Low-Rank Separated Representation Surrogates of High-Dimensional Stochastic Functions: Application in Bayesian Inference
This study introduces a non-intrusive approach in the context of low-rank separated representation to construct a surrogate of high-dimensional stochastic functions, e.g., PDEs/ODEs, in order to decrease the computational cost of Markov Chain Monte C…
Authors: AbdoulAhad Validi
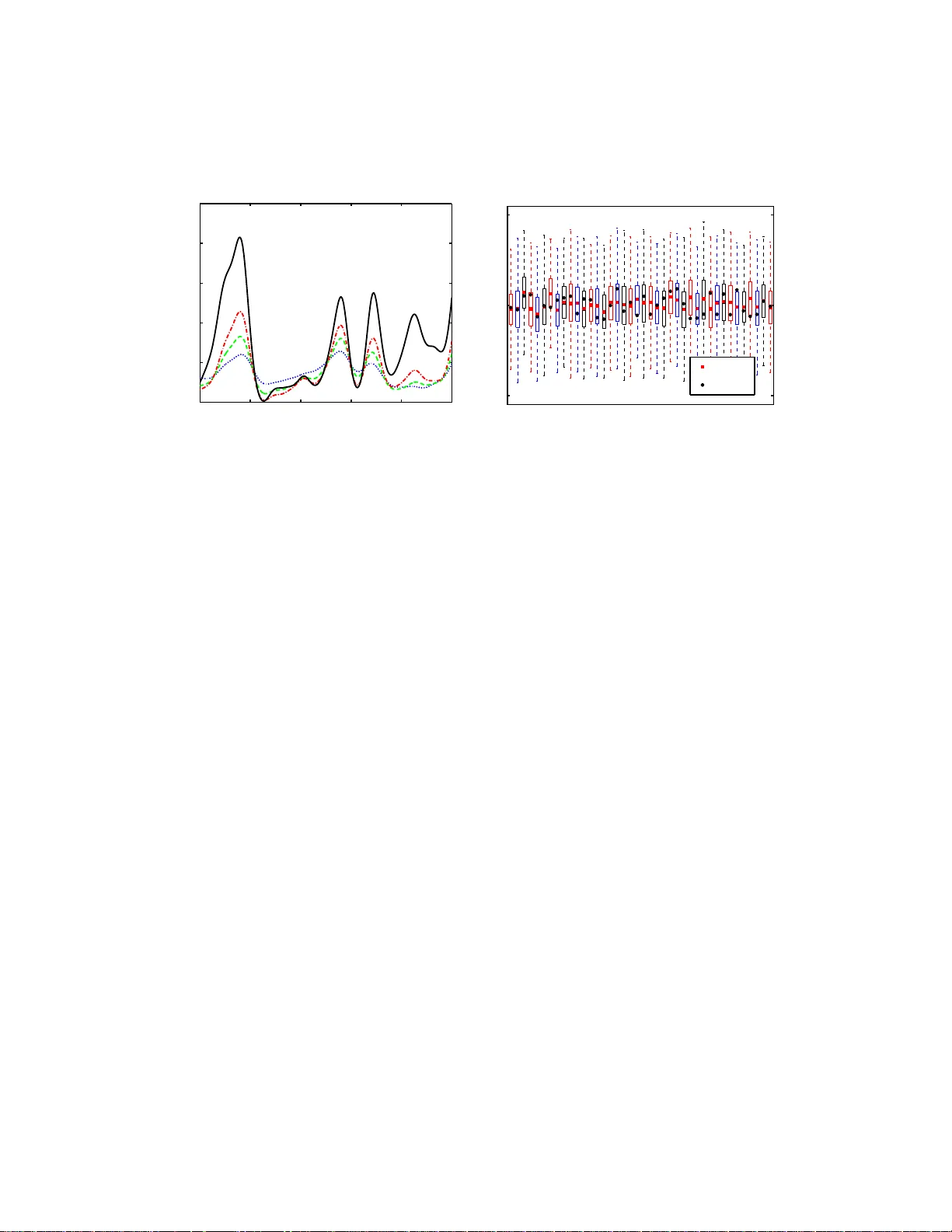
Lo w-Rank Separated Represen tation Surrogates of High-Dimensional Sto c hastic F unctions: Application in Ba y esian Inference Ab doulAhad V alidi Me cha nic al Engine ering Dep artment, Michigan State University, East L ansing, MI, 48824 , US A Abstract This study in tro duces a non-in trusiv e appro ac h in the conte xt of low-rank separated represen tation t o construct a surrogate of high- dimensional sto c has- tic functions, e.g., PDEs/ODEs, in or der to decrease the computationa l cost of Mark o v Chain Mon te Carlo sim ulations in Bay esian inference. The surro- gate mo del is constructe d via a regularized alternativ e least- square regression with Tikhono v regularization using a roughening matrix computing the gra- dien t of the solution, in conjunction with a p erturbatio n-based error indicator to detect optimal mo del complexities. The mo del approximates a v ector of a con tinuous solutio n a t discrete v alues of a physic al v ariable. The required n um b er of random realizations to ac hiev e a succ essful approximation lin- early dep ends on the function dimensionalit y . The computational cost of the mo del construction is quadratic in the n umber of ra ndom inputs, whic h p oten tially tac kles the curse of dimensionality in high- dimensional sto c hastic functions. F urthermore, t his v ector v alued s eparated represen tation-based mo del, in comparison to the a v ailable scalar-v alued case, leads to a signifi- can t r eduction in the cost of appro ximation b y an order of magnitude equal to the v ector size. T he perfo rmance of the metho d is studied t hr o ugh its application to three n umerical examples including a 41-dimensional elliptic PDE and a 2 1-dimensional cavit y flo w. Keywor ds: Separated represen tation; In ve rse problem; Ba y esian inference; Uncertain ty quantification; High-dimensional PDE/OD E Email addr ess: v alidia b@msu.e du (AbdoulAhad V a lidi) Pr eprint submitte d to Elsevier July 16, 2018 1. In tro duction An in vers e problem arises when the inputs/complex ities of a mo del are es- timated indirectly from outputs, e.g., noisy observ ations [57, 38 , 54, 12, 5, 13, 56]. In this context, the Ba y esian a pproac hes, whic h hav e recen tly attracted m uc h atten tion [6, 18, 52], pr ovide a pplied probabilit y and uncertain ty mea- suremen ts f o r statistical inference. Indeed, as an exten tion of con v en tional statistical metho ds [3 3, 23, 29, 57], the solution o f the Ba y esian inference is a p osterior probability distribution ov er the mo del input/complexities regard- ing av ailable/unav ailable prior kno wledge ab out them [3]. The computational cost of estimating the p osterior distribution is a c ha llenge in practice, and, in resp onse, many asymptotic, deterministic, and sampling ba sed metho ds ha v e b een dev elop ed fo cusing on reductions of or surrogates the forw ard mo del [48, 42, 40 , 41, 3 2 ]. Deterministic metho ds might b e reasonable alternatives in low to mo der- ate dimensions, but for high-dimensional and complex problems, the Mark o v Chain Monte Carlo (MCMC) [4 4 ] strategy is a more g eneral and flexible approac h [11 , 55, 21, 30]. The MCMC a ppro ac h requires ev aluation of the lik eliho o d function [45], indeed, solving the fo r ward model man y times, whic h migh t b e costly and/o r in tractable. In the case of in tensiv e computational mo dels, e.g., those describ ed b y a system of Ordinary Differen tial Equations (ODEs) or P artial Differen tial Equations (PDEs), the cost of suc h an ap- proac h b ecomes prohibitiv e. T o do so, generalized p olynomial c haos (g PC)- based [58], Sto c hastic Galerkin, and Collo cation metho ds [42, 14] ha ve b een dev elop ed. How ev er, these approaches are attractiv e alternatives for low (o r mo derate) dimensions. In the case of high-dimensional problems, low-r an k non-intrusive sep ar ate d r epr esentation appr oximation of the mo del is pro - p osed to construct a surrogate of the fo rw ar d mo del [8, 9, 2, 15]. Then, for efficien t Ba y esian inference, this surrog a te mo del is used in computing the lik eliho o d function, as well as the p osterior probabilit y distribution function. In 192 7, Hitc hco c k [31] introduced separated represen ta tion, whic h is also kno wn as para llel fa ctor analysis or canonical decomp osition, to express a P o ly adic as a sum of pro ducts of rank-one v ectors. Subsequen tly , t his ap- proac h ha s b een widely used in a v ariet y of areas including c hemical kinetics [15], data mining [1, 35, 28, 36], and image pro cessing [17, 5 0]. Here, a n approac h is pr o p osed t o construct a v ector v alued separated represen t a tion 2 of a con tinuous sto chastic function of a ph ysical random v ariable ξ and input random v a riables y , i.e., u ( ξ , y ), y = ( y 1 , . . . , y d ), d ∈ N . This function can b e approximated with accuracy O ( ǫ ) in a separated form as u ( ξ , y ( w )) = r X l =1 s l u l 0 ( ξ ) d Y i =1 u l i ( y i ( w )) + O ( ǫ ) , (1) where u l 0 ( ξ ), whic h is a v ector v alued univ ariate function of a phy sical v ari- able ξ ; u l i ( y i ( w )) d i =1 , l = 1 , . . . , r , whic h are univ ar iate functions of ran- dom v ariables; and s l , whic h are normalization constan ts; are unkno wn and m ust b e computed. Because the separation rank, r , as o ne o f the mo del complexities, is indep enden t of problem dimensionalit y [7, 9, 8, 15], d , the computational complexit y is a w eakly-linear f unction in d , whic h remark ably reduces the curse o f dimensionalit y , a b ottlenec k for uncertain t y quan tifica- tion of high-dimensional f unctions. F urthermore, the mo del has low -rank separated represen tation approximation structure if a small separation rank can b e found for it. This study is o rganized a s follows. In section 2, the Bay esian inference is discusse d in mor e detail. In section 3, the general problem setup describ ed for either system of ODEs or PDEs. Thereafter, in se ction 4, the v ector case of the separated represen ta tion is in tro duced, and in sections 4.1 and 4.2, a regularization approach and an error indicator are prop osed fo r sta- bilizing the metho d and finding the optim um construction of the separated mo del. In section 5, the results are presen ted for three different examples: a man ufactured function, a n elliptic equation, and a cav it y flow problem. 2. Ba y esian Inference The goa l of an in v erse problem is to recov er anterior information from a v ailable data [12, 57, 5]. The quantit y of in terest, u , in the forw ard problem con text is computed given a mathematical mo del, A , and par a meters, y ; ho w ev er, in the in vers e problem either the parameters or the mathematical mo del is computed giv en the o t her t w o quan t ities. Considering a g eneral sy stem of equations A ( y ) ≈ u , there are tw o main approache s for parameter estimation: main classical least squares 1 and 1 The classica l leas t square approaches are linear and non- linea r r egressio n, and data fre e inference [57, 3 4]. 3 Ba y esian strategies. In the Ba y esian approac hes the mo del is treated as a random v ar iable and the solutions are probabilit y distributions for those mo del par ameters that are sought [3]. Detailed statistical kno wledge (e.g., mo de, mean, standard deviation, correlat io n, smo othness, etc.) of the pa- rameters can b e rev ealed using the probability distributions, while in the classical metho ds the solutio ns are p o in t quan tities and the parameter statis- tics are not a v ailable. In Ba y esian approach es, the prio r information, whic h comes from other sources (e.g., ph ysical and exp erimen tal observ ations), is called the “ pr ior distr ibution ” of parameters y , and is denoted by p ( y ). The “ poster ior d istr ibution ”, q ( y | u ), can b e fo rm ulat ed b y incorp orating the giv en data along with the prior distribution in Ba y es’ theorem [4, 16] as follo ws: q ( y | u ) = p ( u | y ) p ( y ) R p ( u | y ) p ( y ) d y . (2) The data are incorp o r a ted in the formulation through the lik eliho o d func- tion p ( u ), whic h can b e presen ted as L ( y ) ≡ p ( u | y ). Remark 1. In r e ality, prior and p osterior distributions show the str ength of p er c eption ab out fe asible values for the inputs, y , b efor e and after exp erienc- ing the outputs, u . Mor e pri o r inform a tion on the mo del p ar a meters, e. g . , a r ange of p ossible va lues, le ads to a mo r e suitable prior distribution. If ther e is no availabl e prior information ab out the p ar ameters, then b ase d on “the principle of indiffer enc e” an “uninformative” prior distribution is chos e n; in which al l the mo del p ar ameter values a r e a s sume d to have the same likeliho o d. In general, determining the p osterior distribution is computationally ex- p ensiv e and pro blematic due to the integral in (2) , whic h is usually a high- dimensional integral. A t ypical simplified mo del is assumed when the v alue of the in tegral is not really needed. In t hese situations tw o differen t mo del p osterior distributions are compared by computing the lik eliho o d functions; therefore Eq. (2) can b e written as q ( y | u ) ∝ p ( u | y ) p ( y ) . (3) The g eneral system of equations is conv erted to u = A ( y ) + η , (4) where η is a ssumed to b e an independent and iden tically distributed (i.i.d) noise vec tor of size n , which is normally distributed with zero mean, σ stan- dard deviation, and p η noise densit y , i.e., η k ∼ N (0 , σ 2 k ) , k = 1 , . . . , n . Here, 4 η may cov er b oth exp erimen tal and mo delling erro rs. The mo delling error encompasses n umerical errors and the errors due to simplifying assumptions neglecting some ph ysics of t he problem. The lik eliho o d function L ( y ) can b e presen ted as: L ( y ) ≡ N Y j =1 p η u ( j ) − A ( j ) ( y ) . (5) Therefore, the p osterior distribution can b e written as q ( y | u ) ∝ L ( y ) p ( y ) , (6) b y comparing equations (5) and (3). Remark 2. I n the c ase of i.i.d noise in the me asur e d data, A ( u | y ) is nor- mal ly di stribute d with u me an and σ standa r d dev iation, i.e., A ( u | y ) ∼ N ( u , σ 2 ) . The c haracteristics of the p osterior distributions can be computed b y sev eral metho ds including n umerical in tegration, asymptotic appro ximation, and sampling-based approac hes [24, 43]. The sampling-based approac hes generate samples man y times to examine whether the prior distribution ap- pro ximates the p osterior distribution. Sev eral sampling metho ds are av ail- able to explore p osterior distributions [19, 20, 53, 59, 51] for low and mo derate- dimensional problems. Because this w ork deals with high-dimensional prob- lems, the Marko v Chain Monte Carlo strategy (MCMC) o f Bay esian inference is used a lo ng with the combination of tw o p o w erful ideas: Dela ying Rejection (DR) [55, 46, 2 2] and Adaptive Metrop olis (AM) sampling [26, 27], whic h together are kno wn as DRAM [25]. In the DRAM approach, the f orw a r d mo del ma y need to b e computed, e.g., 10 6 times, whic h migh t b e v ery exp ensiv e. In o r der to decreas e the computational cost of the sim ulations, v a rious methods suc h as generalized p olynomial c haos, Sto chas tic G alerkin, and Collo cation w ere dev elop ed t o appro ximate the output [58, 42, 14]. The cost f unction of those prop osed mo dels is exp onen tially prop ortional to the problem dimension; therefor e they a re adequate for lo w to mo derate-dimensional problems. Here, for high- dimensional problem cases, a surrogate mo del in the context of separated represen tation [8] is dev elop ed, in whic h the computational cost is a quadratic function o f the dimensionalit y . In section 4, the separated repres en tation appro ximation is explained in detail. In t he next section, the problem setup is introduced for the PDE/ODE system of equations. 5 3. Problem Setup Let (Ω , F , P ) b e a complete probabilit y space, where F is the σ -algebra of ev ents , Ω is t he set of elemen tary ev ents, a nd P : F → [0 , 1] is a probability measure on σ − field F . A generic sto c hastic P artial/Ordinary Differen tial Equation (PDE/O D E) can b e formulated as A ( ξ , y ( ω ); u ) = 0 , ( ξ , ω ) ∈ [Ξ 1 , Ξ 2 ] × Ω , (7) where A defines the f o rw ar d mo del. ξ ∈ [Ξ 1 , Ξ 2 ] , (Ξ 1 , Ξ 2 ) ∈ R × R , is a ph ysical (spatial/temp ora l) v ariable and y ( ω ) = ( y 1 ( ω ) , . . . , y d ( ω )) : Ω → R d , d ∈ N , is a v ector of random inputs con taminated by uncertainties . According to a probability densit y function of y i , ρ ( y i ) : Γ ⊆ R → R ≥ 0 , where i v aries from 1 to d , the comp onents of the random ve ctor y ( ω ) are assumed i.i.d. u is the con tin uous solution, but, here, a discrete approx imation or a v ector v alued solution at n different v alues of ξ is considered, i.e., u : R d +1 → R n . Indeed, the solution of interes t can b e show n as: u ( ξ , y ( w )) := u ( ξ , y 1 ( w ) , . . . , y d ( w )) : [Ξ 1 , Ξ 2 ] × Γ d → R n . (8) F urthermore, an appropriate b oundary conditions and initial v alues ar e con- sidered related to the problems in tr o duced by (7). 4. Separated Represen tation Separated repres en tation techniq ues in high-dimensional function approx- imations, p ot entially eliminate the curse of dimensionalit y by appro ximating a d -dimensional function b y solving d one-dimensional functions [8 , 15, 9]. In this section the separated represen ta t io n heuristic, a n algorithm for the tec hnique, and core principles are review ed. T o a void instabilit y , a Tikhono v regularization is intro duced and to detec t the optimal mo del structure, a p erturbation-based error indicator is defined. The goal is to non- linearly estimate the v ector v alued f unctions u ( ξ , y ( w )) using the equiv a len t separated represen t ation as: u ( ξ , y ( w )) = r X l =1 s l u l 0 ( ξ ) d Y i =1 u l i ( y i ( w )) + ε . (9) Here, r ∈ N , the separation rank, is not giv en a priori and is esti- mated b y the defined error indicator, whic h is describ ed in section 4.2. u 0 6 is a v ector v alued univ aria t e function of a temporal/ spatia l v ariable and u l i ( y i ) d i =1 ∈ R , l = 1 , . . . , r are univ ar iate functions of random input v ari- ables y i . { s l } r l =1 ∈ R > 0 are scalar normalization v alues. Similar to the separation rank, these v alues ar e not kno wn a priori and mus t b e computed. Definition 1. The sp ac e of r -se p ar ation r ank and d + 1 -dimensiona l f unction s is U r = ( r X l =1 s l u l 0 d Y i =1 u l i ( y i ) ) . (10) Definition 2. Given a set of N indep endent r andom inputs y ( j ) , j = 1 , . . . , N , and the c orr esp onding ve ctor v a lue d solutions with size n , the data set D is define d by D = y ( j ) ; u ( j ) ξ , y ( j ) N j =1 , (11) and the F r ob enius norm of u is fo rm ulate d as k u k D = h u , u i 1 2 D , (12) wher e the i n ner pr o duct b e twe en u and v c an b e define d such that h u , v i D = D y ( j ) , u ( j ) ξ , y ( j ) N j =1 , y ( j ) , v ( j ) ξ , y ( j ) N j =1 E D (13) = 1 nN N X j =1 u ( j ) · v ( j ) . The separated appro ximation of u , u s , can b e estimated via the solution of a least-squares regression problem u s = a r g min ˆ u s ∈ U r k u − ˆ u s k 2 D . (14) The current non-linear sc hemes to solv e non-linear optimization prob- lems (14), e.g., damp ed Gauss-Newton [10], ar e prohibitiv ely expensiv e for high-dimensional problems and are limited to low (or mo derate)-dimensional problems. Alternativ ely , for high-dimensional problems, the m ulti- linear al- ternating least squares (ALS) metho d [49] is used. In this approach , at the separation rank l , the univ ariat e function along dimension k , u l k ( y k ), is solved b y cons tructing the related one-dimensional least-squares regression problem, and freezing the other univ ariate functions u l i ( y i ) , i = 1 , . . . , d, i 6 = k , at their 7 curren t v alues. The regression pro cess is rep eated for eac h dimension in turn till a ll the univ ar ia te functions are solve d. With resp ect to the pro ba bilit y densit y functions of y i , ρ ( y i ), the uni- v ariate functions u l i ( y i ) are expanded in to a finite dimensional bases, e.g., orthogonal sp ectral p olynomials in the case of Polyn omial Chaos Expansion (PCEs). These functions are approx imated b y u l i ≈ M X α =0 c l α,i ψ α ( y i ) , (15) where { ψ α ( y i ) } is a set of sp ectral (e.g., Legendre and Hermit) p olynomi- als of degree α ≤ M ∈ N 0 := N ∪ { 0 } . The expansion co efficien ts c i := c 1 0 ,i , . . . , c 1 M ,i , . . . , c r 0 ,i , . . . , c r M ,i ∈ R r ( M +1) along dimension i = 1 , . . . , d , are computed b y reducing (14) to a discrete least-squares o ptimization suc h as c i = a r g min ˆ c i k u − ˆ u r k 2 D (16) = a r g min ˆ c i u − u 0 r X l =1 M X α =0 ˆ c l α,i ψ α ( y i ) ! s l d Y k =1 6 = i u l k ( y k ) 2 D . Here ˆ u r is a rank ed r appro ximation of u . The first deriv ativ e of (1 4 ) with resp ect to the ra ndom input v a riables is set to zero t o compute the expansion co efficien ts, whic h leads t o solve the follo wing system of syste m of equations: A T i A i c i = A T i u , i = 1 , . . . , d. (17) The matrix A i ∈ R ( nN ) × ( r ( M +1)) is a column blo ck structured matrix, A i = [ A 1 i . . . A r i ]. Each column-blo c k matrix A l i ∈ R ( nN ) × ( M +1) , is computed b y A l i (( j − 1) n + 1 : ( j − 1) n + n, α + 1) (18) = u 0 s l ψ α ( y ( j ) i ) d Y k =1 6 = i u l k ( y ( j ) k ) , i = 1 , . . . , d. Because the function u may not b e a smo oth function of the phys ical random v ariable, u 0 is directly solv ed without expanding it into a sp ectral p olynomial. The equiv alen t relations of (16), (17), and (18) for solving u 0 8 are u 0 = a r g min ˆ u 0 k u − ˆ u r k 2 D (19) = a r g min ˆ u 0 u − u 0 r X l =1 s l d Y i =1 u l i ( y i ) 2 D , A 0 u 0 = u , (20) and A l 0 (( j − 1) n + 1 : ( j − 1) n + n, α + 1) (21) = u 0 s l d Y i =1 u l i ( y ( j ) i ) , A l 0 ∈ R ( nN ) × ( r ( M +1)) , resp ectiv ely . The non-intrus iv e separated r epresen tation appro ximation, similar to other regression metho ds, may suffer f rom the iss ue of instability for the g iven com- plexit y parameters; therefore, Tikhono v regularization is utilized here. 4.1. R e gularization In eac h iteration of the ALS algorithm that the unkno wns of the sepa- rated r epresen tation form ulation are up dated, the residual norm k u − u s k D decreases. Mo del structures with larger v alues of ( r, M ) lead to a g reater decrease of the residual norm; therefore, one may expect that the larger the v alues of the mo del complexities, the more accurate the results. Ho we v er, in the cases of non- separable functions, lack of information, or noisy data, excess iv e reduction o f the residual norm results in instabilit y , in whic h the metho d can matc h t he realization solutions individually but b e completely unreasonable for other data p oin ts. A naive parametric approa c h to a v oid this issue is c ho osing small v a lues fo r ( r , M ), whic h may lead to unfitted appro ximation. Instead, a non-parametric approac h is used based on the concept of regularization b y encouraging additional smo o t hness constraints on the approxim ated solution, u s . F or a given r and M a Tikhono v reg- ularization [3] is examined b y adding a smo othness penalty term k Lc k 2 2 , L ∈ R ( r ( M +1)) × ( r ( M +1)) , to the regression cost function (16), i.e., c r eg = arg min ˆ c r eg 1 nN k A ˆ c r eg − u k 2 2 + λ 2 k L ˆ c r eg k 2 2 , (22) 9 where L is a roughening matrix, λ ∈ R ≥ 0 is a regularizatio n parameter, and c r eg is a matrix of the expansion co efficien ts. Selecting suitable v alues f o r λ and L is essen tial for b etter p erforma nce of the Tikhono v regularizatio n. Among sev eral av aila ble statistical metho ds to estimate the λ , e.g., Moro zo v’s Discrepancy Principle, L-curve , Predictiv e Risk Estimator, and G eneralized Cross V alidation (GCV) [4 7, 29, 3 ], the GCV is found to b e more accurate and used in this study . The v a lue of λ in comparison to the singular v alues of A is imp ortan t to the question of whether to regularize the problem. Consider ς j , where j = 1 , . . . , nN , as a singular v alues of Singular V alue Decomp osition (SVD) of matr ix A , suc h that ς 1 ≥ ς 2 ≥ . . . ≥ ς nN . In tuitiv ely , if the v alue of the regularization parameter, λ , is close to the minim um singular v alue ς nN , i.e., λ ≤ C × ς nN , C ∈ R [0 . 99 1 . 01] , (23) the problem is not ill-p osed and the p enalt y term just adds no ise to it; there- fore, the regularization is not needed. In eac h iteration of the ALS pro cess this condition is chec k ed to decide whether to regular ize the problem. The other impo rtan t factor of the Tikhono v regularization is the rough- ening matrix, whic h aff ects the effectiv eness a nd p erformance of the metho d. In the standard form of the regularization, where the roughening matrix is a n iden tity matrix ( L = I ) , t he ob jecting function in v olving k c k 2 (and k u 0 k 2 ) is minimized. In highly sparse regions, where larg e deviations are p enalized in the reconstruction, the standard Tikhonov regular izat io n fa v ors inaccurate solutions. Therefore, a roughening matrix based on the solution gr adien t is deriv ed as follo ws k Lc k 2 2 = E ∇ u T s ∇ u s , (24) where ∇ u s is the gradien t of the separated appro ximation of u with resp ect to the y i , i = 1 , . . . , d . In comparison to the work of [15], where the second order momen t of the solutio n is considered, k Lc k 2 2 = E [ u 2 s ], the v alue of (24) is m uc h larger, whic h can promote smo othness and mo r e hea vily p enalize co efficien ts corresp onding to higher order p olynomials. In pra ctice, as will b e demonstrated by the n umerical examples in section 5, less instabilit y and more control ov er t he solution can b e exp ected. It is straigh tfor ward to sho w that E ∇ u T s ∇ u s = c T B c , where B = L T L ∈ R ( r ( M +1)) × ( r ( M +1)) is a p ositiv e definite and symmetric mat r ix. Eac h 10 ( l , l ′ )-th blo ck of B is computed b y the following equation: B ( l, l ′ ) = s l s l ′ u T 0 l u 0 l d Y i 6 = k M X α =0 c l α,i c l ′ α,i ! M X α =0 M X α ′ =0 c l α,k c l ′ α,k γ αα ′ ! I M + 1 , (25) where γ αα ′ = h∇ ψ α ∇ ψ α ′ i and I M + 1 denotes an identit y mat r ix of size M + 1 . The gradient of discretized u 0 can b e approx imated b y L 0 u 0 , where L 0 = -1 1 -1 1 . . . -1 1 -1 1 . (26) Similarly , the equiv alen t equation of (22) for u 0 is given b y u 0 r eg = a r g min ˆ u 0 r eg 1 nN k A 0 ˆ u 0 r eg − u k 2 2 + λ 2 k L 0 ˆ u 0 r eg k 2 2 . (27) The issue of instability could b e mitigated by regularization, but still there is a need to detect the optimal r and M to tackle the issue of o v er/under- fitting, when the complexit y para meters are greater or smaller than the op- timal v alues. In the next section, an indicator based on a p erturbation error is introduced to detect the optimal mo del complexities. 4.2. Perturb ation b ase d err or indic ator T o detect the optimal v alues of separated rank and p olynomial degree, ( r , M ), an error indicator is in tro duced by defining a p erturbation b ound on the sensitivit y of b oth regularized and non-regula r ized solutions (Equations: 16, 19, 22, and 27). F or regularized cases and i = 1 , . . . , d , the Pe rturbation- based Error Indicator (PEI) can b e deriv ed as P E I i = ( nN ) 0 . 5 λ − 1 i k L − 1 k 2 ˆ σ i k c i k 2 , i = 1 , . . . , d , (28) where c i is the solutio n o f the problem (16) and λ i is the regularization parameter for dimension i [5 7]. F or non-regularized cases, where λ i = 0 , the minim um singular v alue of matrix A in (28) is used instead. It is assumed that the separated represen ta tion errors, ε , in (9) can b e appro ximated b y 11 random v aria bles with zero means and σ standard deviations. Here, ˆ σ i is the estimation of the standard deviation σ i , which is giv en by ˆ σ i = k Ac i − u k 2 2 nN − tr ( H i ) . (29) The hat matrix , H i = A A T A + λ 2 i L T L − 1 A T , is a mapping matrix of the realizations to their separated represen tation approxim ations. F or the 0-th dimension the equiv alent error indicator is deriv ed as P E I 0 = ( nN ) 0 . 5 λ − 1 0 k L − 1 0 k 2 ˆ σ 0 k u 0 k 2 , (30) where λ 0 is a regularization parameter for dimension d + 1. F or each pair of ( r, M ) there is a ( d + 1) size PEI v ector asso ciated with the last iteration of the ALS. F or that particular pair, the ma ximum v alue of the PE I v ector, P E I ( r ,M ) max , is chose n. Notice that the PEI dep ends on r and M indirectly through c , and conserv ativ ely λ and L . The PEI asso ciated with unnecess arily small/la r ge mo del complexities is a large v alue. Ho w ev er, it is relativ ely small for those mo del complexities whic h could b e optima l, e.g., where the standard deviation erro r is minimal. Among all p ossible mo del structures, the one whic h correspo nds to the minim um v a lue of P E I ( r ,M ) max is selected as the optimal separated represen tation mo del. In algo rithm (1), the o v erall non-in trusiv e ALS pro cedure including the pro p osed regularization strategy and p erturbation error indicator is summarized. 4.3. Co m putational c ost It is w orthwhile to elab orate on the computational cost and complexit y of the algorithm. F or a giv en y i , each univ ariate function u l i ( y i ), is ev alu- ated with complexity O ( M K ) , where K is the n um b er of ALS iteratio ns. Therefore, the cost of computing mat r ix A in (17) is O ( r M dK N n ). F or a full sw eep of t he ALS, all the norma l equations (17) can be solved us- ing Cholesky decomp osition of A T A with complexit y O ( r 2 M 2 dK 2 N n 2 ) f or eac h. Similarly , equation (30) can b e computed with cost O ( r 2 K 2 N n ). It is assumed that N ≫ r M ( d + 1), whic h is an asymptotic but relev ant assumption. Therefore, the complexit y o f the alg o rithm is O ( r 3 M 3 d 2 K 2 n 2 ), whic h is quadratic in d . F or the situations where the forward mo del is ex- p ensiv e or the cost of a surrogate mo del exponentially grows as a function of 12 dimensionalit y , the separated approxim ation with this cost is an outstanding success . In the next section, the results of nu merical examples are prov ided. • Input : Dat a set D = y ( j ) ; u ( y ( j ) ) N j =1 and accuracy ǫ • Output : r , M , { c l α,i } d i =1 , and s l for α = 0 , . . . , M and l = 1 , . . . , r • Set r = 1 and M = 1 and initialize c i and u 0 randomly while k u − u s k D > ǫ do while k u − u s k D de cr e as e s much do for α ← 0 t o M do • Fix { c l α,i } d i =1 and solv e u 0 using: E q . (1 9) if (23) is .T rue. E q . (2 7) if (23) is .F a l s e . • Up date s l ← s l k u 0 k D and u 0 ← u 0 / k u 0 k D , for i ← 1 to d do • Fix { c l α,k } k 6 = i and solve { c l α,i } using: E q . (1 4 ) if ( 2 3) is .T rue. E q . (2 2 ) if (23) is .F a lse. • Up date s l ← s l k u l i k D and c l α,i ← c l α,i / k u l i k D end end end • Set r = r + 1 and (randomly) initialize c r i for i = 1 , . . . , d , and u r 0 • If r M d > N set r = 1 and M = M + 1; (randomly) initialize c i and u 0 end • Rep ort the optim um r and M based on the error indicator and corresp ondence c , u 0 , and s l Algorithm 1: The algorithm for constructing a separated represen ta- tion appro ximation mo del of a v ector v alued sto c hastic function, non- in trusiv ely . 13 1 2 3 4 5 10 −3 10 −2 10 −1 10 0 10 1 Average of relative error in standard deviation Separation rank (r) 1 2 3 4 5 10 −3 10 −2 10 −1 10 0 Perturbation−based Error Indicator (PEI) Minimum STD Error Minimum Error Indicator 10 −4 10 −3 10 −2 10 −1 10 0 10 −3 10 −2 10 −1 10 0 10 1 Residual norm Average of relative error in standard deviation M=2 M=5 M=3 M=4 Optimal (r,M)=(6,4) Based on the PEI (a) (b) Figure 1: Perturbation based error indicator (PEI) (Section 4.2) pe r formance in estimating the optimal s e paration r ank a nd p olynomial degree ( r , M ). (a) Relative sta nda rd devia - tion e rror and p erturba tion based error indicator vs. sepa ration r ank r for the o ptimal po lynomial de g ree M ; (b) Relative s tandard deviation err or vs. residual norm for different po lynomial degree M . (Relativ e error in standard deviation ( − − − ); Perturbation bas e d error indica tor (P EI) ( ◦ − − − )). 5. R esults In this section, the p erformance of the non-in trusiv e separated represen ta- tion mo del and its application in Bay esian inference is inv estigated through a 11-dimensional manufactured function, a 1D in space 41- dimensional elliptic PDE, and a 2 D in space 21-dimensional ca vit y flo w. 5.1. A manufactur e d function Here, to v erify algorithm 1, the follo wing 11-dimensional function is con- sidered: u ( ξ , y ) = u ( ξ , y 1 , . . . , y 10 ) = a 0 + a 1 sin ( π ξ ) y 1 + a 2 cos (3 π ξ ) y 2 3 − 1 (31) + a 3 sin (6 π ξ ) y 3 9 − 3 + ǫ , where { y i } 10 i =1 are indep enden t normal random v ariables, ξ is a spatial v ari- able, and u is a discretized v ector of the solution with size n = 20, i.e., u = { u j } n j =1 . The co efficien t s { a i } 3 i =0 are equal to { 0 . 55 , 1 , √ 2 4 , 0 . 1 √ 6 } . The noise ǫ is a i.i.d standard normal random v ariable with 0 . 00 5 standard devi- ation. The results are sho wn in Fig ures 1 a nd 2. 14 Figure 1 sho ws the p erformance of the p erturbation based error indicator (PEI) in estimating the optimal separatio n rank and p olynomial degree f o r the case N = 500. In Figur e 1. a the PEI sho ws t ha t the v alues of pair ( r , M ) = (6 , 4 ) are the optimal mo del complexities, whic h corresp ond to the smallest v alue of the standard deviation relativ e erro r . The PEI functionality for the case N = 500 is more clear, but for some cases it refers to the pair ( r , M ), where the standard deviation error is no t necess arily minimal, but it is still acceptable. In figure 1. b , relative standar d deviation erro r with resp ect to the residual norm is plotted for v arious M . The optimal pair ( r , M ) = (6 , 4) refers not only to the minim um standard deviation error but also to the smallest residual nor m a s w ell. The small separation r a nk r = 6 means that this man ufactured function can b e approxim ated b y a low- r ank separated mo del. It also can b e sho wn that larger v alues of p olynomial degree, ( M = 5), do not ne cessarily lead to more accurate mo dels. In general, the optimal v alues of pair ( r , M ) are not unique for a problem and migh t b e differen t fo r differen t data sets as w ell as differen t n um b ers of samples. Figure 2. a sho ws the opt ima l ( r, M ) for differen t num b ers of samples for the same problem. When the n um b er of samples is increased, more infor- mation is pro vided; therefore, the constructed mo dels compute the solutions with higher accuracy . This is sho wn in figure 2. b , where t he error in standard deviation decreases ab out one order of magnitude by increasing t he n um b er of samples from N = 500 to N = 1000 . The mean v alue of the solution is constan t a nd equal to 0 . 55. In figure 2. c , the difference of the predicted and exact mean is illustrated with respect to the spatial v a riable ξ . Figure 2. d sho ws t he standard deviation of the problem based on the separated repre- sen tatio n for the case N = 1000 in comparison to t he exact v alue. It also can b e observ ed from figure 2. b that the av erage ov er the spatial v ariable of the relativ e error s in standard deviation and mean are 0 . 001 and 0 . 0001, resp ectiv ely . 5.2. El liptic sto chastic e quation The ob jectiv e of considering an elliptic sto chastic equation is to esti- mate the diffusion co efficien ts from a v ailable (noisy) observ a t ions of the so- lution field b y MC MC, applying the separated represen tation-based surrogate mo del. Here, the forw ard mo del, A , is considered as the follo wing 1D in space el- liptic sto c hastic PDE on the unit in terv al [Ξ 1 , Ξ 2 ] = [0 , 1] and the con tin uous 15 10 2 10 3 10 4 1 2 3 4 5 6 7 Separation rank (r) Number of samples (N) 10 2 10 3 10 4 1 2 3 4 5 6 7 Polynomial degree (M) 10 2 10 3 10 4 10 −4 10 −3 10 −2 Average of relative error in standard deviation Number of samples (N) 10 2 10 3 10 4 10 −6 10 −4 10 −2 Average of relative error in mean (a) (b) 0 0.2 0.4 0.6 0.8 1 −4 −2 0 2 4 6 8 10 12 x 10 −6 Spatial coordinate ( ξ ) Approximated mean − Exact mean 0 0.2 0.4 0.6 0.8 1 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 Spatial coordinate ( ξ ) Standard deviation (c) (d) Figure 2: (a) Optimal pa ir of ( r, M ) based on PEI vs. num b er of samples; (b) Relative error in standard devia tion and mean vs. num b er o f samples (ba sed on the refer ence solution); (c) Approximated mean v alues min us the exact mean equals to 0 . 5 5 vs. spatial v aria ble ; a nd (d) sta ndard deviation of the problem vs. spatial v a riable. (Separ ation rank r ( ); Polynomial degree M ( ◦ ); Relative error in: standar d deviatio n ( − − − ) a nd mean ( ◦ − − − ); Separated representation approximation ( − − − ); Reference v alue ( . . . )). 16 domain ( D ⊂ R 1 ), with Dirich let b oundary conditions on ∂ D [39]: ∇ ( κ ( ξ , y ( w )) ∇ u ( ξ , w )) = − f ( ξ ) (32) u (0 , y ) = u (1 , y ) = 0 , where f ( ξ ) = 1 is assumed as a constan t source t erm . Here, ∇ ≡ ∂ /∂ ξ and t he PDE is spatially discretized b y the finite difference approach with spacing ∆ ξ = 1 / 1000 on a uniform grid. The κ describes a spatially heteroge- neous (diffusion) co efficien t a s a source of uncertainties that is sto chastically discretized b y the Ka r hunen-Lo ev e expansion κ ( ξ , w ) = κ 0 + exp d X i =1 p λ i φ i ( ξ ) y i ( w ) ! , (33) along with an offset κ 0 = 0 . 5. The { y i } d i =1 are indep enden t random v ariables uniformly distributed on [ − 1 , 1], where ( λ i , φ i ) are the pairs of eigen v alues and eigenfunctions of the cov ariance function c ( ξ , ξ ′ ) resp ectiv ely , i.e., Z D c ( ξ , ξ ′ ) φ ( ξ ′ ) d ξ ′ = λ i φ i ( ξ ) . (34) The c ( ξ , ξ ′ ) is the co v ar ia nce kerne l o f the G aussian pro cess with expo- nen tia l form as follows: c ( ξ , ξ ′ ) = σ 2 exp − ( ξ − ξ ′ ) 2 L 2 c ! , (35) with a prio r standar d deviation σ = 1 and corr elat io n length L c = 1 / 14. The eigenfunctions, φ i , are discretized on the same grid, where the solution field, u , is discretized. The observ ations, u , in equation (32 ) are o bta ined at n = 20 p oin ts in D using a finite elemen t based solv er prov ided in FEniCS. F ollow ing a lgorithm 1 with N = { 500 , 1000 , 2000 } samples, the separated represen tation mo dels are prepared to predict the solutio n o f the elliptic equation (32 ). T o find the optimal pair of ( r , M ), the minimum v alue of PEI is found. Figure 3. a sho ws the standard deviation error and PEI for t he case of N = 2000 and M = 3. In this case, the minimum v alue of PEI corresp onds to a separation rank of 12 and p olynomial degree o f 3, where the standard deviation error is also minimal. The optimal pair of ( r , M ) is obtained with 17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 10 −4 10 −3 10 −2 10 −1 10 0 10 1 Average of relative error in standard deviation Separation rank (r) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 10 1 10 2 10 3 Perturbation−based Error Indicator (PEI) Minimum Error Indicator Minimum STD Error 10 2 10 3 10 4 1 2 3 4 5 6 7 8 9 10 11 12 13 Separation rank (r) Number of samples (N) 10 2 10 3 10 4 1 2 3 4 5 6 7 8 Polynomial degree (M) (a) (b) Figure 3: The mo del p erformance in estimating the problem’s statistics and optimal sep- aration rank a nd p olyno mial degree with resp ect to the num b er of samples N (a) Relative standard deviation and mea n error s vs. num b er of samples a nd (b) O ptimal pair o f sep- aration ra nk and p olynomial degree vs. num b er of sa mples. (Relative error in: s tandard deviation ( − − − ) and mean ( ◦ − − − ); Optimal separation r ank ( ); Optimal p olynomial degree ( ◦ )). the same a na lysis for different n um b er of samples. As can b e seen in figure 3. b , there is no unique separation rank and p olynomial degree for t he problem, and these v alues dep end on the num b er of samples and the data set, e.g., the optimal pairs for N = 1000 and 2 000 are equal to (7 , 3) and (12 , 3), resp ectiv ely . Figure 4 illustrates the av erage relativ e errors in standard deviation and mean with res p ect to the n um b er of samples. The a verage is ov er the ph ysical v ariable of size n . The reference statistics are obta ined b y the Mon te Carlo (MC) approac h with N = 25000 samples to compare the predicted results with. It can b e seen that the separated represen tation mo del with N = 200 0 predicts an av erage of mean and standard deviation relative errors equal to 9 × 10 − 4 and 4 × 10 − 4 , respectiv ely . In figure 4, the accuracy o f the separated represen tation mo del is compared to regression and MC approac hes. It is sho wn tha t to g et the same accuracy the separated mo del ne eds few er samples b y one order of magnitude. The problem stat istics which are illustrated in figures 5. a and 5. b are compared to the regression results and the reference v alues. Up to this p oint, an accurate surroga t e separated represen tation mo del to approximate the solution of the equation (32) ha s b een pro vided and v ali- 18 10 2 10 3 10 4 10 5 10 −4 10 −3 10 −2 10 −1 Number of samples (N) Average of relative error in standard deviation 10 2 10 3 10 4 10 5 10 −4 10 −3 10 −2 Number of samples (N) Average of relative error in mean (a) (b) Figure 4: Comparison o f the average rela tiv e er rors in standard deviation and mean of the solution for the separated repres en tation, reg ression and Monte Carlo: (a) Relative standard deviation err or; (b) Relative mea n er ror (Separa ted repr esentation ( − − − ); Regressio n ( ◦ − − − ); Mont e Carlo ( ) ) 0 0.2 0.4 0.6 0.8 1 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 0.09 Spatial coordinate ( ξ ) Mean 0 0.2 0.4 0.6 0.8 1 4 5 6 7 8 9 10 11 12 x 10 −3 Spatial coordinate ( ξ ) Standard Deviation (a) (b) Figure 5 : Statistics of the elliptic PDE solution a s a function of s patial v a riable ( ξ ) (a) Mean; (b) Standard deviation; (Es tima ted based on: Separa ted repres e ntation with: N = 1000 ( . . . . . . ) a nd N = 20 0 0 ( − − − ); Re g ression with N = 25000 ( ◦ − − − ); Monte Carlo with N = 25 000 ( ) . 19 dated. In the followin g, it will b e s how n ho w this surrogate mo del can b e used in in v erse problems. Ba sed o n the true v alue of diffusion co efficien t κ , equa- tion (32) is solv ed to obta in t he exact v alue of the solution, u exact . The true κ is obtained b y generating uniform indep enden t random v ar ia bles, { y i } d i =1 , and computing equation (3 3). In the inv erse problem con text, one needs noisy observ ations, e.g., exp erimen tal results. T o do so, an i.i.d standard normal noise vec tor is added to the exact solutio n, i.e., u noisy = u exact + ε , where ε j ∼ N (0 , σ noise ) , j = 1 , . . . , n . Here, one case where σ noise = 0 . 05 and n = 20 is considered for the 41-dimensional elliptic PDE (32). T o decrease the computational cost of re- p eated ev aluation of the forward mo del in Ba y esian inference approac hes, the separated represen tation surrogate mo del is used to approximate t he elliptic PDE solution, u . The results are sho wn in figures 6. a and 6. b . Figure 6. a illustrates the diffusion co efficien ts based on the p osterior realizations com- puted by DRAM [2 5]. Regarding the prior infor mation, the KL mo des in equation (33) are uniformly distributed; ho wev er, a Gaussian prior distribu- tion with pr ior mean and pr ior std is considered and transformed t o uniform distribution on [ − 1 , 1] b y y = er f ( θ − pr ior mean ) / √ 2 × pr ior std ∼ U ( − 1 , 1) . (36) Here, θ is a normal random v ariable θ ∼ N ( pr ior mean , pr ior std ) and er f is the error function. F igure (6. a ) show s the results of inv erse mo delling for three cases with prior Ga ussian distributions a nd the same pr ior mean , but differen t pr ior std . The pr ior mean v alue is approximated b y the metho d described in [37], whic h minimizes the square ro ot of the differences b etw een the appro ximation and the exact v alue of the solution. The prio r standard deviations are equal to { 0 . 3 , 0 . 6 , 1 } . The solid line represen ts the true v alue of the diffusion co efficien ts used t o generate the da t a and t he remaining lines represen t the DRAM sim ulations with v arious prior standard deviations. The results are obtained using 10 6 DRAM samples, disregarding 2 . 5 × 10 5 of them as burn-in samples. As exp ected, due to the ill-conditioning of the problem the non-smo oth part o f the diffusion field is not easy to reconstruct. Ho w ev er, by decreasing the prior- standar d deviation, whic h defines more narro w er b ound around the pr ior mean for the realizations, more features of the diffusion field can b e captured. Figure 6. b illus trates a b oxplot of KL mo de weigh ts superimp osed with the p osterior mean of realizatio ns obtained with DRAM. In eac h b oxplot a cen tr a l 20 0 0.2 0.4 0.6 0.8 1 0.5 1 1.5 2 2.5 3 Spatial coordinate ( ξ ) Diffusion coeficient ( κ ) −5 0 5 1 2 3 4 5 6 7 8 9 1011 1213 1415 1617 1819 2021 2223 2425 2627 2829 3031 3233 3435 3637 3839 40 KL modes KL weights MCMC Truth (a) (b) Figure 6: MCMC r esults for one-dimensio na l elliptic PDE. (a) Diffusion co efficient o b- tained with p osterio r realizatio ns vs. the spatial v ar iable. ( σ p = 0 . 3 ( . − . − . − ), σ p = 0 . 6 ( − − − ), σ p = 1 ( . . . ), and truth (so lid line). (b) P oster ior b oxplot obtained with the MCMC. (Posterior mean ( ) and the true v alue of KL w eights ( ◦ ). b o x r epresen ts the cen ter (50%) of the p osterior, a cen tra l line indicates the median, upp er and low er lines represen t the 25% and 75% quan tile of the p osterior, and t w o v ertical lines, or whisk ers indicate the en tire range of the p osterior outside the cen tral b o x. The exact v alue of the r ealizations whic h w ere used to generate the data are also sho wn in this figure. It is sho wn in the figure 6. b that the lo w er mo des are a ppro ximated more accurately than the higher mo des. Because the elliptic op erator in equation (32) smo ot hs the higher index-mo des and conseque ntly they ar e rougher and more difficult to rev eal by MCMC than the low er index-mo des. 5.3. Ca v ity Flow T o inv estigate the p erformance of the algorithm in a more c hallenging problem, a square 2D in space cavit y flo w is considered, whic h is filled with a Newtonian fluid of densit y ρ c , molecular viscosit y µ c , and thermal con- ductivit y κ c . The righ t and left ve rtical walls are main t a ined at T h and T c temp erature, resp ectiv ely , where T h > T c . The tw o horizon tal w alls are assumed to b e adiabatic. F urthermore, the reference temp erature and the temp erature difference are defined as: T r ef = ( T h + T c ) / 2 , (37) 21 and ∆ T r ef = T h − T c , (38) where the tw o temp erature b oundary conditions are T h = − T c = − 1 / 2. Using the Boussinesq appro ximation the normalized g o v erning equations can b e derive d as follo ws: ∂ u ∂ t + u · ∇ u = −∇ p + P r √ Ra ∇ 2 u + P r T y , (39) ∇ · u = 0 , (40) ∂ T ∂ t + ∇ · ( u T ) = 1 √ Ra ∇ 2 T , (41) where u is v elo cit y , t is t ime, p is pressure, and T is normalized temp erature suc h that T ≡ ( T − T r ef ) /T r ef . The P r and Ra are Prandtl and Ra yleigh n um b ers, whic h are equal to 0.71 and 10 6 , resp ectiv ely , whic h v alues lead to a steady laminar circulating flow. The equations are discretized on a 1000 × 1000 grid. The temp erature on the cold w all ( ξ 1 = 1) is expressed as: T ( ξ 1 = 1 , ξ 2 ) = T c + T ′ ( ξ 2 ) . (42) The mean temp erature along the cold w all, h T ( ξ 1 = 1 , ξ 2 ) i , is assumed to b e indep enden t of ξ 2 and equal to T c = − 0 . 5. Here, the effect of the cold wall temp erature fluctuations T ′ ( ξ 2 ) on the temp erature field is studied. Thes e fluctuations are appro ximated by a tr uncated K L expansion with d = 20 terms as follo ws: T ′ ( ξ 2 ) = d X i =1 p λ i φ i ( ξ 2 ) y i ( w ) , (43) where { y i } d i =1 are indep enden t input random v a riables with Gaussian distri- butions. λ i , the eigen v alues, are computed b y λ i = σ 2 c 2 L c 1 + ( ω i L c ) 2 , (44) in whic h ω i are p ositiv e ro o t s of the c ha r a cteristic equation [1 − L c ω i tan( ω i / 2)] [ L c ω i + tan( ω i / 2)] = 0 . (45) 22 The L c and σ c are 1 / 21 and 11 / 100, resp ectiv ely . In equation (43), φ i are eigenfunctions which are giv en b y φ i ( ξ 2 ) = cos[ ω i ( ξ 2 − 0 . 5)] r 0 . 5+ sin ( ω i ) 2 ω i sin[ ω i ( ξ 2 − 0 . 5)] r 0 . 5 − sin ( ω i ) 2 ω i . (46) The solv er is pro vided in FEniCS based on finite elemen t algorit hm and decoupling the go v erning equations and it ran 10 , 000 times part ia lly on t he Jan us supercomputer at UC Bo ulder. In figure 7, the temp erature con tours for the 2D-cavit y flo w are show n, in whic h t wo v ectors with size n = 20 of temp erature on v ertical line ξ 1 = 0 . 5 and ho rizon ta l line ξ 2 = 0 . 5 are con- sidered for separated represen ta tion appro ximation. The separated represen- tation mo dels w ere constructed following algorithm 1. Figure 8 illustrates the optimal separated rank and p olynomial degree fo r a set of num b ers of samples { 300 , 600 , 100 0 , 200 0 } . It can b e observ ed that the separation ranks of the separated mo dels are smaller than 10 , whic h lead to successfully ap- pro ximate the function with lo w -r ank separated mo dels. The separated rep- resen tatio n complexities are sampling based and v ary for differen t num b ers of samples. F ig ures 9.a and 9.b compare the con v ergence of the a v erage of standard deviation and mean of the scaled temp erature o n the t w o lines ξ 1 = 0 . 5 and ξ 2 = 0 . 5 o bta ined by separated represen tat ion, p olynomial c haos expansion regression [15], and the standard Mon te Carlo sim ulat io n. As the separated represen tation mo del construction is based on random sampling of the solution, the higher a ccuracy in the approximations may b e ac hieve d by incorp orating more samples, while in the PC regression the solution a ccuracy ma y not improv e by incorpo rating larger num b ers of samples. Additionally , the con v ergence rate of the separated represen tation is faster than the PC regression. T o appro ximate the t emp erature and its standard deviation and mean v alues on b oth lines ξ 1 = 0 . 5 a nd ξ 2 = 0 . 5, the separated represen tat io n mo del whic h is constructed with N = 2000 samples is used. Figure 10 compares the appro ximations of the separated represen tation mo del with the standard Mon te Carlo metho d. Figures 10.a and 10.b illustrate the mean v alues and figures 10.c a nd 10.d illustrate the standard deviation v alues. The av erage of relative errors in standard deviation and mean on the line ξ 1 = 0 . 5 a re { 0 . 008 , 0 . 000 59 } and corresp onding v a lues for the line ξ 2 = 23 ξ 1 ξ 2 Scaled Temperature Field 0.0 0.5 1.0 1 0.5 0.0 −0.5 0 0.5 Figure 7 : Scaled temper ature field of a square 2 D cavit y flow and a ssigned vertical line ξ 1 = 0 . 5 ( . − . − . − ) and horizo n tal line ξ 2 = 0 . 5 ( − − − ) for s eparated r epresentation approximations. 10 2 10 3 10 4 1 2 3 4 5 6 7 8 9 10 Separation rank (r) Number of samples (N) 10 2 10 3 10 4 1 2 3 4 5 6 7 Polynomial degree (M) 10 2 10 3 10 4 1 2 3 4 5 6 7 8 9 10 Separation rank (r) Number of samples (N) 10 2 10 3 10 4 1 2 3 4 5 6 7 Polynomial degree (M) (a) (b) Figure 8: Optimal v alues of sepa ration ra nk r and spectral polyno mial degr ee M obtained by following alg orithm 1 fo r the lines : (a) ξ 1 = 0 . 5 and (b) ξ 2 = 0 . 5. (Separation rank r ( ); Polynomial degree M ( ◦ )). 24 10 2 10 3 10 4 10 −3 10 −2 10 −1 Number of samples (N) Average of relative error in standard deviation 10 2 10 3 10 4 10 −3 10 −2 10 −1 Number of samples N Average of relative error in mean × 10 −1 (a) (b) Figure 9: Comparison o f the average of rela tiv e e r rors in standard deviation and mean for the separ ated representation, Regressio n, and Mon te Carlo simulation (Line ξ 1 = 0 . 5 ( ); Line ξ 2 = 0 . 5 ( − − − )). (a) Average of relative erro r in standar d devia tion a nd (b) Av erag e of relative error in mean. (Separated repres e n tation ( ); PC regres sion ( ◦ ); Monte Carlo ( ⋄ )). 0 . 5 are { 0 . 009 , 0 . 000 4 2 } , which sho w the out p erformance of the separated represen tation approximation. Here, the analysis is fo cused on the p osterior distributions of KL mo de w eights in estimating the temp erature fluctuations on the cold w a ll. In in- v erse mo delling, Gaussian prior distributions with a prior mean computed b y the metho d in [37] and prior standard deviations { 0 . 3 , 0 . 6 , 1 } are a ssume d, where the results are sho wn in figure 11.a. The solid line r epresen ts the exact v a lue o f the fluctuations used to generate data b efore adding the ob- serv a tional noise term, and the rest of the lines represen t the fluctuations computed b y eq (43) with the mean of the MCMC c hains for { y i } d =20 i =1 . The MCMC results with differen t prior standard deviations w ere obt a ined using a DRAM with 10 6 samples, discarding the first 2 . 5 × 10 5 as burn-in samples. It can b e seen that b y decreasing the prior standard deviation, whic h restricts the sampling space around the prior mean and ma y lead to selecting mor e accurate samples, more f eatures of the temp erature fluctuations can b e cap- tured. In fig ure 11.b a b oxplot of the exact v a lues of the KL mo de w eigh ts is illustrated, sup erimp osed with the p osterior mean of the MCMC c hain. It is sho wn that the mo de we ights from lo wer indices to higher indices are iden tified accurately , a nd the exact v alues and MCMC means agree reason- 25 0 0.2 0.4 0.6 0.8 1 −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 0.4 Spatial coordinate ( ξ 2 ) Mean 0 0.2 0.4 0.6 0.8 1 −0.2 −0.15 −0.1 −0.05 0 0.05 0.1 0.15 Spatial coordinate ( ξ 1 ) Mean (a) (b) 0 0.2 0.4 0.6 0.8 1 0.005 0.01 0.015 0.02 0.025 0.03 0.035 0.04 Spatial coordinate ( ξ 2 ) Standard deviation 0 0.2 0.4 0.6 0.8 1 0.014 0.016 0.018 0.02 0.022 0.024 Spatial coordinate ( ξ 1 ) Standard deviation (c) (d) Figure 10: The v alues of the mean and standard devia tion of the scaled temp erature as a function of space. (a) Mean v alue on line ξ 1 = 0 . 5; (b) Mean v alue o n line ξ 2 = 0 . 5 (c) Standard deviation v alue on line ξ 1 = 0 . 5; (d) Standard deviation v a lue on line ξ 2 = 0 . 5. (Estimated with Mo n te Carlo ( N = 10 , 000) ( ♦ − − − ) and Separ ated r epresentation approximation ( N = 2000) ( − − − )). 26 0 0.2 0.4 0.6 0.8 1 −0.8 −0.7 −0.6 −0.5 −0.4 −0.3 −0.2 −0.1 Spatial coordinate ( ξ 2 ) Temperature fluctuation on the cold wall −3 −2 −1 0 1 2 3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 KL Modes KL weights MCMC Truth (a) (b) Figure 11: MCMC results for 2D cavity flow. (a) T emp erature fluctuations on the cold wall obtained with p oster io r realiz ations vs. the spatial v ariable. ( σ p = 0 . 3 ( . − . − . − ), σ p = 0 . 6 ( − − − ), σ p = 1 ( . . . ), and truth (so lid line). (b) Posterior b oxplot obtained with the MCMC. (P osterio r mean ( ) and the true v alue of K L w eights ( ◦ ). ably w ell. F or b etter illustration o f the metho d p erformance, in figure 12, the histograms of the MCMC c hain for { y i } d =20 i =1 are plotted. In this fig ur e the exact v alues of y i are sup erimp osed on the histogram of the p osterior samples. The densit y of v ariables generated b y MCMC coincides with the exact v alue of random v ariables. Eac h MCMC c hain takes approximately 2 4 hours with t w o 4-cores CPU and 12 G B RAM computer, how ev er in v erse mo delling using the phy sical mo del generally deemed to b e prohibitiv e. It is not claimed that this is the most efficien t in v erse mo delling approac h, ho w ev er, it is claimed that the separated represen tation surrogate mo del not only pro vides opp ort unities to do in v erse mo delling, but also it represen ts an out p erformance MCMC approac h. 6. C onclusion In this study , a surrog ate mo del has b een introduced non-in trusiv ely in the context of the lo w-rank separated represen tation, whic h mak es feasible the use of an in tractable Mark o v Chain Mon te Carlo (MCMC) sim ulation in Ba y esian inference for high-dimensional sto c hastic functions. In the sepa- rated represen tation a pproac h, a high- dimensional sto c hastic function is bro- k en do wn into a linear sum of unkno wn one-dimensional functions of ra ndom 27 −2 0 2 y1 −2 0 2 y2 −4 −2 0 y3 −4 −2 0 y4 −2 0 2 y5 0 2 4 y6 −2 0 2 y7 −2 0 2 y8 −5 0 5 y9 −5 0 5 y10 −4 −2 0 y11 −5 0 5 y12 −2 0 2 y13 −2 0 2 y14 −5 0 5 y15 −2 0 2 y16 −5 0 5 y17 −5 0 5 y18 −5 0 5 y19 −2 0 2 y20 Figure 1 2: The histogram of MCMC chain for 2 D cavit y flo w. (The true v alue of the realizations ( ◦ )) 28 inputs. Here, the separated mo del a pproximates a vec tor of a contin uous so- lution at discrete v a lues of a ph ysical v a riable. This ve ctor v alued separated mo del, whic h is an extension of previous work [15] for the scalar-v alued case, leads to a significan t reduction in the computational cost of the approxim a- tion b y an order of magnitude equal to the v ector size. Because the solution can b e appro ximated b y one v ector v alued separated mo del, while the solu- tion at eac h ph ysical v ariable m ust b e approxim ated separately with differen t scalar-v alued separated mo dels. An alternativ e least square regression-based approac h w as presen ted t o stably construct the separated mo dels. Also, the issue of instabilit y whic h ma y o ccur in regression-based approac hes w as tac kled using the Tikhono v regularization. The regularization is applied with a roughening matrix computing the gradien t of the solution, which leads to hav e more con trol ov er the solutions a nd p enalizing and smo othing the hig her or der p olynomials. In o r der to find a n adequate regularization parameter, Generalized Cross V alida tion (GCV) is adopted. F urthermore, a p erturbation-based error indicator has b een defined to find the optimal mo del complexities known as separation rank and p olynomial degree. These parameters are indep enden t from t he function dimensionality d , whic h migh t lead to a succes sful appro ximation with a num b er of randomly generated re- alizations of sto c hastic functions linearly depends on d . The computatio na l cost of the approx imation quadratically increases with respect to the function dimensionalit y whic h ma y o v ercome the issue of the curse of dimensionalit y , a b ottle-nec k for uncertain ty quantification of high-dimensional sto chas tic functions. It ha s b een sho wn n umerically that the lo w-rank separated r epresen- tation appro ximation mo del outp erforms the curren t tec hniques for high- dimensional approx imations. And also, using these surrogates particularly of high-dimensional sto c hastic functions, mak es computationally prohibitive in v erse problem analysis feasible with high accuracy . The p erformance of the approac h was examined with three problems, including an 1 1-dimensional man ufactured function, a 41- dimensional (1D in space) elliptic PDE, and a 21-dimensional (2D in space) ca vit y flow. Ov erall, the Ba y esian inference with a surrogate separated represen tatio n mo del pro ceeds with more relia- bilit y and efficiency than with a phy sical mo del. F or future works, the applications of low-rank separated represen tation appro ximations in sensitivit y analysis and function dimensionalit y reduction migh t b e attractive areas. 29 Ac kno wledgemen t s This w o rk utilized the Jan us sup ercomputer, whic h is supp orted by the National Science F oundation (a w ard n um b er CNS-0821 794) and t he Unive r- sit y of Colorado Boulder. The Jan us supercomputer is a joint effort of the Univ ersity of Colorado Boulder, the Univ ersit y of Color ado Denv er and the National Cen ter for A tmospheric Research . References [1] E. Acar, T.G. Kolda, and D.M. Dunla vy . An optimization approach for fitting canonical tensor decomp o sitions. T ec hnical report , Sandia National Lab oratories, SAND2 0 09-0857, Liv ermore CA, 200 9. [2] A. Ammar, B. Mokdad, F. Chinesta, and R. Keunings. A new family of solv ers for some classe s o f m ultidimensional partial differen tial equations encoun tered in kinetic theory mo deling of complex fluids. Journal of Non-Newtonian F l uid Me chanics , 139(3):153 – 176, 200 6 . [3] R. C. Aster, B. Borche rs, and C. H. Th urb er. p a r ameter estimation and inverse pr oblem s . Elsevier Academic Press, 2005. [4] T. Bay es and R. Price. An essa y tow ards solving a problem in the do c- trine of c hance. b y the late rev. mr. bay es, comm unicated b y mr. price, in a letter to john canton, m. a. a nd f. r. s. T ec hnical Rep ort 53, Philo- sophical T ransactions of the Roy al So ciet y of London, Jan uary 1763. [5] A. Beck and M. T eb oulle. A fast iterat iv e shrink age-threshold algorit hm for linear in v erse problems. SIAM J. Imaging Scien c es , 2:183 – 202, 2009 . [6] J. M. Bernardo and A. F. M. Smith. Bayesian The ory . Wiley , 1994 . [7] G. Beylkin, J. Garc k e, and M. J. Mohlenk amp. Multiv a r iate regression and mac hine learning with sums o f separable functions. SIAM Journal on Scien tific Computing , 31(3) :1840–1857, 2009. [8] G. Beylkin and M.J. Mohlenk amp. Numerical op erator calculus in higher dimensions. Pr o c e e dings of the National A c ademy of Scienc e , 9 9:10246– 10251, 2002. 30 [9] G. Beylkin and M.J. Mohlenk amp. Algo rithms for n umerical analysis in high dimensions. SIAM Journal on Scientific Computing , 26(6):213 3 – 2159, 2 005. [10] A. Bjrc k. Numeric al metho ds for le ast squar es pr oblems . 1996 . [11] P . Br´ emaud. Markov Chains, Gibb s Fi e lds, Monte Carlo Simulation, and Queues . Springer, 1999. [12] P . Constan tine, Q. W ang, A. Do ostan, and G . Iaccarino. A surrogate accelerated bay esian in v erse analysis of the HyShot I I fligh t data. In AIAA-2011-2037 , 2011. [13] I. D a ub ec hies, M. Defrise, and C. De Mol. An iterativ e thresholding algorithm for linear in v erse problems with a sparsit y constrain t. Com- munic ations on Pur e and Applie d Mathematics , 57(11):1413– 1457, 2004. [14] A. Do ostan, R. G hanem, a nd J. Red-Horse. Sto c ha stic mo del reduction for c haos represen tations. Com puter Metho d s in Applie d Me chan ics and Engine ering , 196(37-4 0 ):3951–3966 , 2 007. [15] A. D o ostan, A. V alidi, and G . Iaccarino. Non-intrusiv e lo w-rank sep- arated approx imation of high-dimensional sto chastic mo dels. Com- puter Metho ds in Applie d Me chanics and Engine e ring , 201 3, doi: h ttp://dx.doi.org/ 10.1016 / j.cma.2013.04.003. [16] S. E. Fien b erg. When did bay esian inference b ecome “bay esian”? Bayesian Analysis , 1:1–40, 2006. [17] R. F uruk aw a, H. Ka w asaki, K. Ik euc hi, and M. Sak auchi. App earance based ob ject mo deling using texture database: acquisition, compres- sion and rendering. In EGR W 02: Pr o c e e din gs of the 13th Eur o gr aphics workshop on R endering, A ir e-la-Vil le, Switzerland, Switzerland , pag es 257–266, 2 0 01. [18] A. G elman, J.B. Carlin, H.S. Stern, and D.B. Rubin. Bayesian D a ta A nalysis, 2nd Edition . Chapman & Hall, Bo ca Rat on, 200 3. [19] J. Gew ek e. Ba y esian inference i n econometric mo dels using mon te carlo in tegration. Ec onome tric a , 57:131 7 –1339, 1989. 31 [20] J. Gew ek e. Ba y esian inference i n econometric mo dels using mon te carlo in tegration. Ec onome tric a , 57:131 7 –1339, 1989. [21] W. R. Gilks, S. Ric hardson, and D. J. Spiegelhalter. Markov chain Monte-Carlo in p r atic e . 1 9 96. [22] P . Green a nd A. Mira. Delay ed r ejection in rev ersible jump metrop olis- hastings. Biometrika , 88:1 035–1053, 2001. [23] C. G ro etsc h. In verse pr oblems in the mathematic al scienc es . 1993. [24] H. Haario, M. Laine, a nd E. Saksman M. Leh tinen, and J. T amminen. Mon te carlo methods for high dimensional in v ersion in remote sensing. J. R. S tatist. So c. B , 66:591–60 8 , 2004 . [25] H. Haario, M. Laine, A. Mira, and E. Saksman. DRAM: Efficien t adap- tiv e MCMC. Statistics an d Computing , 16:3 3 9–354, 2006. [26] H. Haario, E. Saksman, and J. T amminen. Adaptiv e prop osal distribu- tion for random w alk metrop o lis algorithm. Com p . Stat. , 14 :375–393, 1999. [27] H. Haario , E. Saksman, and J. T amminen. An Ada ptive Metrop olis algorithm. Bernoul li , 7:223 –242, 2001. [28] W. Hack busc h and B. N. Khoro mskij. Kroneck er tensor-pro duct ap- pro ximation to certain matrix-v alued functions in higher dimensions . T ec hnical Rep ort Preprin t 16, Max-Planc k-Institut f ¨ ur Mathematik in den Naturwissens c haften, 2004. [29] P . C. Hansen. Discr ete Inverse Pr oblem s Insight and A lgorithms . SIAM, 2010. [30] D. Higdon and C. Holloman. Marko v c hain Mon te Carlo-based ap- proac hes for inference in computationa lly intens iv e inv erse problems. [31] F.L. Hitch co ck . The expression of a tensor or a p oly adic as a sum of pro ducts. Journal of Mathematics and Physics , 6:16 4–189, 1927. [32] T. Jaakk ola and M. Jordan. Bay esian parameter estimation via v a r ia- tional metho ds. Statistics a n d Computing , 10:25 –37, 2000. 32 [33] J. Kaipio and E. Somersalo. Statistic al and Computational I nverse Pr ob- lems . Springer, 2004. [34] A. Kirsc h. An in tro duction to the mathematical theory of inv erse prob- lems. App l i e d Mathematic al Scienc es , 120, 96. [35] T. G. Kolda and B. W. Ba der. T ensor decomp ositions and applications. SIAM R eview , 51(3):45 5 –500, 2009. [36] P . Kro onen b erg and J. Leeu w. Principal comp onen t analysis of three- mo de data b y means of alternating least squares algorithms. Psychome- trika , 4 5(1):69–97, March 1980. [37] J. C. Lagarias, J. A. Reeds, M. H. W righ ts, and P . E. W righ t . Con v er- gence prop erties of the nelder-mead simplex method in lo w dimensions. SIAM J. O ptim. , 9:112– 1 47, 1998. [38] X. Ma and N. Zabaras. An efficien t ba ye sian inference appro ac h to in v erse pr o blems based on an a daptiv e sparse grid collo cation metho d. Inverse Pr oble ms , 25:035 0 13, 2009. [39] O.P . Le Maitre and O. Knio. Sp e ctr al Metho ds for Unc ertainty Quantifi- c ation with Applic a tion s to C omputational Fluid Dynamics . Springer, 2010. [40] Y. M. Marzouk and H. N. Na jm. D imensionalit y reduction and p oly- nomial c haos acceleration o f ba y esian inference in in v erse problems. J. Comput. Phys. , 228:1862–19 0 2, 200 9. [41] Y. M. Marzouk and D. Xiu. A Sto c hastic Collo catio n Appro a c h to Ba y esian Inference in Inv erse Problems. Communic ations in Computa- tional Physics , 6:826–847, 2 0 09. [42] Y. M. Marzouk and D. Xiu. A sto chastic collo cation approac h to ba y esian inference in in v erse problems. Com munic ations In Compu- tational Physics , 6(4):826–847 , 2009. [43] I. McKeagueand, G. K. Nic holls, and K. Sp eer. Statistical in v ersion of south atlantic circulation in an ab yssal neutral densit y lay er. Journal o f Marine R ese ar ch , 6 3:683–704, 2005. 33 [44] N. Metrop olis, A. W. Ro sen bluth, M. N. Rosen bluth, A. H. T eller, and E. T eller. Equation of state calculations b y fast computing machine s. The Journal of Chemic al Physics , 21:1087– 1 092, 1 953. [45] I. Miller and M. Miller. Mathematic al Statistics with Applic ation . P ear- son, 20 0 4. [46] A. Mira. Ordering and improvin g the p erformance of mon te carlo mark o v c ha ins. B ernoul li , 16:340 –350, 2002. [47] V. A. Morozov. R e gularization Metho ds for Il l-Pose d Pr oblems . CR C, 1993. [48] T. Moselh y and Y. M. Marzouk. Ba y esian inference with optimal maps. A rxiv:1109 . 1 516v3 , 2 012. [49] C. R. Rao and H. T outen burg. Line a r Mo dels: L e ast Squar es and A lter- natives . 19 99. [50] A. Shash ua and A. Levin. Linear image co ding for regression and classi- fication using the tensor-rank principle. In CVPR 2001: Pr o c e e ding s of the 2001 IEEE Computer So ciety Confer enc e o n Co m puter Visi o n and Pattern R e c o gnition , pag es 42–49, 2001. [51] R. L. Smith. Efficien t mon te carlo procedures for generating p oints uniformly distributed ov er b ounded regions. Op er. R es. , 32:12 96–1308, 1984. [52] J. C. Spall. I ntr o duction to S to chastic Se ar ch and Optimiza tion, Esti- mation, Simulation and Contr ol . Wiley , 2010. [53] T. Stew art. Multiparameter univ ariate bay esian inference . J. A m er. Statist. Asso c. , 74:68 4–693, 1979. [54] A. T arantola. I nverse p r oblem the ory - and metho ds for m o del p ar ameter estimation . 20 05. [55] L. Tierney . Marko v c hains for exploring p osterior distributions. The A nnals of Statistics , 22 (4):1701–17 6 2, 1994. [56] J.A. T ropp and S.J. W righ t. Computational metho ds for sparse solution of linear in v erse problems. Pr o c e e dings of the IEEE , 20 10. in press. 34 [57] C. R. V ogel. Computational Metho ds for Inverse Pr o b l e ms . So ciety f or Industrial and Applied Mathematics, Philadelphia, P A, USA, 2002. [58] X. W an a nd G. Karnia da kis. An adaptive multi-elemen t generalized p olynomial c ha o s metho d for sto chastic differen tial equations. J. Comp. Phys. , 2 09:617–642, 2005. [59] Zellner a nd E. Rossi. Bay esian a nalysis of dic hotomous quan ta l respo nse mo dels. J. Ec onometrics , 25:365–393 , 1 984. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment