Consistent Bounded-Asynchronous Parameter Servers for Distributed ML
In distributed ML applications, shared parameters are usually replicated among computing nodes to minimize network overhead. Therefore, proper consistency model must be carefully chosen to ensure algorithm's correctness and provide high throughput. E…
Authors: Jinliang Wei, Wei Dai, Abhimanu Kumar
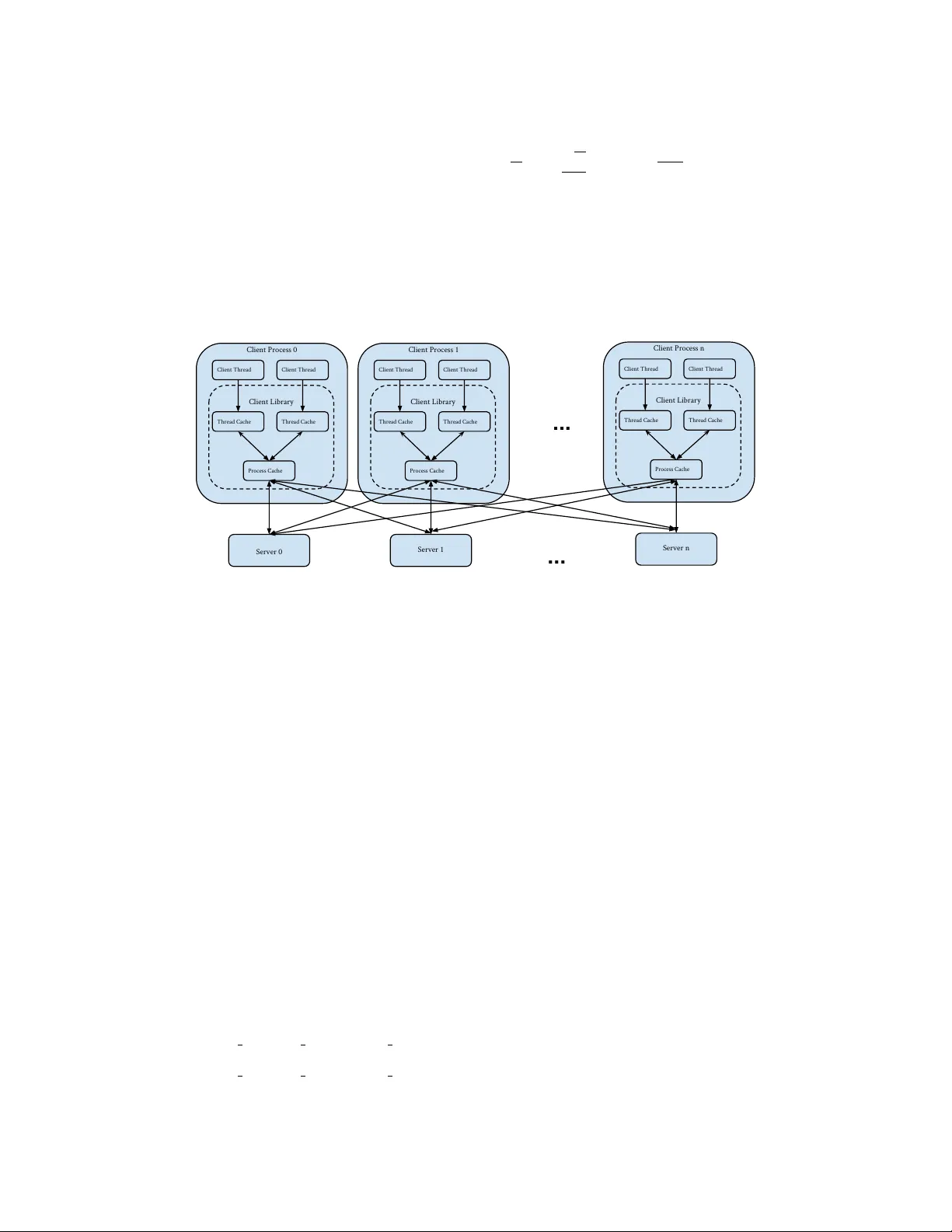
Consisten t Bounded-Async hronous P arameter Serv ers for Distributed ML Jinliang W ei, W ei Dai, Abhiman u Kumar, Xun Zheng, Qirong Ho and Eric P . Xing Sc ho ol of Computer Science Carnegie Mellon Univ ersity Pittsburgh, P A 15213 jinlianw@cs,wdai@cs,abhimank@andrew, xunzheng@cs,qho@cs,epxing@cs.cmu.edu Jan uary 3, 2014 Abstract In distributed ML applications, shared parameters are usually replicated among computing no des to minimize netw ork ov erhead. Therefore, prop er consistency model must b e carefully c hosen to ensure algorithm’s correctness and pro vide high throughput. Existing consistency mo dels used in general- purp ose databases and mo dern distributed ML systems are either to o lo ose to gua rantee correctness of the ML algorithms or too strict and thus fail to fully exploit the computing p ow er of the underlying distributed system. Man y ML algorithms fall in to the category of iterative c onver gent algorithms which start from a ran- domly chosen initial point and con verge to optima b y rep eating iteratively a set of procedures. W e’ve found that man y such algorithms are to a b ounded amoun t of inconsistency and still conv erge correctly . This property allows distributed ML to relax strict consistency mo dels to improv e system performance while theoretically guarantees algorithmic correctness. In this pap er, we present several relaxed consis- tency mo dels for async hronous parallel computation and theoretically prov e their algorithmic correctness. The prop osed consistency mo dels are implemen ted in a distributed parameter serv er and ev aluated in the context of a p opular ML application: topic mo deling. 1 In tro duction In response to the rapidly increasing in terests in big data analytics, v arious system framew orks ha ve b een prop osed to scale out ML algorithms to distributed systems, such as Pregel [8], Piccolo [9], GraphLab [7] and Y ahooLDA [1]. Amongst them, parameter server [10, 5, 3, 9, 10] is a widely used system architecture and programming abstraction that may supp ort a broad range of ML algorithms. P arameter serv er can b e conceptualized as a (usually distributed) key-v alue store that stores mo del parameters and supp orts concurren t read and write accesses from distributed clients [5]. In order to minimize the netw ork ov erhead of remote accesses, shared parameters are (partially) replicated on client no des and accesses are serviced from lo cal replicas. Th us proper lev el of consistency guarantees m ust b e ensured. A desirable consistency mo del for parameter serv er m ust meet tw o requirements: 1) Correctness of the distributed algorithm can b e theoretically prov en; 2) Computing pow er of the system is fully utlized. The consistency mo del effectively decouples the system implementations from ML algorithms and can b e used to reason ab out the quality of the solution (such as the rate of v ariance reduction). Main taining consistency among replicas is a classic problem in database research. V arious consistency mo dels hav e been used to provide different levels of guarantees for differen t applications [11]. Ho wev er, directly applying them usually fails to meet the requiremen ts of a parameter serv er. It is difficult or imp ossible to pro ve algorithm correctness based on a naive even tual consistency model as it fails to b ound the delay of seeing other clients’ up dates while one client k eeps making progress and that may lead to divergence. 1 Stronger consistency mo dels such as sequen tial consistency and linearizability require serializable up dates and that significantly restricts parallelism of the application. Consistency models employ ed in mo dern distributed ML system tend to fall into tw o extremes: either sequen tial consitency or no consistency guaran tee at all. F or example, Distributed GraphLab serializes read and write accesses to vertices and edges b y scheduling vertex programs according to a carefully colored graph or by lo cking [7]. Altougth such a model guarantees the correctness of the algorithm, it may under- utilize the distributed system’s computing p o wer. At the other extreme, Y ahooLDA [1] emplo ys a b est-effort consistency mo del where the system makes b est effort to delivery up dates but do es not make any guaran tee. Although the system empirically achiev es go od p erformance for LD A, there is no theoretical guarantee that the distributed implementation of the algorithm is correct. It is also unclear whether such system with lo ose consistency can generalize to a broad range of ML algorithms. In fact, the system can p oten tially fail if stragglers present or the netw ork bandwith is saturated. Recen tly , [5] presented the Stale Synchrnous Parallel (SSP) mo del, which is a v arian t of b ounded stal- eness consistency mo del – a form of ev en tual consistency . Simimlar to Bulk Sync hrnous Parallel (BSP), an execution of SSP consists of multiple iterations and eac h iteration is comp osed of a computation phase and a sync hronization phase. Up dates are sen t out only during the sync hronization phase. How ev er, in SSP , a client is allow ed to go b ey ond other clients b y at most s iterations, where s is a threshold set by the application. In SSP , accesses to shared parameters are usually serviced by lo cal replicas and net work accesses only o ccur in case the lo cal replica is more than s iterations stale. SSP delivers high throughput as it reduces net work communication cost. [5] sho ws SSP is theoretically sound b y proving the con vergence of sto c hastic gradient descent. Async hronous parallel mo del impro v es system p erformance ov er BSP b ecause 1) it uses CPU and net work bandwidth in parallel (e.g. sending out up dates whenev er net work bandwidth is a v ailable); 2) it do es not enforce a synchronization barrier. Also, since the system makes b est effort to send out up dates (instead of w aiting for synchoronization barrer), clients are more likely to compute with fresh data. Th us it may bring algorithmic benefits. It is more difficult to maintain consistency in an asynchronous system as comm uncation ma y happ en anytime. W e ha v e found that man y ML algorithms are sufficien tly robust to a b ounded amoun t of inconsistency and th us admits consistency mo dels weak er than serializability . By relaxing the consistency guarantees prop erly , the system may gain significan t throughput improv ements. In this pap er, we present a few high-throughput consistency mo dels that takes adv antange of the robustness of ML algorithms. As shown in [5], even though relaxed consistency improv es system throughput, it may result in reduced algorithmic progress p er-iteration (e.g., smaller cov ergence rate). All our proposed consistency mo dels allows application dev elop ers to tune the strictness of the consistency mo del to achiev e the sweet sp ot. W e present the following consistency mo dels: Clo c k-b ounded Async hronous P arallel (CAP) : W e apply the concept of “clo c k-b ounded” consis- tency of SSP to asynchronous parameter server. Unlik e SSP where up dates are sent out only during the sync hrnonization phase, CAP propgates up dates whenever the netowrk bandwidth is av ailable. Similar to SSP , CAP guarantees b ounded staleness - a client must see all up dates older than certain timestamp. V alue-b ounded Async hronous P arallel (V AP) This consistency mo del guarantees a b ound on the absolute deviation b et ween an y t wo parameter replicas. Clo c k-V alue-b ounded Asnyc hronous P arallel (CV AP) This model combines CAP and V AP to pro vide stronger consistency guarantee. With suc h a guarantee, the solution’s quality (e.g. asymptotic v ariance) can b e assessed. 2 Consistency Mo dels In this section, we presen t the formal definitions of CAP , V AP and CV AP . Consisder a collection of P w orkers which share access to a set of parameters. A work er writes to a parameter θ by applying an up date in the form of an asso ciate and commutativ e operation θ ← θ + δ . The async hronous parameter server prop ogates out the up date at some p oin t of time and the work er usually pro ceeds without w aiting but may blo c k o ccasionally to main tain consistency . Th us the parameter server ma y accum ulate a set of updates generated by a work er which are not yet synchronized acro os all work ers. All our consistency mo dels ensure read-m y-writes consistency . That is, a work er sees all its previous writes whether or not the up dates are 2 (3, 2) (4, 4) (5, 3) ... (6, 2) Worker 1 An update that is visible to all workers . An unsynchronized local update: not yet visible to all workers The current update that blocks the worker. The current update that allows the worker to proceed (3, 2) (4, 4) (5, 3) ... (6, 2) Worker 1 after update 4 is acknowledged Figure 1: An illustration of V AP . The arrow represents a series of up dates that a work er applies to a parameter. An up date is representd by a pair of num b ers ( i, j ) where i is the up date’s sequence num b er and j is the v alue of the up date. In this example, the v alue bound is set to 8. Applying the 6th up date blo c ks the work er as it would bring the accumulated unsync hronized up dates beyond 8. After the 4th up date becomes visible to all work ers, the work er ma y pro cee with up date (6 , 2). sync hronized with other work ers. Intuitiv ely , read-m y-write consistency is desirable as it allows a work er to pro ceed with more fresh parameter. Our consistency mo dels also ensure FIFO consistency [6] - up dates from a single work er are seen by all other work ers in the order in which they are issued. In tuitively , this consistency guarantee ensures that the up dates are handled as fairly as the netw ork ordering and preven ts a work er from b eing biased by a particular subset of up dates from another work er. 2.1 Clo c k-b ounded Asynchronous Parallel (CAP) Informally , Clo c k-b ounded Asynchronous Parallel (CAP) ensures all work ers are making sufficient progress forw ard, otherwise, faster work ers are blo c ked to wait for the slow ones. Progress of a work er is represented b y “clock”, whic h is an in teger which starts from 0 and is incremented at regular in terv als. Up dates generated b et w een clo c k [ c − 1 , c ] are timestamp ed with c . The consistency mo del guarantees that a work er with clo c k c sees all other clients’ up dates in the range of [0 , c − s − 1], where s is a user-defined threshold. W e omit the pro of of correctness for CAP as the analysis in [5] applies to CAP as well. 2.2 V alue-bounded Async hronous P arallel (V AP) Since the asynchronous parameter serv er does not blo c k work ers when propagating out up dates, a work er may accum ulate a set of up dates that are only visiable to itself. W e refer this set of updates as unsynchr onize d lo c al up dates . As the up date op eration is associative and comm utative, up dates ma y b e aggregated b y summing them up. The V alue-b ounded Asynchronous Parallel (V AP) mo del guarantees that for any work er the accumulated sum s of unsynchr onize d lo c al up dates of any parameter is less than v thr where v thr is a user-defined threshold. When a w ork er attempts to apply an update that mak es the accum ulated sum exceed the threshold v thr , the work er is blo ck ed until the system has made a sufficient num b er of its up dates visible to all work ers. The V AP mo del is illustrated b y Figure 1. W e should note that the V AP mo del describ ed ab o ve still allows t wo w orkers to see tw o very different set of up dates. F or an y pair of work ers, say A and B, ev en though V AP restricts ho w they see up dates generated within this pair, it makes no guarantees ab out seeing up dates that are generated by other p eer work ers. F or example, it can happ en that work er A has seen one up date from each other work er, but B hasn’t seen any of them. Th us, V AP only pro vides a v ery loose b ound on how tw o w orkers may read different v alues: for an y tw o work ers A and B, let θ A and θ B b e the sum ov er all up dates seen by A and B resp ectively . Then, the absolute difference b et ween θ A and θ B , | θ A − θ B | , is upp er b ounded by max ( u, v thr ) × P , where u is an upp er b ound on the magnitude of any up date, v thr is the aforemen tioned user-defined threshold, and P is the num W e ma y provide a stronger consistency guarantee by restricting how work ers see other work ers’ up dates. W e refer to an up date as a half-synchr onize d up date if the up date is seen by at least other one w orker (that did not generate the up date), but has not yet b een seen by all other work ers. In addition to the guarantees pro vided by w eak V AP , the strong V AP mo del guarantees that for any parameter, the total magnitude of all 3 half-synchr onize d up dates is b ounded by max ( u, v thr ), where u and v thr are as defined b efore. Th us, strong V AP guarantees that for any t wo w orkers A and B , | θ A − θ B | is upp er b ounded b y 2 ∗ max ( u, v thr ). Note that this is indep enden t of P , the num b er of w orkers. 2.3 Clo c k-V alue-bounded Async hronous P arallel (CV AP) CAP may be combined with V AP to provide stronger consistency guaran tees. The idea is that CV AP ensure all w orkers mak e enough progress but bounds the absolute difference b et ween replicas. CV AP pro vides the consistency guarantees of both CAP and V AP . As V AP has a strong and a weak version, there are t wo versions of CV AP correspondingly . As we shown in Section 3, CV AP allows application dev elop ers to guaran tee a certain level of solution quality . 3 Theoretical Analysis W e choose the Sto c hastic Gradient Descent algorithm as our example application and prov e its conv ergence under V AP . Our pro of utilizes the techniques dev elop ed in [5]. As in [5], the V AP mo del supp orts operations x ← x ⊕ ( z · y ), where x , y are members of a ring with an ab elian op erator ⊕ (such as addition), and a m ultiplication op erator · such that z · y = y 0 where y 0 is also in the ring. W e shall informally refer to x as the “system state”, u = z y as an “up date”, and to the op eration x ← x + u as “writing an up date” . As defined in section 2.2 the up dates u are accumulated and are propagated to server when they are greater than v thr . W e call these propagation times as t p . W e define u p,t p as the accumulated up date written b y w orker p at propagation time t p through the write op eration x ← x + u p,t p . The up dates u p,t p are a function of the system state x , and under the V AP model, differen t w orkers will “see” different, noisy versions of the true state x . ˜ x p,t p is the noisy state read b y work er p at time t p , implying that u p,t p = G ( ˜ x p,t p ) for some function G . F ormally , in V AP ˜ x p,t p can take: V alue Bounded Staleness: Fix a staleness s . Then, the noisy state ˜ x p,t p is equal to ˜ x p,t p = x 0 + P X p 0 =1 t p 0 − 1 X t =1 u p 0 ,t | {z } guaranteed pre-propagation up dates + u p,t p | {z } guaranteed read-my-writes up dates + X ( p 0 ,t p 0 ) ∈S p,t p u p 0 ,t p 0 | {z } best-effort in-propagation updates , (1) where S p,t p ⊆ W p,t = ([1 , P ] \ { p } ) × { t 1 , t 2 , ..., t P } is some subset of the up dates u written in b et ween propagations t p − 1 and t p “windo w” and do es not include up dates from w orker p . In other w ords, the noisy state ˜ x p,t p consists of three parts: 1. Guaranteed “pre-propagation” up dates from b egining to t p 0 − 1, for every work er p 0 . 2. Guaranteed “read-m y-writes” set u p,t p that cov ers all “in-windo w” up dates made by the querying w orker p . 3. Best-effort “in-window” up dates S p,t p (not counting up dates from work er p ). As with [5], V AP also generalizes the Bulk Sync hronous P arallel (BSP) mo del: BSP Lemma: Under zero staleness V AP reduces to BSP . Pro of: ˜ x p,t p exactly consists of all updates un til time t p . W e now define a reference sequence of states x t , informally referred to as the “true” sequence : x t = x 0 + t X t 0 =0 u t 0 , where u t := u t mo d P , b t/P c . In other words, we sum up dates by first lo oping ov er work ers ( t mo d P ), then ov er time-interv als b t/P c . No w, let us use V AP to b ound the difference b et ween the “true” sequence x t and the noisy views ˜ x p,t p : 4 Lemma 1: Assume s ≥ 1, and let ˜ x t := ˜ x t mo d P , b t/P c , so that ˜ x t = x t + ∆ t , (2) where ∆ t is the the difference (i.e. error) b et ween ˜ x t and x t . W e claim that k ∆ t k ≤ 2 v thr √ K ( P − 1), where k · k is the ` 2 norm, and K is the dimension of x . Proof : As argued earlier, strong V AP implies k ∆ t k ∞ ≤ 2 v thr ( P − 1). The result immediately follows since k y k ≤ √ K k y k ∞ for all y . Theorem 1 (SGD under V AP): Supp ose we wan t to find the minimizer x ∗ of a conv ex function f ( x ) = 1 T P T t =1 f t ( x ), via gradient descent on one comp onen t ∇ f t at a time. W e assume the comp onen ts f t are also con vex. Let the up dates u t := − η t ∇ f t ( ˜ x t ), with decreasing step size η t = σ √ t . Also let the V AP threshold v thr decrease according to v t = δ √ t . Then, under suitable conditions ( f t are L -Lipschitz and the distance b et w een t wo p oints D ( x k x 0 ) ≤ F 2 ), R [ X ] := T X t =1 [ f t ( ˜ x t ) − f ( x ∗ )] ≤ σ L 2 √ T + F 2 √ T σ + 4 δ LP √ K T Dividing b oth sides by T , w e see that V AP conv erges at rate O 1 √ T when all other quan tities are fixed. 3.1 Pro of of Theorem 1 W e follow the pro of of [5]. Define D ( x k x 0 ) := 1 2 k x − x 0 k 2 , where k · k is the ` 2 norm. Pro of: W e hav e , R [ X ] := T X t =1 f t ( ˜ x t ) − f t ( x ∗ ) ≤ T X t =1 h∇ f t ( ˜ x t ) , ˜ x t − x ∗ i ( f t are conv ex) = T X t =1 h ˜ g t , ˜ x t − x ∗ i . where we hav e defined ˜ g t := ∇ f t ( ˜ x t ). The high-level idea is to sho w that R [ X ] ≤ o ( T ), whic h implies E t [ f t ( ˜ x t ) − f t ( x ∗ )] → 0 and th us con vergence. First, we shall say something ab out each term h ˜ g t , ˜ x t − x ∗ i . Lemma 2: If X = R n , then for all x ∗ , h ˜ x t − x ∗ , ˜ g t i = 1 2 η t k ˜ g t k 2 + D ( x ∗ k x t ) − D ( x ∗ k x t +1 ) η t + h ∆ t , ˜ g t i Pro of: D ( x ∗ k x t +1 ) − D ( x ∗ k x t ) = 1 2 k x ∗ − x t + x t − x t +1 k 2 − 1 2 k x ∗ − x t k 2 = 1 2 k x ∗ − x t + η t ˜ g t k 2 − 1 2 k x ∗ − x t k 2 = 1 2 η 2 t k ˜ g t k 2 − η t h x t − x ∗ , ˜ g t i = 1 2 η 2 t k ˜ g t k 2 − η t h ˜ x t − x ∗ , ˜ g t i − η t h x t − ˜ x t , ˜ g t i = 1 2 η 2 t k ˜ g t k 2 − η t h ˜ x t − x ∗ , ˜ g t i − η t h− ∆ t , ˜ g t i 5 Th us, D ( x ∗ k x t +1 ) − D ( x ∗ k x t ) = 1 2 η 2 t k ˜ g t k 2 − η t h ˜ x t − x ∗ , ˜ g t i − η t h− ∆ t , ˜ g t i D ( x ∗ k x t +1 ) − D ( x ∗ k x t ) η t = 1 2 η t k ˜ g t k 2 − h ˜ x t − x ∗ , ˜ g t i − h− ∆ t , ˜ g t i h ˜ x t − x ∗ , ˜ g t i = 1 2 η t k ˜ g t k 2 + D ( x ∗ k x t ) − D ( x ∗ k x t +1 ) η t + h ∆ t , ˜ g t i . This completes the pro of of Lemma 2. Bac k to Theorem 1: Returning to the pro of of Theorem 1, we use Lemma 2 to expand the regret R [ X ]: R [ X ] ≤ T X t =1 h ˜ g t , ˜ x t − x ∗ i = T X t =1 1 2 η t k ˜ g t k 2 + T X t =1 D ( x ∗ k x t ) − D ( x ∗ k x t +1 ) η t + T X t =1 h ∆ t , ˜ g t i = T X t =1 1 2 η t k ˜ g t k 2 + h ∆ t , ˜ g t i + D ( x ∗ k x 1 ) η 1 − D ( x ∗ k x T +1 ) η T + T X t =2 D ( x ∗ k x t ) 1 η t − 1 η t − 1 W e now upp er-bound each of the terms: T X t =1 1 2 η t k ˜ g t k 2 ≤ T X t =1 1 2 η t L 2 (Lipsc hitz assumption) = T X t =1 1 2 σ √ t L 2 ≤ σ L 2 √ T , and D ( x ∗ k x 1 ) η 1 − D ( x ∗ k x T +1 ) η T + T X t =2 D ( x ∗ k x t ) 1 η t − 1 η t − 1 ≤ F 2 σ + 0 + F 2 σ T X t =2 h √ t − √ t − 1 i (Bounded diameter) = F 2 σ + F 2 σ h √ T − 1 i = F 2 σ √ T , and T X t =1 h ∆ t , ˜ g t i ≤ " T X t =1 2 v t √ K ( P − 1) L # (Lemma 1 plus Lipsc hitz assumption) = " T X t =1 2 δ √ t √ K ( P − 1) L # ≤ 4 δ LP √ K T . 6 Hence, R [ X ] ≤ T X t =1 h ˜ g t , ˜ x t − x ∗ i ≤ σ L 2 √ T + F 2 √ T σ + 4 δ LP √ K T . This completes the pro of of Theorem 1. 4 P arameter Serv er Design and Implemen tation Server 0 Client Process 0 Client Library Thread Cache Thread Cache Client Thread Process Cache Client Thread Server 1 Client Process 1 Client Library Thread Cache Thread Cache Client Thread Process Cache Client Thread Client Process n Client Library Thread Cache Thread Cache Client Thread Process Cache Client Thread ... ... Server n Figure 2: Parameter serv er architecture: a hierachical cache is used to minimize netw ork comm unication o verhead and reduce conten tion among application threads. W e implemen ted the prop osed consitency mo dels in a parameter server, called Petuum PS. F or the purp ose of comparison, Petuum PS also implemented SSP . Petuum PS is implemented in C++ and ZeroMQ is used for net work communication. P etuum PS contain s a collection of server pro cesses, which holds the shared parameters in a distributed fashion.. An application pro cess accesses the shared parameters via a clien t library . The client library cac hes the parameters in order to minimize netw ork communication ov erhead. An application pro cess may contain m ultiple threads. The clien t library allo cates a thread cac he for each application thread to reduce con tention among them. A thread is considered as a work er in our consistency mo de description. The parameter server arc hitecture is visualized in Fig 2. 4.1 System Abstraction P etuum PS organizes shared parameters as tables. Thus a parameter stored in Petuum PS is identified by a triple of table id, row id and column id. P etuum PS supp orts b oth dense and sparse rows corresp onding to dense and spares column index. A table is distributed across a set of serv er pro cesses via hash partitioning and row is the unit of data distribution and transmission. The data stored in one table m ust b e of the same t yp e and P etuum PS can supp ort an unlimited num b er of tables. It’s w orth men tioning that our implemen tation allo ws different tables to use different consistency mo del. P etuum PS supp orts a set of straigh tforward APIs for data access. The main functions are: • Get(table id, row id, column id) : Retriev e an element from a table. • Inc(table id, row id, column id, delta) : Update an element by delta. • Clock() : Incremen t the w orker thread’s clo c k by 1. 7 Consistency Controller Get Inc Clock GetPolicy IncPolicy ClockPolicy Consistency Policy OpLog Tablet Data Storage Figure 3: Consistency Controller and Consistency Policy 4.2 System Components P etuum PS’s client library employs a tw o-level cache hierach y to hide netw ork access latency and minimize con tension among application threads: all application threads within a process share a process cache whic h cac hes rows fetched from server. Each thread has its own thread cac he and accesses to data are mostly serviced by thread cache as long as memory suffices. In order to supp ort asynchronous computation, thread cac he emplo ys a write-back strategy . In order to supp ort Clo c k-based consistency mo dels, the system needs to keep track of the clo c k of each w orker. This is ac hieved via using vector clo c k. Each client library maintains a vector clo c k where each en tity represents the clock of a thread. The minm um clock in the vector represents the progress of the pro cess. Server treats a pro cess as an en tity and its v ector clo c k keeps track of the progress of all pro cesses. Async hronous system tends to congest the netw ork with large volume of messages. Our client and server th us batch messages to ac hieve high throughput. Messages are sent out based on their priorities whic h might b e application-dep enden t. W e by default prioritize up dates with larger magnitude as they are more lik ely to contribute to con vergence. 4.3 Implemen ting Consistency Models W e implement SSP , CAP , V AP and CV AP in a unified, mo dular fashion. W e realized that those consistency mo dels can be implemented b y p erforming different op erations up on application threads accessing param- eters. In other words, the exact sematics of the APIs dep end on the consistency mo del being used. Eac h consistency mo del is expressed as a Consistency Policy data structure. Eac h table is asso ciated with a Con- sistency Contr ol ler , which c hec ks Consistency Policy and services user accesses accordingly . The consistency con trol logic is visualized in Fig 3. Differen t semantics of the APIs include netw ork communication and blo c king wait for responses. Petuum PS uses three t yp es of netw ork communications: • Client Push : Clien t pushes one or a batched set of up dates to server. • Client Pull : Clien t pull a row from serv er • Server Push : Serv er pushes one or a batched set of up dates to relev ant clien ts. Coupled with prop er cache coherence mechanism, those APIs are sufficien t for implementing our consis- tency mo dels. 5 Ev aluation W e ev aluate our prototype parameter server via topic mo deling. Latent Diric hlet Allo cation (LDA) [2] is a p opular unsup ervised mo del that discov ers a latent topic vector for each do cumen t. W e implemen ted LDA 8 20News # of do cs 11269 # of words 53485 # of tokens 1318299 T able 1: Summary statistics of tw o corpra used in LD A. on our parameter server with the weak V AP model and conducted exp erimen ts on a 8-no de cluster. Eac h no de is equipped with 64 cores and 128GB of main memory and the no des are connected with a 40 Gbps Ethernet netw ork. W e restrict our exp erimen t to use at most 8 cores and 32GB of memory p er mac hine to emm ulate cluster with normal mac hines. W e used a relatively small dataset 20News and ev aluted the strong scalability of the system in particular. Statistics of the 20News dataset are sho wn in T able 1. W e fixed the n umber of top cis to b e 2000 while v arying the num b er of work ers. W e assign each work er a core exclusively . W e sho w the results in Figure 5 where the num b er of cores used ranges from 8 to 32. The curv e sho wed the sp eed up using P etuum-PS vs. ideal linear scalabilit y . Even though our exp erimen ts are conducted on a relativ ely small scale, the results show that it has a great p oten tial to scale up. A ckno wledgments W e thank PRObE [4] and CMU PDL Consortium for pro viding testb ed and technical supp ort for our exp erimen ts. References [1] Amr Ahmed, Moahmed Aly , Joseph Gonzalez, Shrav an Naray anamurth y , and Alexander J. Smola. Scalable inference in latent v ariable mo dels. In Pr o c e e dings of the Fifth A CM International Confer enc e on W eb Se ar ch and Data Mining , WSDM ’12, pages 123–132, New Y ork, NY, USA, 2012. ACM. [2] David M. Blei, Andrew Ng, and Michael Jordan. Latent dirichlet allo cation. JMLR , 3:993–1022, 2003. 9 [3] James Cipar, Qirong Ho, Jin Kyu Kim, Seunghak Lee, Gregory R. Ganger, Garth Gibson, Kimberly Keeton, and Eric Xing. Solving the straggler problem with b ounded staleness. In Pr o c. of the 14th U senix W orkshop on Hot T opics in Op er ating Systems , HotOS ’13. Usenix, 2013. [4] Garth Gibson, Gary Grider, Andree Jacobson, and W y att Lloyd. Prob e: A thousand-node exp erimen tal cluster for computer systems research. volume 38, June 2013. [5] Qirong Ho, James Cipar, Henggang Cui, Seunghak Lee, Jin Kyu Kim, Phillip B. Gibb ons, Garth A. Gibson, Greg Ganger, and Eric Xing. More effective distributed ml via a stale synchronous parallel parameter server. In A dvanc es in Neur al Information Pr o c essing Systems 26 , pages 1223–1231. 2013. [6] R. J. Lipton and J. S Sandb erg. Pram: A scalable shared memory . T echnical Rep ort CS-TR-180-88, Princeton Universit y , Sep 1988. [7] Y ucheng Lo w, Danny Bickson, Joseph Gonzalez, Carlos Guestrin, Aap o Kyrola, and Joseph M. Heller- stein. Distributed graphlab: A framework for mac hine learning and data mining in the cloud. Pr o c. VLDB Endow. , 5(8):716–727, April 2012. [8] Grzegorz Malewicz, Matthew H. Austern, Aart J.C Bik, James C. Dehnert, Ilan Horn, Naty Leiser, and Grzegorz Cza jk owski. Pregel: A system for large-scale graph pro cessing. In Pr o c e e dings of the 2010 A CM SIGMOD International Confer enc e on Management of Data , SIGMOD ’10, pages 135–146, New Y ork, NY, USA, 2010. ACM. [9] Russell Po wer and Jiny ang Li. Piccolo: Building fast, distributed programs with partitioned tables. [10] Alexander Smola and Shrav an Naray anam urthy . An architecture for parallel topic mo dels. Pr o c. VLDB Endow. , 3(1-2):703–710, September 2010. [11] Doug T erry . Replicated data consistency explained through baseball. Commun. A CM , 56(12):82–89, Decem b er 2013. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment