Improving CASA Runtime Performance by Exploiting Basic Feature Model Analysis
In Software Product Line Engineering (SPLE) families of systems are designed, rather than developing the individual systems independently. Combinatorial Interaction Testing has proven to be effective for testing in the context of SPLE, where a representative subset of products is chosen for testing in place of the complete family. Such a subset of products can be determined by computing a so called t-wise Covering Array (tCA), whose computation is NP-complete. Recently, reduction rules that exploit basic feature model analysis have been proposed that reduce the number of elements that need to be considered during the computation of tCAs for Software Product Lines (SPLs). We applied these rules to CASA, a simulated annealing algorithm for tCA generation for SPLs. We evaluated the adapted version of CASA using 133 publicly available feature models and could record on average a speedup of $61.8%$ of median execution time, while at the same time preserving the coverage of the generated array.
💡 Research Summary
Software Product Line Engineering (SPLE) requires testing not just a single system but an entire family of related products. Combinatorial Interaction Testing (CIT) addresses this challenge by selecting a representative subset of products that covers all t‑wise feature interactions; such a subset is formalized as a t‑wise covering array (tCA). However, generating a tCA for a constrained feature model (FM) is NP‑complete, and the search space grows explosively with the number of features and constraints.
The authors build on two reduction rules previously proposed for feature‑model‑based testing: (1) any t‑set that contains the root feature can be ignored, because any valid product must include the root; (2) any t‑set that contains a mandatory child feature can also be ignored, as any valid product containing that child must also contain its parent and thus automatically covers the root‑containing t‑set. Applying these rules reduces the set of t‑sets that must be explicitly covered from |FL|!/(|FL|‑t)!·2^t to (|FL|‑m)!/(|FL|‑m‑t)!·2^t, where m is the number of ignored features (root plus all mandatory children).
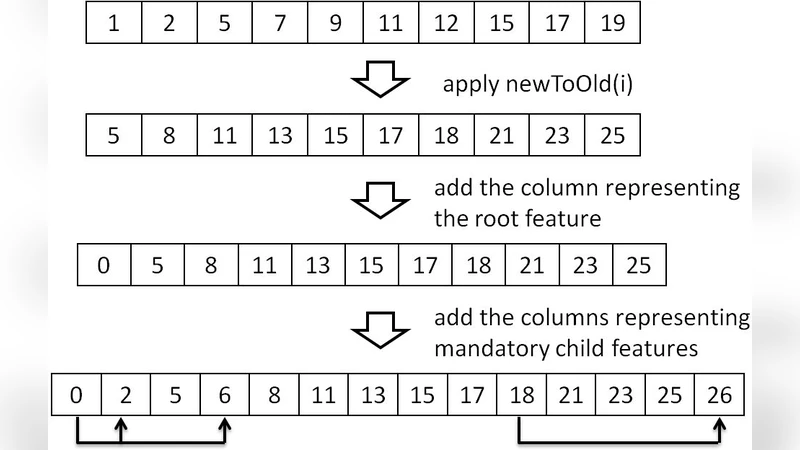
The paper integrates these reductions into CASA, a simulated‑annealing based tCA generator that is currently the only meta‑heuristic tool for SPLs. The integration proceeds by preprocessing the FM: the FM is converted to the OVM‑based CNF format required by CASA, then all ignored features are removed, shrinking the number of columns and the range of column values. After the annealing phase finishes, the resulting array is post‑processed to re‑insert the ignored features in their original positions, preserving the semantics of the original model.
The authors evaluate the modified CASA on 133 publicly available feature models from the SPLOT repository. For each model, both the original and the adapted CASA are executed 100 times, and median runtimes are compared. Statistical analysis (e.g., Wilcoxon signed‑rank test) confirms that the adapted version achieves a statistically significant reduction in runtime, with an average speed‑up of 61.8 % in median execution time. Importantly, the size of the generated tCAs and their coverage remain unchanged, demonstrating that the reduction rules improve efficiency without sacrificing solution quality.
Key contributions include: (i) a practical demonstration that simple structural reductions can dramatically accelerate a state‑of‑the‑art tCA generator; (ii) extensive empirical validation on a large, diverse benchmark set; and (iii) a clear pathway for applying the same reductions to other search‑based tCA generation techniques. The paper also outlines future work such as extending the approach to other meta‑heuristics (genetic algorithms, particle swarm optimization), handling more complex constraint families, and integrating the method into continuous testing pipelines. Overall, the study provides strong evidence that exploiting basic feature‑model properties is an effective strategy for scaling combinatorial testing in SPLE environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment