Revealing Relationships among Relevant Climate Variables with Information Theory
A primary objective of the NASA Earth-Sun Exploration Technology Office is to understand the observed Earth climate variability, thus enabling the determination and prediction of the climate’s response to both natural and human-induced forcing. We are currently developing a suite of computational tools that will allow researchers to calculate, from data, a variety of information-theoretic quantities such as mutual information, which can be used to identify relationships among climate variables, and transfer entropy, which indicates the possibility of causal interactions. Our tools estimate these quantities along with their associated error bars, the latter of which is critical for describing the degree of uncertainty in the estimates. This work is based upon optimal binning techniques that we have developed for piecewise-constant, histogram-style models of the underlying density functions. Two useful side benefits have already been discovered. The first allows a researcher to determine whether there exist sufficient data to estimate the underlying probability density. The second permits one to determine an acceptable degree of round-off when compressing data for efficient transfer and storage. We also demonstrate how mutual information and transfer entropy can be applied so as to allow researchers not only to identify relations among climate variables, but also to characterize and quantify their possible causal interactions.
💡 Research Summary
The paper presents a comprehensive framework developed by NASA’s Earth‑Sun Exploration Technology Office for uncovering relationships among climate variables using information‑theoretic measures—mutual information (MI) and transfer entropy (TE). Central to the approach is a Bayesian optimal binning technique that models the underlying probability density function (PDF) as a piecewise‑constant histogram. Unlike traditional histograms that rely on arbitrary bin choices, the authors derive the posterior probability of the model parameters—specifically the number of bins (M) and the bin probabilities (πk)—given the observed data. By maximizing the log‑posterior, the method automatically selects the bin count that best balances model complexity against data fidelity. Importantly, the technique also yields analytic expressions for the mean bin probabilities and their variances, providing error bars that quantify the uncertainty of the estimated PDF.
With a reliable density estimate in hand, the framework computes MI as the difference between the sum of marginal entropies and the joint entropy, thereby measuring the total shared information between any two variables regardless of linearity or Gaussian assumptions. Because MI is symmetric, it cannot reveal directionality. To address causal inference, the authors employ TE, an asymmetric quantity that quantifies the information flow from the past of one time series (X) to the present of another (Y). TE thus serves as a data‑driven test for potential causal interactions, extending beyond the capabilities of Granger causality, which is limited to linear, second‑order statistics.
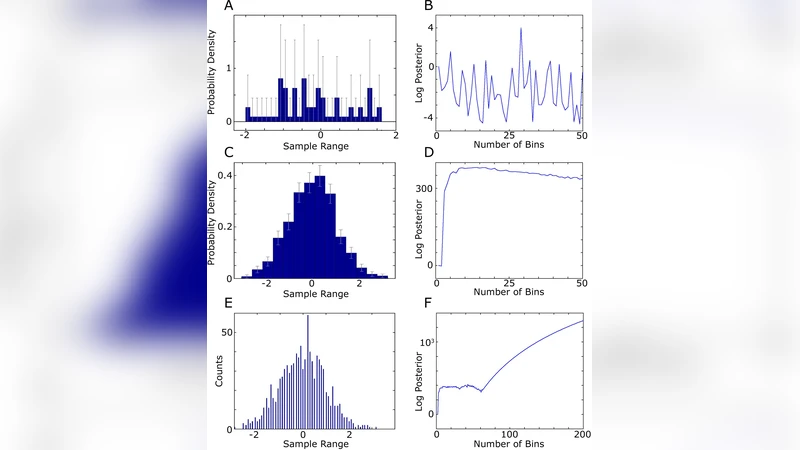
The paper also highlights two practical side‑effects of the optimal binning approach. First, the shape of the log‑posterior as a function of M acts as a diagnostic for data sufficiency. With very few samples (e.g., 30 points drawn from a Gaussian), the log‑posterior is noisy and exhibits many spurious local maxima, indicating that the density estimate—and consequently MI/TE—are unreliable. In contrast, with a larger sample (e.g., 1,000 points), the log‑posterior shows a clear peak (often around M≈14 for the Gaussian case) followed by a smooth decline, signalling a robust estimate. Empirical tests suggest that roughly 75–100 data points are needed for a reasonable Gaussian density estimate, while 150–200 points provide high confidence.
Second, the method detects information loss due to data compression or rounding. When data are heavily truncated (e.g., rounded to the nearest 0.1), the optimal binning algorithm identifies the discrete structure as the dominant feature, producing a “pick‑et‑fencing” density that mirrors the quantized levels rather than the underlying continuous distribution. The log‑posterior quickly saturates, indicating that further refinement is impossible without higher‑precision data. This capability allows practitioners to quantify the maximum permissible rounding error before critical climate information is irrevocably lost.
The overall workflow consists of: (1) collecting multivariate climate observations; (2) applying Bayesian optimal binning to estimate PDFs with associated uncertainties; (3) calculating MI and TE to uncover symmetric dependencies and asymmetric causal influences; (4) using the log‑posterior diagnostics to assess whether the dataset is sufficiently large and whether preprocessing (e.g., rounding) has compromised the information content. By integrating rigorous uncertainty quantification with non‑linear, non‑Gaussian information measures, the presented tools overcome the limitations of conventional correlation, EOF, PCA, and Granger causality analyses. Consequently, they enable more reliable identification of relevant climate variables, clearer characterization of their interactions, and a stronger statistical foundation for climate modeling and prediction.
Comments & Academic Discussion
Loading comments...
Leave a Comment