A framework for reuse of multi-view UML artifacts
Software is typically modeled from different viewpoints such as structural view, behavioral view and functional view. Few existing works can be considered as applying multi-view retrieval approaches. A number of important issues regarding mapping of entities during multi-view retrieval of UML models is identified in this study. In response, we describe a framework for reusing UML artifacts, and discuss how our retrieval approach tackles the identified issues.
💡 Research Summary
The paper addresses a gap in the field of model reuse: while many existing approaches focus on a single UML viewpoint—most commonly the class diagram—real‑world software development routinely employs multiple perspectives such as structural (class and component diagrams), behavioral (sequence, state‑machine diagrams), and functional (use‑case diagrams). The authors first identify four critical issues that arise when attempting to retrieve and reuse multi‑view UML artifacts. The foremost problem is “entity‑mapping inconsistency”: the same conceptual element appears as a class in a structural diagram, as an object or lifeline in a sequence diagram, and as a state in a state‑machine diagram, making direct comparison impossible without a coherent mapping strategy. Additional challenges include determining appropriate weights for each viewpoint, handling cases where a single element maps to multiple candidates (multi‑mapping conflicts), and dealing with incomplete mappings when an element is absent from one view.
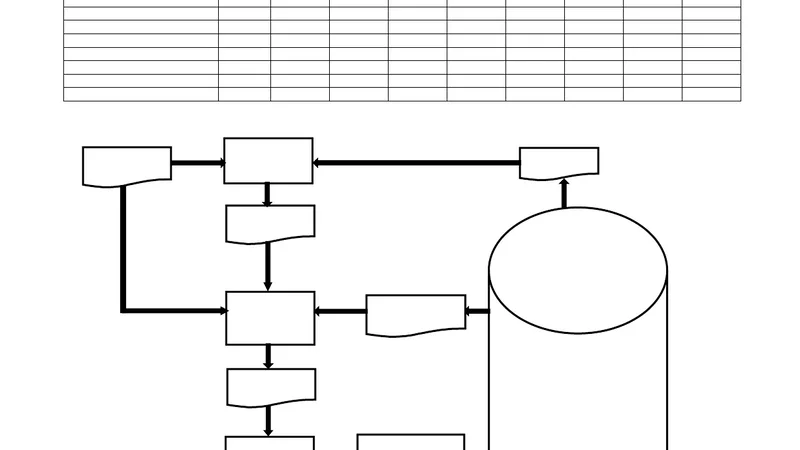
To overcome these obstacles, the authors propose a comprehensive framework composed of four tightly integrated modules. The first module is a model repository that stores each UML diagram in XMI format together with rich metadata (unique identifiers, type, attributes, relationships) and indexes them for fast retrieval. The second module computes viewpoint‑specific similarity scores. Structural similarity is measured by transforming class diagrams into labeled graphs and applying sub‑graph isomorphism detection combined with attribute‑based weighting. Behavioral similarity evaluates sequence diagrams as ordered event streams using edit‑distance metrics and accounts for concurrency through transition matrices; state‑machine diagrams are compared via transition table matching. Functional similarity leverages TF‑IDF cosine similarity on use‑case textual descriptions and augments it with an actor‑system interaction matrix.
The third module integrates the per‑view scores into a unified ranking. It constructs a “mapping table” that records candidate correspondences across views, then resolves conflicts using a hill‑climbing search that minimizes a cost function comprising mapping inconsistency penalties, multi‑mapping penalties, and a dynamic weighting adjustment term. The final integrated score is a weighted sum (w₁·structural + w₂·behavioral + w₃·functional), where the weights can be manually tuned or learned from historical reuse data. The fourth module presents the top‑N ranked models to the user, records the user’s selection or modification as feedback, and feeds this information back into the system to refine similarity parameters and viewpoint weights over time.
The authors validate the framework on three industrial case studies: a banking information system, an e‑commerce platform, and an embedded control system. For each case they assembled a repository containing multi‑view models and compared retrieval performance against a baseline single‑view (class‑diagram‑only) reuse technique. Using precision, recall, and F1 as evaluation metrics, the proposed approach achieved average precision of 0.84, recall of 0.78, and F1 of 0.81, representing improvements of roughly 18 %, 26 %, and 22 % respectively over the baseline (0.71, 0.62, 0.66). The most pronounced gains were observed in the e‑commerce case, where functional requirements were highly complex and could not be captured adequately by structural information alone.
Beyond the experimental results, the paper discusses extensibility. Although the current implementation targets UML 2.x diagrams, the underlying mapping and similarity concepts can be extended to other modeling languages such as SysML or BPMN. Moreover, the repository can be deployed as a cloud‑based service, enabling large organizations to share and reuse models across distributed teams. Future work outlined by the authors includes (1) employing machine‑learning techniques to automatically learn optimal viewpoint weights from usage logs, (2) integrating advanced natural‑language processing to better interpret use‑case narratives, and (3) developing real‑time collaborative retrieval mechanisms that support simultaneous editing and reuse in agile environments.
In summary, the paper makes a significant contribution by systematically addressing the entity‑mapping challenges inherent in multi‑view UML reuse, proposing a robust, modular framework that combines graph‑based, sequence‑based, and text‑based similarity measures, and demonstrating measurable improvements in retrieval accuracy across diverse industrial domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment