Parameterized Complexity of the k-anonymity Problem
The problem of publishing personal data without giving up privacy is becoming increasingly important. An interesting formalization that has been recently proposed is the $k$-anonymity. This approach requires that the rows of a table are partitioned i…
Authors: Stefano Beretta, Paola Bonizzoni, Gianluca Della Vedova
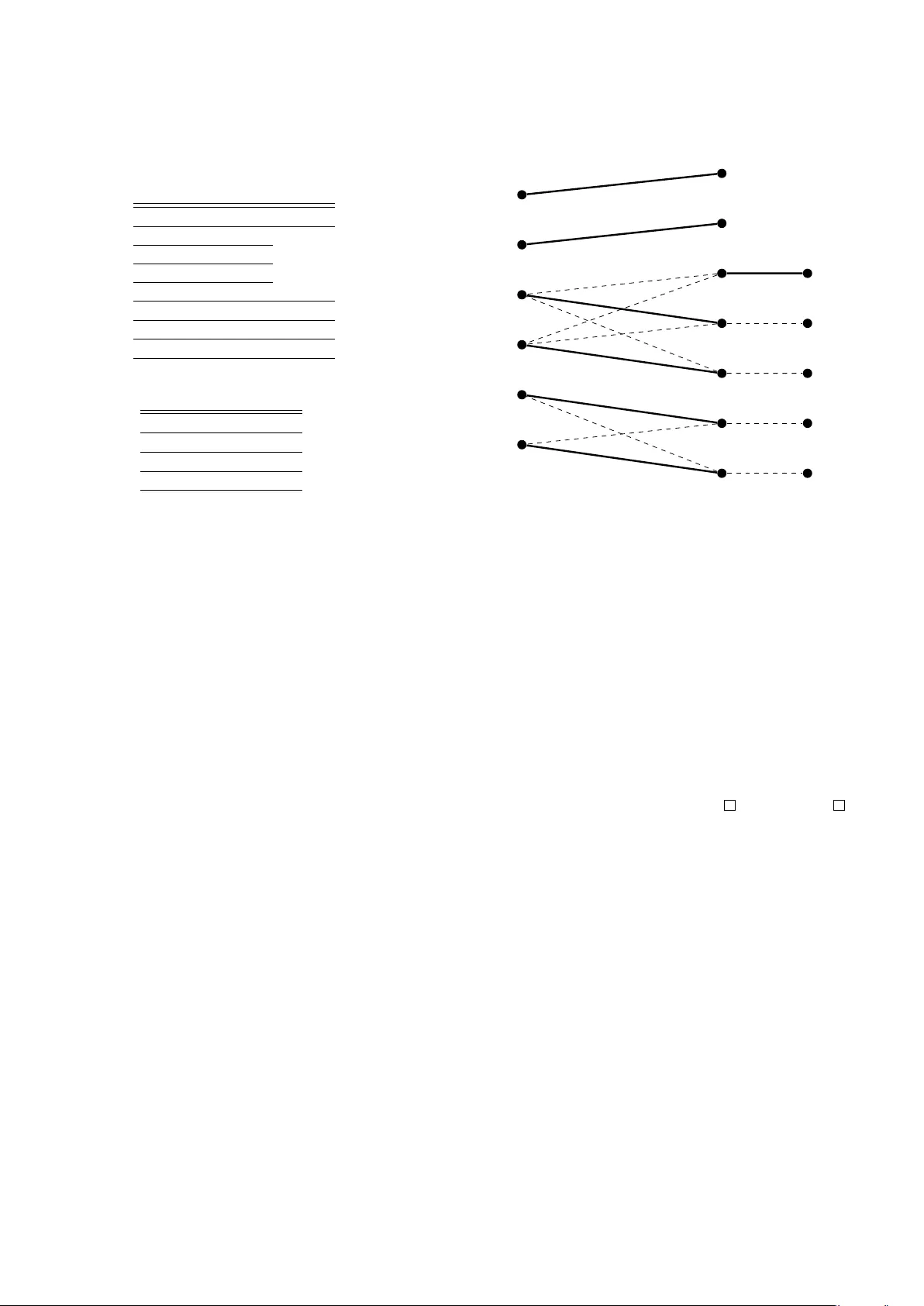
P arameterized Complexit y of k -Anon ymit y: Hardness and T ractabilit y Stefano Beretta ∗ P aola Bonizzoni † Gianluca Della V edo v a ‡ Riccardo Dondi § Y uri Pirola ¶ Octob er 26, 2018 Abstract The problem of publishing p ersonal data without giving up priv acy is becoming increasingly imp ortan t. A clean formalization that has b een recen tly prop osed is the k -anonymit y , where the ro ws of a table are partitioned in clusters of size at least k and all ro ws in a cluster b ecome the same tuple, after the suppression of some entries. The natural optimization problem, where the goal is to minimize the n umber of suppressed entries, is hard even when the stored v alues are ov er a binary alphabet and as well as on a table consists of a b ounded n umber of columns. In this paper w e study ho w the complexity of the problem is influenced by differen t parameters. First w e sho w that the problem is W[1]-hard when parameterized b y the v alue of the solution (and k ). Then we exhibit a fixed-parameter algorithm when the problem is parameterized b y the num b er of columns and the maximum num b er of differen t v alues in an y column. Finally , we prov e that k -anonymit y is still APX-hard even when restricting to instances with 3 columns and k = 3. 1 In tro duction In epidemic studies the analysis of large amoun ts of p ersonal data is essen tial. A t the same time the dissemination of the results of those studies, even in a compact and summarized form, can pro vide some information that can be exploited to iden tify the row p ertaining to a certain individual. F or instance, ZIP co de, gender and date of birth can uniquely iden tify 87% of indi- viduals in the U.S. [18]. Therefore when managing personal data it is of the utmost imp ortance to effectively protect individuals’ priv acy . One approach to deal with such problem is the k -anon ymity mo del [16, 18, 15, 12]. Eac h ro w of a given table represen ts all data regarding a certain individual. Then differen t ro ws are clustered together, and some entries of the rows in each cluster are suppressed (i.e. they are replaced with a ∗ ) so that eac h cluster consists of at least k identical rows. Therefore eac h ro w r in the resulting table is clustered with at least other k − 1 rows identical to r , hence the resulting ∗ DISCo, Univ ersit` a degli Studi di Milano-Bicocca, Milano - Italy † DISCo, Univ ersit` a degli Studi di Milano-Bicocca, Milano - Italy ‡ Dipartimen to di Statistica, Universit` a degli Studi di Milano-Bicocca, Milano - Italy § Dipartimen to di Scienze dei Linguaggi, Univ ersit` a degli Studi di Bergamo, Bergamo - Italy ¶ DISCo, Universit` a degli Studi di Milano-Bico cca, Milano - Italy 1 data do not allow to iden tify any individual. While suc h form ulation is not really sophisticated and has some practical limitations, it is definitely in teresting from a theoretical p oint of view, as witnessed b y the rich literature av ailable. W e will fo cus on separating the cases that can be solv ed efficien tly from those that are in tractable, therefore hin ting at whic h strategies are lik ely or not going to be successfully emplo yed when studying more sophisticated formalizations. Notice that differen t form ulations of the problem hav e also b een proposed [1], for example allo wing the generalization of entry v alues, that is an entry v alue can b e replaced with a less sp ecific v alue [3], or considering a notion of proximit y among v alues [10]. A parsimonious principle leads to the optimization problem where w e wan t to minimize the n umber of en tries in the table to b e suppressed. The k -anonymit y problem is known to b e APX-hard even when the matrix entries are ov er a binary alphab et and k = 3 [6], as w ell as when the matrix has 8 columns and k = 4 (this time on arbitrary alphab ets) [6]. F urther- more, a p olynomial-time O ( k )-appro ximation algorithm on arbitrary input alphab et, as well as appro ximation algorithms for restricted cases are known [2]. Recen tly , t wo p olynomial-time ap- pro ximation algorithms with factor O (log k ) ha ve b een indep enden tly proposed [14, 11]. In this pap er we inv estigate the parameterized complexity [8, 13] of the problem, un veiling ho w different parameters are inv olv ed in the complexit y of the problem. A first systematic study of the parameterized complexit y of the k -anon ymity problem has b een prop osed in [7]. Here, w e follow the same direction, sho wing that the problem is W[1]-hard when parameterized b y the size of the solution and k , and w e provide a fixed-parameter algorithm, when the problem is parameterized by the num b er of columns and the maximum n umber of different v alues in any column. These problems w ere left op en in [7]. In T able 1 w e rep ort the status of the parameterized complexity of the k -anon ymity problem, where in b old we ha ve emphasized the new results presen ted in this pap er. W e recall that a problem P parameterized by a set Y of parameters is in the class FPT [8] if it admits an exact algorithm with complexity f ( Y ) n O (1) , where f is an arbitrary function, and n is the size of the input problem, while it is W[i]-hard [8], for some 1 ≤ i ≤ p if it is unlik ely to be fixed-parameter tractable. W e recall that XP [8] is a superclass of all sets W[ p ]. Moreo ver, pro ving that a problem Π with parameter set S is NP-hard when all parameters in S are some constants, implies that (Π , S ) / ∈ XP unless P = NP . − k e k , e − NP-hard [12] / ∈ X P [6, 2] W[1]-hard new W[1]-hard new | Σ | / ∈ X P [6] / ∈ X P [6] ??? ??? m / ∈ X P for m ≥ 8 [6] / ∈ X P for m ≥ 8, k ≥ 4 [6] FPT [7] FPT [7] n FPT [7] FPT [7] FPT [7] FPT [7] | Σ | , m FPT new FPT [7] FPT [7] FPT [7] | Σ | , n FPT [7] FPT [7] FPT [7] FPT [7] T able 1: Summary of the parameterized complexity status of the k -anon ymity problem; | Σ | represen ts the maximum num ber of differen t v alues in a column, m represents the num b er of columns, n represen ts the num b er of rows, k represents the minim um size of a cluster, e represents the size of the solution. The rest of the pap er is organized as follows. In Section 2 w e introduce some preliminary definition and w e giv e the formal definition of the k -anonymit y problem. In Section 3 w e sho w that the k -anonymit y is W[1]-hard. In Section 4 we give a fixed parameter algorithm, when the problem is parameterized by the size of the alphab et and the num b er of columns. Finally , in 2 Section 5 we sho w that the 3-anon ymity problem is APX-hard, ev en when the ro ws ha ve length b ounded by 3. 2 Preliminary Definitions Let us in tro duce some preliminary definitions that will b e used in the rest of the pap er. Given a graph G = ( V , E ), and V 0 ⊆ V , the sub gr aph induc e d by V 0 is denoted by G [ V 0 ] = ( V 0 , E 0 ), where E 0 = E ∩ ( V 0 × V 0 ). A graph G = ( V , E ) is cubic when eac h vertex in V has degree three. Giv en an alphab et Σ, a row r is a vector of elemen ts taken from the set Σ, and the j -th elemen t of r is denoted by r [ j ]. Notice that it is equiv alen t to consider a row as a v ector ov er Σ or as a string ov er alphab et Σ. Let r 1 , r 2 b e t wo equal-length rows. Then H ( r 1 , r 2 ) is the Hamming distance of r 1 and r 2 , i.e. |{ i : r 1 [ i ] 6 = r 2 [ i ] }| . Let R b e a set of l rows, then a clustering of R is a partition Π = ( P 1 , . . . , P t ) of R . Given a clustering Π = ( P 1 , . . . , P t ) of R , we define the c ost of the ro w r b elonging to a set P i of Π as c Π ( r ) = |{ j : ∃ r 1 , r 2 ∈ P i , r 1 [ j ] 6 = r 2 [ j ] }| , that is the n umber of entries of r that ha ve to be suppressed so that all ro ws in P i are iden tical. Similarly w e define the cost of a set P i , denoted b y c Π ( P i ), as | P i ||{ j : ∃ r 1 , r 2 ∈ P i , r 1 [ j ] 6 = r 2 [ j ] }| . The cost of Π, denoted by c (Π), is defined as P P i ∈ Π c ( P i ). Given a set S ⊆ R and a clustering Π of R , the cost induced by Π in set S is c Π ( S ) = P r ∈ S c Π ( r ). Notice that, giv en a clustering Π = ( P 1 , . . . , P t ) of R , the quantit y | P i | max r 1 ,r 2 ∈ P i { H ( r 1 , r 2 ) } is a low er b ound for c ( P i ), since all the p ositions for which r 1 and r 2 differ will b e deleted in eac h ro w of P i . W e are no w able to formally define the k -Anonymit y Problem ( k -AP). Problem 1. k -AP. Input : a set R of e qual lenght r ows over an alphab et Σ R . Output : a clustering Π = ( P 1 , . . . , P t ) of R such that for e ach set P i , | P i | ≥ k and c (Π) is minimum. In what follows, given a set S of parameters, w e denote by h S i -AP the k -AP problem param- eterized by S , th us omitting k . W e will consider the following parameters: m is the n umber of columns of the ro ws in R ; n is the num b er of ro ws in R ; | Σ | is the maximum n umber of different v alues in an y column of the table; k is the minim um size of a cluster; e is the maxim um num b er of entries that can b e suppressed. Let Π = ( P 1 , . . . , P z ) b e a solution of the k -AP problem. Notice that a suppression at p osition j of a row r is represen ted replacing the symbol r [ j ] with a ∗ . Giv en a set P j of Π, some entries of the ro ws clustered in P j are suppressed, so that the resulting rows are all identical to a vector r o v er alphabet Σ R ∪ {∗} ; suc h a v ector is the r esolution ve ctor associated with P j . Giv en a resolution vector r , we define del ( r ) as the nu mber of entri es suppressed in r , that is del ( r ) = |{ j : r [ j ] = ∗}| . Given a resolution vector r and a row r i ∈ R , we sa y that r is c omp atible with row r i iff r [ j ] 6 = r i [ j ] implies r [ j ] = ∗ . Given a row r i of R and a set of resolution vectors S 0 , w e define the set comp ( r i , S 0 ) = { r ∈ S 0 : r is compatible with r i } . Giv en a set R of ro ws, w e define a gr oup of rows of R as a maximal set of identical rows. Giv en a group g , the r epr esentative r ow of g , denoted b y r ( g ), is an y row of g , while s ( g ) is the n umber of rows in g and exc ( g ) = max { 0 , s ( g ) − k } . A set R of rows can b e partitioned in groups of identical rows in p olynomial time [7], therefore w e can compute in p olynomial time whether a set R of rows is k -anon ymous, i.e. R can b e partioned into groups of size at least k . If this is not p ossible, then observ e that at least k entries of R m ust b e suppressed to get a solution of 3 the k -AP problem, that is e ≥ k . Hence h e i -AP is in FPT iff h e, k i -AP is in FPT. Consequen tly our parameterized reduction [8, 13] will show the fixed-parameter intractabilit y of h e i -AP and h e, k i -AP . 3 h e i -AP and h e, k i -AP are W[ 1 ]-hard W e show that h e i -AP and h e, k i -AP are W[1]-hard. Giv en an set R of equal length ro ws, h e i -AP and h e, k i -AP ask if there exists a clustering Π = ( P 1 , . . . , P t ) of R such that | P i | ≥ k for each set P i , and c (Π) ≤ e . W e presen t a parameter preserving reduction from the h -Clique problem, which is kno wn to be W[1]-hard [9], to the h e i -AP problem. Given a graph G = ( V , E ), an h -clique is a set V 0 ⊆ V where each pair of v ertices in V 0 are connected b y an edge of G , and | V 0 | = h . The h -Clique problem asks for a subset V 0 of the vertices of a given graph G inducing an h -clique in G . Clearly the v ertices of a h -clique are connected b y h 2 edges. Giv en a graph G = ( V , E ), w e use m G and n G to denote resp ectiv ely the num b er of edges and of vertices of G . W e construct the instance R of h e i -AP associated with G . First, let us define k = 2 h 2 . The set R consists of ( k + 1) m G + ( k − h 2 ) rows and 2 h + n G columns ov er alphab et Σ R = { 0 , 1 } ∪ { σ i,j : ( v i , v j ) ∈ E } . More precisely , for each edge e ( i, j ) = ( v i , v j ) in E , there is a group R ( i, j ) of k + 1 identical rows r x ( i, j ), 1 ≤ x ≤ k + 1, where • r x ( i, j )[ l ] = σ i,j , for 1 ≤ l ≤ 2 h ; • r x ( i, j )[2 h + i ] = 1, r x ( i, j )[2 h + j ] = 1; • r x ( i, j )[2 h + l ] = 0, for l 6 = i, j and 1 ≤ l ≤ n . Moreo ver, R also contains a group R 0 made of k − h 2 iden tical ro ws equal to 0 2 h + n G . Lemma 1. L et R b e the instanc e of h e i -AP asso ciate d with G and c onsider two r ows r , r x ( i, j ) of R , such that r ∈ R 0 and r x ( i, j ) ∈ R ( i, j ) . Then, r [ t ] 6 = r x ( i, j )[ t ] , for e ach 1 ≤ t ≤ 2 h . Lemma 2. L et G = ( V , E ) b e a gr aph, let V 0 b e a h -clique of G and let R b e the instanc e of h e i -AP asso ciate d with G . Then we c an c ompute in p olynomial time a solution Π of h e i -AP over instanc e R with c ost at most 6 h 3 . Lemma 3. L et G = ( V , E ) b e an instanc e of h -Clique, let R b e the instanc e of h e i -AP asso ciate d with G and let Π b e a solution of h e i -AP over instanc e R with c ost at most 6 h 3 . Then we c an c ompute in p olynomial time a h -clique V 0 of G . Pr o of. First we will prov e that Π must ha ve a set R 0 0 ⊃ R 0 . Assume to the con trary that in Π there are tw o sets A , B containing at least a ro w of R 0 . Notice that | R 0 | < k while | A | , | B | ≥ k . Moreo ver, by Lemma 1, all rows in A or B must hav e suppressed the first 2 h entries, whic h results in at least 4 hk > 6 h 3 suppressions, con tradicting the assumption on the cost of the solution. Hence, R 0 is prop erly contained in a set R 0 0 of Π, as | R 0 | < k . Moreo ver, let r 0 b e a row of R 0 0 \ R 0 and let r b e a ro w of ∈ R 0 . By Lemma 1 r 0 [ t ] 6 = r [ t ] for eac h column t , 1 ≤ t ≤ 2 h , therefore all en tries in the first 2 h columns of each row in R 0 0 m ust be suppressed. No w, let us prov e that, for eac h set R ( i, j ) of R , there exists a set R 0 ( i, j ) of Π suc h that R 0 ( i, j ) ⊆ R ( i, j ). Assume to the contrary that no such set R 0 ( i, j ) exists, for a given R ( i, j ). 4 Then either R ( i, j ) ⊆ R 0 0 or there exists a ro w of R ( i, j ) clustered together with a ro w of R ( x, y ) in Π, with ( x, y ) 6 = ( i, j ). In the first case, that is R ( i, j ) ⊆ R 0 0 , | R 0 0 | ≥ 2 k + 1 − h 2 , by construction all entries of the first 2 h columns of the rows in R 0 0 m ust b e suppressed, resulting in at least 2 h (4 h 2 − h 2 ) > 6 h 3 suppressions and th us contradicting the assumption on the cost of the solution. Consider no w the second case, that is there is a set A in Π containing at least a ro w of t wo different sets R ( i, j ) and R ( x, y ) of R . Observe that giv en r 0 ∈ R 0 0 \ R 0 and r ∈ R 0 , r and r 0 differ in the first 2 h columns. Th us the entries of the first 2 h columns of the ro ws of R 0 0 m ust b e suppressed, resulting in at least 4 hk > 6 h 3 suppressed entries and thus con tradicting the assumption on the cost of the solution. Hence, for each set R ( i, j ) of R , there exists a set R 0 ( i, j ) of Π suc h that R 0 ( i, j ) ⊆ R ( i, j ). By our previous argumen ts we can assume that Π consists of the clusters R 0 0 and R 0 ( i, j ), for eac h R ( i, j ) ∈ R , and that | R ( i, j ) | − 1 ≤ | R 0 ( i, j ) | ≤ | R ( i, j ) | . Notic e that only R 0 0 can contain some suppressed en tries. Also | R 0 0 | = k , for otherwise we can impro v e the cost of Π b y moving a row in R ( i, j ) ∩ R 0 0 from R 0 0 to R 0 ( i, j ). Now let E 0 b e the set of edges ( v i , v j ) of G such that a row of R ( i, j ) is in R 0 0 and let V 0 b e the set of v ertices incident on at least an edge in E 0 . Then we can sho w that G [ V 0 ] is a h -clique. Notice that the en tries in the first 2 h columns of R 0 0 m ust b e suppressed, as well as all columns with index 2 h + l such that v l ∈ V 0 , since in those columns all rows in R 0 ha ve v alue 0 while some row in R 0 0 \ R 0 ha ve v alue 1. An immediate consequence is that the ov erall num ber of suppressed entries is at least 2 hk + k | V 0 | . Since, by h yp othesis, the n umber of suppressed entries is at most 6 h 3 = 3 k h , then | V 0 | ≤ h . Notice that, since | R 0 | = k − h 2 and | R 0 0 | = k , then R 0 0 \ R 0 con tains exactly h 2 distinct rows corresp onding to edges in E 0 inciden t on V 0 v ertices. Hence V 0 induces a h -clique in G . F rom Lemma 2 and 3, our reduction is parameter preserving, therefore h e i -AP and h e, k i -AP are W[1]-hard. 4 An FPT algorithm for h| Σ | , m i -AP In this section we presen t a fixed-parameter algorithm for the h| Σ | , m i -AP problem, that is the instance of the AP problem, where the n umber m of columns and the maximum n umber | Σ | of differen t v alues in any column are tw o parameters. Notice that k -AP parameterized by exactly one of | Σ | or m is not in FPT, as k -AP is APX-hard (hence NP-hard) even when one of | Σ | or m is a constan t [6]. Before giving the details of the algorithm, let us first introduce some preliminary definitions. Let R b e an instance of h| Σ | , m i -AP, and for each column of R with index j , 1 ≤ j ≤ m , let Σ j b e the set of differen t v alues that the rows of R ha v e in column j . Notice that | Σ j | ≤ | Σ | , for eac h 1 ≤ j ≤ m . Let Σ ∗ j = Σ j ∪ {∗} and Σ ∗ = Σ ∪ {∗} . Assume Π = { P 1 , · · · , P z } is a feasible solution of h| Σ | , m i -AP o v er instance R . The set S 0 consisting of a resolution vector for eac h set P i ∈ Π is called c andidate set for solution h| Σ | , m i -AP. Let S b e the set of p ossible rows of length m and ha ving v alue ov er alphabet Σ ∗ j for the p osition j , 1 ≤ j ≤ m , then | S | is bounded by | Σ ∗ | m . Giv en a candidate set S 0 , notice that S 0 ⊆ S and that each ro w r ∈ R must compatible with at least one resolution vector in S 0 . Giv en a ro w r and the set S 0 of resolution v ectors, recall that w e denote b y C omp ( r, S 0 ) the set of resolution vectors of S 0 compatible with r . Moreo ver, given a resolution v ector r 0 ∈ S 0 , we denote by del ( r 0 ) the n umber of suppressions in r 0 . F or each ro w r ∈ R we define its w eight as w ( r ) = max r x ∈ C omp ( r,S 0 ) { m − del ( r x ) } . Notice that w ( r ) = m whenever r is compatible with a 5 Algorithm 1 : Solving h| Σ | , m i -AP Input : An instance R of h| Σ | , m i -AP made of a set of n ro ws, each one consisting of m sym b ols, and an in teger e Output : a solution of h| Σ | , m i -AP o v er instance R , if h| Σ | , m i -AP admits a solution that suppresses at most e en tries; S ← the set of resolved vectors of length m , where eac h j -th sym b ol, 1 ≤ j ≤ m , is tak en 1 from the alphab et Σ ∗ j ; W = P r ∈ R w ( r ); 2 foreac h subset S 0 of S do 3 G R,S 0 ← the graph asso ciated with R , S 0 ; 4 M ← a maxim um matc hing of G R,S 0 ; w ← the weigh t of M ; 5 if M is fe asible and w ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e | − e then 6 return the solution Π S 0 ( M ) of R asso ciate d with M ; 7 return No such solution exists 8 ro w without suppressions. Informally , the w eight of a ro w is equal to the maximum num b er of its en tries that might b e preserved in a solution where S 0 is the set of resolution vectors. Finally , w e define W = P r ∈ R w ( r ) and w 0 ( r x ) = W + m − del ( r x ) + 1 for eac h row r x ∈ S 0 . Notice that w 0 ( r x ) ≥ P r ∈ R w ( r ), for each r x ∈ R . The w eights defined ab o ve will b e used later in Section 4.1 to define the weigh t function w h . Let us first describe the general idea of the algorithm. Given a candidate set S 0 , the algorithm computes an optimal solution Π S 0 asso ciated with a candidate set S 0 ⊆ S (see Algorithm 1). The algorithm consists of tw o main phases. In the first phase (Section 4.1), given the set R of input ro ws and the candidate set S 0 , the algorithm builds a weigh ted bipartite graph G S 0 ,R asso ciated with R and S 0 . In the second phase (Section 4.2) a solution of h| Σ | , m i -AP is computed starting from a maximum weigh ted matching of the graph G S 0 ,R . Section 4.3 is dev oted to pro ve that the solution computed b y the algorithm is optimal. 4.1 Building the graph G R,S 0 Let us consider a candidate set S 0 of vectors for an optimal solution of h| Σ | , m i -AP. Since S 0 ⊆ S , there exist at most 2 | Σ ∗ | m p ossible candidate sets of rows S 0 , therefore our FPT algorithm computes each candidate set S 0 and verifies if there exists a solution Π S 0 with cost at most e . In order to verify if such a solution exists, the algorithm builds a bipartite graph G R,S 0 , as describ ed in this section. The intuitiv e idea b ehind the graph is that edges of the graph corresp ond to p ossible wa ys of assigning each ro w in R to a resolution vector x ∈ S 0 . Rows assigned to the same resolution vector x ∈ S 0 are clustered in the solution Π S 0 . The construction of the vertex set of the graph is based on a a partition of R in to tw o disjoint sets called R saf e and R dist (that is R dist = R \ R saf e ). The set R saf e consists of those rows r ∈ R b elonging to the group g suc h that: s ( g ) ≥ k , that is r b elongs to a group of at least k identical ro ws, and there exists a row r j ∈ S 0 , such that r j and r ( g ) are the same vector. Notice that only ro ws in R saf e migh t ha v e no suppressed en try in a solution Π S 0 . The v ertex set of G R,S 0 = ( V , E ) has 6 sets. Two sets ( R l dist , R r dist ) consist of vertices asso ciated with the ro ws in R dist , three sets ( R 0 l saf e , R l saf e , R r saf e ) consist of v ertices asso ciated with the ro ws 6 in R saf e , and a final set called T consists of vertices asso ciated with the ro ws in S 0 . In the latter case notice that for eac h ro w x in S 0 there exist k vertices in T to ensure that the cluster associated with x has size at least k . The vertex set is defined as follo ws: • for eac h row x ∈ R dist , there is a corresp onding vertex R l dist ( x ) in R l dist and a corresp onding v ertex R r dist ( x ) in R r dist ; • for eac h group g consisting of the set of rows { x 1 , x 2 , . . . , x s ( g ) } , where eac h x i ∈ R saf e , 1 ≤ i ≤ s ( g ), there are k corresp onding v ertices in R 0 l saf e , (suc h vertices are denoted b y R 0 l saf e ( g , 1) , . . . , R 0 l saf e ( g , k )), exc ( g ) corresp onding vertices in R l saf e (suc h vertices are denoted b y R l saf e ( g , 1) , . . . , R l saf e ( g , exc ( g )), and exc ( g ) corresp onding v ertices in R r saf e (suc h v ertices are denoted by R r saf e ( g , 1) , . . . , R r saf e ( g , exc ( g )); • for eac h row x ∈ S 0 , there are k corresp onding v ertices in T (such v ertices are denoted b y T ( x, 1) , . . . , T ( x, k )). Notice that our graph G R,S 0 is edge-w eighted. Let w h b e the w eight function assigning a p ositiv e weigh t to each edge of G R,S 0 . Given the set of edges E 0 ⊆ E , w e denote by w h ( E 0 ) = P e ∈ E 0 w h ( e ). First, notice that the set S 0 consists of tw o disjoint sets: the set S 0 saf e consists of those ro ws in S 0 that hav e no suppressions, while S 0 cost = S 0 \ S 0 saf e . Eac h edge connects a v ertex of R 0 l saf e ∪ R l saf e ∪ R l dist with a vertex of R r saf e ∪ R r dist ∪ T , hence the graph G R,S 0 is bipartite. The set S 0 consists of tw o disjoin t sets: the set S 0 saf e consists of those rows in S 0 that ha v e no suppressions, while S 0 cost = S 0 \ S 0 saf e . Intuitev ely , eac h edge represents a possible assignmen t of a ro w in R to a resolution v ector in S 0 . Algorithm 2 : F rom a matc hing to a feasible solution of h| Σ | , m i -AP. Input : A graph G R,S 0 asso ciated with an instance R and a maximum weigh t matching M of G R,S 0 Output : A solution Π S 0 ( M ) of h| Σ | , m i -AP o ver instance R foreac h e dge y of M do 1 if y = ( R l dist ( r ) , T ( x, j )) then /* edges defined at point 1 */ 2 ro w r is assigned to a set whose resolution row is x , x ∈ S 0 3 if y = ( R l dist ( r ) , R r dist ( r )) then /* edges defined at point 2 */ 4 ro w r is assigned to a set whose resolution row is r y = arg max w ( r ), r y ∈ S 0 ; 5 if y = ( R 0 l saf e ( g , i ) , T ( x, j )) then /* edges defined at point 3 */ 6 assign the i -th row of g to a set whose resolution row is x , x ∈ S 0 ; 7 if y = ( R l saf e ( g , i ) , T ( x, j )) then /* edges defined at point 4 */ 8 assign the i -th exceeding ro w of g to a set whose resolution ro w is x , x ∈ S 0 ; 9 if y = ( R l saf e ( g , i ) , R r saf e ( g , i )) then /* edges defined at point 5 */ 10 assign the i -th exceeding ro w of group g to the set whose resolution row is r ( g ), 11 with r ( g ) ∈ S 0 and r ∈ R saf e ; No w w e are ready to define formally the set of edges E of G R,S 0 and the w eight function w h . There are fiv e possible kinds of edges. 7 1. Let r b e a row of R dist , and let x b e a ro w in C omp ( r, S 0 ) ∩ S 0 cost . Then there is an edge y = ( R l dist ( r ) , T ( x, j )), for eac h 1 ≤ j ≤ k , with w eight w h ( y ) = w 0 ( x ). 2. Let r be a row in R dist . Then there is an edge y = ( R l dist ( r ) , R r dist ( r )) with w eight w h ( y ) = w ( r ). 3. Let g b e a group consisting of ro ws { r 1 , . . . , r s ( g ) } , where r i , for eac h i with 1 ≤ i ≤ s ( g ), is a ro w of R saf e ; let r 0 b e the resolution v ector of S 0 saf e iden tical to r ( g ). Then there is an edge y i = ( R 0 l saf e ( g , i ) , T ( r 0 , i )), for each i with 1 ≤ i ≤ k . All edges y i ha ve w eight w h ( y i ) = w 0 ( r 0 ). 4. Let g b e a group consisting of ro ws { r 1 , . . . , r s ( g ) } , where r i , for eac h i with 1 ≤ i ≤ s ( g ), is a row of R saf e ; let x b e a row in C omp ( r ( g ) , S 0 ) ∩ S 0 cost . Then there is an edge y i,j = ( R l saf e ( g , i ) , T ( x, j )), for eac h i with 1 ≤ i ≤ exc ( g ) and for each j with 1 ≤ j ≤ k . All edges y i,j ha ve weigh t w h ( y i,j ) = w 0 ( x ). 5. Let g b e a group consisting of rows { r 1 , . . . , r s ( g ) } , where r i , 1 ≤ i ≤ s ( g ), is a row of R saf e . Then there is an edge y i = ( R l saf e ( g , i ) , R r saf e ( g , i )) for each i with 1 ≤ i ≤ exc ( g ). All edges y i ha ve weigh t w h ( y i ) = w ( r ( g )). 4.2 Computing a solution of h| Σ | , m i -AP In this section w e prov e in Lemma 6 that Π S 0 ( M ) is a clustering of the rows in R that is a feasible solution for the h| Σ | , m i -AP problem. See Fig. 4.2 for an example. Since G R,S 0 bipartite, w e can efficien tly compute a maxim um w eigh t matc hing M of G R,S 0 [17]. Giv en a matc hing M of the graph G R,S 0 , Algorithm 2 computes in p olynomial time a clustering Π S 0 ( M ) of the rows in R . Informally , the clustering is computed by assigning the ro ws in R to the resolution v ector in S 0 , using the edges in the matc hing M . Notice that, eac h vertex R l saf e ( r , i ) has only the edge ( R l saf e ( r , i ) , T ( r, i )) on it, hence we can alw ays add those edges to any matching 1 . Let M b e a matching of G R,S 0 and let v b e a vertex of G R,S 0 , then we say that v is c over e d b y a matc hing M if there exists an edge of M for which v is one of its endpoints. Moreov er, we will say that M is fe asible if all v ertices in T are co v ered by M . When a matching M cov ers all vertices in R l dist ∪ R l saf e and is feasible, it is defined as a c omplete matching . Let Π b e a clustering of an instance R of the h| Σ | , m i -AP problem. Then Π is fe asible if and only if each set of the partition Π contains at least k ro ws. The next part of this section is dev oted to sho w that every maximum w eigh t matc hing M is complete and that clustering Π S 0 ( M ) is fe asible . First, we will show in the next t wo lemmata that, giv en W 0 = k P r x ∈ T w 0 ( r x ), W 0 is a threshold that distinguishes betw een matc hings that are feasible and those that are not. Lemma 4. L et M b e a matching of G R,S 0 , let X b e the subset of T c onsisting of the vertic es of T that ar e c over e d by M , and let M 1 b e the subset of the e dges of M that have one endp oint in X . Then the total weight of the e dges in M 1 is exactly P T ( t,i ) ∈ X w 0 ( t ) . Pr o of. It is an immediate consequence of the observ ation that all edges where an endp oint is T ( t, j ) ha v e the same w eigh t w 0 ( t ), with t ∈ S 0 . 1 Notice that these connected comp onents are in tro duced only to simplify the relationship b etw een a matching M and the corresp onding solution Π S 0 ( M ) of h| Σ | , m i -AP 8 Ro ws R Name Data w Group r 1 aaa 3 r 2 aaa 3 r 3 aaa 3 g 1 r 4 aaa 3 r 5 aba 2 g 2 r 6 bbb 2 g 3 r 7 bb c 2 g 4 Resolution vectors S 0 Name V ectors w s 1 aaa 21 s 2 a*a 20 s 3 bb* 20 R l dist ( r 7 ) R l dist ( r 6 ) R l dist ( r 5 ) R l saf e ( g 1 , 2) R l saf e ( g 1 , 1) R 0 l saf e ( g 1 , 2) R 0 l saf e ( g 1 , 1) R r saf e ( g 1 , 2) R r saf e ( g 1 , 1) R r dist ( r 7 ) R r dist ( r 6 ) R r dist ( r 5 ) T ( s 3 , 1) T ( s 3 , 2) T ( s 2 , 1) T ( s 2 , 2) T ( s 1 , 1) T ( s 1 , 2) 2 2 2 3 20 20 20 20 20 20 3 20 20 20 20 21 21 Figure 1: An instance R of h| Σ | , m i -AP, with k = 2 and m = 3, a resolution v ector set S 0 and the asso ciated graph G R,S 0 . The thic k edges are a maximum w eight matc hing of G R,S 0 . The corresp onding solution is made of the sets { r 1 , r 2 , r 3 } (cost 0), { r 4 , r 5 } (cost 2), { r 6 , r 7 } (cost 2). Lemma 5. L et M b e a matching of G R,S 0 and let M 1 b e the subset of the e dges of M that have one endp oint in T . Then the total weight of the e dges in M 1 is at le ast W 0 = k P r ∈ S 0 w 0 ( r ) if and only if M is fe asible. Pr o of. Let M 1 b e the subset of the edges of M that ha v e one endp oin t in T , and let W 1 b e the total weigh t of edges in M 1 . An immediate consequence of Lemma 4 is that W 1 = W 0 if and only if M 1 is feasible. Assume no w that M is not feasible, then there exists at least one v ertex S 0 ( x, j ) ∈ T that is not cov ered b y M . Again, a consequence of Lemma 4 is that W 1 ≤ W 0 − w 0 ( x ). Let M 2 b e the set M \ M 1 . By construction, w 0 ( x ) > W and W is an upp er b ound on the total w eight of M 2 , therefore W 1 + w h ( M 2 ) < W 0 , completing the pro of. Using Lemmata 4 and 5, we can pro ve Lemma 6. Lemma 6. L et M b e a maximum weight matching of G R,S 0 , then M is c omplete and the solution Π S 0 ( M ) c ompute d by Algorithm 2 is fe asible. 4.3 Pro ving the optimality of Π S 0 ( M ) This section is devoted to pro ve that, starting from a maximum w eight matc hing M , Algorithm 2 computes an optimal solution Π S 0 ( M ) of h| Σ | , m i -AP. In order to prov e that any maximum weigh t matc hing M of the graph G R,S 0 leads to an optimal solution of h| Σ | , m i -AP ov er instance R , w e are going to prov e that P ( u,v ) ∈ M w h (( u, v )) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e if and only if h| Σ | , m i -AP ov er instance R admits a solution with cost not greater than e , and such solution is computed by applying Algorithm 2. Suc h result will be obtained through a sequence of technical lemmata. 9 Since M is a maximum weigh ted matc hing, we can assume b y Lemma 6 that M is complete. Giv en a complete matc hing M , w e denote b y M ( T ) the set of edges of M with one endpoint in R l dist ∪ R l saf e ∪ R 0 l saf e and one endp oint in T , while w e denote b y M ( L ) the set of those edges of M that hav e one endp oin t in R l dist ∪ R l saf e and one endp oin t in R r dist ∪ R r saf e . F urthermore, let us denote by V ( T ) the set of vertices of R l dist ∪ R l saf e ∪ R 0 l saf e that are endp oints of an edge in M ( T ) and b y V ( L ) the set of v ertices of R l dist ∪ R l saf e that are endp oints of an edge in M ( L ). Notice that b y definition of V ( L ) and, by definition of complete matc hing, V ( T ) ∪ V ( L ) = R l dist ∪ R l saf e ∪ R 0 l saf e . Finally , let us denote by R ( L ) the set of ro ws in R asso ciated with the vertices in V ( L ). Lemma 7 sho ws ho w the w eight of a complete matc hing M is related to the edge w eigh ts of G R,S 0 . Lemma 7. L et M b e a c omplete matching of G R,S 0 , and let w h ( M ) b e the total weight of M . Then w h ( M ) = k P r ∈ S 0 ( W + m − del ( r ) + 1) + P r ∈ R ( L ) ( m − del ( r )) = ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − ( k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r )) . In the next tw o lemmata, w e will sho w that: (i) given an instance R of h| Σ | , m i -AP, if there exists a solution of h| Σ | , m i -AP ov er R that suppresses at most e en tries then the graph G R,S 0 asso ciated with R admits a complete matc hing of G R,S 0 with total w eight w G ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e ; (ii) giv en a complete matching of the graph G R,S 0 of total weigh t w G ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e , Algorithm 2 returns a solution Π S 0 ( M ) of h| Σ | , m i -AP that suppresses at m ost e entries. These lemmata, coupled with Lemma 6, pro ve the correctness of Algorithm 2 in Theorem 10. Lemma 8. L et R b e an instanc e of h| Σ | , m i -AP, let Π S 0 b e a fe asible solution of h| Σ | , m i -AP over instanc e R that suppr esses at most e entries, let G R,S 0 b e the gr aph asso ciate d with R and S 0 . Then ther e exists a c omplete matching of G R,S 0 with total weight w G ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . Lemma 9. L et R b e an instanc e of h| Σ | , m i -AP, let G R,S 0 b e the gr aph asso ciate d with R , and let M b e a c omplete matching of G R,S 0 of weight w h ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . Then, starting fr om the matching M of G R,S 0 , Algorithm 2 c omputes a fe asible solution Π S 0 ( M ) of h| Σ | , m i -AP over instanc e R , wher e ther e ar e at most e suppr essions. Pr o of. Since M is complete, for eac h v ertex T ( x, j ) of T , with 1 ≤ j ≤ k , there exists an edge ( v , T ( x, j )) ∈ M for some v ∈ ( R l dist ∪ R l saf e ∪ R 0 l saf e ). Then Algorithm 2 defines a solution Π S 0 ( M ) for h| Σ | , m i -AP assigning, for eac h edge ( v , T ( x, j )), the row r corresponding to v ertex v to the set that has resolution v ector x . More precisely , ro w r is defined by Algorithm 2 as the j -th elemen t of the set that has resolution v ector x . Therefore each set asso ciated with a resolution ro w x ∈ S 0 will consist of at least k ro ws compatible with x . Hence Π S 0 ( M ) is a feasible solution. Recall that M has a total weigh t of at least ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . W e will prov e that Π S 0 ( M ) induces at most e suppressions. By Lemma 7, w h ( M ) = k P r ∈ S 0 ( W + m − del ( r ) + 1) + P r ∈ R ( L ) m − del ( r ) = ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R l saf e | − ( k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r )) ≥ ( W +1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R l saf e |− e where k P r ∈ S 0 del ( r )+ P r ∈ R ( L ) del ( r ) ≤ e . Notice that, b y definition of Π S 0 ( M ), eac h vertex of V ( T ) corresp onds to a row in R assigned to a set with a resolution vector in S 0 . Suc h ro ws associated with V ( T ) induce a cost in Π S 0 ( M ) of k P r ∈ S 0 del ( r ). F urthermore, the v ertices of V ( L ) corresponds to rows of R inducing a cost of at most P r ∈ R ( L ) del ( r ). Therefore Π S 0 ( M ) induces k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r ) ≤ e suppres- sions. 10 Theorem 10. L et R b e an instanc e of h| Σ | , m i -AP. Then A lgorithm 1 r eturns a solution Π S 0 ( M ) of c ost at most e if and only if such a solution exists. Pr o of. By Lemma 6, Π S 0 ( M ) is feasible. Hence if Π S 0 ( M ) suppresses at most e en tries, then h| Σ | , m i -AP admits a solution of cost at most e . On the other hand, b y Lemma 8, if there exists a solution Π 0 of R that suppresses at most e en tries, then there exists a feasible matching M with w eight w G ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . Then, b y Lemma 9, Algorithm 1 returns a solution Π S 0 ( M ) of h| Σ | , m i -AP that suppresses at most e en tries. If h| Σ | , m i -AP admits a solution that suppresses at most e en tries, then there exists a set S ∗ of resolution vectors suc h that Π S ∗ is a solution for h| Σ | , m i -AP with resolution v ectors S ∗ with the property that Π S ∗ suppresses at most e entries. Now, there exist O (2 ( | Σ | +1) m ) possible sets of resolution vectors and the construction of graph G R,S 0 requires O ( k | S ∗ || R | ) ≤ O ( k e | R | ) ≤ O ( k mn 2 ). A maxim um matc hing M of a bipartite graph can be computed in polynomial time [17] and starting from M , we can compute a solution of the h| Σ | , m i -AP in time O ( | M | ) ≤ O ( m ). Hence the o verall time complexit y of the algorithm is O (2 ( | Σ | +1) m k mn 2 ). 5 APX-hardness of 3 -AP( 3 ) In this section we inv estigate the computational and appro ximation complexit y of 3-AP(3), that is k -AP when each row consists of exactly 3 columns and k = 3. W e show that 3-AP(3) is APX- hard via an L-reduction from Minimum V ertex Cov er on Cubic Graphs (MVCC), whic h is known to be APX-hard [4]. Due to page limit, w e only sk etc h the pro of. The MV CC problem, giv en a cubic graph G = ( V , E ), asks for a smallest C ⊆ V such that each edge of G has at least one of its endp oints in C . Let G = ( V , E ) b e instance of MVCC, where | V | = n and | E | = m . The reduction builds an instance R of 3-AP(3) asso ciating with eac h v ertex v i ∈ V a set R i consisting of 9 rows, and with each edge e = ( v i , v j ) ∈ E a set E i,j consisting of 7 ro ws. Finally , a set X of 3 more ro ws is added to R . No w w e can describ e formally our reduction. Let R i b e the set of rows asso ciated with vertex v i ∈ V . The rows in R i ha ve v alues ov er an alphab et Σ i = { σ i , σ i, 1 , σ i, 2 , σ i, 3 } . The set R i consists of 9 rows b elonging to 6 groups, denoted by g 1 ( v i ) , . . . , g 6 ( v i ), of identical rows. The represen tative rows of groups g 1 ( v i ) , . . . , g 6 ( v i ), and the cardinality of the groups, are defined as follo ws: - r ( g h ( v i )) = σ i,h σ i σ i,h , with h ∈ { 1 , 2 , 3 } ; eac h group g h ( v i ), with h ∈ { 1 , 2 , 3 } , consists of exactly tw o ro ws; - r ( g 3+ h ( v i )) = σ i σ i σ i,h , with h ∈ { 1 , 2 , 3 } ; each group g 3+ h ( v i ), with h ∈ { 1 , 2 , 3 } , consists of exactly one ro w. Notice that given t wo rows r, r 0 b elonging to different groups of R i , H ( r, r 0 ) = 1 iff r ∈ g h ( v i ), r 0 ∈ g 3+ h ( v i ) (or the conv erse) or r, r 0 ∈ { g 4 ( v i ) , g 5 ( v i ) , g 6 ( v i ) } . Giv en a group g h ( v i ), with h ∈ { 1 , 2 , 3 } , each sym b ol σ i,h is called the private symbol of g h ( v i ). The groups of rows g j ( v i ), with j ∈ { 1 , 2 , 3 } , are denoted as the do cking gr oups of R i , and each of them is associated with a set E i,h of rows enco ding an edge ( v i , v h ) of G . More precisely , given the set of ro ws E i,j , we denote by d i,j ( g ( v i )) the do c king group of R i asso ciated with set E i,j . No w, let us build the set E i,j of rows asso ciated with an edge ( v i , v j ). Let d i,j ( g ( v i )) and d i,j ( g ( v j )) b e the t wo do cking groups of R i and R j resp ectiv ely , asso ciated with the set E i,j . 11 Let σ i,x and σ j,y b e the priv ate symbols of groups d i,j ( g ( v i )) and d i,j ( g ( v j )) resp ectively . The set E i,j consists of 7 rows distributed in 6 groups. The ro ws of E i,j ha ve v alues o ver alphabet Σ i,j = { σ i,x , σ j,y , σ i,j , σ i,j, 4 , σ i,j, 5 , σ i,j, 6 } . Let us define the representativ e rows and the cardinality of the groups in E i,j : - r ( g 1 ( v i , v j )) = σ i,x σ i,j σ i,x ; group g 1 ( v i , v j ) consists of a single row; - r ( g 2 ( v i , v j )) = σ i,x σ i,j σ j,y ; group g 2 ( v i , v j ) consists of tw o ro ws; - r ( g 3 ( v i , v j )) = σ j,y σ i,j σ j,y ; group g 3 ( v i , v j ) consists of a single row; - r ( g t ( v i , v j )) = σ i,j,t σ i,j σ i,j,t , with t ∈ { 4 , 5 , 6 } ; eac h group g t ( v i , v j ), with t ∈ { 4 , 5 , 6 } , consists of a single row. The group of E i,j that has tw o o ccurrences of symbol σ i,x shared with d i,j ( g ( v i )) is called the i -group of set E i,j , and is denoted as g i ( v i , v j ). Notice that, given t wo ro ws r, r 0 of R i , E i,j resp ectiv ely , then H ( r, r 0 ) = 1 iff r ∈ d i,j ( g ( v i )) and r 0 ∈ g i ( v i , v j ). Finally , a set X of 3 rows x 1 , x 2 , x 3 are added to R . The rows in X ha ve v alues ov er an alphab et Σ x disjoin t from any other set Σ i , Σ i,j . Each ro w x i = w 3 i , and it has Hamming distance 3 from an y other ro w of R . Therefore for an y set C con taining some rows x i , all p ositions of a ro w in C will b e suppressed. No w, consider the set R i . The following lemma gives a low er b ound on the cost of an optimal solution of 3-AP(3) ov er instance R i . Lemma 11. L et R i b e a set of r ows, then an optimal solution of 3 -AP( 3 ) over instanc e R i has a c ost of at le ast 9 . The main idea of the reduction is showing that w e can consider a set of solutions, called c anonic al solutions , that is solutions where: (i) Π con tains exactly one cluster X con taining only suppressed en tries; (ii) eac h set R i is asso ciated with either a typ e a or a typ e b solution (to b e defined later), ev entually with the con tribution of some ro ws in the sets E i,j for a typ e b solution; (iii) tw o sets R i , R j are asso ciated with a typ e b solution only if there is no edge set E i,j in the instance R , that is the corresp onding vertices v i , v j are not adjacen t in G ; (iv) either an edge set is part of a typ e b solution of some set R i and has a total cost of 10 or it has a total cost of 11. Notice that, b y construction, in a canonical solution, ro ws x 1 , x 2 , x 3 ∈ X . Let us define the notions of typ e a and typ e b solution. Giv en a set R i and the edge sets E i,j , E i,h , E i,l , a typ e a solution for R i consists of three sets S i, 1 , S i, 2 , S i, 3 , where S i,t = g t ( v i ) ∪ g t +3 ( v i ), while a typ e b solution consists of the following sets: (i) three sets d i,j ( g ( v i )) ∪ g i ( v i , v j ), d i,h ( g ( v i )) ∪ g i ( v i , v h ), d i,l ( g ( v i )) ∪ g i ( v i , v l ); (ii) g 4 ( v i ) ∪ g 5 ( v i ) ∪ g 6 ( v i ). Lemma 12 is the main technical contribution of this section. Lemma 12. L et Π b e a solution of 3 -AP( 3 ) over instanc e R . Then we c an c ompute in p olynomial time a c anonic al solution Π 0 of 3 -AP( 3 ) over instanc e R such that c (Π 0 ) ≤ c (Π) . Sketch of the pr o of. By direct insp ection, it is immediate to notice that typ e a and typ e b solutions induce 9 suppression in rows of R i hence, by Lemma 11, they are optimal for R i . The next step is computing in p olynomial time a solution Π 00 suc h that eac h set R i is associated in Π 00 only with either a typ e a or typ e b solution, and such that c (Π 00 ) ≤ c (Π). Such step is obtained by exploiting the optimality of typ e a and typ e b solutions for R i , and some prop erties of the instance R . 12 Then, starting from such solution Π 00 , w e can compute in p olynomial time a canonical solution Π 0 suc h that c (Π 0 ) ≤ c (Π 00 ). The main idea to pro ve this result is that for an y tw o sets R i , R j , suc h that b oth R i and R j are asso ciated with a typ e b solution in Π 00 and E i,j is part of the instance R , then w e can improv e the solution b y imposing a typ e a solution for R i . A consequence of Lemmata 11 and 12 and some prop erties of the instance R , is Lemma 13. Lemma 13. L et Π b e a solution of 3 -AP( 3 ) over instanc e R of c ost 6 | V | + 3 | C | + 11 | E | + 9 , then we c an c ompute in p olynomial time a solution of MVCC over instanc e G of size C . Pr o of. Let us consider a canonical solution of 3-AP(3). First ,notice that the three rows w 1 , w 2 , w 3 pro vide together a cost of 9. Since t wo sets of rows are asso ciated with a typ e b solution only if there do es not exist a set E i,j , on the contrary , given an edge set E i,j at least one of the set R i and R j is asso ciated with a typ e a solution. Consequently , the set of ro ws asso ciated with a typ e a solution corresponds to a v ertex co ver of the graph G . No w consider the cost of a canonical solution. F or eac h set R i of rows asso ciated with a typ e b solution, we can sho w that each of the three edge sets E i,j , E i,h , E i,l has a cost of 10. Notice that, given an edge set E i,j , if b oth sets R i , R j are asso ciated with typ e a solutions, then we can sho w that the edge set E i,j has a cost of 11. Accounting this decreasing of the cost of the edge sets to the set R i of rows with a typ e b solution, is equiv alent to assign to a typ e b solution a cost equal to 6, while a typ e a solution has a cost equal to 9. Similarly to Lemma 13, we can prov e that starting from a solution C of MV CC ov er instance G , w e can compute in polynomial time a solution Π of 3-AP(3) o ver instance R of cost 6 | V | + 3 | C | + 11 | E | + 9. Therefore 3-AP(3) is APX-hard. References [1] G. Aggarwal, T. F eder, K. Kenthapadi, S. Khuller, R. P anigrahy , D. Thomas, and A. Zhu. Ac hieving anon ymity via clustering. In PODS , pages 153–162. 2006. [2] G. Aggarwal, T. F eder, K. Ken thapadi, R. Motw ani, R. Panigrah y , D. Thomas, and A. Zhu. Anon ymiz- ing tables. In ICDT , LNCS 3363, pages 246–258. 2005. [3] G. Aggarw al, K. Ken thapadi, R. Motw ani, R. Panigrah y , D. Thomas, and A. Zh u. Approximation algorithms for k-anonymit y . J. Privacy T e chnolo gy , 2005. [4] P . Alimon ti and V. Kann. Some APX-completeness results for cubic graphs. The or etic al Computer Scienc e , 237(1–2):123–134, 2000. [5] G. Ausiello, P . Crescenzi, V. Gam b osi, G. Kann, A. Marchetti-Spaccamela, and M. Protasi. Com- plexity and Appr oximation: Combinatorial optimization pr oblems and their appr oximability pr op erties . Springer-V erlag, 1999. [6] P . Bonizzoni, G. Della V edo v a, and R. Dondi. The k-anon ymity problem is hard. In F CT , LNCS 5699, pages 26–37. 2009. [7] R. Cha ytor, P . A. Ev ans, and T. W areham. Fixed-parameter tractability of anonymizing data by suppressing entries. J. Comb. Optim. , 18(4): 362-375, 2009. [8] R. Downey and M. F ellows. Par ameterize d Complexity . Springer V erlag, 1999. [9] R. G. Downey and M. R. F ellows. Fixed-parameter tractability and completeness ii: On completeness for W [1]. The or etic al Computer Scienc e , 141(1&2):109–131, 1995. 13 [10] W. Du, D. Eppstein, M. T. Goo drich, and G. S. Lueker. On the appro ximabilit y of geometric and geographic generalization and the min-max bin cov ering problem. In W ADS , LNCS 5664, pages 242–253. 2009. [11] A. Gionis and T. T assa. k -anonymization with minimal loss of information. TKDD , 21(2): 206-219, 2009. [12] A. Meyerson, R. Williams. On the complexit y of optimal K-anon ymity . In PODS , pages 223–228. 2004. [13] R. Niedermeier. Invitation to Fixe d-Par ameter Algorithms . Oxford Universit y Press, 2006. [14] H. Park and K. Shim. Approximate algorithms for k-anonymit y . In SIGMOD , pages 67–78. 2007. [15] P . Samarati. Protecting resp ondents’ iden tities in micro data release. TKDD , 13:1010–1027, 2001. [16] P . Samarati and L. Sw eeney . Generalizing data to provide anon ymity when disclosing information (abstract). In PODS , page 188. 1998. [17] J. Sch wartz, A. Steger and A. W eissl, F ast algorithms for w eighted bipartite matc hing. In WEA , pages 476–487, 2005. [18] L. Sweeney . k-anonymit y: a mo del for protecting priv acy . International Journal on Unc ertainty, F uzziness and Know le dge-b ase d Systems , 10(5):557–570, 2002. 14 App endix Pro ofs of Section 3 Pro of of Lemma 1 Lemma 14. L et R b e the instanc e of h e i -AP asso ciate d with G and c onsider two r ows r, r x ( i, j ) of R , such that r ∈ R 0 and r x ( i, j ) ∈ R ( i, j ) . Then, r [ t ] 6 = r x ( i, j )[ t ] , for e ach 1 ≤ t ≤ 2 h . Pr o of. By construction, r [ t ] = 0 for all t with 1 ≤ t ≤ 2 h , while r x ( i, j )[ t ] = σ i,j . Pro of of Lemma 2 Lemma 15. L et G = ( V , E ) b e a gr aph, let V 0 b e a h -clique of G and let R b e the instanc e of h e i -AP asso ciate d with G . Then we c an c ompute in p olynomial time a solution Π of h e i -AP over instanc e R with c ost at most 6 h 3 . Pr o of. Initially let Π 0 b e a solution consisting of clusters R 0 , R ( i, j ), for each R ( i, j ) ∈ R . F or each R ( i, j ), let r 1 ( i, j ) b e the first row of R ( i, j ). Compute a new solution Π consisting of clusters R 0 0 , R 0 ( i, j ), for eac h R ( i, j ) ∈ R , where: • R 0 ( i, j ) = R ( i, j ) \ { r 1 ( i, j ) } , for each v i , v j ∈ V 0 ; • R 0 ( i, j ) = R ( i, j ), for v i / ∈ V 0 or v j / ∈ V 0 ; • R 0 0 = R 0 S R ( i,j ) ∈ R ( R 0 ( i, j ) \ R ( i, j )) Notice that, since V 0 is a h -clique, | R 0 0 | = k . Moreov er, by construction, | R ( i, j ) | ≥ | R 0 ( i, j ) | ≥ | R ( i, j ) | − 1, therefore Π is a feasible solution for R . Notice also that no en tries is suppressed in the ro ws of eac h set R 0 ( i, j ), therefore to determine the cost of Π 0 it suffices to determine the num b er of entries deleted in R 0 0 , and we will show that such num b er is exactly 6 h 3 . Indeed, by construction, for each column t of the first 2 h columns, and for each row r ∈ R 0 and r x ( i, j ) ∈ R ( i, j ), r [ t ] 6 = r x ( i, j )[ t ], hence all the en tries of the first 2 h columns of the ro ws in R 0 0 m ust be deleted, resulting in 2 hk suppressions. No w let us consider the columns with index 2 h + 1 ≤ t ≤ 2 h + n and v t ∈ V 0 . In such p ositions, all ro ws of R 0 are equal to 0, while all rows in the sets R ( y , t ), R ( t, y ) are equal to 1. Consider the h ( h − 1) 2 of R 0 0 \ R 0 . As the corresp onding edges are incident on a set of h vertex, b y construction there exists a set H of exactly h columns, with H = { t : 2 h + 1 ≤ t ≤ 2 h + n } , where at least one of the ro ws in R 0 0 \ R 0 is equal to 1, while the ro ws in R 0 are all equal to 0. Since in any other column all ro ws in R 0 0 ha ve v alue equal to 0, hence there are additional hk suppressions for the columns with index 2 h + 1 ≤ t ≤ 2 h + n . Ov erall, the num b er of suppressions is 3 hk whic h, b y the c hoice of k is equal to 6 h 3 . Pro ofs of Section 4 Pro of of Lemma 6 Lemma 16. L et M b e a maximum weight matching of G R,S 0 , then the solution Π S 0 ( M ) c ompute d by A lgorithm 2 is fe asible. Lemma 6 is a consequence of Lemmata 19 and 17. Lemma 17. L et M b e a maximum weight matching of G R,S 0 , then M is a fe asible matching. Pr o of. First notice that, as M is feasible, each v ertex of T is cov ered and eac h vertex R l saf e ( r , j ), with 1 ≤ j ≤ k , is cov ered b y M . Assume that M is not complete and that a vertex R l dist ( r ) of R l dist (resp. R l saf e ( r , k + j ), with 1 ≤ j ≤ exc ( g ), of R l saf e ) is not matc hed. Then, by construction, also the vertex 15 R r dist ( r ) of R r dist (resp. R r saf e ( r , j ) of R r saf e ) is not cov ered by M , as R l dist ( r ) (resp. R l saf e ( r , k + j )) is the only v ertex adjacent to R r dist ( r ) (resp. R r saf e ( r , j )) in G R,S 0 . Hence we can compute the matc hing M 0 b y adding all the edges of M to M 0 and b y adding edges ( R l dist ( r ) , R r dist ( r )), (resp. ( R l saf e ( r , k + j ) , R r saf e ( r , j ))) for each vertex R l dist ( r ) (resp. R l saf e ( r , k + j )) not cov ered by M . Lemma 18. L et M b e a fe asible matching of G R,S 0 , if M is not c omplete, then we c an c ompute in p olynomial time a c omplete matching M 0 , such that w h ( M 0 ) > w h ( M ) . As a consequence of Lemma 18, we assume in what follo ws that an y matching M is complete. F ur- thermore, we can prov e the follo wing result. Lemma 19. L et M b e a c omplete matching of G R,S 0 . Then A lgorithm 2 c omputes in p olynomial time a fe asible clustering Π S 0 ( M ) . Pr o of. Since Π S 0 ( M ) feasible, all vertices in T are cov ered by M . F urthermore, w e can assume, by Lemma 18, that each v ertex in R l dist ∪ R l saf e is cov ered by M . Hence eac h ro w in R is assigned by Algorithm 2 to a set whose resolution v ector is S 0 . F urthermore Algorithm 2 assigns to eac h set with resolution vector x ∈ S 0 at least k ro ws. Hence the clustering Π S 0 ( M ) computed by Algorithm 2 is feasible. Pro of of Lemma 7 Lemma 20. L et M b e a c omplete matching of G R,S 0 , then the total weight of M , w h ( M ) , is e qual to k P r ∈ S 0 ( W + m − del ( r ) + 1) + P r ∈ R ( L ) ( m − del ( r )) = ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e | − ( k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r )) . Pr o of. The total weigh t w h ( M ) of the matching M is defined as w h ( M ) = X ( u,v ) ∈ M ( T ) w h (( u, v )) + X ( u,v ) ∈ M ( L ) w h ( u, v ) . By Lemma 5 and by definition of the weigh t function w h , it follows that w h ( M ) = k X r ∈ S 0 w 0 ( r ) + X r ∈ R ( L ) ( m − del ( r )) and by definition of w 0 ( r ) it holds w h ( M ) = k X r ∈ S 0 ( W + m − del ( r ) + 1) + X r ∈ R ( L ) ( m − del ( r )) . Hence w h ( M ) = ( W + m + 1) k | S 0 | − k X r ∈ S 0 del ( r ) + X r ∈ R ( L ) m − X r ∈ R ( L ) del ( r ) . By definition of feasible matching and b y Lemma 18, | V ( T ) | = | T | . F urthermore, since | T | = k | S 0 | , then mk | S 0 | = m | T | = m | V ( T ) | . By construction P r ∈ R ( L ) m = m | V ( L ) | and V ( T ) ∪ V ( L ) = R l dist ∪ R l saf e . Hence w h ( M ) = ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e | − ( k X r ∈ S 0 del ( r ) + X r ∈ R ( L ) del ( r )) . 16 Pro of of Lemma 8 Lemma 21. L et R b e an instanc e of h| Σ | , m i -AP, let Π S 0 b e a fe asible solution of h| Σ | , m i -AP over instanc e R that suppr esses at most e entries, let G R,S 0 b e the gr aph asso ciate d with R and S 0 . Then ther e exists a c omplete matching of G R,S 0 with total weight w G ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . Pr o of. Since Π S 0 is feasible, we notice that each set of Π S 0 asso ciated with a resolution vector r ∈ S 0 m ust ha ve cardinalit y at least k . F urthermore, we assume that all the sets of Π S 0 are all associated with differen t resolution vectors, otherwise w e can merge all the sets with the same resolution vector without increasing the cost of Π S 0 . Let x be a row of S 0 and denote b y R x ⊆ R the set of rows of R assigned to the set associated with resolution vector x . Starting from Π S 0 w e compute incrementally a matc hing M by adding edges. First, for each set of vertices T ( x, i ), 1 ≤ i ≤ k , let i ∗ b e the minimum n umber such that T ( x, i ∗ ) do es not ha ve an y edge incident on it in M . First, assume that x ∈ S 0 saf e ; add the edge ( R 0 l saf e ( g , i ) , T ( x, i )) to M , for eac h 1 ≤ i ≤ k . Now, assume that x ∈ S 0 cost . Scan the ro ws in R x and for eac h ro w r in R x , if r ∈ R dist add the edge ( R l dist ( r ) , T ( x, i ∗ )) to M . If r ∈ R saf e and b elongs to group g add the edge ( R l saf e ( g , i ) , T ( x, i ∗ )) to M . If no suc h T ( x, i ∗ ) exists, then no edge is added to M . Notice that by construction, since all sets in S 0 ha ve at least k ro ws, then all vertices of T are cov ered by M , therefore M is feasible. Finally add to M all edges ( R l dist ( x ) , R r dist ( x )), ( R l saf e ( g , i ) , R r saf e ( g , i )), 1 ≤ i ≤ exc ( g ), for eac h vertex in { R l dist , R l saf e } resp ectively that is not already cov ered in M . Hence M is complete. Giv en a solution Π S 0 , a resolution v ector x of S 0 and the corresp onding matching M , consider the order in whic h the rows of a set R x are scanned sequen tially to construct M . Each of the first k rows assigned to a cluster with resolution vector equal to x , by construction corresp onds to an edge of M joining a v ertex of V ( T ) and a vertex of T . Since M is complete, those ro ws ha ve a total cost in Π S 0 of k P r ∈ S 0 del ( r ). The remaining rows of R corresp ond to v ertices of V ( L ). Notice that those ro ws ha ve a total cost in Π S 0 not larger than P r ∈ R ( L ) del ( r ). By Lemma 7 w h ( M ) = ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − ( k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r )). Since Π S 0 suppresses at most e entries of R , then e ≤ k P r ∈ S 0 del ( r ) + P r ∈ R ( L ) del ( r ), therefore w h ( M ) ≥ ( W + 1) k | S 0 | + m | R l dist ∪ R l saf e ∪ R 0 l saf e | − e . Pro ofs of Section 5 It is easy to see that, by construction, the following prop erties hold. Prop osition 22. L et r a , r b b e two r ows of R i , with r a = g j ( v i ) and r b = g l ( v i ) , j < l . L et r c b e a r ow of R j , with i 6 = j . Then: • H ( r a , r c ) = H ( r b , r c ) = 3 ; • H ( r a , r b ) ≤ 2 ; • H ( r a , r b ) = 1 iff r a = g h ( v i ) and r b = g h +3 ( v i ) , with 1 ≤ h ≤ 3 , or r a = g h ( v i ) and r b = g l ( v i ) , with 4 ≤ j ≤ l ≤ 6 . Prop osition 23. L et r a , r b b e two r ows of E i,j , with r a ∈ g h ( v i , v j ) and r b ∈ g l ( v i , v j ) , with h < l . L et r c , r d b e two r ows of R i and R p , with p 6 = i, j , and let r e b e a r ow of E t,z , with t 6 = i or z 6 = j . Then: • H ( r a , r b ) ≤ 2 ; • H ( r a , r b ) = 1 iff r a = g h ( v i , v j ) and r b = g h +1 ( v i , v j ) , with 1 ≤ h ≤ 2 ; • H ( r a , r c ) = 1 iff r c is in the do cking gr oup d i,j ( g ( v i )) of R i and r a is in the gr oup g i ( v i , v j ) ; • H ( r a , r c ) = 2 only if r c is in a gr oup adjac ent to d i,j ( g ( v i )) ; • H ( r a , r d ) = 3 ; • H ( r a , r e ) = 3 . 17 In what follo ws, b y an abuse of notation, we may use a group g ( · ) to denote its representativ e row r g ( · ). Fig. 5 shows the groups of R i , R j , E i,j . Each group of identical rows si represen ted with a v ertex, while an edge joins tw o vertices iff the corresp onding groups are at Hamming distance 1. g (v ) 4 j g (v ) 5 j g (v ) 2 j g (v ) 6 j g (v ) 3 j g (v ) 1 j g (v , v ) j 1 i g (v , v ) j 3 i g (v , v ) j 2 i g (v ) 1 i g (v ) 4 i g (v ) 5 i g (v ) 2 i g (v ) 3 i g (v ) 6 i g (v , v ) j 4 i g (v , v ) j 5 i g (v , v ) j 6 i R R i j E i,j Figure 2: Groups at Hamming distance 1 in R i , R j , E i,j : v ertices represent groups, while an e dge joins tw o v ertices represen ting groups at Hamming distance 1. Pro of of Lemma 11 Lemma 24. L et R i b e a set of r ows, then an optimal solution of 3 -AP( 3 ) over instanc e R i has a c ost of at le ast 9 . Pr o of. Let us consider the set of 9 rows, distributed in 6 groups, of R i . As none of the group of R i consists of at least 3 rows, it follows that any solution of 3-AP(3) suppresses at least one entry in each row of R i , hence the lemma follo ws. Pro of of Lemma 12 In order to pro ve Lemma 12, first we hav e to show some prop erties of a canonical solution. Lemma 25. L et R i b e a set of r ows. Then a solution of 3 -AP( 3 ) over instanc e R induc es an optimal c ost for the set R i if it is a type a solution. Pr o of. By construction, a typ e a solution is an optimal solution o v er instance R i , as eac h ro w has a cost of 1 in a typ e a solution. No w, in Lemma 26, we will prov e a prop erty of a typ e b solution ov er the sets R i , E i,j , E i,h , E i,k . Lemma 26. L et S b e a type b solution of 3 -AP( 3 ) over instanc e R i ∪ E i,j ∪ E i,h ∪ E i,k , then S suppr esses 9 entries in the r ows of R i , and 1 entry for e ach r ow of g i ( v i , v j ) , g i ( v i , v h ) , g i ( v i , v k ) . Pr o of. By construction each set of a typ e b solution con taining a do cking group of R i consists of three ro ws, where exactly one p osition is suppressed for each ro w by Prop. 23. The cluster g 4 ( v i ) ∪ g 5 ( v i ) ∪ g 6 ( v i ) consists of 3 rows, where exactly one p osition is suppressed for each row. By a simple counting argument, the rows of R i ha ve a total cost of 9. Let Π b e a solution of 3-AP(3) ov er instance R and let E i,j b e an edge set. Then w e say that Π induce an i-normal solution for E i,j if it con tains the follo wing three sets: (i) one set clusters C 1 = g i ( v i , v j ) ∪ d i,j ( v i ), (ii) one set containing C 2 ⊇ S t ∈{ 4 , 5 , 6 } g t ( v i , v j ), such that exactly tw o en tries (in columns 1 and 3) are suppressed in the ro ws of C 2 , (iii) set C 3 = g 2 ( v i , v j ) ∪ g j ( v i , v j ). 18 Lemma 27. L et Π b e a solution of 3 -AP( 3 ) over instanc e R and let E i,j b e an e dge set, then Π suppr esses at most 10 entries in the r ows of E i,j only if it induc es an i-normal or j-normal solution for E i,j . Pr o of. First assume that Π induces an i-normal solution for E i,j . By Prop. 23, it follo ws that one en try of g i ( v i , v j ) is suppressed. In the set consisting of the rows in g t ( v i , v j ), with t ∈ { 4 , 5 , 6 } , b y Prop. 23 tw o p ositions for each row are suppressed. Finally , b y Prop. 23, in the set g 2 ( v i , v j ) ∪ g j ( v i , v j ), exactly one p osition is suppressed for each row. No w, let us prov e that if Π is a solution that is not i-normal or j-normal for E i,j , then c Π ( E i,j ) ≥ 11. Notice that that each row in g t ( v i , v j ), with t ∈ { 4 , 5 , 6 } , has a Hamming distance 2 from an y other ro w of R \ g t ( v i , v j ), hence at least tw o en tries are suppressed in eac h solution Π. F urthermore, notice that eac h of the four ro ws in the groups g 1 ( v i , v j ), g 2 ( v i , v j ), g 3 ( v i , v j ) m ust hav e a cost of at most 1. But then, the rows of g 2 ( v i , v j ) must be co-clustered with the row of exactly one of g 1 ( v i , v j ), g 3 ( v i , v j ) (w.l.o.g. g 1 ( v i , v j )). But then g 3 ( v i , v j ) = g i ( v i , v j ), must b e co-clustered with d i,j ( v i ). Lemma 28. L et S b e a solution of 3 -AP( 3 ) over instanc e R , then we c an c ompute in p olynomial time a solution S 0 such that c ( S 0 ) ≤ c ( S ) and S 0 c ontains at most one set suppr essing thr e e entries for e ach r ow. Pr o of. Assume that solution S con tains sets Y 1 , . . . , Y p , with p ≥ 2, suc h that all the p ositions of the ro ws in Y j are suppressed. Then we can compute in p olynomial time a solution S 0 b y merging the set Y 1 , . . . , Y p in a single cluster Y . Notice that c ( S 0 ) ≤ c ( S ), as in b oth solution S 0 and S three p ositions are suppressed for each row r ∈ S j =1 ...p Y j . No w, let us first introduce some prop erties of a solution of 3-AP(3) o ver instance R . Lemma 29. L et Π b e a solution of 3 -AP( 3 ) over instanc e R , we c an c ompute in p olynomial time a solution Π 0 such that 1. for e ach e dge set E i,j , Π 0 has a set S i,j c ontaining the r ows of gr oups S t =4 , 5 , 6 g t ( v i , v z ) , such that for e ach r ow in S i,j exactly two c olumns (c olumns 1 and 3 ) ar e supprsse d; 2. c (Π 0 ) ≤ c (Π) . Pr o of. First, notice that by Prop. 23 the ro ws in the groups ∪ t =4 , 5 , 6 g t ( v i , v j ) hav e distance smaller than 3 only w.r.t. rows of E i,j . F urthermore, notice that, by construction, each row in S t =4 , 5 , 6 g t ( v i , v j ) ma y b e equal to another ro w of R only in the second p osition. Assume that there exist clusters S 1 , S 2 , S 3 (at most one of these clusters can be empty) con taining the rows of S t =4 , 5 , 6 g t ( v i , v j ), such that at most tw o en tries are suppressed for each row of the cluster S j , j ∈ { 1 , 2 , 3 } . Then, for each ro w in S 1 ∪ S 2 ∪ S 3 , the positions 1 and 3 are suppressed. Hence, w e can merge clusters S 1 , S 2 , S 3 , without increasing the cost of the solution, obtaining one set that con tains the ro ws S t =4 , 5 , 6 g t ( v i , v z ). Assume that some rows of ∪ t =4 , 5 , 6 g t ( v i , v j ) are in the cluster X and some rows of ∪ t =4 , 5 , 6 g t ( v i , v j ) are in a different cluster Y , such that at most tw o entries are suppressed for each ro w of the cluster Y . Then w e can mo ve the ro ws of ∪ t =4 , 5 , 6 g t ( v i , v j ) ∩ X to Y , decreasing the cost of the solution. No w, assume that these rows are all clustered in set X . It follo ws that eac h ro w of ∪ t =4 , 5 , 6 g t ( v i , v j ) ha ve a cost of 3. Hence, we can mov e this set of rows to a new set ∪ t =4 , 5 , 6 g t ( v i , v j ), decreasing the cost of the solution. Lemma 30. L et R i , R j b e two set of r ows and let E i,j b e an e dge set of R . L et Π b e a solution of 3 -AP( 3 ) over instanc e R that asso ciates a type b solution with b oth R i , R j . Then we c an c ompute in p olynomial time a solution Π 0 of 3 -AP( 3 ) over instanc e R wher e exactly one of R i , R j is asso ciate d with a t yp e b solution and such that c (Π 0 ) ≤ c (Π) . Pr o of. Notice that, by Prop. 23, the rows of group g 2 ( v i , v j ) hav e Hamming distance 1 only from the rows of g 1 ( v i , v j ) and g 3 ( v i , v j ). Since in a typ e b solution the rows of g 1 ( v i , v j ) and g 3 ( v i , v j ) are co-clustered with rows of R i and R j , it follows b y Prop. 23 that the rows of g 2 ( v i , v j ) are co-clustered in Π with rows at 19 Hamming distance at least 2. Hence, Π suppresses tw o entries in each ro w of g 2 ( v i , v j ), and, as g 2 ( v i , v j ) consists of 2 rows, at least 4 en tries of rows in g 2 ( v i , v j ) are suppressed in Π. Notice that, as R i and R j are asso ciated with typ e b solutions in Π, the only ro ws that can be clustered with the ro ws of g 2 ( v i , v j ) are those of groups g 4 ( v i , v j ), g 5 ( v i , v j ), g 6 ( v i , v j ). Starting from solution Π, let us compute a solution Π 0 of 3-AP(3) ov er instance R as follo ws. Let E i,j , E i,t , E i,z b e the edge sets associated with the three edges incident in v i . Mo dify solution Π s o that Π 0 induces a typ e a solution for R i , and a j-normal solution for E i,j . Moreov er, for eac h row of a group g i ( v i , v z ) of an edge set E i,z , with z 6 = j , co-cluster suc h group g i ( v i , v z ) with the cluster con taining the ro ws of S t =4 , 5 , 6 g t ( v i , v z ). By Lemma 27 the rows of edge set E i,j ha ve a total cost of 10. Notice that by Lemma 29, we can assume that Π has a set C containing S t =4 , 5 , 6 g t ( v i , v z ), suc h that exactly tw o en tries (corresponding to the p ositions 1 and 3) are suppressed for eac h row in C . Hence the representativ e row of C has Hamming distance 2 from g i ( v i , v z ), as they are equal in p osition 2. No w, each of these tw o rows g i ( v i , v z ) has a cost of 2 in Π 0 , while it has a cost of least 1 in Π. Notice that each of the t wo ro ws of g 2 ( v i , v j ) has a cost of at least 2 in Π, while it has a cost of 1 in Π 0 . Hence, c (Π 0 ) ≤ c (Π). Lemma 31. L et Π b e a solution of the 3 -AP( 3 ) over instanc e R , such that two sets R i , R j ar e not asso ciate d with a type b solution in Π and Π induc es a total c ost of 10 for the r ows in E i,j . Then at le ast one of R i , R j has c ost 11 . Pr o of. Assume that Π induces a total cost of 10 for the rows in E i,j . Notice that the rows in S t =4 , 5 , 6 g t ( v i , v j ) ha ve a total cost of 6, as by Prop. 23 they are at Hamming distance at least 2 from an y other ro w of R . F urthermore, the 4 rows of E i,j \ S t =4 , 5 , 6 g t ( v i , v j ) m ust hav e a cost of at least 1 in Π. Notice that, b y Lemma 27, Π induces either an i-normal or j-normal solution for E i,j (w.l.o.g. w e assume that is i-normal). Hence g i ( v i , v j ) is clustered with the rows of d i,j ( v i )), while of g j ( v i , v j ) is clustered with g 2 ( v i , v j ), other- wise some rows of g 2 ( v i , v j ) are clustered in Π with a row at Hamming distance at least 2, hence the total cost of the rows in E i,j is greater than 10. But then, we claim that Π induces a cost of at least 11 for the ro ws of the set R i . No w, recall that by hypothesis R i is not asso ciated with a typ e b solution in Π, and let us consider the clusters con taining ro ws of R i in Π. Notice that if at least t w o ro ws of R i are clustered with some ro ws at Hamming distance at least 2, then Π induces a cost of at least 11 for the set R i . Recall that group d i,j ( g ( v i )) of R i is clustered only with ro ws of group g i ( v i , v j ) of E i,j , and consider the cases that either the three groups of ro ws in g 4 ( v i ) , g 5 ( v i ) , g 6 ( v i ) are co-clustered, or not. In the former case, as R i is not asso ciated with a typ e b solution, it follows that the ro ws of at least one of the docking group of R i are clustered with rows at Hamming distance 2; hence Π induces a cost of at least 11 for the set R i . In the latter case, let us consider the group of R i (w.l.o.g. g 4 ( v i )) adjacen t to d i,j ( g ( v i )) and let C be the cluster con taining the unique ro w of g 4 ( v i ). As the rows in g 4 ( v i ) , g 5 ( v i ) , g 6 ( v i ) are not co-clustered, it follo ws that C contains a row r at Hamming distance at least 2 from g 4 ( v i ). If r ∈ R i , then Π suppresses at least t wo entries of tw o rows of R i , namely r and g 4 ( v i ), hence Π induces a cost of at least 11 in rows of R i . If r / ∈ R i , then r must b e a ro w at Hamming distance 3 from g 4 ( v i ). Indeed b y Prop. 22 and b y Prop. 23, the rows at Hamming distance not greater than 2 from g 4 ( v i ) b elong to R i ∪ ( E i,j \ S t =4 , 5 , 6 g t ( v i , v j )). W e hav e assumed that ( R i \ { g 4 ( v i ) } ) ∩ C = ∅ , and it m ust be ( E i,j \ S t =4 , 5 , 6 g t ( v i , v j )) ∩ C = ∅ , since b y h yp othesis Π induces an i-normal solution for the rows in E i,j . Hence g 4 ( v i ) must hav e cost equal to 3 and must b e part of the cluster X in Π b y the Lemma 28. It follo ws that Π induces a cost of at least 11 for the set R i . No w, let us prov e Lemma 12. Lemma 32. L et Π b e a solution of 3 -AP( 3 ) over instanc e R . Then we c an c ompute in p olynomial time a c anonic al solution Π 0 of 3 -AP( 3 ) over instanc e R such that c (Π 0 ) ≤ c (Π) . 20 Pr o of. Let us consider the solution Π. Before computing a canonical solution Π 0 , w e compute an interme- diate solution Π 00 suc h that c (Π 00 ) ≤ c (Π) as follo ws. First, for each set R i , if R i is associated with a typ e b solution in Π, then define a typ e b solution for R i in Π 00 . Otherwise, if eac h docking v ertices d i,j ( v i ) of a set R i is clustered in Π with the row of group g i ( v i , v j ) o f E i,j , then define a typ e b solution for R i in Π 00 ; else define a typ e a solution for R i in Π 00 . F urthermore, define a set con taining row x 1 , x 2 , x 3 in Π 00 . Next, consider the ro ws of an edge set E i,j , and define a clustering of the ro ws not y et clustered in Π 00 . If exactly one of R i , R j (w.l.o.g. R i ) is asso ciated with a typ e b solution in Π 00 , then define an i-normal solution for E i,j in Π 00 . Else if at least one of R i , R j (w.l.o.g. R i ) is asso ciated with a typ e a solution in Π 00 , then define the following solution: one set contains the ro ws in g i ( v i , v j ) ∪ g 2 ( v i , v j ); one set contains the rows in S t =4 , 5 , 6 ( g t ( v i , v j )) ∪ g j ( v i , v j ). If b oth R i , R j are asso ciated with a typ e b solution in Π 00 , then define a set S t =4 , 5 , 6 ( g t ( v i , v j )) ∪ g 2 ( v i , v j ) in Π 00 . No w, let us show that c (Π) ≥ c (Π 00 ). By Lemma 25 and by Lemma 26 it follows that for eac h row in a set R i the cost in Π 00 is optimal. F urthermore, b y Lemma 28, w e can assume that Π contains a set X ⊇ { x 1 , x 2 , x 3 } , hence the rows in { x 1 , x 2 , x 3 } ha ve all cost 3 in b oth Π and Π 00 . Hence it remains to consider the cost of the edge set E i,j . Let E i,j b e an edge set. Notice that by Lemma 29 we can assume that Π con tains a set S i,j ⊇ S t =4 , 5 , 6 g t ( v i , v j ), and by construction Π 00 con tains a set S 0 i,j ⊇ S t =4 , 5 , 6 g t ( v i , v j ). Hence each row of g t ( v i , v j ), with t ∈ { 4 , 5 , 6 } , has a cost equal to 2 in b oth Π, Π 00 . Let us consider the case when b oth sets R i and R j are associated with a typ e b solution in both Π and Π 00 . The groups of E i,j not co-clustered in a typ e b solution of R i , R j , are g 2 ( v i , v j ), g 4 ( v i , v j ), g 5 ( v i , v j ), g 6 ( v i , v j ). By construction, as the ro ws at Hamming distance 1 from g 2 ( v i , v j ) are clustered in the typ e b solution of R i , R j in Π (hence cannot b e co-clustered with g 2 ( v i , v j )), it follo ws that the ro ws g 2 ( v i , v j ) m ust be clustered with a row having Hamming distance at least 2 in Π. As Π 00 con tains the set S 00 i,j = ( S t =4 , 5 , 6 g t ( v i , v j )) ∪ g 2 ( v i , v j ) and as Π con tains the set S i,j ⊇ S t =4 , 5 , 6 g t ( v i , v j ), it follows that the cost of the rows in E i,j in solution Π is greater or equal than the cost of the rows in E i,j in solution Π 00 . Let us consider the case when exactly one of the sets R i and R j (w.l.o.g. R j ) is asso ciated with a typ e b solution in Π 00 and in Π. By construction, R i is asso ciated with a typ e a solution in Π 00 . By Lemma 27 it follows that that c Π 00 ( E i,j ) = 10, and, as each ro w in S t =4 , 5 , 6 g t ( v i , v j ) has a cost of 2 in Π 00 , it follows that eac h row in E i,j \ ( S t =4 , 5 , 6 g t ( v i , v j )) has a cost of 1 in Π 00 . As Π contains the set S i,j , it follows that Π suppresses tw o entries in the rows of S t =4 , 5 , 6 g t ( v i , v j ), hence the cost of the ro ws in E i,j in solution Π is greater or equal than the cost of the rows in E i,j in solution Π 00 . Let us consider the case when at least one of the sets R i and R j (w.l.o.g. R i ) is associated with a typ e b solution in Π 00 and not in Π. Notice that by construction, the rows in groups d i,j ( v i ), g i ( v j , v j ) are clustered in b oth Π and Π 00 . Now, if Π induces a cost of at least 11 for the rows in E i,j , since Π 00 induces a cost of at most 11 for the ro ws in E i,j it follows that c Π ( E i,j ) ≥ c Π 00 ( E i,j ). If Π induces a cost of 10 for the rows in E i,j , then b y Prop. 23 g 2 ( v i , v j ) must b e co-clustered with g j ( v i , v j ). Then, it follows that by construction R j is asso ciated with a typ e a solution in Π 00 and that the rows of E i,j ha ve a total cost of 10 in Π 00 . Hence c Π ( E i,j ) ≥ c Π 00 ( E i,j ). No w, let us consider the case when both R i , R j , are associated with a typ e a solution in Π 00 . In this case, b y construction, the ro ws in the edge set E i,j ha ve a total cost of 11 in Π 00 , while they hav e a cost of at least 10 in Π, as the ro ws in S t =4 , 5 , 6 g t ( v i , v j ) (con tained in the set S i,j of Π) ha v e a total cost of 6, while eac h of the 4 rows of E i,j \ S t =4 , 5 , 6 g t ( v i , v j ) has a cost of at least 1 in Π. Assume that the rows of E i,j ha ve a total cost of 10 in Π. By Lemma 31, Π induces a total cost of 11 for the rows of one of the sets R i , R j (w.l.o.g. R i ). Notice that b y Lemma 25 Π 00 induces a cost of 9 for all the set R i . Now, let us consider the set R i and the three edge sets E i,j , E i,h , E i,k . In what follo ws, w e will consider the cost induced b y Π and by Π 00 in the set R i and in some of the edge sets E i,j , E i,h , E i,k . More precisely , for each edge set E i,x in { E i,j , E i,h , E i,k } , let us consider its cost together with the cost of R i only if d i,x ( v i ) and g i ( v i , v x ) are clustered in Π (otherwise E i,x will b e even tually b e considered together with R x ). By construction the cost of at most t wo edge sets in E i,j , E i,h , E i,k (assume w.l.o.g. E i,j , E i,h ) are considered together with the cost of R i , otherwise d i,x ( v i ) and g i ( v i , v x ) w ould b e co-custered in Π, for eac h x ∈ { j , h, k } and by construction R i w ould b e asso ciated with a typ e b solution in Π 00 . Since c Π ( E i,j ) ≥ 10, c Π ( E i,h ) ≥ 10, c Π ( R i ) ≥ 11, while c Π 00 ( E i,j ) = 11, c Π 00 ( E i,h ) = 11 and c Π ( R i ) = 9 it follows 21 that c Π ( E i,j ) + c Π ( E i,h ) + c Π ( R i ) ≥ c Π 00 ( E i,j ) + c Π 00 ( E i,h ) + c Π 00 ( R i ). No w, we ha v e sho wn that c (Π) ≥ c (Π 00 ). Notice that Π 00 ma y not be a canonical solution, as there ma y exist tw o sets R i , R j , with E i,j part of the instance, asso ciated with a typ e b solution in Π 00 . Now, applying Lemma 30 for eac h pair of sets R i , R j , asso ciated with a typ e b solution in Π 00 , with E i,j part of the instance, we can compute a canonical solution Π 0 suc h that c (Π 00 ) ≥ c (Π 0 ). Hence c (Π) ≥ c (Π 0 ). Lemma 33. L et C b e c over of G . Then, we c an c ompute in p olynomial time a solution Π of 3 -AP( 3 ) over instanc e R of c ost 6 | V | + 3 | C | + 11 | E | + 9 . Pr o of. W e can define a solution Π of 3-AP(3) of cost 6 | V | + 3 | C | + 11 | E | + 9, as follows. Define a typ e a solution for each R i asso ciated with a v ertex v i ∈ C . Each of such sets has a cost of 9. Define a typ e b solution for set R i asso ciated with a vertex v i ∈ V − C , and define an i-normal solution for the sets E i,j , E i,h , E i,l . Each such set R i has a cost of 9, and eac h edge set in { E i,j , E i,h , E i,l } has a cost of 10. Accoun ting this decreasing of the cost of the edge sets (from 11 to 10) to the set R i , is equiv alent to assign to a typ e b solution a cost equal to 6. F or an y other edge set E i,j add to Π the follo wing sets: S 1 = g 1 ( v i , v j ) ∪ g 2 ( v i , v j ), S 2 = g 3 ( v i , v j ) ∪ g 4 ( v i , v j ) ∪ g 5 ( v i , v j ) ∪ g 6 ( v i , v j ). Eac h such edge set has a cost of 11. Finally , define a set X = { x 1 , x 2 , x 3 } , ha ving a total cost of 9. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment