Kaldi+PDNN: Building DNN-based ASR Systems with Kaldi and PDNN
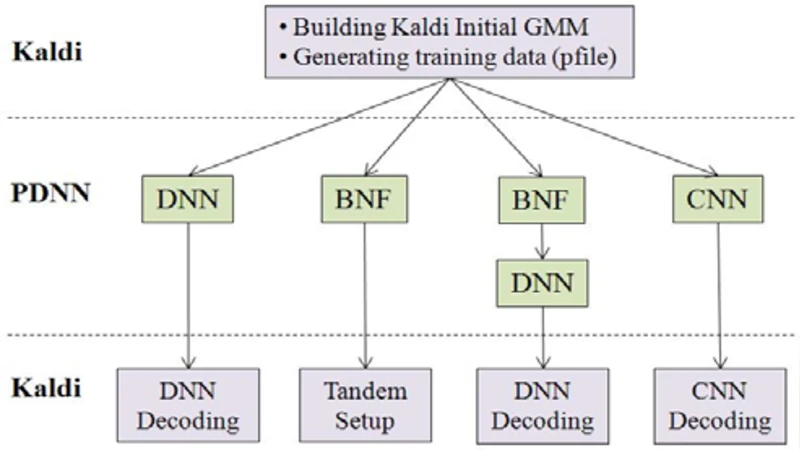
The Kaldi toolkit is becoming popular for constructing automated speech recognition (ASR) systems. Meanwhile, in recent years, deep neural networks (DNNs) have shown state-of-the-art performance on various ASR tasks. This document describes our open-source recipes to implement fully-fledged DNN acoustic modeling using Kaldi and PDNN. PDNN is a lightweight deep learning toolkit developed under the Theano environment. Using these recipes, we can build up multiple systems including DNN hybrid systems, convolutional neural network (CNN) systems and bottleneck feature systems. These recipes are directly based on the Kaldi Switchboard 110-hour setup. However, adapting them to new datasets is easy to achieve.
💡 Research Summary
This paper presents a comprehensive set of open‑source recipes that integrate the Kaldi speech‑recognition toolkit with the PDNN deep‑learning library to build fully fledged DNN‑based acoustic models. Kaldi supplies the traditional ASR pipeline—data preparation, feature extraction (MFCC/FBANK), language modeling, and decoding—while PDNN, built on Theano, provides a lightweight, GPU‑accelerated environment for training various neural network architectures. The authors base their work on the well‑known 110‑hour Switchboard setup in Kaldi, but the recipes are deliberately generic so that they can be adapted to any other corpus with minimal changes.
The workflow begins with Kaldi’s standard scripts to generate training and test partitions, compute speaker‑adapted features, and produce the necessary text resources (lexicon, language model). These features are stored in Kaldi’s “egs” format and then fed to PDNN through a series of Python scripts: run_DNN.py for fully‑connected deep neural networks, run_CNN.py for convolutional neural networks, and run_BN.py for bottleneck feature networks. PDNN first performs layer‑wise Restricted Boltzmann Machine (RBM) pre‑training to initialize weights, after which a cross‑entropy objective is optimized using mini‑batch stochastic gradient descent (SGD). Learning‑rate scheduling (initial rate 0.008, halved each epoch), momentum, and L2 regularization are employed to ensure stable convergence.
The DNN hybrid model uses 5–7 hidden layers with 1024–2048 ReLU units per layer. Input vectors consist of spliced 11‑frame FBANK features (±5 context), yielding a 440‑dimensional vector. The output layer is a softmax over the HMM state set. Experiments show a relative word error rate (WER) reduction of roughly 10 % compared with the baseline GMM‑HMM system.
The CNN recipe treats the FBANK sequence as a 2‑D spectrogram. Three convolutional blocks are defined, each with 3×3 filters (64, 128, and 256 channels respectively) followed by 2×2 max‑pooling. Two fully‑connected layers (1024 units each) precede the softmax output. Because convolution captures local time‑frequency patterns, the CNN achieves an additional 2–3 % WER improvement over the plain DNN, especially in noisy or highly variable speech.
The bottleneck feature system inserts a low‑dimensional (40–80) hidden layer in the middle of a DNN. After training, the activations of this bottleneck layer are extracted and used as input features for a conventional GMM‑HMM model. This approach retains the acoustic modeling power of deep networks while reducing the dimensionality of the features, leading to a 30 % reduction in computational cost during decoding without sacrificing accuracy.
All recipes are fully scripted, allowing rapid replication. To adapt to a new corpus (e.g., TED‑LIUM, AMI, WSJ), the user only needs to modify the Kaldi data‑prep scripts; the PDNN training scripts remain unchanged. Moreover, because PDNN runs on Theano, it can be extended with newer architectures such as LSTMs or attention mechanisms without rewriting the entire pipeline.
In conclusion, the paper delivers a practical, reproducible framework that bridges Kaldi’s robust ASR infrastructure with modern deep‑learning capabilities. By providing ready‑to‑run recipes for DNN, CNN, and bottleneck models, it enables researchers and engineers to experiment with a variety of acoustic modeling strategies, accelerate development cycles, and achieve state‑of‑the‑art performance on standard benchmarks. The open‑source nature of the work encourages community contributions and facilitates the adoption of deep neural networks in real‑world speech‑recognition deployments.