ U A1 U B1 ] Σ A 2 0 0 Σ B 2 [ U A1 U B1 ] 0 . The nuclear norm || A || ∗ is the sum of the square root of the singular values of AA 0 . Thus, || [ A , B ] || ∗ = || A || ∗ + || B || ∗ . B. Basic Propositions Proposition 2. Let A and B be matrices of the same r ow dimensions, and [ A , B ] be the concatenation of A and B , we have || [ A , B ] || 2 ≤ || A || 2 + || B || 2 , with equality if at least one of the two matrices is zer o. Proposition 3. Let A and B be matrices of the same r ow dimensions, and [ A , B ] be the concatenation of A and B , we have || [ A , B ] || F ≤ || A || F + || B || F , with equality if and only if at least one of the two matrices is zer o. References Aharon, M., Elad, M., and Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE T rans. on Signal Pr ocess- ing , 54(11):4311–4322, Nov . 2006. Basri, R. and Jacobs, D. W . Lambertian reflectance and linear subspaces. IEEE T rans. on P att. Anal. and Mach. Intell. , 25(2):218–233, 2003. Belkin, M. and Niyogi, P . Laplacian eigenmaps for dimen- sionality reduction and data representation. Neural Com- putation , 15:1373–1396, 2003. Breiman, L. Random forests. Machine Learning , 45(1): 5–32, 2001. Learning T ransformations f or Classification F orests Cand ` es, E. J., Li, X., Ma, Y ., and Wright, J. Robust prin- cipal component analysis? J. A CM , 58(3):11:1–11:37, June 2011. Criminisi, A. and Shotton, J. Decision F or ests for Com- puter V ision and Medical Image Analysis . Springer , 2013. Denil, M., Matheson, D., and Nando, D. F . Consistency of online random forests. In International Confer ence on Machine Learning , 2013. Elhamifar , E. and V idal, R. Sparse subspace clustering: Al- gorithm, theory , and applications. IEEE T rans. on P att. Anal. and Mac h. Intell. , 2013. T o appear . Fazel, M. Matrix Rank Minimization with Applications. PhD thesis, Stanfor d University , 2002. Gall, J. and Lempitsky , V . Class-specific hough forests for object detection. In Proc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , 2009. Gemert, J. C., Geusebroek, J., V eenman, C. J., and Smeul- ders, A. W . K ernel codebooks for scene categoriza- tion. In Pr oc. Eur opean Confer ence on Computer V ision , 2008. Hastie, T . and Simard, P . Y . Metrics and models for hand- written character recognition. Statistical Science , 13(1): 54–65, 1998. Jiang, Z., Lin, Z., and Davis, L. S. Learning a discrimi- nativ e dictionary for sparse coding via label consistent K-SVD. In Pr oc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , Colorado springs, CO, 2011. Kuybeda, O., Frank, G. A., Bartesaghi, A., Borgnia, M., Subramaniam, S., and Sapiro, G. A collaborativ e frame- work for 3D alignment and classification of heteroge- neous sub volumes in cryo-electron tomography . Journal of Structural Biology , 181:116–127, 2013. Lazebnik, S., Schmid, C., and Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing nat- ural scene categories. In Pr oc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , 2006. Miao, J. and Ben-Israel, A. On principal angles between subspaces in rn. Linear Algebra and its Applications , 171(0):81 – 98, 1992. Moosmann, F ., T riggs, B., and Jurie, F . Fast discriminati ve visual codebooks using randomized clustering forests. In Advances in Neural Information Pr ocessing Systems , 2007. Peng, Y ., Ganesh, A., Wright, J., Xu, W ., and Ma, Y . RASL: Robust alignment by sparse and lo w-rank de- composition for linearly correlated images. In Pr oc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , San Francisco, USA, 2010. Qiu, Q. and Sapiro, G. Learning transformations for clus- tering and classification. CoRR , abs/1309.2074, 2013. Quinlan, J. Ross. C4.5: Pr ograms for Machine Learning . Morgan Kaufmann Publishers Inc., 1993. Recht, B., Fazel, M., and Parrilo, P . A. Guaranteed min- imum rank solutions to linear matrix equations via nu- clear norm minimization. SIAM Review , 52(3):471–501, 2010. Shen, X. and W u, Y . A unified approach to salient object detection via low rank matrix recov ery . In Pr oc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , Rhode Island, USA, 2012. Shotton, J., Girshick, R., Fitzgibbon, A., Sharp, T ., Cook, M., Finocchio, M., Moore, R., K ohli, P ., Criminisi, A., Kipman, A., and Blake, A. Ef ficient human pose esti- mation from single depth images. IEEE T r ans. on P att. Anal. and Mac h. Intell. , 99(PrePrints), 2012. Srebro, N., Rennie, J., and Jaakkola, T . Maximum margin matrix factorization. In Advances in Neural Information Pr ocessing Systems , V ancouver , Canada, 2005. T omasi, C. and Kanade, T . Shape and motion from im- age streams under orthography: a factorization method. International Journal of Computer V ision , 9:137–154, 1992. Wright, J., Y ang, M., Ganesh, A., Sastry , S., and Ma, Y . Robust face recognition via sparse representation. IEEE T rans. on P att. Anal. and Mach. Intell. , 31(2):210–227, 2009. Y ang, J., Y u, K., Gong, Y ., and Huang, T . Linear spatial pyramid matching using sparse coding for image classi- fication. In Proc. IEEE Computer Society Conf. on Com- puter V ision and P att. Recn. , 2009. Zhang, Q. and Li, B. Discriminati ve k-SVD for dictionary learning in face recognition. In Pr oc. IEEE Computer Society Conf. on Computer V ision and P att. Recn. , San Francisco, CA, 2010. Zhang, Z., Liang, X., Ganesh, A., and Ma, Y . TIL T: trans- form inv ariant low-rank textures. In Pr oc. Asian con- fer ence on Computer vision , Queensto wn, New Zealand, 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment