Spectral redemption: clustering sparse networks
Spectral algorithms are classic approaches to clustering and community detection in networks. However, for sparse networks the standard versions of these algorithms are suboptimal, in some cases completely failing to detect communities even when othe…
Authors: Florent Krzakala, Cristopher Moore, Elchanan Mossel
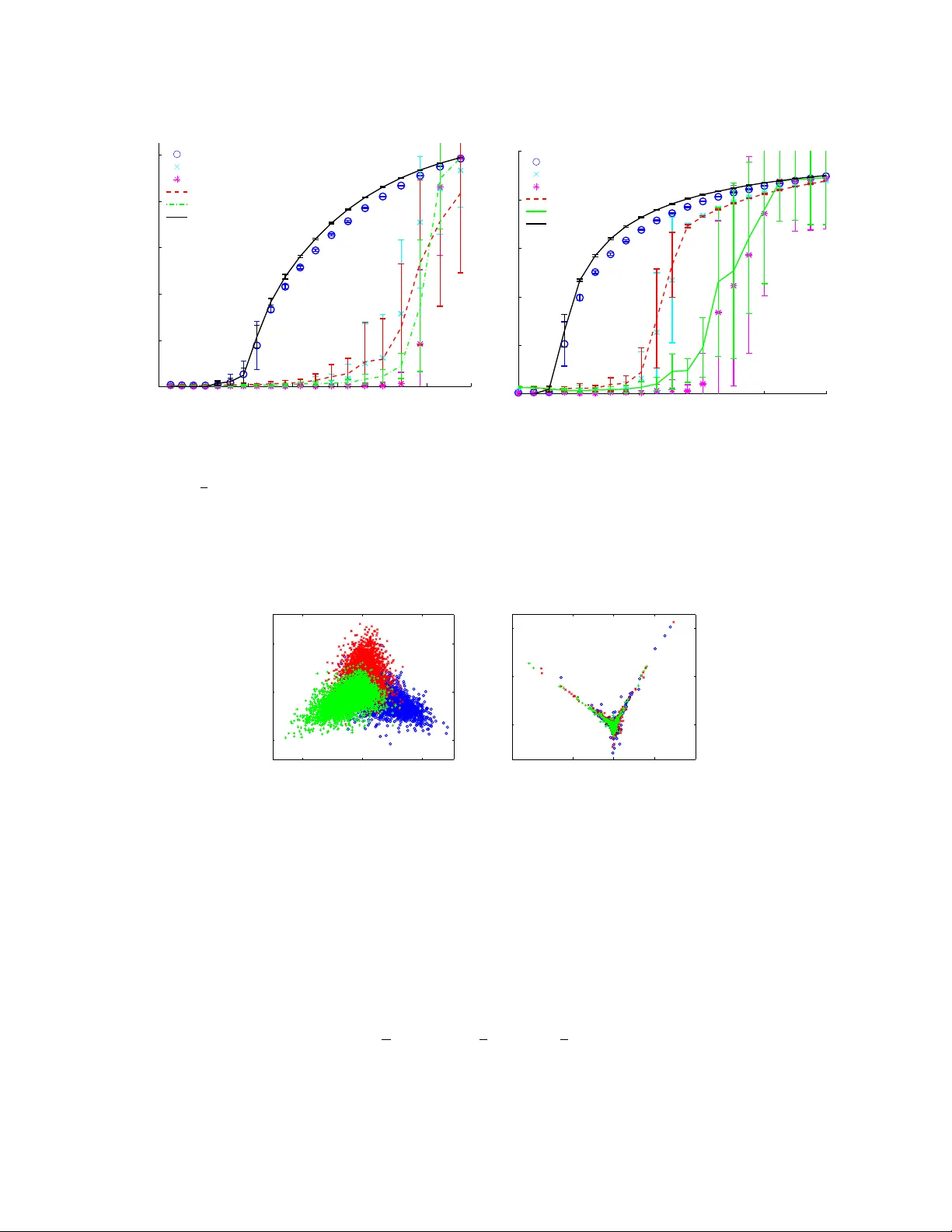
Sp ectral redemption: clustering sparse net w orks Floren t Krzak ala 1 , Cristopher Moore 2 , Elchanan Mossel 3 Jo e Neeman 3 , Allan Sly 3 , Lenk a Zdeb oro v á 4 and Pan Zhang 1 , 2 1 ESPCI and CNRS UMR 7083, 10 rue V auquelin,Paris 75005 2 Santa F e Institute, 1399 Hyde Park R o ad, Santa F e NM 87501, USA 3 University of California, Berkeley 4 Institut de Physique Thé orique, CEA Saclay and URA 2306, CNRS, 91191 Gif-sur-Yvette, F r anc e (Dated: August 26, 2013) Sp ectral algorithms are classic approac hes to clustering and communit y detection in net works. Ho wev er, for sparse net works the standard v ersions of these algorithms are sub optimal, in some cases completely failing to detect comm unities even when other algorithms such as b elief propagation can do so. Here we in tro duce a new class of spectral algorithms based on a non-bac ktrac king walk on the directed edges of the graph. The sp ectrum of this op erator is muc h b etter-b eha ved than that of the adjacency matrix or other commonly used matrices, maintaining a strong separation b et w een the bulk eigenv alues and the eigen v alues relev an t to communit y structure even in the sparse case. W e sho w that our algorithm is optimal for graphs generated by the sto chastic blo ck mo del, detecting comm unities all the wa y down to the theoretical limit. W e also show the spectrum of the non-bac ktracking op erator for some real-w orld net works, illustrating its adv antages ov er traditional sp ectral clustering. Detecting comm unities or modules is a central task in the study of so cial, biological, and technological netw orks. T w o of the most popular approaches are statistical inference, where we fix a generative mo del suc h as the sto c hastic blo c k mo del to the net work [1, 2]; and sp ectral metho ds, where we classify vertices according to the eigen vectors of a matrix associated with the net w ork suc h as its adjacency matrix or Laplacian [3]. Both statistical inference and sp ectral methods hav e been shown to work well in netw orks that are sufficiently dense, or when the graph is regular [4 – 8]. How ev er, for sparse netw orks with widely v arying degrees, the communit y detection problem is harder. Indeed, it w as recen tly shown [9 – 11] that there is a phase transition b elow which comm unities present in the underlying blo c k mo del are imp ossible for any algorithm to detect. While standard sp ectral algorithms succeed down to this transition when the netw ork is sufficiently dense, with an av erage degree growing as a function of netw ork size [8], in the case where the av erage degree is constant these metho ds fail significantly ab o ve the transition [12]. Thus there is a large regime in whic h statistical inference succeeds in detecting communities, but where curren t spectral algorithms fail. It was conjectured in [11] that this gap is artificial and that there exists a sp ectral algorithm that succeeds all the wa y to the detectability transition ev en in the sparse case. Here, w e prop ose an algorithm based on a linear op erator considerably differen t from the adjacency matrix or its v arian ts: namely , a matrix that represents a w alk on the directed edges of the netw ork, with backtrac king prohibited. W e giv e strong evidence that this algorithm indeed closes the gap. The fact that this op erator has b etter sp ectral prop erties than, for instance, the standard random walk op erator has b een used in the past in the context of random matrices and random graphs [13 – 15]. In the theory of zeta functions of graphs, it is kno wn as the edge adjacency op erator, or the Hashimoto matrix [16]. It has b een used to show fast mixing for the non-backtrac king random walk [17], and arises in connection to b elief propagation [18, 19], in particular to rigorously analyze the b ehavior of b elief propagation for clustering problems on regular graphs [5]. It has also b een used as a feature vector to classify graphs [20]. How ev er, using this op erator as a foundation for sp ectral clustering and comm unit y detection appears to b e nov el. W e sho w that the resulting sp ectral algorithms are optimal for netw orks generated b y the sto c hastic blo c k mo del, finding communities all the wa y down to the detectability transition. That is, at any p oint ab o ve this transition, there is a gap b et w een the eigenv alues related to the communit y structure and the bulk distribution of eigenv alues coming from the random graph structure, allo wing us to find a lab eling correlated with the true communities. In addition to our analytic results on sto chastic blo c k mo dels, we also illustrate the adv antages of the non-bac ktracking op erator o ver existing approac hes for some real netw orks. 2 - 4 - 2 0 2 4 0.05 0.10 0.15 0.20 0.25 c FIG. 1: The sp ectrum of the adjacency matrix of a sparse netw ork generated by the blo c k mo del (excluding the zero eigenv alues). Here n = 4000 , c in = 5 , and c out = 1 , and we a verage ov er 20 realizations. Even though the eigen v alue λ c = 3 . 5 given by (2) satisfies the threshold condition (1) and lies outside the semicircle of radius 2 √ c = 3 . 46 , deviations from the semicircle law cause it to get lost in the bulk, and the eigenv ector of the second largest eigenv alue is uncorrelated with the communit y structure. As a result, sp ectral algorithms based on A are unable to iden tify the communities in this case. I. SPECTRAL CLUSTERING AND SP ARSE NETW ORKS In order to study the effectiv eness of sp ectral algorithms in a sp ecific ensem ble of graphs, supp ose that a graph G is generated by the sto chastic blo ck mo del [1]. There are q groups of vertices, and each vertex v has a group lab el g v ∈ { 1 , . . . , q } . Edges are generated indep enden tly according to a q × q matrix p of probabilities, with Pr[ A u,v = 1] = p g u ,g v . In the sparse case, we ha v e p ab = c ab /n , where the affinity matrix c ab sta ys constant in the limit n → ∞ . F or simplicit y we first discuss the commonly-studied case where c has tw o distinct entries, c ab = c in if a = b and c out if a 6 = b . W e take q = 2 with tw o groups of equal size, and assume that the net work is assortativ e, i.e., c in > c out . W e summarize the general case of more groups, arbitrary degree distributions, and so on in subsequent sections b elo w. The group lab els are hidden from us, and our goal is to infer them from the graph. Let c = ( c in + c out ) / 2 denote the a v erage degree. The detectability threshold [9–11] states that in the limit n → ∞ , unless c in − c out > 2 √ c , (1) the randomness in the graph washes out the blo ck structure to the extent that no algorithm can lab el the vertices b etter than c hance. Moreo ver, [11] pro ved that b elo w this threshold, it is imp ossible to identify the parameters c in and c out , while ab ov e the threshold the parameters c in and c out are easily identifiable. The adjacency matrix is defined as the n × n matrix A u,v = 1 if ( u, v ) ∈ E and 0 otherwise. A t ypical spectral algorithm assigns eac h vertex a k -dimensional vector according to its entries in the first k eigenv ectors of A for some k , and clusters these vectors according to a heuristic suc h as the k -means algorithm (often after normalizing or w eighting them in some w a y). In the case q = 2 , we can simply lab el the vertices according to the sign of the second eigenv ector. As sho wn in [8], sp ectral algorithms succeed all the wa y do wn to the threshold (1) if the graph is sufficiently dense. In that case A ’s sp ectrum has a discrete part and a con tinuous part in the limit n → ∞ . Its first eigen vector essentially sorts vertices according to their degree, while the second eigen vector is correlated with the communities. The second eigen v alue is given by λ c = c in − c out 2 + c in + c out c in − c out . (2) The question is when this eigen v alue gets lost in the contin uous bulk of eigenv alues coming from the randomness in the graph. This part of the sp ectrum, lik e that of a sufficiently dense Erdős-Rényi random graph, is asymptotically distributed according to Wigner’s semicircle law [21] P ( λ ) = 1 2 π c p 4 c − λ 2 . 3 - 1 1 2 3 - 1.5 - 1.0 - 0.5 0.5 1.0 1.5 µ c FIG. 2: The sp ectrum of the non-b ac ktrac king matrix B for a net work generated by the block mo del with same parameters as in Fig. 1. The leading eigenv alue is at c = 3 , the second eigenv alue is close to µ c = ( c in − c out ) / 2 = 2 , and the bulk of the sp ectrum is confined to the disk of radius √ c = √ 3 . Since µ c is outside the bulk, a sp ectral algorithm that lab els vertices according to the sign of B ’s second eigenv ector (summed o ver the incoming edges at eac h vertex) lab els the ma jorit y of vertices correctly . Th us the bulk of the sp ectrum lies in the interv al [ − 2 √ c, 2 √ c ] . If λ c > c , whic h is equiv alent to (1), the sp ectral algorithm can find the corresp onding eigenv ector, and it is correlated with the true comm unit y structure. Ho wev er, in the sparse case where c is constan t while n is large, this picture breaks down due to a num b er of reasons. Most imp ortan tly , the leading eigenv alues of A are dictated b y the v ertices of highest degree, and the corresp onding eigenv ectors are lo calized around these v ertices [22]. As n gro ws, these eigenv alues exceed λ c , swamping the communit y-correlated eigen v ector, if an y , with the bulk of uninformative eigenv ectors. As a result, sp ectral algorithms based on A fail a significant distance from the threshold given by (1). Moreo v er, this gap gro ws as n increases: for instance, the largest eigen v alue gro ws as the square ro ot of the largest degree, which is roughly prop ortional to log n/ log log n for Erdős-Rényi graphs. T o illustrate this problem, the sp ectrum of A for a large graph generated b y the blo ck mo del is depicted in Fig. 1. Other p opular op erators for sp ectral clustering include the Laplacian L = D − A where D uv = d u δ u,v is the diagonal matrix of vertex degrees, the random walk matrix Q uv = A uv /d u , and the mo dularity matrix M uv = A uv − d u d v / (2 m ) . Ho wev er, all these exp erience qualitativ ely the same difficulties as with A in the sparse case. Another simple heuristic is to simply remo ve the high-degree vertices (e.g. [6]), but this throws a wa y a significant amoun t of information; in the sparse case it can even destroy the gian t comp onen t, causing the graph to fall apart into disconnected pieces [23]. I I. THE NON-BA CKTRACKING OPERA TOR The main contribution of this pap er is to show how to redeem the p erformance of spectral algorithms in sparse net works by using a differen t linear op erator. The non-b acktr acking matrix B is a 2 m × 2 m matrix, defined on the directed edges of the graph. Specifically , B ( u → v ) , ( w → x ) = ( 1 if v = w and u 6 = x 0 otherwise . Using B rather than A addresses the problem described ab o ve. The spectrum of B is not sensitive to high-degree v ertices, since a walk starting at v cannot turn around and return to it immediately . Other con venien t prop erties of B are that any tree dangling off the graph, or disconnected from it, simply contributes zero eigen v alues to the sp ectrum, since a non-backtrac king w alk is forced to a leaf of the tree where it has nowhere to go. Similarly one can show that unicyclic components yield eigenv alues that are either 0 , 1 or − 1 . As a result, B has the follo wing sp ectral prop erties in the limit n → ∞ in the ensemble of graphs generated b y the blo c k mo del. The leading eigenv alue is the av erage degree c = ( c in + c out ) / 2 . At any point ab o v e the detectability 4 threshold (1), the second eigen v alue is asso ciated with the blo c k structure and reads µ c = c in − c out 2 . (3) Moreo ver, the bulk of B ’s sp ectrum is confined to the disk in the complex plane of radius √ c , as shown in Fig. 2. As a result, the second eigenv alue is w ell separated from the top of the bulk, i.e., from the third largest eigenv alue in absolute v alue, as sho wn in Fig. 3. The eigenv ector corresp onding to µ c is strongly correlated with the communit y structure. Since B is defined on directed edges, at eac h vertex we sum this eigenv ector ov er all its incoming edges. If we lab el v ertices according to the sign of this sum, then the ma jorit y of vertices are lab eled correctly (up to a change of sign, which switches the t wo communities). Th us a sp ectral algorithm based on B succeeds when µ c > √ c , i.e. when (1) holds—but unlike standard sp ectral algorithms, this criterion now holds even in the sparse case. W e present arguments for these claims in the next section. I II. RECONSTRUCTION AND A COMMUNITY-CORRELA TED EIGENVECTOR In this section we sketc h justifications of the claims in the previous section regarding B ’s sp ectral prop erties, sho wing that its second eigenv ector is correlated with the communities whenever (1) holds. Let us start b y recalling ho w to generalize equation (2) for the adjacency matrix A of sparse graphs. W e follow [11], who derived a similar result in the case of random regular graphs. With µ = µ c defined as in (3), for a given integer r , consider the vector f ( r ) v = µ − r X u : d ( u,v )= r σ u , (4) where σ u = ± 1 denotes u ’s communit y . By the theory of the reconstruction problem on trees [24, 25], if (1) holds then the correlation h f ( r ) , σ i /n is b ounded aw a y from zero in the limit n → ∞ . W e will show that if r is large but small compared to the diameter of the graph, then f ( r ) is closely related to the second eigenv ector of B . Thus if we lab el v ertices according to the sign of this second eigenv ector (summed ov er all incoming edges at each vertex) w e obtain the true communities with significan t accuracy . First we show that f ( r ) appro ximately ob eys an eigen v alue equation that generalizes (2). As long as the radius- r neigh b orho od of v is a tree, w e ha ve ( Af ( r ) ) v = µ − r X u : d ( u,v )= r +1 σ u + ( d v − 1) X u : d ( u,v )= r − 1 σ u , so ( Af ( r ) ) v = µf ( r +1) v + ( d v − 1) µ − 1 f ( r − 1) v . (5) Summing o v er v ’s neighborho o d giv es the exp ectation E " X u ∈ N ( v ) σ u # = µσ v , and summing the fluctuations o ver the (in exp ectation) c r v ertices at distance r giv es f ( r ) v − f ( r ± 1) v = O ( c r/ 2 µ − r ) . If µ = µ c and (1) holds so that µ c > √ c , these fluctuations tend to zero for large r . In that case, we can identify f ( r ) with f ( r ± 1) , and (5) b ecomes Af = µf + ( D − 1 ) µ − 1 f . (6) In particular, in the dense case w e can recov er (2) by approximating D with c 1 , or equiv alen tly pretending that the graph is c -regular. Then f is an eigenv ector of A with eigenv alue λ c = µ + ( c − 1) µ − 1 . 5 W e define an analogous approximate eigenv ector of B , g ( r ) u → v = µ − r X ( w,x ): d ( u → v ,w → x )= r σ x , where no w d refers to the num b er of steps in the graph of directed edges . W e hav e in exp ectation B g ( r ) = µg ( r +1) , and as b efore | g ( r ) − g ( r +1) | tends to zero as r increases. Iden tifying them giv es an approximate eigenv ector g with eigen v alue µ , B g = µg . (7) F urthermore, summing ov er all incoming edges gives X u ∈ N ( v ) g u → v = f v , giving signs correlated with the true communit y memberships σ v . W e note that the relation b etw een the eigen v alue equation (7) for B and the quadratic eigenv alue equation (6) is exact and w ell known in the theory of zeta functions of graphs [16, 26, 27]. More generally , all eigenv alues µ of B that are not ± 1 are the ro ots of the equation det µ 2 1 − µA + ( D − 1 ) = 0 . (8) This equation hence describ es 2 n of B ’s eigenv alues. These are the eigen v alues of a 2 n × 2 n matrix, B 0 = 0 D − 1 − 1 A . (9) The left eigen vectors of B 0 are of the form ( f , − µf ) where f obeys (6). Th us we can find f by dealing with a 2 n × 2 n matrix rather than a 2 m × 2 m one, which considerably reduces the computational complexity of our algorithm. Next, we argue that the bulk of B ’s spectrum is confined to the disk of radius √ c . First note that for any matrix B , 2 m X i =1 | µ i | 2 r ≤ tr B r ( B r ) T . On the other hand, for an y fixed r , since G is lo cally treelike in the limit n → ∞ , each diagonal entry ( u → v , u → v ) of B r ( B r ) T is equal to the n um b er of vertices exactly r steps from v , other than those connected via u . In expectation this is c r , so by linearit y of exp ectation E tr B r ( B r ) T = 2 mc r . In that case, the spectral measure has the prop ert y that E ( | µ | 2 r ) ≤ c r . Since this holds for any fixed r , w e conclude that almost all of B ’s eigenv alues ob ey | µ | ≤ √ c . Proving rigorously that al l the eigen v alues in the bulk are asymptotically confined to this disk requires a more precise argument and is left for future work. As a side remark we note that (8) yields B ’s sp ectrum for d -regular graphs [27]. There are n pairs of eigenv alues µ ± suc h that µ ± = λ ± p λ 2 − 4( d − 1) 2 , (10) where λ are the (real) eigenv alues of A . These are related by µ + µ − = d − 1 , so all the non-real eigenv alues of B are conjugate pairs on the circle of radius √ d − 1 . The other eigen v alues are ± 1 . F or random regular graphs, the asymptotic spectral density of B follows straightforw ardly from the well known result of [13] for the sp ectral density of the adjacency matrix. Finally , the singular v alues of B are easy to derive for an y simple graph, i.e., one without self-loops or multiple edges. Namely , B B T is blo ck-diagonal: for each vertex v , it has a rank-one block of size d v that connects v ’s outgoing edges to eac h other. As a consequence, B has n singular v alues d v − 1 , and its other 2 m − n singular v alues are 1 . Ho wev er, since B is not symmetric, its eigen v alues and its singular v alues are differen t—while its singular v alues are con trolled b y the v ertex degrees, its eigenv alues are not. This is precisely why its sp ectral properties are b etter than those of A and related op erators. 6 3 4 5 6 1.8 2.2 2.6 3 c in −c out µ 1 µ 2 |µ 3 | theory sqrt(3) FIG. 3: The first, second and third largest eigenv alues µ 1 , µ 2 and | µ 3 | respectively of B as functions of c in − c out . The third eigen v alue is complex, so w e plot its mo dulus. V alues are a veraged ov er 20 netw orks of size n = 10 5 and a verage degree c = 3 . The green line in the figure represents µ c = ( c in − c out ) / 2 , and the horizontal lines are c and √ c resp ectiv ely . The second eigen v alue µ 2 is w ell-separated from the bulk throughout the detectable regime. IV. MORE THAN TWO GROUPS AND GENERAL DEGREE DISTRIBUTIONS The argumen ts given ab o ve regarding B ’s sp ectral prop erties generalize straightforw ardly to other graph ensembles. First, consider blo ck models with q groups, where for 1 ≤ a ≤ q group a has fractional size n a . The av erage degree of group a is c a = P b c ab n b . The hardest case is where c a = c is the same for all a , so that we cannot simply lab el v ertices according to their degree. The leading eigenv ector again has eigenv alue c , and the bulk of B ’s sp ectrum is again confined to the disk of radius √ c . No w B has q − 1 linearly independent eigen vectors with real eigenv alues, and the corresp onding eigenv ectors are correlated with the true group assignmen t. If these real eigen v alues lie outside the bulk, w e can identify the groups b y assigning a vector in R q − 1 to eac h vertex, and applying a clustering technique such as k -means. These eigenv alues are of the form µ = cν where ν is a nonzero eigenv alue of the q × q matrix T ab = n a c ab c − 1 . (11) In particular, if n a = 1 /q for all a , and c ab = c in for a = b and c out for a 6 = b , we hav e µ c = ( c in − c out ) /q . The detectabilit y threshold is again µ c > √ c , or | c in − c out | > q √ c . (12) More generally , if the comm unity-correlated eigen vectors ha ve distinct eigenv alues, w e can hav e multiple transitions where some of them can b e detected b y a sp ectral algorithm while others cannot. There is an imp ortan t difference b etw een the general case and q = 2 . While for q = 2 it is literally impossible for an y algorithm to distinguish the comm unities b elow this transition, for larger q the situation is more complicated. In general (for q ≥ 5 in the assortative case, and q ≥ 3 in the disassortativ e one) the threshold (12) marks a transition from an “easily detectable” regime to a “hard detectable” one. In the hard detectable regime, it is theoretically p ossible to find the communities, but it is conjectured that any algorithm that do es so tak es exp onential time [9, 10]. In particular, we hav e found exp erimen tally that none of B ’s eigenv ectors are correlated with the groups in the hard regime. Nonetheless, our arguments suggest that sp ectral algorithms based on B are optimal in the sense that they succeed all the wa y down to this easy/hard transition. Since a ma jor dra wback of the stochastic blo ck mo del is that its degree distribution is P oisson, w e can also consider random graphs with sp ecified degree distributions. Again, the hardest case is where the groups ha ve the same degree distribution. Let a k denote the fraction of vertices of degree k . The av erage branching ratio of a branc hing process that explores the neighborho od of a v ertex, i.e., the av erage num b er of new edges leaving a v ertex v that we arrive at when follo wing a random edge, is ˜ c = P k k ( k − 1) a k P k k a k = h k 2 i / h k i − 1 . 7 W e assume here that the degree distribution has b ounded second moment so that this pro cess is not dominated b y a few high-degree vertices. T he leading eigenv alue of B is ˜ c , and the bulk of its sp ectrum is confined to the disk of radius √ ˜ c , ev en in the sparse case where ˜ c do es not gro w with the size of the graph. If q = 2 and the av erage num bers of new edges linking v to its o wn group and the other group are ˜ c in / 2 and ˜ c out / 2 resp ectiv ely , then the approximate eigen vector described in the previous section has eigenv alue µ = (˜ c in − ˜ c out ) / 2 . The detectability threshold (1) then b ecomes µ > √ ˜ c , or ˜ c in − ˜ c out > 2 √ ˜ c . The threshold (12) for q groups generalizes similarly . V. DERIVING B BY LINEARIZING BELIEF PR OP AGA TION The matrix B also app ears naturally as a linearization of the up date equations for b elief propagation (BP). This linearization w as used previously to inv estigate phase transitions in the p erformance of the BP algorithm [5, 9, 10, 28]. W e recall that BP is an algorithm that iteratively up dates messages η v → w where ( v , w ) are directed edges. These messages represen t the marginal probability that a vertex v b elongs to a given comm unity , assuming that the v ertex w is absent from the net w ork. Eac h such message is up dated according to the messages η u → v that v receives from its other neighbors u 6 = w . The up date rule dep ends on the parameters c in and c out of the blo ck mo del, as w ell as the exp ected size of eac h communit y . F or the simplest case of t wo equally sized groups, the BP up date [9, 10] can b e written as η + v → w η − v → w := e − h Q u ∈ N ( v ) − w η + u → w c in + η − u → w c out Q u ∈ N ( v ) − w η + u → w c out + η − u → w c in . (13) Here + and − denote the tw o comm unities. The term e h , where h = ( c in − c out )( n BP + − n BP − ) and n B P ± is the current estimate of the fraction of v ertices in the tw o groups, represen ts messages from the non-neighbors of v . In the assortativ e case, it preven ts BP from conv erging to a fixed p oint where ev ery v ertex is in the same comm unity . The up date (13) has a trivial fixed p oin t η v → w = 1 / 2 , where every vertex is equally likely to b e in either communit y . W riting η ± u → v = 1 / 2 ± δ u → v and linearizing around this fixed p oint gives the follo wing up date rule for δ , δ v → w := c in − c out c in + c out X u ∈ N ( v ) − w δ u → v , or equiv alently δ := c in − c out c in + c out B δ . (14) More generally , in a blo c k model with q communities, an affinity matrix c ab , and an expected fraction n a of vertices in each communit y a , linearizing around the trivial point and defining η a u → v = n a + δ a u → v giv es a tensor pro duct op erator δ := ( T ⊗ B ) δ , (15) where T is the q × q matrix defined in (11). W e can also describ e the linearization of BP in terms of the 2 n × 2 n matrix B 0 defined in (9). Specifically , if we define δ in and δ out as the q n -dimensional v ectors where δ in v = P u ∈ N ( v ) δ a u → v and δ out v = P u ∈ N ( v ) δ a v → u are the sum of δ ov er v ’s incoming and outgoing edges resp ectively , then δ out δ in = ( T ⊗ B 0 ) δ out δ in . (16) Th us w e can analyze BP to first order around the trivial fixed p oint by keeping track of just 2 q n v ariables rather than 2 q m of them. This shows that the sp ectral prop erties of the non-backtrac king matrix are closely related to belief propagation. Sp ecifically , the trivial fixed p oint is unstable, leading to a fixed p oin t that is correlated with the communit y structure, exactly when T ⊗ B has an eigen v alue greater than 1 . How ever, by a voiding the fixed point where all the vertices b elong to the same group, we suppress B ’s leading eigenv alue; th us the criterion for instabilit y is ν µ 2 > 1 where ν is T ’s leading eigen v alue and µ 2 is B ’s second eigen v alue. This is equiv alen t to (12) in the case where the groups are of equal size. In general, the BP algorithm pro vides a sligh tly b etter agreemen t with the actual group assignmen t, since it appro ximates the Ba yes-optimal inference of the blo ck model. On the other hand, the BP up date rule dep ends on the parameters of the blo c k mo del, and if these parameters are unknown they need to b e learned, which presents additional difficulties [12]. In contrast, our sp ectral algorithm do es not dep end on the parameters of the blo ck mo del, giving an adv an tage o ver BP in addition to its computational efficiency . 8 VI. EXPERIMENT AL RESUL TS AND DISCUSSION 2.5 3 3.5 4 4.5 5 5.5 6 0 0.2 0.4 0.6 0.8 1 c in −c out Overlap Non−backtracking Modularity Random Walk Adjacency Laplacian BP 2 4 6 8 10 12 0 0.2 0.4 0.6 0.8 1 Average Degree Overlap Non−backtracking Modularity Random Walk Adjacency Laplacian BP FIG. 4: The accuracy of sp ectral algorithms based on different linear op erators, and of b elief propagation, for tw o groups of equal size. On the left, we v ary c in − c out while fixing the a verage degree c = 3 ; the detectabilit y transition given by (1) o ccurs at c in − c out = 2 √ 3 ≈ 3 . 46 . On the right, we set c out /c in = 0 . 3 and v ary c ; the detectability transition is at c ≈ 3 . 45 . Each p oin t is av eraged o ver 20 instances with n = 10 5 . Our sp ectral algorithm based on the non-bac ktracking matrix B achiev es an accuracy close to that of BP , and b oth remain large all the wa y down to the transition. Standard spectral algorithms based on the adjacency matrix, mo dularit y matrix, the Laplacian, and the random walk matrix fail w ell ab ov e the transition, doing no b etter than chance. −0.03 0 0.03 −0.03 0 0.03 −0.1 0 0.1 0 0.1 0.2 0.1 0.1 FIG. 5: Clustering in the case of three groups of equal size. On the left, a scatter plot of the second and third eigen vectors (X and Y axis resp ectively) of the non-backtrac king matrix B , with colors indicating the true group assignmen t. On the right, the analogous plot for the adjacency matrix A . Here n = 3 × 10 4 , c = 3 , and c out /c in = 0 . 1 . Applying k -means giv es an o verlap 0 . 712 using B , but 0 . 0063 using A . In Fig. 4, we compare the spectral algorithm based on the non-bac ktrac king matrix B with those based on v arious classical op erators: the adjacency matrix A , the mo dularity matrix M , the Laplacian L , and the random w alk matrix Q . W e see that there is a regime where standard sp ectral algorithms do no b etter than chance, while the one based on B achiev es a strong correlation with the true group assignment all the wa y do wn to the detectability threshold. W e also show the performance of b elief propagation, which is b eliev ed to b e asymptotically optimal [9, 10]. W e measure the performance as the overlap , defined as 1 n X u δ g u , ˜ g u − 1 q ! 1 − 1 q . (17) Here g u is the true group lab el of v ertex u , and ˜ g u is the lab el found b y the algorithm. W e break symmetry b y maximizing ov er all q ! permutations of the groups. The o v erlap is normalized so that it is 1 for the true lab eling, and 0 for a uniformly random lab eling. 9 -4 -3 -2 -1 1 2 3 4 -4 -2 2 4 6 8 10 12 Football q=12 Overlap: 0.9163 -30 -20 -10 10 20 30 -40 -20 20 40 60 80 Polblogs q=2 Overlap: 0.8533 -4 -2 2 4 -5 5 10 Adjnoun q=2 Overlap: 0.6250 -3 -2 -1 1 2 3 -4 -2 2 4 6 8 Dolphins q=2 Overlap: 0.7419 -4 -3 - 2 -1 1 2 3 4 -4 -2 2 4 6 8 10 12 Polbooks q=3 Overlap: 0.7571 -4 -3 -2 -1 1 2 3 4 -4 -2 2 4 6 8 10 12 Karate q=2 Overlap: 1 FIG. 6: Spectrum of the non-bac ktracking matrix in the complex plane for some commonly used b enc hmarks for communit y detection in real net works taken from [29–34]. The radius of the circle is the square ro ot of the largest eigenv alue, which is a heuristic estimate of the bulk of the sp ectrum. The ov erlap is computed using the signs of the second eigenv ector for the net works with tw o communities, and using k-means for those with three and more communities. The non-backtrac king op erator detects comm unities in all these netw orks, with an ov erlap comparable to the p erformance of other sp ectral metho ds. As in the case of syn thetic netw orks generated by the sto c hastic blo ck mo del, the num ber of real eigen v alues outside the bulk app ears to b e a go o d indicator of the num ber q of communities. In Fig. 5 w e illustrate clustering in the case q = 3 . As describ ed ab ov e, in the detectable regime we exp ect to see q − 1 eigen v ectors with real eigenv alues that are correlated with the true group assignment. Indeed B ’s second and third eigenv ector are strongly correlated with the true clustering, and applying k -means in R 2 giv es a large ov erlap. In con trast, the second and third eigenv ectors of the adjacency matrix are essen tially uncorrelated with the true clustering, and similarly for the other traditional op erators. Finally we turn to w ards real netw orks to illustrate the adv antages of sp ectral clustering based on the non- bac ktracking matrix in practical applications. In Fig. 6 w e sho w B ’s sp ectrum for several netw orks commonly used as b enchmarks for comm unity detection. In each case we plot a circle whose radius is the square ro ot of the largest eigen v alue. Even though these netw orks w ere not generated by the sto chastic block model, these sp ectra look quali- tativ ely similar to the picture discussed abov e (Fig. 2). This leads to sev eral very conv enien t prop erties. F or eac h of these net works we observed that only the eigenv ectors with real eigenv alues are correlated to the group assignment giv en b y the ground truth. Moreov er, the real eigen v alues that lie outside of the circle are clearly identifiable. This is v ery unlike the situation for the operators used in standard spectral clustering algorithms, where one must decide whic h eigen v alues are in the bulk and which are outside. In particular, the num b er of real eigenv alues outside of circle seems to b e a natural indicator for the true n umber q of clusters presen t in the netw ork, just as for net works generated b y the stochastic blo c k mo del. This suggests that in the netw ork of p olitical b o oks there might in fact b e 4 groups rather than 3, in the blog netw ork there might b e more than tw o groups, and in the NCAA fo otball netw ork there might b e 10 groups rather than 12. Ho wev er, we also note that large real eigen v alues ma y corresp ond in some ne t w orks to small cliques in the graph; it is a philosophical question whether or not to count these as comm unities. Note also that clustering based on the non-backtrac king matrix works not only for assortative netw orks, but also for disassortativ e ones, suc h as word adjacency netw orks [31], where the imp ortan t real eigenv alue is negativ e—without b eing told which is the case. A Matlab implementation with demos that can b e used to repro duce our numerical results can be found at [35]. VI I. CONCLUSION While recent adv ances hav e made statistical inference of netw ork mo dels for communit y detection far more scalable than in the past (e.g. [9, 36 – 38]) sp ectral algorithms are highly comp etitiv e b ecause of the computational efficiency of sparse linear algebra. Ho wev er, for sparse net works there is a large regime in which statistical inference metho ds suc h as belief propagation can detect communities, while standard spectral algorithms cannot. 10 W e closed this gap b y using the non-backtrac king matrix B as a new starting p oin t for spectral algorithms. W e sho wed that for sparse netw orks generated by the sto chastic blo ck mo del, B ’s spectral prop erties are m uch b etter than those of the adjacency matrix and its relatives. In fact, it is asymptotically optimal in the sense that it allo ws us to detect communities all the w a y do wn to the detectability transition. W e also computed B ’s sp ectrum for some common b enc hmarks for comm unity detection in real-world netw orks, showing that the real eigenv alues are a go o d guide to the num ber of comm unities and the correct lab eling of the v ertices. Our approac h can b e straigh tforwardly generalized to sp ectral clustering for other t yp es of sparse data, suc h as real-v alued similarities b et w een ob jects. The definition of B extends to B ( u → v ) , ( w → x ) = ( s ( u, v ) if v = w and u 6 = x 0 otherwise , where s ( u, v ) is the similarity index b et ween u and v . As in the case of graphs, w e cluster the vertices by computing the top eigenv ectors of B , pro jecting the rows of B to the space spanned b y these eigenv ectors, and using a low- dimensional clustering algorithm such as k -means to cluster the pro jected rows [3]. Ho w ever, w e b eliev e that, as for sparse graphs, there will b e imp ortan t regimes in which using B will succeed where standard clustering algorithms fail. Given the wide use of sp ectral clustering throughout the sciences, we exp ect that the non-bac ktracking matrix and its generalizations will ha ve a significan t impact on data analysis. A ckno wledgments W e are grateful to Noga Alon, Brian Karrer, Mark Newman, Nati Linial, and Xiaoran Y an for helpful discussions. C.M. and P .Z. are supported b y AF OSR and D ARP A under gran t F A9550-12-1-0432. F.K. and P .Z. ha v e b een supp orted in part b y the ERC under the Europ ean Union’s 7th F ramew ork Programme Grant Agreement 307087- SP ARCS. E.M and J.N. w ere supported by NSF DMS gran t n um b er1106999 and DOD ONR gran t N000141110140. [1] Holland P W, Lask ey K B, Leinhardt S (1983). Sto c hastic blo c kmo dels: First steps. So cial Networks 5:109–137. [2] W ang Y J, W ong G Y (1987). Sto c hastic Blo ckmodels for Directed Graphs. Journal of the Americ an Statistic al Asso ciation 82(397):8–19. [3] V on Luxburg, U. (2007). A tutorial on spectral clustering. Statistics and computing, 17(4), 395-416. [4] Bick el P J, Chen A (2009). A nonparametric view of netw ork mo dels and Newman-Girv an and other mo dularities. PNAS 106:21068–21073. [5] Co ja-Oghlan A, Mossel E and Vilenchik D (2009). A Sp ectral Approach to Analyzing Belief Propagation for 3-Coloring. Combinatorics, Prob ability and Computing 18: 881–912. [6] Co ja-Oghlan A (2010). Graph partitioning via adaptive spectral techniques. Combinatorics, Pr obability and Computing , 19(02):227–284. [7] McSh erry F (2001). Sp ectral partitioning of random graphs. F oundations of Computer Science, 2001. Pro ceedings. 42nd IEEE Symp osium on, 529–537. [8] Nadakuditi R R and Newman M E J (2012). Graph sp ectra and the detectability of communit y structure in netw orks. Phys. Rev. L ett. 108:188701. [9] Decelle A, Krzak ala F, Mo ore C, and Zdeb oro v a L (2011). Phase transition in the detection of mo dules in sparse netw orks. Physic al R eview L etters 107 065701. [10] Decelle A, Krzak ala F, Mo ore C, and Zdeborov a L (2011). Asymptotic analysis of the sto chastic blo c k mo del for mo dular net works and its algorithmic applications. Physical R eview E 84 066106. [11] Mossel E, Neeman J, Sly A (2012). Stochastic Block Models and Reconstruction. Preprint, [12] Zh ang P , Krzak ala F, Reichardt J, and Zdeb oro v á L (2012). Comparative study for inference of hidden classes in sto c hastic blo c k mo dels. Journal of S tatistical Mechanics: Theory and Experiment, 2012(12), P12021. [13] McKay , B D (1981). The exp ected eigenv alue distribution of a large regular graph. Linear Algebra and its Applications 40, 203-216. [14] Sasha S (2007). Random matrices, nonbac ktrac king walks, and orthogonal polynomials. Journal of Mathematical Physics, 48. [15] F riedman J (2008). A proof of Alon’s second eigen v alue conjecture and related problems. Memoirs of the American Math- ematical So ciet y , no. 910. [16] Hashimoto, Ki-ichiro (1989). Zeta functions of finite graphs and representations of p-adic groups. Automorphic forms and geometry of arithmetic v arieties, 211-280. [17] Alon N, Benjamini I, Lub etzky E and Sasha S (2007). Non-bac ktracking random walks mix faster. Communications in Con temp orary Mathematics 9(4), 585–603. 11 [18] W atanab e, Y., F ukumizu, K. (2010). Graph zeta function in the Bethe free energy and loopy b elief propagation. arXiv preprin t [19] V ontobel, P . O. (2010). Connecting the Bethe en tropy and the edge zeta function of a cycle co de. In IEEE International Symp osium on Information Theory Proceedings (ISIT), pp. 704-708. [20] Ren, P ., Wilson, R. C., Hanco ck, E. R. (2011). Graph characterization via Ihara co efficients. IEEE T ransactions on Neural Net works, 22(2), 233-245. [21] Wigner E P (1958). On the distribution of the roots of certain symmetric matrices. Ann. Math, 67(2), 325-327. [22] Krivelevic h M and Sudako v B (2003). The largest eigenv alue of sparse random graphs. Combinatorics, Probability and Computing 12(01), 61-72. [23] Bollobas B, Sv ante J and Oliver R (2007). The phase transition in inhomogeneous random graphs. Rand om Structures & Algorithms 31.1: 3–122. [24] Kesten H and Stigum B P (1966). Additional limit theorems for indecomp osable multidimensional Galton-Watson pro- cesses. Ann. Math. Statist. 37:1463–1481. [25] Mossel E and P eres Y (2003). Information flow on trees. The Annals of Applied Pr ob ability 13:817–844. [26] Bass, H (1992). The Ihara-Selberg zeta function of a tree lattice. International Journal of Mathematics, 3(06), 717-797. [27] Angel O, F riedman J and and Hoory S (2007). The non-bac ktracking spectrum of the universal cov er of a graph. arXiv preprin t [28] Richardson T and Urbanke R (2008). Mo dern co ding theory . Cambridge Univ ersity Press. [29] Adamic L, Glance N (2005). The p olitical blogosphere and the 2004 US Election: Divided They Blog. In Pr o c 3r d Intl W orkshop on Link Disc overy . [30] Zachary W W (1977). An information flow mo del for conflict and fission in small groups. Journal of Anthr op olo gic al R ese ar ch 33:4520-473. [31] Newman M E (2006). Finding communit y structure in netw orks using the eigen vectors of matrices. Ph ysical review E, 74(3), 036104. [32] Girv an M, and Newman M E (2002). Comm unity structure in so cial and biological netw orks. Pro ceedings of the National A cademy of Sciences, 99(12), 7821-7826. [33] Lusseau D, Schneider K, Boisseau O J, Haase, P , Slo oten, E, and Dawson S M. (2003). The bottlenose dolphin communit y of Doubtful Sound features a large proportion of long-lasting asso ciations. Behavioral Ecology and So ciobiology , 54(4), 396-405. [34] The net work was compiled by V aldis Krebs and can be found on http://www.orgnet.com/. [35] A matlab demo file can be found on http://panzhang.net/dea/dea.tar.gz . [36] Ball, B, Karrer, B, and Newman, M E J (2011). Efficient and principled metho d for detecting communities in netw orks. Ph ysical Review E, 84(3), 036103. [37] Chen, A, Amini A A, Bick el P J and Levina E (2012). Fitting communit y mo dels to large sparse netw orks. arXiv preprin t [38] Gopalan P , Mimno D, Gerrish S, F reedman M and Blei D (2012). Scalable inference of o v erlapping comm unities. In A dv ances in Neural Information Processing Systems 25 (pp. 2258-2266).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment