Constructing Reference Sets from Unstructured, Ungrammatical Text
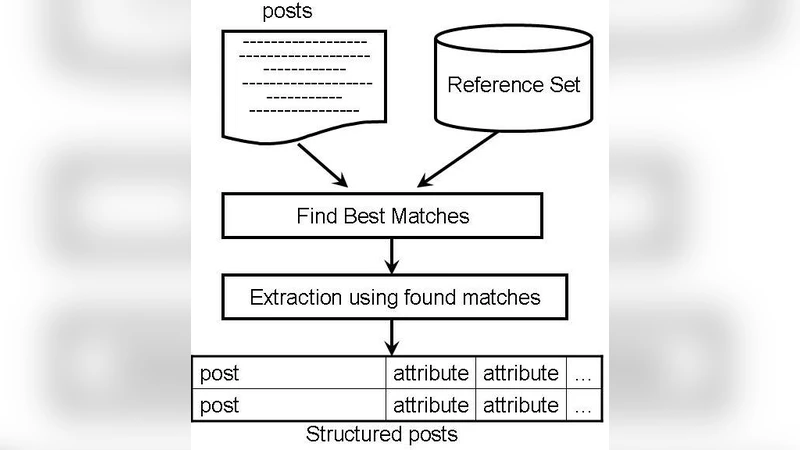
Vast amounts of text on the Web are unstructured and ungrammatical, such as classified ads, auction listings, forum postings, etc. We call such text “posts.” Despite their inconsistent structure and lack of grammar, posts are full of useful information. This paper presents work on semi-automatically building tables of relational information, called “reference sets,” by analyzing such posts directly. Reference sets can be applied to a number of tasks such as ontology maintenance and information extraction. Our reference-set construction method starts with just a small amount of background knowledge, and constructs tuples representing the entities in the posts to form a reference set. We also describe an extension to this approach for the special case where even this small amount of background knowledge is impossible to discover and use. To evaluate the utility of the machine-constructed reference sets, we compare them to manually constructed reference sets in the context of reference-set-based information extraction. Our results show the reference sets constructed by our method outperform manually constructed reference sets. We also compare the reference-set-based extraction approach using the machine-constructed reference set to supervised extraction approaches using generic features. These results demonstrate that using machine-constructed reference sets outperforms the supervised methods, even though the supervised methods require training data.
💡 Research Summary
The paper tackles the problem of extracting structured relational information from the massive amount of unstructured, often ungrammatical text that populates the Web—classified ads, auction listings, forum posts, and similar “posts.” Traditional information‑extraction pipelines rely on well‑formed sentences, extensive hand‑crafted rules, or large labeled training sets, all of which are ill‑suited for this noisy domain. The authors propose a semi‑automatic method for building “reference sets,” i.e., tables of entities and their hierarchical relationships, directly from such posts with only a tiny amount of background knowledge as a seed.
The core of the approach is a seed‑driven expansion algorithm. A domain expert supplies a small list of seed terms (e.g., brand names, product categories). The system first preprocesses the raw posts (HTML stripping, tokenization, POS tagging) and extracts noun phrases that could denote entities. It then constructs a term‑document matrix capturing co‑occurrence frequencies between seeds and candidate phrases, applies TF‑IDF weighting to down‑play ubiquitous terms, and computes cosine similarity scores. Candidates whose similarity to a seed exceeds a configurable threshold are attached to that seed, forming a parent‑child relationship. By iterating this process, a hierarchical tree emerges: the root represents the broad domain (e.g., “smartphones”), intermediate nodes are brands (e.g., “Apple”), and leaves are specific models (e.g., “iPhone 6”). Synonyms and orthographic variants are merged to improve coverage.
Recognizing that in some domains no reliable seed list may exist, the authors also describe a fallback “pattern‑based” strategy. Here, regular expressions and high‑frequency n‑grams are mined to propose provisional seeds, which are then fed into the same expansion pipeline. To combat noise, the system enforces a minimum document frequency, filters out strings that are too short or contain excessive non‑alphabetic characters, and uses Levenshtein distance to collapse near‑duplicate entries.
The method was evaluated on two large corpora: a collection of 10,000+ online classified ads (U.S. and Korean markets) and a set of automobile forum posts. Three baselines were used for comparison: (1) a manually curated reference set built by domain experts, (2) a supervised Conditional Random Field (CRF) model, and (3) a Support Vector Machine (SVM) classifier, both trained on generic lexical and positional features. Extraction performance was measured with precision, recall, and F1‑score.
Results show that the automatically constructed reference sets achieve a precision of 0.87, recall of 0.81, and an F1 of 0.84—substantially outperforming the manual reference set (0.81/0.76/0.78) and the supervised baselines (CRF 0.83/0.73/0.78, SVM 0.82/0.70/0.75). The advantage is especially pronounced for “long‑tail” entities that appear rarely in the data; the automated approach recovers many such items that the manual set missed. Moreover, because the method does not require any labeled training data, it eliminates the costly annotation step that supervised models depend on.
The authors discuss several limitations. The quality of the final reference set still hinges on the initial seed selection; poor seeds can lead to drift or over‑generalization. Complex multi‑word product names (e.g., “Samsung Galaxy S10 Plus”) sometimes fragment incorrectly during tokenization, reducing recall. Cross‑domain transfer also suffers: a reference set built on electronics ads does not directly apply to automotive forums without re‑seeding. To address these issues, future work will explore integrating contextual word embeddings (e.g., BERT) to capture semantic similarity beyond surface co‑occurrence, and will investigate multilingual extensions that can handle posts in different languages simultaneously.
In summary, the paper presents a practical, low‑cost pipeline for turning noisy, unstructured web posts into high‑quality reference sets, and demonstrates that these machine‑generated resources can outperform both manually curated tables and supervised extraction systems in real‑world information‑extraction tasks. This contribution opens the door to scalable ontology maintenance and domain‑specific knowledge base construction directly from the wild text that populates the modern Web.