Cross-Domain Sparse Coding
Sparse coding has shown its power as an effective data representation method. However, up to now, all the sparse coding approaches are limited within the single domain learning problem. In this paper, we extend the sparse coding to cross domain learn…
Authors: Jim Jing-Yan Wang
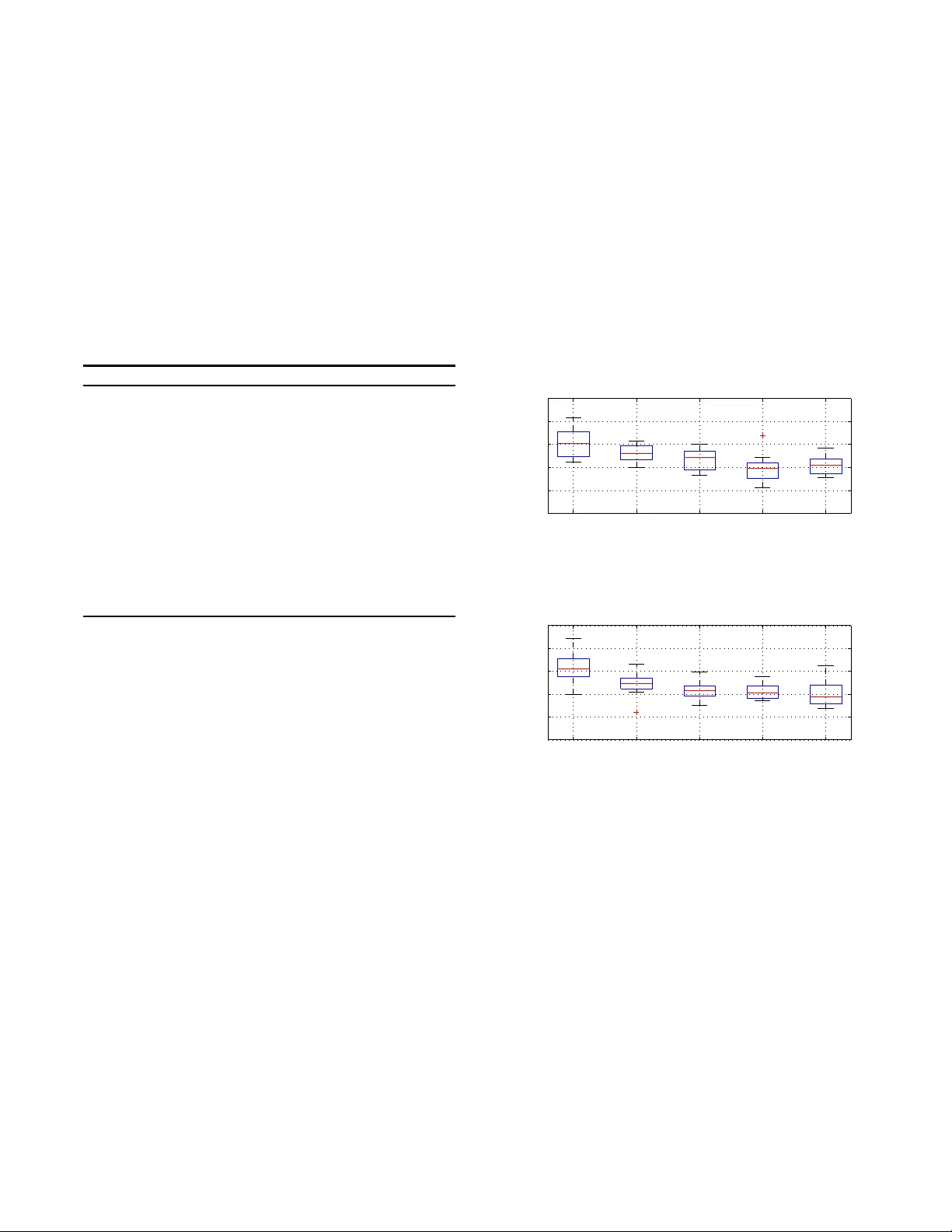
Cr oss-Domain Spars e Coding Jim Jing-Y an W ang 1 , 2 1 Unive rsity at Buffalo , The State University of Ne w Y ork, Buffalo , NY 14203, USA 2 National K ey Laborato r y for No vel S oftware T echnology , Nanjing Unive rsity , Nanji ng 210023, China jimjywang @gmail.com ABSTRA CT Sparse codin g has show n its p o wer a s an effective data rep- resen tation method. How ever, up to no w, all the sparse cod - ing approac hes are limited wi thin the single domain learning problem. In this pap er, w e extend the sparse cod in g t o cross domain learning problem, which tries to learn from a source domain to a target domai n with significant differen t distribu- tion. W e imp ose the Maximum Mean Discrepancy (MMD) criterion to redu ce th e cross-domain distribution difference of sparse co des, and also regularize the sparse co des by the class lab els of the samples from b oth domains to increase the discriminativ e abilit y . The encouragi ng exp erimen t results of the proposed cross-domain sparse co d ing alg orithm on tw o chall enging tasks — image classification of photograph and oil painting domains, and multiple user spam detection — show t h e adv antage of the prop osed metho d o ver other cross-domain d ata representation metho ds. Categories and Subject Descriptors I.2.6 [ AR TIFICIAL INTELLIGENCE ]: Learning Keyw ords Cross-Domain Learning; Sparse Coding; Maximum Mea n Discrepancy 1. INTR ODUCTION T raditional ma chine l earning metho ds usually assume that there are sufficient t raining sa mples to train the classifier. How ever, in many real-w orld app licatio ns, t h e num b er of labeled samples are alwa y s limited, making the learned clas- sifier not robust enough. Recently , cross-domain learning has been proposed to solve this problem [2], by borrow ing labeled samples from a so called “source domain” for the learning p roblem of th e “target domain” in h and. The sam- ples from these tw o domains hav e different d istributions but are related, and share th e same class lab el and feature space. Tw o t yp es of domain transfer learning metho ds hav e b een Permission to make digital or hard copies of all or part of this work for personal or classroom us e is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full cita- tion on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. T o copy otherwise, or re- publish, to pos t on servers or to redistribute to lis ts, requires prior s pecific permission and/or a fee. Request permissions from permissions@acm. or g. Copyright 20XX ACM X-XXXXX-XX-X/XX/XX ...$15.00. studied: classifie r tr ansfer metho d which learns a classi- fier for the target domain by t he target d omain samples with help of the source domain samples, while cross domain data represent ation tries to map all the samples from b oth source and target domains t o a data representation space with a common distribution across domains, whic h could b e used t o train a single d omain classifier for t he target domain [2, 5, 8, 9]. In this pap er, we fo cus on the cross do- main rep resen tation p roblem. Some w orks hav e b een done in this field by v arious data representation metho ds. F or exam- ple, Blitzer et al. [2] proposed the structural corresp ondence learning (SCL) algorithm to indu ce corresp ondence among features from th e source and target domains, Daume I II [5] prop osed the feature rep lication (FR) metho d to augmen t features for cross-domain learning. Pan et al. [8] prop osed transfer comp onent analysis (TCA) whic h learns transfer compon ents across d omains via Maximum Mean Discrep- ancy (MMD) [3], and extended it to semi-sup ervised TCA (SSTCA) [9]. Recently , sparse coding has attracted man y attention as an effective d ata representation metho d, w hich represen t a data sample as the sparse linear combinatio n of some code- w ords in a cod ebo ok [7]. Most of th e sparse coding algo- rithms are unsup ervised, due to the small num b er of la- b eled samples. Some semi-supervised sparse coding meth- ods are proposed to utilize the labeled samples and signif- ican t p erformance improv ement has b een rep orted [4]. In this case, it would b e very interesting to inv estigate the use of cross-domain represen tation to p rovide more a v ailable la- b eled samples from t he source domain. T o our kno wledge, no work has b een done u sing the sparse coding meth od to solv e the cross-domain problem T o fill in t h is gap, in this p a- p er, we prop ose a no vel cross-domain sparse cod ing method to combine the adva ntages of b oth sparse co ding and cross- domain learning. T o this end, we will try to learn a common codeb o ok for the sparse codin g of the samples from b oth the s ource and target domains. T o utilize the class lab els, a semi -sup ervised regulariza tion will also b e in trod uced to the sparse codes. Moreov er, t o reduce the mismatch b etw een the distributions of the sparse co des of the source and target samples, w e adapt t h e MMD rule to sparse co des. The remaining of this pap er is organized as follo ws: In Section 2 , we will introd uce the formulatio ns of th e pro- p osed Cross-Domain Sparse coding (CroDomSc), and its im- plementatio ns. Section 3 reports exp erimental results, and Section 4 concludes the pap er. 2. CR OSS-DOMAIN SP ARSE C ODING In t his section, w e will introdu ce the p roposed CroDomSc metho d . 2.1 Objecti ve function W e denote the t raining dataset with N samples as D = { x i } N i =1 ∈ R D , where N is the num b er of data samples, x i is the feature vector of the i -th sample, an d D is the feature dimensionalit y . It is also organized as a matrix X = [ x 1 , · · · , x N ] ∈ R D × N . The training set is comp osed of the source domain set D S and target domain set D T , i.e., D = D S S D T . W e also denote N D and N T as the num b er of samples in source and target domain set separativel y . All the samples from the source d omain set D S are l ab eled, while only a few samples from the target domain D T are lab eled. F or each labeled sample x i , w e d enote its class lab el as y i ∈ C , where C is the class lab el space. T o construct th e ob jective function, w e consider the follow ing three p rob lems: Sparse Co ding Problem Given a sample x i ∈ D and a codeb o ok matrix U = [ u 1 , · · · , u K ] ∈ R D × K , where the k -th column is the k -th cod ew ord and K is the num b er of codewords in the co deb ook, sparse coding tries to reconstruct x by the linear reconstruction of the co dew ords in the codeb o ok as x i ≈ P K k =1 v ki u k = U v i , where v i = [ v 1 i , · · · , v K i ] ⊤ ∈ R K is the recon- struction coefficient vector for x i , which should b e as sparse as possible, thus v i is also called sparse code. The problem of sparse co ding can b e formulated as follo ws: min U,V X i : x i ∈D k x i − U v i k 2 2 + α k v i k 1 = k X − U V k 2 2 + α X i : x i ∈D k v i k 1 s.t. k u k k ≤ c, k = 1 , · · · , K (1) where V = [ v 1 , · · · , v N ] ∈ R K × N is the sparse co de matrix, with its i -th collum the sparse co d e of i -th sample. Semi-Sup ervised Sparse Co ding Re gul arization In th e sparse code space, th e in tra-class v ariance should b e minimized while the inter-cla ss va riance should b e max- imized for all th e samples labeled, from b oth t arget and source domains. W e fi rst define the semi-sup ervised regularization matrix as W = [ W ij ] ∈ { +1 , − 1 , 0 } N × N , where W ij = +1 , if y i = y j , − 1 , if y i 6 = y j , 0 , if y i or y j is unk own. (2) W e defi ne the degree of x i as d i = P j : x j ∈D W ij , D = diag ( d 1 , · · · , d N ), and L = D − W as the is the Lapla- cian matrix. Then we formulate the semi-sup ervised regularization p roblem as the follo wing problem: min V X i,j : x i , x j ∈D k v i − v j k 2 2 W ij = tr [ V ( D − W ) V ⊤ ] = tr ( V LV ⊤ ) (3) In this w a y , the l 2 norm distance b etw een sparse co des of intra -class pair ( W ij = 1) will b e minimized, while inter-cla ss pair ( W ij = − 1) maximized. Reducing Mismatch of Sparse Code Di s tribution T o reduce the mismatch of the d istributions of th e source domain and target domain in the sparse co d e space, w e ad opt the MMD [3] as a criteri on, whic h is based on the minimization of the d istance b etw een the means of codes from tw o domains. The problem of redu cing the mismatc h of the sparse cod e distribution b etw een source and target domains could b e formatted as fol- lo ws, min V 1 N S P i : x i ∈D S v i − 1 N T P j : x j ∈D T v j 2 = k V π k 2 2 = T r [ V π π ⊤ V ⊤ ] = T r ( V Π V ⊤ ) (4) where π = [ π 1 , · · · , π N ] ⊤ ∈ R N with π i the domain indicator of i -th sample defined as π i = ( 1 N S , x i ∈ D S , − 1 N T , x i ∈ D T . (5) and Π = π π ⊤ . By summarizing the formulations in (1), (3) and (4), t he CroDomSc problem is mo deled as the follo wing optimization problem: min U,V k X − U V k 2 2 + β T r [ V LV ⊤ ] + γ T r [ V Π V ⊤ ] + α X i : x i ∈D k v i k 1 = k X − U V k 2 2 + T r [ V E V ⊤ ] + α X i : x i ∈D k v i k 1 s.t. k u k k ≤ c, k = 1 , · · · , K (6) where E = ( β L + γ Π). 2.2 Optimization Since direct optimization of (6) is difficult, an iterativ e, tw o-step strategy is used to optimize the cod ebo ok U and sparse co des V alternately while fixing the oth er one. 2.2.1 On optimizing V by fixing U By fixing the co debo ok U , the optimization problem (6) is redu ced to min V k X − U V k 2 2 + T r [ V E V ⊤ ] + α X i : x i ∈D k v i k 1 (7) Since the reconstruction error term can b e rewritten as k X − U V k 2 2 = P i : x i ∈D k x i − U v i k 2 2 , and th e sparse code regularization term could b e rewritten as T r [ V E V ⊤ ] = P i,j : x i , x j ∈D E ij v ⊤ i v j , (7) could b e rewritten as: min V X i : x i ∈D k x i − U v i k 2 2 + X i,j : x i , x j ∈D E ij v ⊤ i v j + α X i : x i ∈D k v i k 1 (8) When up dating v i for any x i ∈ D , th e other codes v j ( j 6 = i ) for x j ∈ D , j 6 = i are fixed . Thus, we get the follow ing optimization prob lem: min v i k x i − U v i k 2 2 + E ii v ⊤ i v i + v ⊤ i f i + α k v i k 1 (9) with f i = 2 P j : x j ∈D ,j 6 = i E ii v j . The ob jective function in (9) could b e optimized efficiently by the modified feature-sign searc h algorithm prop osed in [10]. 2.2.2 On optimizing U by fixing V By fix ing the sparse co des V an d removing irrelev ant terms, the opt imization p roblem (6) is red uced to min U k X − U V k 2 2 s.t. k u k k 2 2 ≤ c, k = 1 , · · · , K (10) The p roblem is a least square problem with quadratic con- strain ts, and it can b e solv ed in the same wa y as [7]. 2.3 Algorithm The p roposed Cross Domai n Sparse co ding algor ithm, named as CroDomSc , is summarized in A lgorithm 1. W e hav e applied the original sparse coding method s to the sam- ples from b oth the source and target domains for initializa- tion. Algorithm 1 CroDom-Ss Algorithm INPUT : T raining sample set from b oth source and target sets D = D S S D T ; Initialize the co deb ooks U 0 and sparse co des V 0 for sam- ples in D by using single domain sp arse co ding. for t = 1 , · · · , T do for i : x i ∈ D do Up date the sp arse co de v t i for x i by fixing U t − 1 and other sparse co des v t − 1 j for x j ∈ D , j 6 = i by solving (9). end for Up date the co deb o ok U t by fixing the sparse co d e ma- trix V t by solving ( 10). end for OUTPUT : U T and V T . When a test sample from target domain comes, we simply solv e problem (9) to obtain its sparse co de. 3. EXPERIMENTS In the exp eriments , w e exp erimen t ally ev aluate th e pro- p osed cross domain data representation meth od, CroDomSc. 3.1 Experimen t I: Cr oss-Domain Image Clas - sification In the first exp erimen t, w e considered the problem of cross domain image cl assification of the ph otographs and the oil paintings , which are treated as tw o different domains. 3.1.1 Dataset and Setup W e collected an image d atabase of b oth photographs and oil paintings. The database contains totally 2,000 images of 20 seman t ical classes. There are 100 images in each class, and 50 of them are photographs, and the remaining 50 ones are oil paintings. W e extracted and concatenated the color, texture, shap e and bag-of-w ords h istogra m features as visual feature vector from each image. T o conduct the exp eriment, we use photograph domain and oil painting domain as source domain and target domain in turns. F or each target d omain, we randomly split it into training subset (600 images) and test subset (400 images), while 200 images from the training sub set are randomly se- lected as lab el samples and all the source domain samples are labeled. The random splits are rep eated for 1 0 times. W e first p erform the CroDomSc to the training set and u se the sparse co d es learned to train a semi-sup ervised SV M classifier [6]. Then the test samples will also b e represented as sparse co de and classified u sing the learned SV M. 3.1.2 Results W e compare our CroDomSc against severa l cross-Domain data representation metho ds: SSTCA [9], TCA [8], FR [5] and SCL [2]. The boxplots of the classification accuracies of the 10 splits using photograph and oil p ain t ing as target domains are rep orted in Figure 1. F rom Figure 1 we can see that the prop osed CroDomSc outp erforms the other four compet in g metho ds for b oth photograph and oil painting domains. It’s also interesting to notice th at the classification of the FR and SCI metho ds are p o or, at around 0.7. SSTCA and TCA seems b etter than FR and SC but are still not compet itive to CroDomSc. CroDomSc SSTCA TCA FR SCL 0.5 0.6 0.7 0.8 0.9 1 Target Domain: Photograph Accuracy (a) Photograph as target domain CroDomSc SSTCA TCA FR SCL 0.5 0.6 0.7 0.8 0.9 1 Target Domain: Oil Painting Accuracy (b) Oil p ain t ing as t arget domain Figure 1: The b oxplot of classification accuracies of 10 spli ts of CroDomSc and compared m ethods. 3.2 Experimen t II: Multiple User Spam Email Detection In the second experiment, w e wi ll ev aluate the prop osed cross-domain d ata representation metho d for the m ultiple user based spam email detection. 3.2.1 Dataset and Setup A email dataset with 15 in b o xes from 15 different users is used in this exp eriment [1]. There are 400 email samples in eac h inbox, and half of th em are spam and the other half non-spam. Due to the significan t differences of the email source among different users, the email set of different users could b e treated as different domains. T o condu ct the ex periment, w e randomly select tw o users’ inboxes as source and target domains. The target domai n will further b e split into test set (100 emails) and training set (300 emails, 100 of which lab eled, and 200 unlab eled). The source domain emails are all lab eled. The word o ccurrence frequency histogra m is extracted from each email as origi- nal feature vector. The CroDomSc algorithm was p erformed to learn the sparse co de o f both source and target d omain samples, whic h w ere used to train the semi-sup ervised clas- sifier. The target domain test samples were also represented as sparse cod es, which were classified u sing the learned clas- sifier. This selection will b e rep eated for 40 times to reduce the b ias of each selection. 3.2.2 Results Figure 2 shows the b o xplots of classification accuracies on th e spam detection task. A s we can observed from the figure, the prop osed CroDomSc alw ays outp erforms its com- p etitors. This is another solid evidence of the effectiveness of the sparse coding metho d for the cross-domain represen- tation problem. Mo reov er, SSTCA, whic h is also a semi- sup ervised cross-domain representation metho d, seems to outp erform other metho ds in some cases. How ever, the dif- ferences of its p erformances and oth er ones are not signifi- cant. CroDom−Sc SSTCA TCA FR SCL 0.7 0.8 0.9 1 ACC ACC Figure 2: The b o xplots of detection accuracies of 40 runs for spam dete ction task. 4. CONCLUSION In this paper, we introd uce the first sparse co ding algo- rithm for cross-domain data representa tion problem. T he sparse co de distribution differences b etw een source and tar- get domai ns are reduced b y regularizi ng sparse co des wi th MMD criterion. Moreo ver, the class labels of b oth source and target domain samples are ut ilized to encourage the dis- criminativ e abilit y . The developed cross-domain sparse co d- ing al gorithm is tested o n t w o cross-domain learning tas ks and th e effectiveness was shown. Acknowledgeme nts This work was supp orted by the National Key Lab oratory for Nov el Soft wa re T ec hnology , Nanjing U nive rsity (Grant No. KFKT2012B1 7). 5. REFERE NCES [1] S. Bic kel. ECML/PKDD Discov ery Challenge 2006, September 2006. [2] J. Blitzer, R. McDonald, and F. P ereira. Domain adaptation with structural corresp ondence learning. In 2006 Confer enc e on Em piric al M etho ds in Natur al L anguage Pr o c essing, Pr o c e e dings of the Confer enc e , pages 120 – 128, 2006. [3] K. M. Borgwa rdt, A . Gretton, M. J. Rasc h, H.-P . Kriegel, B. Schoelkopf, and A. J. S mola. Integrating structured biological data by Kernel Maximum Mean Discrepancy. Bi oinformatics , 22(14):E49– E57, JUL 2006. [4] L. Cao, R. Ji, Y. Gao, Y. Y ang, and Q . Tian. W eakly Sup ervised Sparse Co ding with Geometric Consistency P o oling. In CVPR 2012 , pages 3578–35 85. IEEE, 2012. [5] H. Daume I I I. F rustratingly easy d omain adaptation. In ACL 2007 - Pr o c e e dings of the 45th Annua l Me eting of the Asso ciation for Computational Linguistics , p ages 256 – 263, 2007. [6] B. Geng, D . T ao, C. Xu, L. Y ang, and X.-S. H ua. Ensem ble Manifold R egulariza tion. IEEE T r ansactions on Pattern Ana lysis and Machine Intel ligenc e , 34(6):1227–1233 , JUN 2012. [7] H. Lee, A . Battle, R. R aina, and A. Y. N g. Efficient sparse co ding algorithms. In NI PS , pages 801–808. NIPS, 2007. [8] S. J. Pan, I. W. Tsang, J. T. K wok, and Q. Y ang. Domain Adaptation via T ransfer Component Analysis. In IJCAI 2009 , pages 1187–11 92, 2009. [9] S. J. Pan, I. W. Tsang, J. T. K wok, and Q. Y ang. Domain Adaptation via T ransfer Component Analysis. IEEE T r ansactions on Neur al Networks , 22(2):199– 210, FEB 2011. [10] M. Zheng, J. Bu, C. Chen, C. W ang, L. Z h ang, G. Q iu, and D . Cai. Graph Regularized Sparse Co ding for Image Representation. IEEE T r ansactions on Image Pr o c essing , 20(5):1327– 1336, MA Y 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment